Personalized Object Identification and Localization via In-Context Inference with Vision-Language Models
Pith reviewed 2026-07-02 15:18 UTC · model grok-4.3
The pith
IPLoc-ID adds identification to personalized localization so vision-language models can reject images without the reference object.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
POIL is solved by first predicting a candidate bounding box and then determining whether it corresponds to the reference object instance through a self-posed query that connects the two steps within a single autoregressive generation of a vision-language model.
What carries the argument
The self-posed query, which links bounding-box prediction and instance verification inside one autoregressive generation.
If this is right
- POIL becomes solvable with existing vision-language models without separate training stages for identification.
- False-positive detections drop on images that do not contain the reference instance compared with localization-only methods.
- Localization performance on images that do contain the instance stays close to the performance of the earlier IPLoc method.
- The identification step integrates naturally into few-shot object detection pipelines that previously lacked instance-level rejection.
Where Pith is reading between the lines
- The same single-pass verification trick could be tested on other VLM tasks that require confirming whether a detected region matches a reference.
- Allowing the model to consider several candidate boxes before the verification step might further reduce errors on hard negative images.
- Applications such as robotic search or photo library search would gain the ability to skip irrelevant scenes without extra post-processing.
Load-bearing premise
A vision-language model can reliably decide from the self-posed query whether a candidate bounding box matches the reference object instance.
What would settle it
On a collection of negative query images known to lack the reference object, IPLoc-ID still produces many bounding-box outputs instead of correctly indicating absence.
Figures


read the original abstract
Personalized object localization (POL) localizes an object instance in a query image based on a few reference images with bounding-box annotations and a target object label. The pioneering method, IPLoc, solves this task through in-context inference with vision-language models (VLMs). However, it assumes that the query image always contains the target object. This assumption severely limits its applicability to real-world scenarios with many irrelevant images. To address this issue, we formulate a new task, personalized object identification and localization (POIL), by positioning POL within the broader few-shot object detection framework. POIL aims to localize the target object instance while rejecting query images that do not contain the reference object instance. We also present POIL datasets constructed from public sources. We further propose an in-context algorithm named IPLoc-ID for solving POIL with VLMs. IPLoc-ID first predicts a candidate bounding box and then determines whether it corresponds to the reference object instance. We introduce a self-posed query to connect these two steps within a single autoregressive generation framework. Through ablation studies and comprehensive experiments, we show that IPLoc-ID substantially suppresses false-positive detections on negative query images while maintaining localization performance comparable to IPLoc. Overall, IPLoc-ID effectively addresses the practical instance-level POIL task, which cannot be sufficiently solved by conventional object detection, few-shot object detection, or the localization-only IPLoc method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates the personalized object identification and localization (POIL) task, extending personalized object localization (POL) to reject query images without the target instance. It proposes IPLoc-ID, an in-context inference algorithm for vision-language models (VLMs) that generates a candidate bounding box and then uses a self-posed query to determine if the box corresponds to the reference object in a single autoregressive generation. Ablation studies and experiments on POIL datasets constructed from public sources show that IPLoc-ID reduces false-positive detections on negative query images while maintaining localization performance comparable to the prior IPLoc method.
Significance. If the results hold, this addresses a key limitation in applying POL to real-world scenarios with irrelevant images, making it more practical within the few-shot object detection framework. The work gives credit to reproducibility by constructing POIL datasets from public sources and building on existing VLMs without fine-tuning. The empirical nature avoids parameter fitting, focusing on algorithmic use of in-context learning.
major comments (2)
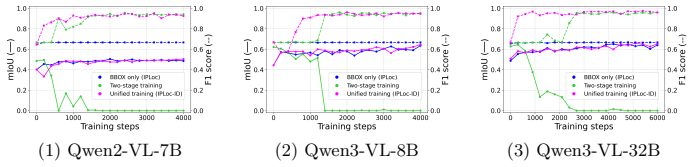
- [Section 3 (Proposed Method)] The headline result of false-positive suppression on negative queries depends on the VLM correctly interpreting the self-posed query to reject non-matching candidate boxes within one autoregressive sequence. The manuscript does not provide a dedicated analysis or quantitative breakdown of identification errors in this step, which is load-bearing for the claim that the method 'substantially suppresses false-positive detections' (abstract; Section 3, algorithm description).
- [Experiments and Ablations] The abstract references ablation studies demonstrating the benefits, but without specific tables or figures showing metrics on negative vs positive queries (e.g., false positive rate, localization IoU or mAP), the support for 'comparable localization performance' and the overall POIL effectiveness cannot be verified in detail.
minor comments (2)
- [Abstract] The description of the self-posed query could be clarified earlier to help readers understand how it connects the localization and identification steps.
