Multimodal Continuous Reasoning via Asymmetric Mutual Variational Learning
Pith reviewed 2026-07-02 15:04 UTC · model grok-4.3
The pith
Asymmetric mutual variational learning with dual KL divergences resolves the train-inference mismatch in continuous multimodal reasoning by reducing answer leakage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AMVL resolves the train-inference mismatch via a bidirectional calibration objective with forward and reverse KL divergences, formalizes leakage as prior contamination, proves the dual-KL objective reduces it, and delivers consistent outperformance including +10.83 average on BLINK and up to +32 on individual tasks.
What carries the argument
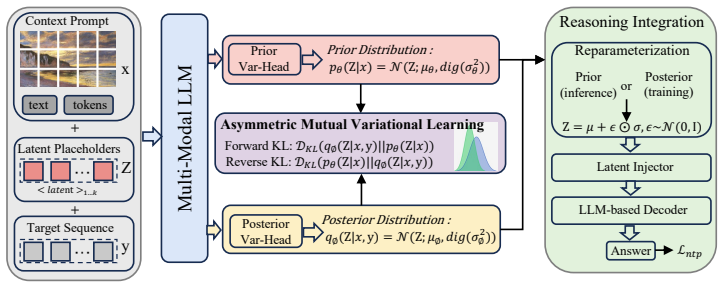
Asymmetric Mutual Variational Learning (AMVL), a bidirectional KL calibration framework that aligns the target-agnostic prior to the answer-conditioned posterior while regularizing the posterior against leakage.
If this is right
- The dual-KL objective yields an average +10.83 improvement on the BLINK benchmark.
- Individual reasoning tasks show gains reaching +32.00 over strong baselines.
- Latent-space stability improves under the bidirectional calibration.
- The method applies directly to latent-integrated multimodal large language models.
Where Pith is reading between the lines
- The same bidirectional calibration could address similar posterior-prior mismatches in other variational multimodal settings.
- Testing AMVL on additional benchmarks with varying degrees of answer leakage would clarify how broadly the reduction holds.
- If the reverse KL regularization generalizes, it may offer a template for stabilizing other continuous reasoning pipelines.
Load-bearing premise
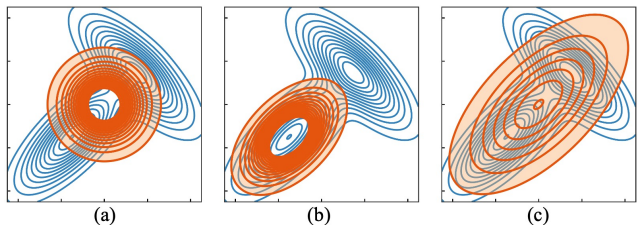
The reverse KL term successfully prevents the posterior from collapsing into regions that are incompatible with inference-time use.
What would settle it
An experiment in which the dual-KL objective produces no gain or new failure modes on held-out reasoning tasks would show the calibration does not reduce leakage as claimed.
Figures

read the original abstract
Multimodal Large Language Models (MLLMs) are often constrained by a language-space bottleneck, forcing complex visual reasoning into discrete tokens which can lose perceptual nuance. A promising alternative is continuous latent reasoning, where the goal is to discover implicit reasoning pathways that bridge the multimodal query and the final answer. However, this introduces a severe train-inference mismatch: a training-time posterior, conditioned on the ground-truth answer, can exploit answer-dependent shortcuts. Standard variational training then forces the inference-time prior to mimic a posterior that has access to information unavailable at test time, leading to poor performance. To address this, we propose Asymmetric Mutual Variational Learning (AMVL), a framework that resolves this mismatch via a bidirectional calibration objective. A forward KL divergence trains the target-agnostic prior to match the posterior, while a novel reverse KL divergence simultaneously regularizes the posterior, preventing it from collapsing into inference-incompatible regions and mitigating this ``answer leakage''. We provide theoretical analysis formalizing this leakage as prior contamination and prove that our dual-KL objective reduces it. We instantiate AMVL in a latent-integrated MLLM and show that it consistently outperforms strong discrete and latent-reasoning baselines, improving the average score on the complex BLINK benchmark by +10.83 and achieving gains of up to +32.00 on individual reasoning tasks, with analyses confirming improved latent-space stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Asymmetric Mutual Variational Learning (AMVL) for continuous latent reasoning in Multimodal Large Language Models (MLLMs). It identifies a train-inference mismatch arising from answer-conditioned posteriors during training and addresses it with a bidirectional calibration objective: forward KL aligns the target-agnostic prior to the posterior, while a novel reverse KL regularizes the posterior to mitigate answer leakage (formalized as prior contamination). The authors provide theoretical analysis and a proof that the dual-KL objective reduces this contamination. They instantiate the method in a latent-integrated MLLM and report consistent outperformance over discrete and latent-reasoning baselines, with +10.83 average improvement on the BLINK benchmark and gains up to +32 on individual tasks, supported by ablation analyses on the reverse KL term and latent-space stability.
