Unleashing More Actions via Action Compositional Training for VLA Models
Pith reviewed 2026-07-02 12:02 UTC · model grok-4.3
The pith
VLA models can compose known sub-skills into new executable behaviors by synthesizing fresh demonstrations from existing tasks via their own latent representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
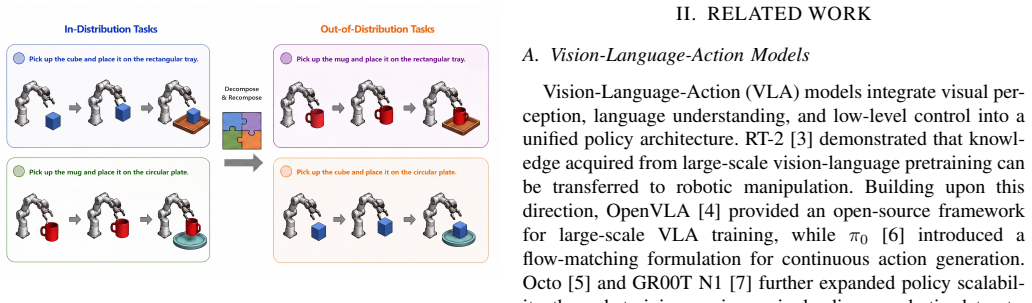
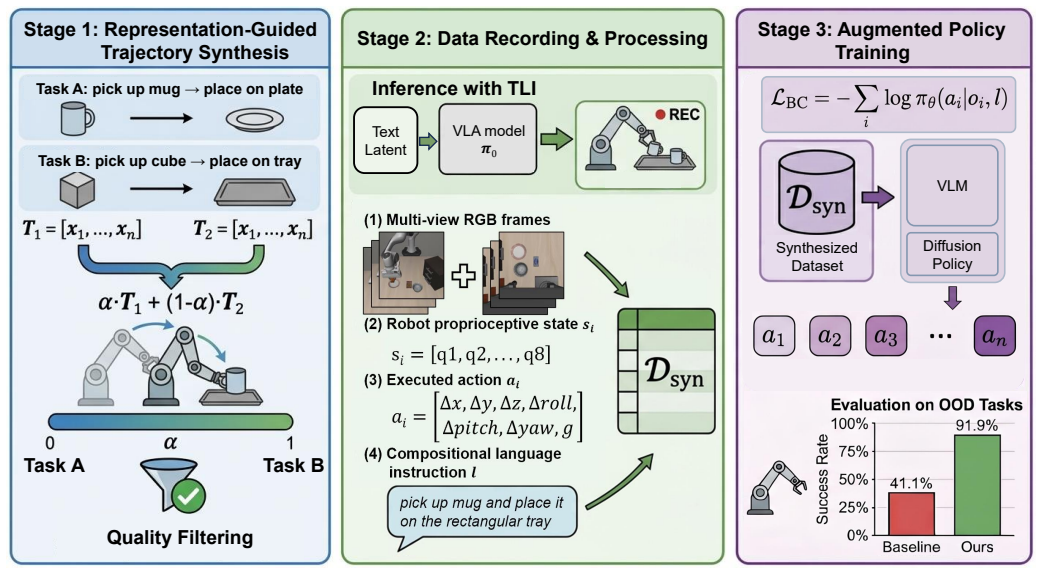
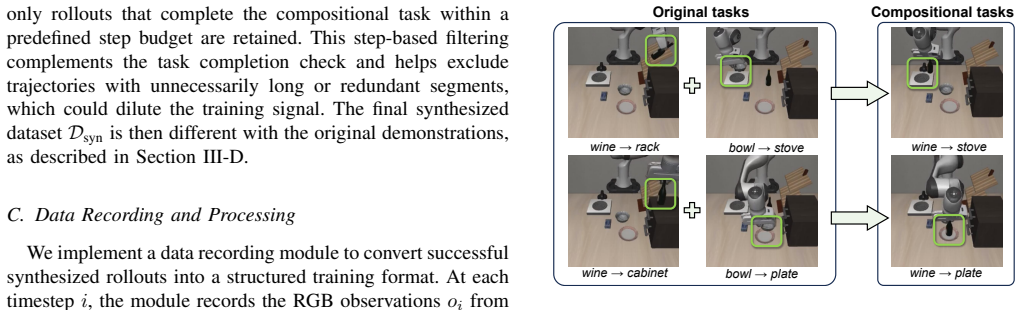
ACT-VLA is an offline data-augmentation framework that leverages a VLA model's latent task representations to synthesize novel, physically valid demonstrations directly from existing tasks; retraining on the resulting expanded distribution mitigates overfitting and enables the policy to execute a much broader set of behaviors that combine known sub-skills in new ways.
