Distributed Prediction under Heterogeneity with Unidentifiable Parameter
Pith reviewed 2026-07-02 08:06 UTC · model grok-4.3
The pith
A distributed semiparametric estimator achieves two-phase minimax optimal convergence rates and non-asymptotic model-free prediction bounds under unidentifiable parameters and data heterogeneity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
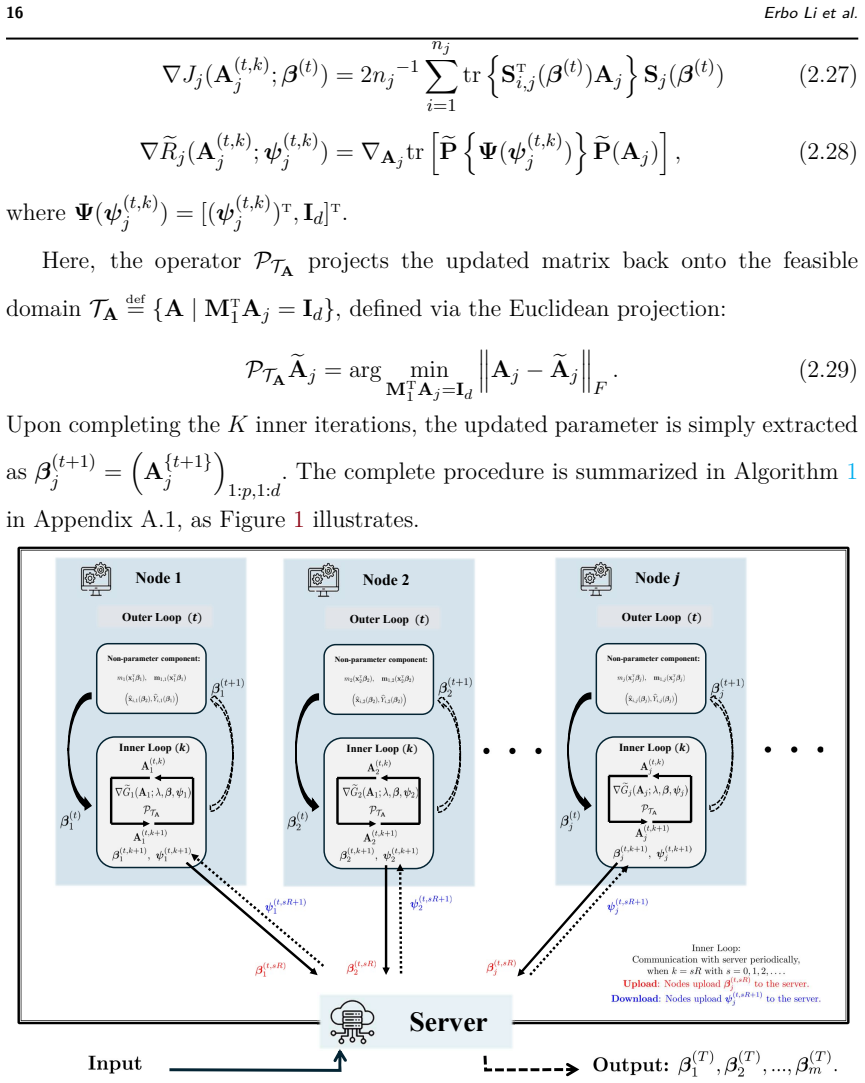
The proposed distributed semiparametric framework formulates adaptive homogeneity pursuit via a trace-similarity penalty to handle heterogeneity, then applies an invex relaxation and multi-step local update algorithm to overcome the severe nonconvexity and communication bottlenecks. This construction yields a non-asymptotic model-free prediction error bound, establishes that the estimator attains a two-phase minimax optimal convergence rate, and provides a sharper model-free prediction error bound. The paper also supplies theoretical guarantees on algorithmic convergence to global optimality and on communication efficiency, with supporting evidence from simulations and a multi-center medical
What carries the argument
The trace-similarity penalty for adaptive homogeneity pursuit, paired with invex relaxation and multi-step local updates, which together resolve heterogeneity and nonconvexity while preserving model-free prediction bounds.