- [References] Consider adding citations to recent studies on VLM limitations in multi-step visual reasoning to contextualize the approach.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments on our manuscript. We address each major comment point-by-point below, with plans to revise the paper to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Section 3 (Proposed Method)] The headline result of false-positive suppression on negative queries depends on the VLM correctly interpreting the self-posed query to reject non-matching candidate boxes within one autoregressive sequence. The manuscript does not provide a dedicated analysis or quantitative breakdown of identification errors in this step, which is load-bearing for the claim that the method 'substantially suppresses false-positive detections' (abstract; Section 3, algorithm description).
Authors: We agree that a dedicated quantitative breakdown of identification errors would provide stronger support for the false-positive suppression claim. In the revised manuscript, we will add an analysis subsection (likely in Section 4) that reports identification accuracy metrics on the self-posed query step, including rejection rates on negative queries, error types (e.g., false acceptance of non-matching boxes), and comparison against the localization-only baseline. revision: yes
-
Referee: [Experiments and Ablations] The abstract references ablation studies demonstrating the benefits, but without specific tables or figures showing metrics on negative vs positive queries (e.g., false positive rate, localization IoU or mAP), the support for 'comparable localization performance' and the overall POIL effectiveness cannot be verified in detail.
Authors: The ablation studies and main experiments in Section 4 are conducted on the constructed POIL datasets that explicitly include both positive and negative queries, with results showing reduced false positives while preserving localization performance comparable to IPLoc. To improve verifiability, we will add or expand tables/figures in the revised version that explicitly break out metrics such as false positive rate, precision, and IoU/mAP separately for negative versus positive queries. revision: yes
Circularity Check
No circularity; empirical algorithm validated on public data
full rationale
The paper introduces the POIL task and IPLoc-ID algorithm as an empirical extension of prior VLM in-context methods. Performance claims rest on ablation studies and experiments using constructed datasets from public sources, not on any equations, fitted parameters, or self-citations that reduce the reported false-positive suppression or localization metrics to quantities defined inside the paper. The self-posed query mechanism is an algorithmic design choice whose effectiveness is measured externally rather than assumed by construction. No load-bearing self-citation chain or self-definitional reduction exists.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models possess sufficient in-context reasoning capability to perform both localization and instance identification from a small number of reference examples.
Reference graph
Works this paper leans on
-
[1]
Minderer, A
M. Minderer, A. Gritsenko, A. Stone, M. Neumann, D. Weissenborn, A. Dosovitskiy, A. Mahendran, A. Arnab, M. Dehghani, Z. Shen, et al., Sim- ple open-vocabulary object detection, in: European conference on computer vision, Springer, 2022, pp. 728–755
2022
-
[2]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, et al., Grounding dino: Marrying dino with grounded pre-training for open-set object detection, in: European conference on computer vision, Springer, 2024, pp. 38–55
2024
-
[3]
Köhler, M
M. Köhler, M. Eisenbach, H.-M. Gross, Few-shot object detection: A comprehensive survey, IEEE transactions on neural networks and learning systems 35 (9) (2023) 11958–11978
2023
-
[4]
Z. Xin, S. Chen, T. Wu, Y. Shao, W. Ding, X. You, Few-shot object detection: Research advances and challenges, Information Fusion 107 (2024) 102307
2024
-
[5]
X. Wang, T. Huang, J. Gonzalez, T. Darrell, F. Yu, Frustratingly simple few-shot object detection, in: H. D. III, A. Singh (Eds.), Proceedings of the 37th International Conference on Machine Learning, Vol. 119 of Proceedings of Machine Learning Research, PMLR, 2020, pp. 9919–9928. URLhttps://proceedings.mlr.press/v119/wang20j.html
2020
-
[6]
Doveh, N
S. Doveh, N. Shabtay, E. Schwartz, H. Kuehne, R. Giryes, R. Feris, L. Kar- linsky, J. Glass, A. Arbelle, S. Ullman, et al., Teaching vlms to localize specific objects from in-context examples, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 9572–9582