What carries the argument
ACT-VLA framework that extracts latent task representations from an existing VLA model and recombines them to produce new demonstration trajectories for policy retraining.
If this is right
- VLA policies become able to handle out-of-distribution scenarios that require only new orderings or pairings of already-demonstrated sub-skills.
- The effective training distribution grows automatically without additional human data collection or teleoperation.
- Overfitting to the narrow behavioral patterns of the original demonstrations is reduced.
- Success rates on manipulation tasks increase substantially when policies are retrained on the synthesized data.
Where Pith is reading between the lines
- The same latent-representation recombination idea could be tested on other sequential models that suffer from demonstration overfitting, such as language-model agents.
- If the synthesized trajectories remain valid when transferred to real robots, the method would cut the cost of scaling VLA training by an order of magnitude.
- The approach implicitly assumes that the original task set already contains all the atomic skills needed for the target domain; domains missing key primitives would still require new data.
Load-bearing premise
The model's latent task representations already encode composable sub-skills that can be recombined into new sequences that remain physically valid in the robot's environment.
What would settle it
A controlled experiment in which the synthesized demonstrations are added to training yet the resulting policy shows no improvement (or degradation) on held-out tasks that require novel combinations of the original sub-skills.
Figures
read the original abstract
Vision-Language-Action models excel at robotic manipulation, driven by the scale and diversity of demonstration data. However, standard training paradigms often cause VLA models to severely overfit to specific behavioral patterns, rendering them unable to generalize to out-of-distribution scenarios even when those scenarios merely require novel combinations of identical sub-skills. While expanding datasets can mitigate this overfitting, acquiring high-quality robot data remains notoriously labor-intensive and cost-prohibitive. To resolve this impasse without expensive human teleoperation and to truly unleash more actions,i.e., enable VLA models to compose known sub-skills into a much broader set of executable behaviors beyond the original demonstrations-we propose ACT-VLA (Action Compositional Training for VLA Models), an offline data augmentation framework that leverages the model's latent task representations to synthesize novel, physically valid demonstrations directly from existing tasks for policy training. By eliminating additional manual data collection, our method automatically expands the training distribution and mitigates overfitting. We evaluate our approach on challenging manipulation tasks in simulation. Experiments demonstrate that while baseline VLA models generalize poorly due to original distribution overfitting, policies trained with our synthesized data achieve substantially higher success rates, validating that leveraging existing tasks for automated demonstration synthesis provides an effective, scalable, and data-efficient route to broadening VLA generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ACT-VLA, an offline data augmentation framework for Vision-Language-Action (VLA) models. It claims that by leveraging the model's latent task representations to synthesize novel, physically valid demonstrations directly from existing tasks, the method expands the training distribution, mitigates overfitting to specific behavioral patterns, and enables generalization to out-of-distribution scenarios requiring novel combinations of sub-skills. Experiments in simulation are said to show that policies retrained on the synthesized data achieve substantially higher success rates than baseline VLA models, validating a scalable, data-efficient route to broader VLA generalization without additional human teleoperation.
Significance. If the synthesis procedure produces physically valid demonstrations and the reported success-rate gains hold under controlled evaluation, the work would address a key bottleneck in robotic learning by providing an automated way to augment demonstration datasets compositionally. This could reduce dependence on costly data collection while improving generalization, with potential impact on scalable VLA training.
major comments (2)
- [Abstract] Abstract: The central empirical claim that 'policies trained with our synthesized data achieve substantially higher success rates' is presented as a bare assertion with no quantitative metrics, success-rate values, baseline comparisons, task descriptions, or error analysis. This renders the primary result unevidenced and prevents assessment of whether the gains are load-bearing or statistically meaningful.
- [Abstract] Abstract (paragraph on ACT-VLA proposal): No algorithm, procedure, equations, or pseudocode is supplied for how latent task representations are used to synthesize novel demonstrations, nor is any validation (e.g., physical validity checks or feasibility filters) described. The weakest assumption—that latent representations suffice to generate physically valid novel behaviors—therefore remains unaddressed and untestable from the given text.