If this is right
- The estimator attains a two-phase minimax optimal convergence rate under the stated conditions.
- A non-asymptotic model-free prediction error bound holds for the distributed procedure.
- The algorithm converges stably to global optimality with reduced communication overhead.
- Theoretical guarantees extend to algorithmic convergence and communication efficiency.
- Empirical superiority is observed in simulations and multi-center medical data.
Where Pith is reading between the lines
- The same penalty-plus-relaxation structure might be tested on other semiparametric problems where parameters are only partially identifiable.
- The communication savings could be quantified more precisely for networks with hundreds of sites rather than the small numbers used in the medical example.
- If the trace-similarity penalty can be replaced by other homogeneity measures, the framework might cover additional forms of distribution shift.
- The two-phase rate structure suggests examining whether the first phase can be shortened by warm-starting from a pooled estimator.
Load-bearing premise
The trace-similarity penalty combined with invex relaxation and multi-step local updates can resolve both heterogeneity and severe nonconvexity while preserving the stated model-free prediction bounds.
What would settle it
A simulation study on synthetic data with known unidentifiable parameters and controlled heterogeneity where the method fails to attain the claimed two-phase minimax rate or exceeds the stated non-asymptotic prediction error bound would falsify the central claim.
Figures
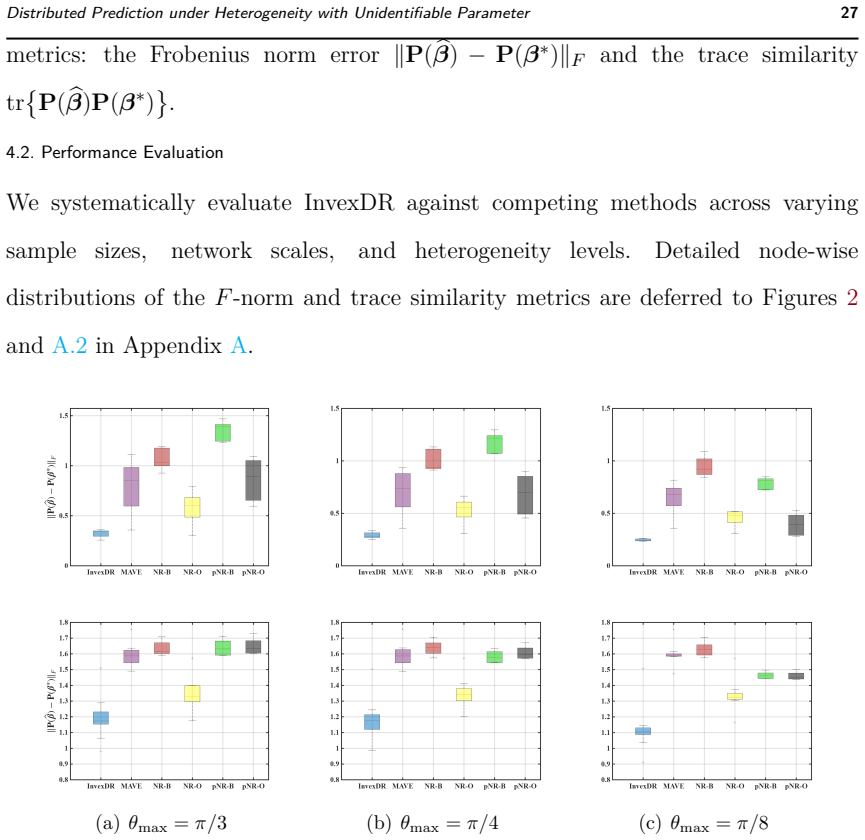
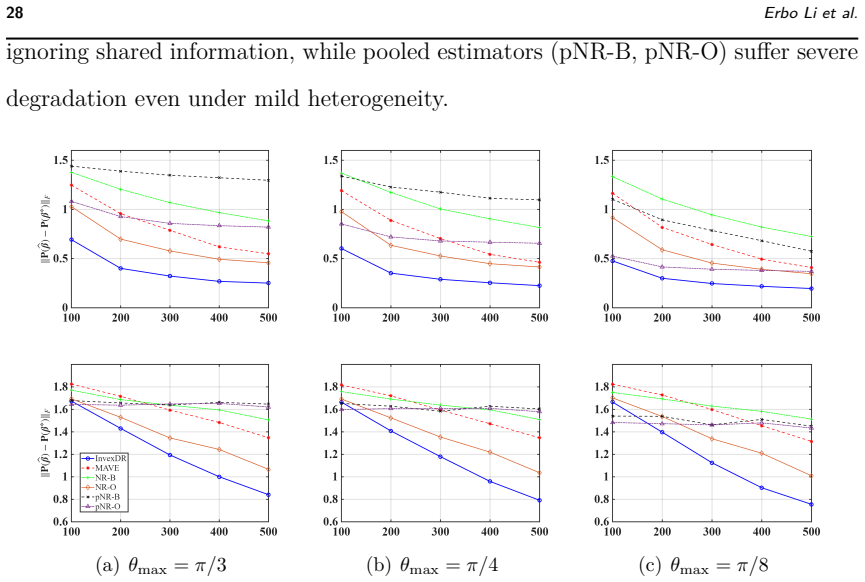
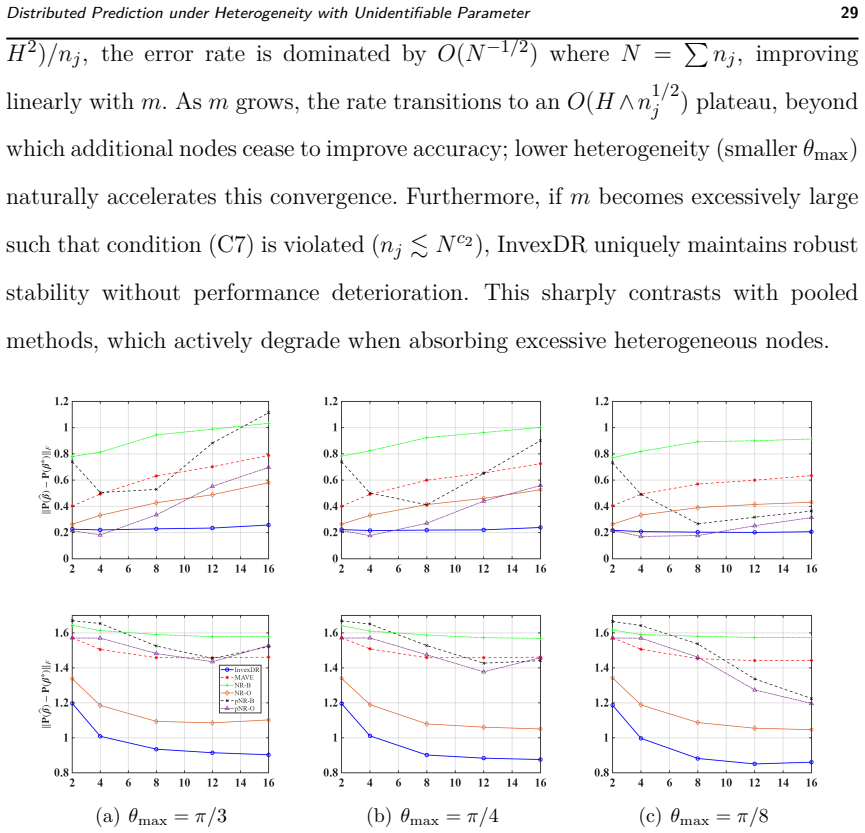
read the original abstract