2025
-
[7]
B. Sun, B. Li, S. Cai, Y. Yuan, C. Zhang, Fsce: Few-shot object detection via contrastive proposal encoding, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 7352–7362. 22
2021
-
[8]
L. Qiao, Y. Zhao, Z. Li, X. Qiu, J. Wu, C. Zhang, Defrcn: Decoupled faster r-cnn for few-shot object detection, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 8681–8690
2021
-
[9]
X. Yan, Z. Chen, A. Xu, X. Wang, X. Liang, L. Lin, Meta r-cnn: Towards general solver for instance-level low-shot learning, in: Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9577– 9586
2019
-
[10]
G. Han, J. Ma, S. Huang, L. Chen, S.-F. Chang, Few-shot object detection with fully cross-transformer, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5321–5330
2022
-
[11]
Zhang, Y
X. Zhang, Y. Liu, Y. Wang, A. Boularias, Detect everything with few examples, in: Proceedings of The 8th Conference on Robot Learning, Vol. 270 of Proceedings of Machine Learning Research, PMLR, 2024, pp. 3986– 4004
2024
-
[12]
X. Yu, Y. Sha, L. Liu, X. Shen, D. Yang, A closer look at cross-domain few-shot object detection: Fine-tuning matters and parallel decoder helps, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[13]
C.-B. Feng, Y. Sha, L. Liu, Y. Yu, C. M. Vong, X. Yu, X. Shen, Few-shot object detection with vision foundation models and graph diffusion, in: The Fourteenth International Conference on Learning Representations, 2026
2026
-
[14]
M. Espinosa, C. Yang, L. Ericsson, S. McDonagh, E. J. Crowley, No time to train! training-free reference-based instance segmentation, arXiv preprint arXiv:2507.02798 (2025)
-
[15]
Psomas, G
B. Psomas, G. Retsinas, N. Efthymiadis, P. Filntisis, Y. Avrithis, P. Maragos, O. Chum, G. Tolias, Instance-level composed image retrieval, in: The Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[16]
X. Hao, K. Zhu, H. Guo, H. Guo, N. Jiang, Q. Lu, M. Tang, J. Wang, Referring expression instance retrieval and a strong end-to-end baseline, in: Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 4464–4473
2025
- [17]
-
[18]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., Learning transferable visualmodelsfromnaturallanguagesupervision, in: Internationalconference on machine learning, PmLR, 2021, pp. 8748–8763. 23
2021
-
[19]
Cherti, R
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gor- don, C. Schuhmann, L. Schmidt, J. Jitsev, Reproducible scaling laws for contrastive language-image learning, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 2818–2829
2023
-
[20]
J. Li, D. Li, C. Xiong, S. Hoi, Blip: Bootstrapping language-image pre- training for unified vision-language understanding and generation, in: Inter- national conference on machine learning, PMLR, 2022, pp. 12888–12900
2022
-
[21]
J. Li, D. Li, S. Savarese, S. Hoi, Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, in: International conference on machine learning, PMLR, 2023, pp. 19730– 19742
2023
-
[22]
N. Ravi, V. Gabeur, Y.-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. Rädle, C. Rolland, L. Gustafson, et al., Sam 2: Segment anything in images and videos, in: International Conference on Learning Representations, Vol. 2025, 2025, pp. 28085–28128
2025
-
[23]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, et al., Dinov2: Learning robust visual features without supervision, arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
H. Liu, C. Li, Q. Wu, Y. J. Lee, Visual instruction tuning, Advances in neural information processing systems 36 (2023) 34892–34916
2023
-
[25]
G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ramé, M. Rivière, et al., Gemma 3 technical report, arXiv preprint arXiv:2503.19786 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, et al., Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution, arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
S. Bai, Y. Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al., Qwen3-vl technical report, arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Zhang, H
H. Zhang, H. Li, F. Li, T. Ren, X. Zou, S. Liu, S. Huang, J. Gao, Leizhang, C. Li, et al., Llava-grounding: Grounded visual chat with large multimodal models, in: European Conference on Computer Vision, Springer, 2024, pp. 19–35
2024
-
[29]
Y. Yao, Q. Yang, H. Zhong, J. Wei, Y. Men, S. Bai, M. Cui, Z. Yang, Qwen3- vl-seg: Unlocking open-world referring segmentation with vision-language grounding, arXiv preprint arXiv:2605.07141 (2026). 24
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Press, M