Simulated Author's Rebuttal
We thank the referee for the thoughtful feedback on the abstract. We agree that the abstract should more clearly convey the quantitative results and technical approach. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that 'policies trained with our synthesized data achieve substantially higher success rates' is presented as a bare assertion with no quantitative metrics, success-rate values, baseline comparisons, task descriptions, or error analysis. This renders the primary result unevidenced and prevents assessment of whether the gains are load-bearing or statistically meaningful.
Authors: The abstract is intentionally concise, but we agree it should include key quantitative support for the main claim. The full manuscript reports detailed success rates, baseline comparisons, task descriptions, and error analysis in the Experiments section. In the revised version we will incorporate specific numerical results (e.g., success-rate deltas and task names) directly into the abstract to make the empirical claim self-contained. revision: yes
-
Referee: [Abstract] Abstract (paragraph on ACT-VLA proposal): No algorithm, procedure, equations, or pseudocode is supplied for how latent task representations are used to synthesize novel demonstrations, nor is any validation (e.g., physical validity checks or feasibility filters) described. The weakest assumption—that latent representations suffice to generate physically valid novel behaviors—therefore remains unaddressed and untestable from the given text.
Authors: Abstracts conventionally omit algorithmic details and equations. The full manuscript (Section 3) supplies the precise procedure for leveraging latent task representations, the synthesis steps, and the physical-validity validation (including feasibility filters). Experimental results in simulation further support that the generated demonstrations are executable. To address the concern we will add a short clarifying phrase in the abstract that points to the synthesis mechanism while remaining within length limits. revision: partial
Circularity Check
No significant circularity; empirical method with independent validation
full rationale
The paper presents an empirical offline data-augmentation pipeline (latent representations → synthesized demonstrations → retrained policy) whose central claim is measured by success-rate improvements on held-out manipulation tasks. No equations, fitted parameters, or derivations appear in the provided text that reduce the output to the input by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the synthesis procedure. The reported gains are therefore not forced by re-labeling or self-referential fitting; they remain an external empirical test of the proposed framework.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collab- oration 0,
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jainet al., “Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collab- oration 0,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 6892–6903
2024
-
[3]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning (CoRL). PMLR, 2023, pp. 2165–2183
2023
-
[4]
Openvla: An open- source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Openvla: An open- source vision-language-action model,” inConference on Robot Learning (CoRL). PMLR, 2025, pp. 2679–2713
2025
-
[5]
Octo: An open-source generalist robot policy,
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine, “Octo: An open-source generalist robot policy,” inProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “π 0: A vision-language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huanget al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
π 0.5: A Vision-Language-Action Model with Open-World Generalization,
K. Black, N. R. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Gallikeret al., “π 0.5: A Vision-Language-Action Model with Open-World Generalization,” in Conference on Robot Learning (CoRL), 2025
2025
-
[9]
Z. Wang, Z. Zhou, J. Song, Y . Huang, Z. Shu, and L. Ma, “Towards testing and evaluating vision-language-action models for robotic manip- ulation: An empirical study,”arXiv preprint arXiv:2409.12894, vol. 1, 2024
-
[10]
LIBERO-PRO: Towards Robust and Fair Evaluation of Vision-Language-Action Models Beyond Memorization
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun, “Libero-pro: Towards robust and fair evaluation of vision-language- action models beyond memorization,”arXiv preprint arXiv:2510.03827, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Feiet al., “Libero-plus: In-depth robustness analysis of vision- language-action models,”arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Vlas are confined yet capable of generalizing to novel instruc- tions,
Q. Li, “Vlas are confined yet capable of generalizing to novel instruc- tions,” inProceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2026
2026
-