Predicting a response based on covariates is a fundamental problem in statistics and machine learning. However, profound difficulties arise when the underlying low-dimensional structural parameters are unidentifiable, as typified in dimension reduction contexts. Specifically,estimating these non-identifiable parameters inherently introduces severe nonconvexity. In distributed settings, this difficulty is further compounded by the challenges of data heterogeneity and communication cost. To overcome these intertwined barriers, we propose a novel distributed semiparametric framework. We formulate an adaptive homogeneity pursuit utilizing a trace-similarity penalty to effectively address data heterogeneity. To resolve the ensuing severe nonconvexity and communication bottlenecks, we introduce an invex relaxation technique coupled with a multi-step local update algorithm, ensuring stable convergence to global optimality with significantly reduced communication overhead. Theoretically, we establish a non-asymptotic model-free prediction error bound and prove that our estimator achieves a two-phase minimax optimal convergence rate and an sharper model-free prediction error bound. Furthermore, we provide theoretical guarantees for algorithmic convergence and communication efficiency. Extensive simulations and a real-world multi-center medical application validate the superiority of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a distributed semiparametric framework for prediction under data heterogeneity when low-dimensional structural parameters are unidentifiable (as in dimension reduction). It introduces an adaptive homogeneity pursuit via a trace-similarity penalty, combined with an invex relaxation and multi-step local updates to address nonconvexity and communication costs. The central claims are a non-asymptotic model-free prediction error bound, achievement of a two-phase minimax optimal convergence rate, a sharper model-free prediction error bound, plus guarantees on algorithmic convergence and communication efficiency, supported by simulations and a multi-center medical application.