O. Press, M. Zhang, S. Min, L. Schmidt, N. A. Smith, M. Lewis, Measuring and narrowing the compositionality gap in language models, in: Findings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 5687–5711
2023
-
[31]
J. Qi, Z. Xu, Y. Shen, M. Liu, D. Jin, Q. Wang, L. Huang, The art of socratic questioning: Recursive thinking with large language models, in: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 4177–4199
2023
-
[32]
G. Sun, C. Qin, J. Wang, Z. Chen, R. Xu, Z. Tao, Sq-llava: Self-questioning for large vision-language assistant, in: European Conference on Computer Vision, Springer, 2024, pp. 156–172
2024
-
[33]
Prasad, E
A. Prasad, E. Stengel-Eskin, M. Bansal, Rephrase, augment, reason: Vi- sual grounding of questions for vision-language models, in: International Conference on Learning Representations, 2024
2024
-
[34]
S. Min, M. Lewis, L. Zettlemoyer, H. Hajishirzi, Metaicl: Learning to learn in context, in: Proceedings of the 2022 conference of the North American chapter of the Association for Computational Linguistics: Human Language Technologies, 2022, pp. 2791–2809
2022
-
[35]
Monajatipoor, L
M. Monajatipoor, L. H. Li, M. Rouhsedaghat, L. Yang, K.-W. Chang, Metavl: Transferring in-context learning ability from language models to vision-language models, in: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 2023, pp. 495–508
2023
-
[36]
K. P. Yu, Z. Zhang, F. Hu, S. Storks, J. Chai, Eliciting in-context learning in vision-language models for videos through curated data distributional properties, in: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 20416–20431
2024
-
[37]
Sheng, D
D. Sheng, D. Chen, Z. Tan, Q. Liu, Q. Chu, J. Bao, T. Gong, B. Liu, S. Xu, N. Yu, Towards more unified in-context visual understanding, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13362–13372
2024
-
[38]
Everingham, L
M. Everingham, L. Van Gool, C. K. Williams, J. Winn, A. Zisserman, The pascal visual object classes (voc) challenge, International journal of computer vision 88 (2) (2010) 303–338
2010
-
[39]
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, C. L. Zitnick, Microsoft coco: Common objects in context, in: European conference on computer vision, Springer, 2014, pp. 740–755
2014
-
[40]
D. M. W. Powers, Evaluation: From precision, recall and f-measure to roc, informedness, markedness and correlation, Journal of Machine Learning Technologies 2 (1) (2011) 37–63. 25
2011
-
[41]
E.J.Hu, Y.Shen, P.Wallis, Z.Allen-Zhu, Y.Li, S.Wang, L.Wang, W.Chen, LoRA: Low-rank adaptation of large language models, in: International Conference on Learning Representations, 2022
2022
-
[42]
H. Fan, L. Lin, F. Yang, P. Chu, G. Deng, S. Yu, H. Bai, Y. Xu, C. Liao, H. Ling, Lasot: A high-quality benchmark for large-scale single object tracking, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5374–5383
2019
-
[43]
Samuel, R
D. Samuel, R. Ben-Ari, M. Levy, N. Darshan, G. Chechik, Where’s waldo: Diffusion features for personalized segmentation and retrieval, Advances in Neural Information Processing Systems 37 (2024) 128160–128181
2024
-
[44]
Huang, X
L. Huang, X. Zhao, K. Huang, Got-10k: A large high-diversity benchmark for generic object tracking in the wild, IEEE transactions on pattern analysis and machine intelligence 43 (5) (2019) 1562–1577
2019
-
[45]
L. Peng, J. Gao, X. Liu, W. Li, S. Dong, Z. Zhang, H. Fan, L. Zhang, Vast- track: Vast category visual object tracking, Advances in Neural Information Processing Systems 37 (2024) 130797–130818
2024
-
[46]
Riquelme, J
C. Riquelme, J. Puigcerver, B. Mustafa, M. Neumann, R. Jenatton, A. Su- sano Pinto, D. Keysers, N. Houlsby, Scaling vision with sparse mixture of experts, Advances in Neural Information Processing Systems 34 (2021) 8583–8595
2021
-
[47]
M. McCloskey, N. J. Cohen, Catastrophic interference in connectionist networks: The sequential learning problem, Psychology of Learning and Motivation 24 (1989) 109–165. doi:10.1016/S0079-7421(08)60536-8
-
[48]
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al., Overcoming catastrophic forgetting in neural networks, Proceed- ings of the National Academy of Sciences 114 (13) (2017) 3521–3526. doi:10.1073/pnas.1611835114
-
[49]
B. Xiao, H. Wu, W. Xu, X. Dai, H. Hu, Y. Lu, M. Zeng, C. Liu, L. Yuan, Florence-2: Advancing a unified representation for a variety of vision tasks, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4818–4829. 26 Appendix A. Additional Experimental Results Appendix A.1. Pretest on instruction prompts The prop...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.