[13]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,”Advances in Neural Information Processing Systems, vol. 36, pp. 44 776–44 791, 2023
2023
-
[14]
InstructVLA: Vision-language-action instruction tuning from understanding to manipulation,
S. Yang, H. Li, Y . Chen, B. Wang, Y . Tian, T. Wang, H. Wang, F. Zhao, Y . Liao, and J. Pang, “InstructVLA: Vision-language-action instruction tuning from understanding to manipulation,” inInternational Conference on Learning Representations (ICLR), 2026
2026
-
[15]
Reconvla: Reconstructive vision-language-action model as effective robot perceiver,
W. Song, Z. Zhou, H. Zhao, J. Chen, P. Ding, H. Yan, Y . Huang, F. Tang, D. Wang, and H. Li, “Reconvla: Reconstructive vision-language-action model as effective robot perceiver,” inAAAI Conference on Artificial Intelligence, 2025
2025
-
[16]
F. Li, W. Song, H. Zhao, J. Wang, P. Ding, D. Wang, L. Zeng, and H. Li, “Spatial forcing: Implicit spatial representation alignment for vision- language-action model,”arXiv preprint arXiv:2510.12276, 2025
-
[17]
3D-VLA: A 3D Vision-Language-Action Generative World Model
H. Zhen, X. Qiu, P. Chen, J. Yang, X. Yan, Y . Du, Y . Hong, and C. Gan, “3d-vla: A 3d vision-language-action generative world model,”arXiv preprint arXiv:2403.09631, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Deco: Task decomposition and skill composition for zero- shot generalization in long-horizon 3d manipulation,
Z. Chen, J. Yin, Y . Chen, J. Huo, P. Tian, J. Shi, Y . Hou, Y . Li, and Y . Gao, “Deco: Task decomposition and skill composition for zero- shot generalization in long-horizon 3d manipulation,”IEEE Robotics and Automation Letters, pp. 5049–5056, 2026
2026
-
[19]
LiLo-VLA: Compositional Long-Horizon Manipulation via Linked Object-Centric Policies, 2026
Y . Yang, S. Cheng, Y . Fang, H. Bharadhwaj, M. Ding, G. Bertasius, and D. Szafir, “Lilo-vla: Compositional long-horizon manipulation via linked object-centric policies,”arXiv preprint arXiv:2602.21531, 2026
-
[20]
Generative skill chaining: Long-horizon skill planning with diffusion models,
U. A. Mishra, S. Xue, Y . Chen, and D. Xu, “Generative skill chaining: Long-horizon skill planning with diffusion models,” inConference on Robot Learning, 2023
2023
-
[21]
arXiv preprint arXiv:2508.19958 , year=
Y . Fan, P. Ding, S. Bai, X. Tong, Y . Zhu, H. Lu, F. Dai, W. Zhao, Y . Liu, S. Huanget al., “Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation,”arXiv preprint arXiv:2508.19958, 2025
-
[22]
Plan-seq- learn: Language model guided rl for solving long horizon robotics tasks,
M. Dalal, T. Chiruvolu, D. Chaplot, and R. Salakhutdinov, “Plan-seq- learn: Language model guided rl for solving long horizon robotics tasks,” arXiv preprint arXiv:2405.01534, 2024
-
[23]
Search-based task planning with learned skill effect models for lifelong robotic manipulation,
J. Liang, M. Sharma, A. LaGrassa, S. Vats, S. Saxena, and O. Kroemer, “Search-based task planning with learned skill effect models for lifelong robotic manipulation,” in2022 International Conference on Robotics and Automation (ICRA), 2022, pp. 6351–6357
2022
-
[24]
Inner Monologue: Embodied Reasoning through Planning with Language Models
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotaret al., “Inner monologue: Embod- ied reasoning through planning with language models,”arXiv preprint arXiv:2207.05608, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Interleave-vla: Enhancing robot manipulation with image-text interleaved instructions,
C. Fan, X. Jia, Y . Sun, Y . Wang, J. Wei, Z. Gong, X. Zhao, M. Tomizuka, X. Yang, J. Yanet al., “Interleave-vla: Enhancing robot manipulation with image-text interleaved instructions,” inInternational Conference on Learning Representations, 2026
2026
-
[26]
Pixelvla: Advancing pixel-level understanding in vision- language-action model,
W. Liang, G. Sun, Y . He, J. Dong, S. Dai, I. Laptev, S. Khan, and Y . Cong, “Pixelvla: Advancing pixel-level understanding in vision- language-action model,” inInternational Conference on Learning Rep- resentations, 2026
2026
-
[27]
GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data
S. Deng, M. Yan, S. Wei, H. Ma, Y . Yang, J. Chen, Z. Zhang, T. Yang, X. Zhang, W. Zhanget al., “Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data,”arXiv preprint arXiv:2505.03233, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Scaling Robot Learning with Semantically Imagined Experience
T. Yu, T. Xiao, A. Stone, J. Tompson, A. Brohan, S. Wang, J. Singh, C. Tan, J. Peralta, B. Ichteret al., “Scaling robot learning with semantically imagined experience,”arXiv preprint arXiv:2302.11550, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li, “Univla: Learning to act anywhere with task-centric latent actions,” arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
M. J. Kim, C. Finn, and P. Liang, “Fine-tuning vision-language- action models: Optimizing speed and success,”arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.