Significance. If the invariance and bound derivations hold, the work would advance distributed learning for heterogeneous, unidentifiable-parameter settings by delivering model-free non-asymptotic guarantees and reduced communication, with potential practical value in multi-site applications.
major comments (2)
- [Abstract] Abstract (paragraph on proposed framework): the non-asymptotic model-free prediction error bound and two-phase minimax rate are asserted to follow from the trace-similarity penalty resolving heterogeneity. However, because the low-dimensional parameters are explicitly unidentifiable, any two equivalent representations related by the inherent group action (e.g., orthogonal transformation) can produce different trace-similarity values; the abstract gives no indication that the penalty is invariant on the quotient space. If it is not, the homogeneity pursuit step can mis-classify sites or introduce bias that propagates into the prediction-error bound, violating the claimed model-free guarantee.
- [Abstract] Abstract (theoretical guarantees paragraph): the claim that the estimator achieves the stated rates and bounds while the invex relaxation resolves severe nonconvexity requires that the penalty and relaxation together preserve the model-free property under unidentifiability. No derivation or assumption list is visible in the provided abstract that reduces the bounds to quantities independent of the choice of representative within each equivalence class; this is load-bearing for the central claim.
minor comments (1)
- [Abstract] Abstract: 'an sharper model-free prediction error bound' contains a grammatical error.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for raising these important points about invariance under unidentifiability. We address each major comment below and indicate the revisions we will make to the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on proposed framework): the non-asymptotic model-free prediction error bound and two-phase minimax rate are asserted to follow from the trace-similarity penalty resolving heterogeneity. However, because the low-dimensional parameters are explicitly unidentifiable, any two equivalent representations related by the inherent group action (e.g., orthogonal transformation) can produce different trace-similarity values; the abstract gives no indication that the penalty is invariant on the quotient space. If it is not, the homogeneity pursuit step can mis-classify sites or introduce bias that propagates into the prediction-error bound, violating the claimed model-free guarantee.
Authors: The trace-similarity penalty is defined via the Frobenius inner product of the estimated loading matrices, which is invariant under simultaneous orthogonal transformations of the loadings because trace(B^T A) remains unchanged when A and B are replaced by AQ and BQ for orthogonal Q. This construction is given explicitly in Equation (3.4) of the manuscript and ensures the penalty value (and therefore the homogeneity pursuit) is the same for any choice of representative within an equivalence class. Consequently the subsequent prediction-error bounds, which depend only on the identifiable prediction map, remain model-free. We will revise the abstract to state that the penalty is invariant on the quotient space. revision: yes
-
Referee: [Abstract] Abstract (theoretical guarantees paragraph): the claim that the estimator achieves the stated rates and bounds while the invex relaxation resolves severe nonconvexity requires that the penalty and relaxation together preserve the model-free property under unidentifiability. No derivation or assumption list is visible in the provided abstract that reduces the bounds to quantities independent of the choice of representative within each equivalence class; this is load-bearing for the central claim.
Authors: The abstract cannot contain full derivations. The model-free character of the bounds is established in Theorems 4.1–4.2 by working exclusively with the identifiable prediction functional; the proofs never rely on a particular representative of the unidentifiable parameter. The invex relaxation (Section 5) is applied to an objective whose level sets are likewise invariant under the group action, as shown in Lemma 5.3. We will add a single sentence to the abstract clarifying that all stated rates and bounds are invariant on the quotient space. revision: yes
Circularity Check
No significant circularity; theoretical bounds derived independently from framework properties
full rationale
The paper's central claims consist of non-asymptotic model-free prediction error bounds and two-phase minimax rates established for the proposed distributed semiparametric estimator. These are presented as following from the trace-similarity penalty, invex relaxation, and multi-step local updates, without any quoted reduction showing that the bounds or rates are equivalent by construction to fitted inputs, self-defined quantities, or load-bearing self-citations. The derivation chain remains self-contained against external benchmarks, with no patterns of self-definitional equivalence, fitted inputs renamed as predictions, or ansatz smuggled via citation matching the enumerated circularity kinds.
Axiom & Free-Parameter Ledger
free parameters (1)
- trace-similarity penalty strength
axioms (1)
- domain assumption The underlying statistical model is semiparametric with low-dimensional structural parameters that are unidentifiable.
invented entities (2)
-
trace-similarity penalty
no independent evidence
-
invex relaxation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
WIREs Computational Statistics , volume =
Cizek, Pavel and Sadıkoglu, Serhan , title =. WIREs Computational Statistics , volume =. doi:https://doi.org/10.1002/wics.1492 , url =. https://wires.onlinelibrary.wiley.com/doi/pdf/10.1002/wics.1492 , abstract =
-
[2]
Econometrics and Statistics , year=
Robust nonparametric regression: review and practical considerations , author=. Econometrics and Statistics , year=
-
[3]
Journal of the Royal Statistical Society Series A: Statistics in Society , volume=
Estimating individual treatment effects using non-parametric regression models: A review , author=. Journal of the Royal Statistical Society Series A: Statistics in Society , volume=. 2022 , publisher=
2022
-
[4]
1-Bit Compressive Sensing for Efficient Federated Learning Over the Air , year=
Fan, Xin and Wang, Yue and Huo, Yan and Tian, Zhi , journal=. 1-Bit Compressive Sensing for Efficient Federated Learning Over the Air , year=
-
[5]
Enhancing 1-Bit Compressive Sensing With Support Estimation in Noisy Wireless Sensor Networks , year=
Yang, Ming-Hsun and Huang, Liang-Chi , journal=. Enhancing 1-Bit Compressive Sensing With Support Estimation in Noisy Wireless Sensor Networks , year=
-
[6]
2023 6th International Conference on Information Communication and Signal Processing (ICICSP) , pages=
Why can one-bit quantization work? a mathematical theory analysis , author=. 2023 6th International Conference on Information Communication and Signal Processing (ICICSP) , pages=. 2023 , organization=
2023
-
[7]
IEEE Transactions on Information Theory , volume=
One-bit compressive sensing with norm estimation , author=. IEEE Transactions on Information Theory , volume=. 2016 , publisher=
2016
-
[8]
2008 42nd Annual Conference on Information Sciences and Systems , pages=
1-bit compressive sensing , author=. 2008 42nd Annual Conference on Information Sciences and Systems , pages=. 2008 , organization=
2008
-
[9]
Applied and Computational Harmonic Analysis , volume=
Noisy 1-bit compressive sensing: models and algorithms , author=. Applied and Computational Harmonic Analysis , volume=. 2016 , publisher=
2016
-
[10]
SIAM Journal on Scientific Computing , volume=
Robust decoding from 1-bit compressive sampling with ordinary and regularized least squares , author=. SIAM Journal on Scientific Computing , volume=. 2018 , publisher=
2018
-
[11]
Global Strategy Journal , volume =
Amore, Mario Daniele and Murtinu, Samuele , title =. Global Strategy Journal , volume =. doi:https://doi.org/10.1002/gsj.1363 , url =. https://sms.onlinelibrary.wiley.com/doi/pdf/10.1002/gsj.1363 , year =
-
[12]
Quantitative Economics , volume =
Liu, Laura and Moon, Hyungsik Roger and Schorfheide, Frank , title =. Quantitative Economics , volume =. doi:https://doi.org/10.3982/QE1505 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.3982/QE1505 , year =
-
[13]
Proceedings of the 31st Conference On Learning Theory , pages =
Learning Single-Index Models in Gaussian Space , author =. Proceedings of the 31st Conference On Learning Theory , pages =. 2018 , editor =
2018
-
[14]
Advances in Neural Information Processing Systems , volume=
Smoothing the landscape boosts the signal for sgd: Optimal sample complexity for learning single index models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Journal of Business & Economic Statistics , volume=
Homogeneity pursuit in single index models based panel data analysis , author=. Journal of Business & Economic Statistics , volume=. 2021 , publisher=
2021
-
[16]
and Brewer, Benjamin and Nakas, Christos T
Bantis, Leonidas E. and Brewer, Benjamin and Nakas, Christos T. and Reiser, Benjamin , title =. Statistics in Medicine , volume =. doi:https://doi.org/10.1002/sim.10252 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/sim.10252 , year =
-
[17]
Electronics , volume=
Machine Learning Techniques Improving the Box--Cox Transformation in Breast Cancer Prediction , author=. Electronics , volume=. 2025 , publisher=
2025
-
[18]
Journal of Econometrics , volume=
Semiparametric estimation of a censored regression model with an unknown transformation of the dependent variable , author=. Journal of Econometrics , volume=. 1999 , publisher=
1999
-
[19]
Journal of the American Statistical Association , volume=
Predicting survival probabilities with semiparametric transformation models , author=. Journal of the American Statistical Association , volume=. 1997 , publisher=
1997
-
[20]
Econometrica , volume=
Rank estimation of transformation models , author=. Econometrica , volume=. 2002 , publisher=
2002
-
[21]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Conditional transformation models , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2014 , publisher=
2014
-
[22]
Stats , volume=
The Detection Method of the Tobit Model in a Dataset , author=. Stats , volume=. 2025 , publisher=
2025
-
[23]
A dimension reduction based approach for estimation and variable selection in partially linear single-index models with high-dimensional covariates , author=
-
[24]
Conference On Learning Theory , pages=
Learning single-index models in gaussian space , author=. Conference On Learning Theory , pages=. 2018 , organization=
2018
-
[25]
Annals of Statistics , pages=
Direct estimation of the index coefficient in a single-index model , author=. Annals of Statistics , pages=. 2001 , publisher=
2001
-
[26]
, author=
Sparse single-index model. , author=. Journal of Machine Learning Research , volume=
-
[27]
Journal of the American Statistical Association , volume=
On partial sufficient dimension reduction with applications to partially linear multi-index models , author=. Journal of the American Statistical Association , volume=. 2013 , publisher=
2013
-
[28]
2009 , publisher=
Semiparametric and nonparametric methods in econometrics , author=. 2009 , publisher=
2009
-
[29]
2018 , publisher=
Sufficient dimension reduction: Methods and applications with R , author=. 2018 , publisher=
2018
-
[30]
Journal of the American Statistical Association , volume =
Ker-Chau Li , title =. Journal of the American Statistical Association , volume =. 1991 , publisher =
1991
-
[31]
Journal of the American Statistical Association , volume=
Sliced inverse regression for dimension reduction: Comment , author=. Journal of the American Statistical Association , volume=. 1991 , publisher=
1991
-
[32]
The Annals of Statistics , number =
Bing Li and Hongyuan Zha and Francesca Chiaromonte , title =. The Annals of Statistics , number =. 2005 , doi =
2005
-
[33]
Journal of the American Statistical Association , volume =
Bing Li and Shaoli Wang , title =. Journal of the American Statistical Association , volume =. 2007 , publisher =
2007
-
[34]
Xia, Yingcun and Tong, Howell and Li, W. K. and Zhu, Li-Xing , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 2002 , month =. doi:10.1111/1467-9868.03411 , url =
-
[35]
Journal of the American Statistical Association , volume =
Yanyuan Ma and Liping Zhu , title =. Journal of the American Statistical Association , volume =. 2012 , publisher =
2012
-
[36]
The Annals of Statistics , number =
Wei Luo and Bing Li and Xiangrong Yin , title =. The Annals of Statistics , number =. 2014 , doi =
2014
-
[37]
Mathematical Programming , volume=
A feasible method for optimization with orthogonality constraints , author=. Mathematical Programming , volume=. 2013 , publisher=
2013
-
[38]
Jordan and Jason D
Michael I. Jordan and Jason D. Lee and Yun Yang , title =. Journal of the American Statistical Association , volume =. 2019 , publisher =
2019
-
[39]
Journal of the American Statistical Association , volume =
Jianqing Fan and Yongyi Guo and Kaizheng Wang , title =. Journal of the American Statistical Association , volume =. 2023 , publisher =
2023
-
[40]
, author=
DISTRIBUTED MEAN DIMENSION REDUCTION THROUGH SEMI-PARAMETRIC APPROACHES. , author=. Statistica Sinica , volume=
-
[41]
Distributed estimation in heterogeneous reduced rank regression: With application to order determination in sufficient dimension reduction , journal =. 2022 , issn =. doi:https://doi.org/10.1016/j.jmva.2022.104991 , author =
-
[42]
Statistical Analysis and Data Mining: The ASA Data Science Journal , volume =
Zhu, Zhengtian and Zhu, Liping , title =. Statistical Analysis and Data Mining: The ASA Data Science Journal , volume =. doi:https://doi.org/10.1002/sam.11592 , year =
-
[43]
Journal of Machine Learning Research , year =
Zhanrui Cai and Runze Li and Liping Zhu , title =. Journal of Machine Learning Research , year =
-
[44]
Annals of statistics , volume=
Distributed estimation of principal eigenspaces , author=. Annals of statistics , volume=
-
[45]
International journal of machine learning and cybernetics , volume=
A survey on federated learning: challenges and applications , author=. International journal of machine learning and cybernetics , volume=. 2023 , publisher=
2023
-
[46]
and Ding, Ming and Pathirana, Pubudu N
Nguyen, Dinh C. and Ding, Ming and Pathirana, Pubudu N. and Seneviratne, Aruna and Li, Jun and Vincent Poor, H. , journal=. Federated Learning for Internet of Things: A Comprehensive Survey , year=
-
[47]
A survey on federated learning , journal =. 2021 , issn =. doi:https://doi.org/10.1016/j.knosys.2021.106775 , author =
-
[48]
Journal of Big Data , volume=
A survey on heterogeneous transfer learning , author=. Journal of Big Data , volume=. 2017 , publisher=
2017
-
[49]
Multimedia Tools and Applications , volume=
Heterogeneous transfer learning: recent developments, applications, and challenges , author=. Multimedia Tools and Applications , volume=. 2024 , publisher=
2024
-
[50]
Tony Cai and Hongzhe Li , title =
Sai Li and T. Tony Cai and Hongzhe Li , title =. Journal of the American Statistical Association , volume =. 2023 , publisher =
2023
-
[51]
Tony and Li, Hongzhe , title =
Li, Sai and Cai, T. Tony and Li, Hongzhe , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 2021 , month =
2021
-
[52]
arXiv e-prints , pages=
Transfer Learning for Kernel-based Regression , author=. arXiv e-prints , pages=
-
[54]
The Annals of Statistics , number =
Yaqi Duan and Kaizheng Wang , title =. The Annals of Statistics , number =. 2023 , doi =
2023
-
[55]
On Convergence of FedProx: Local Dissimilarity Invariant Bounds, Non-smoothness and Beyond , volume =
Yuan, Xiaotong and Li, Ping , booktitle =. On Convergence of FedProx: Local Dissimilarity Invariant Bounds, Non-smoothness and Beyond , volume =
-
[56]
Clustered federated learning based on nonconvex pairwise fusion , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.ins.2024.120956 , author =
-
[58]
Song , title =
Lu Tang and Peter X.K. Song , title =. Journal of Machine Learning Research , year =
-
[60]
Journal of the American Statistical Association , volume =
Jing Zeng and Qing Mai and Xin Zhang , title =. Journal of the American Statistical Association , volume =. 2024 , publisher =
2024
-
[61]
, author=
Robust angle-based transfer learning in high dimensions. , author=. Journal of the Royal Statistical Society. Series B, Statistical methodology , year=
-
[62]
Statistica Sinica , year=
Distributed Sufficient Dimension Reduction for Heterogeneous Massive Data , author=. Statistica Sinica , year=
-
[63]
Journal of the American Statistical Association , volume =
Xintao Xia and Linjun Zhang and Zhanrui Cai , title =. Journal of the American Statistical Association , volume =. 2025 , publisher =
2025
-
[64]
Proceedings of the 39th International Conference on Machine Learning , pages =
Sparse Mixed Linear Regression with Guarantees: Taming an Intractable Problem with Invex Relaxation , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[65]
ArXiv , year=
Invex Programs: First Order Algorithms and Their Convergence , author=. ArXiv , year=
-
[66]
Journal of Scientific Computing , volume=
Trace-penalty minimization for large-scale eigenspace computation , author=. Journal of Scientific Computing , volume=. 2016 , publisher=
2016
-
[67]
SIAM Journal on Scientific Computing , volume=
Weighted trace-penalty minimization for full configuration interaction , author=. SIAM Journal on Scientific Computing , volume=. 2024 , publisher=
2024
-
[68]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
An adaptive estimation of dimension reduction space , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2002 , publisher=
2002
-
[69]
A Survey on Multi-Task Learning , year=
Zhang, Yu and Yang, Qiang , journal=. A Survey on Multi-Task Learning , year=
-
[70]
Towards Personalized Federated Learning , year=
Tan, Alysa Ziying and Yu, Han and Cui, Lizhen and Yang, Qiang , journal=. Towards Personalized Federated Learning , year=
-
[71]
Medical hypotheses , volume=
CCNB1 is a prognostic biomarker for ER+ breast cancer , author=. Medical hypotheses , volume=. 2014 , publisher=
2014
-
[72]
BMC cancer , volume=
Elevated cyclin B2 expression in invasive breast carcinoma is associated with unfavorable clinical outcome , author=. BMC cancer , volume=. 2013 , publisher=
2013
-
[73]
Nature communications , volume=
Polycomb complexes associate with enhancers and promote oncogenic transcriptional programs in cancer through multiple mechanisms , author=. Nature communications , volume=. 2018 , publisher=
2018
-
[74]
British journal of cancer , volume=
Cdc20 and securin overexpression predict short-term breast cancer survival , author=. British journal of cancer , volume=. 2014 , publisher=
2014
-
[75]
Cancer Research , volume=
CDC20 is a novel therapeutic target in triple-negative breast cancer , author=. Cancer Research , volume=. 2020 , publisher=
2020
-
[76]
International journal of oncology , volume=
Characterization of KIF20A as a prognostic biomarker and therapeutic target for different subtypes of breast cancer , author=. International journal of oncology , volume=. 2020 , publisher=
2020
-
[77]
Cell cycle , volume=
Role of L2DTL, cell cycle-regulated nuclear and centrosome protein, in Aggressive Hepatocellularcarcinoma , author=. Cell cycle , volume=. 2006 , publisher=
2006
-
[78]
Computational and structural biotechnology journal , volume=
Insights into a crucial role of TRIP13 in human cancer , author=. Computational and structural biotechnology journal , volume=. 2019 , publisher=
2019
-
[79]
Cancers , volume=
Cyclin E2 promotes whole genome doubling in breast cancer , author=. Cancers , volume=. 2020 , publisher=
2020
-
[80]
Oncogene , volume=
Involvement of elevated expression of multiple cell-cycle regulator, DTL/RAMP (denticleless/RA-regulated nuclear matrix associated protein), in the growth of breast cancer cells , author=. Oncogene , volume=. 2008 , publisher=
2008
-
[81]
Journal of cellular biochemistry , volume=
Potentiation of cancerous progression by LISCH7 via direct stimulation of TGFB1 transcription in triple-negative breast cancer , author=. Journal of cellular biochemistry , volume=. 2020 , publisher=
2020
-
[82]
Plos one , volume=
Benchmarking machine learning models on multi-centre eICU critical care dataset , author=. Plos one , volume=. 2020 , publisher=
2020
-
[83]
2017 , publisher=
Ma, Shujie and Huang, Jian , journal=. 2017 , publisher=
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.