Significance. If the theoretical reduction in prior contamination and the empirical gains hold under scrutiny, the work provides a principled variational framework for handling train-inference mismatch in multimodal latent reasoning. The explicit formalization of leakage, the dual-KL construction, and the ablation evidence tying the reverse term to performance gains represent a concrete advance over standard variational training in MLLMs. The reported benchmark improvements on complex reasoning tasks like BLINK, combined with analyses of latent stability, indicate potential utility for other continuous-reasoning architectures.
minor comments (3)
- [§3.2] §3.2, Eq. (7): the notation for the reverse KL term could be clarified with an explicit statement of the support over which the expectation is taken, to avoid ambiguity with the forward KL in Eq. (6).
- [Table 2] Table 2: the BLINK per-task results would benefit from reporting standard deviations across multiple seeds to substantiate the claimed gains of up to +32.
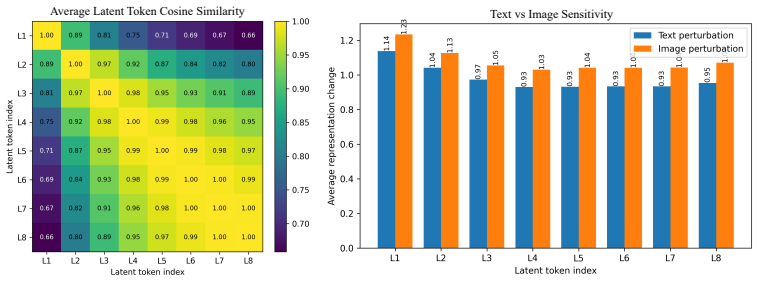
- [§5.3] §5.3: the latent-space stability analysis references cosine similarity but does not specify the exact layer or token positions used for the computation; adding this detail would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work on AMVL, the recognition of its theoretical and empirical contributions, and the recommendation for minor revision. We will prepare a revised manuscript accordingly.
Circularity Check
No significant circularity
full rationale
The paper's central derivation introduces a new bidirectional calibration objective consisting of forward KL (prior to posterior) and reverse KL (posterior regularization) to mitigate answer leakage formalized as prior contamination. The theoretical analysis and proof that the dual-KL objective reduces contamination are presented as a direct consequence of the newly defined objective rather than a reduction to pre-existing fitted quantities or self-referential definitions. No load-bearing steps rely on self-citations for uniqueness theorems, ansatzes, or renamings; the empirical gains are shown via direct comparisons to baselines and ablations on the reverse term. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62(1):1–62, 2022
2022
-
[2]
Dissociating language and thought in large language models.Trends in cognitive sciences, 28(6):517–540, 2024
Kyle Mahowald, Anna A Ivanova, Idan A Blank, Nancy Kanwisher, Joshua B Tenenbaum, and Evelina Fedorenko. Dissociating language and thought in large language models.Trends in cognitive sciences, 28(6):517–540, 2024
2024
-
[3]
Zhongxing Xu, Zhonghua Wang, Zhe Qian, Dachuan Shi, Feilong Tang, Ming Hu, Shiyan Su, Xiaocheng Zou, Wei Feng, Dwarikanath Mahapatra, et al. Thinking in uncertainty: Mitigating hallucinations in mlrms with latent entropy-aware decoding.arXiv preprint arXiv:2603.13366, 2026
-
[4]
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pag...
2024
-
[5]
Latent visual reasoning
Bangzheng Li, Ximeng Sun, Jiang Liu, Ze Wang, Jialian Wu, Xiaodong Yu, Emad Barsoum, Muhao Chen, and Zicheng Liu. Latent visual reasoning. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[6]
Tan-Hanh Pham and Chris Ngo. Multimodal chain of continuous thought for latent-space reasoning in vision-language models.arXiv preprint arXiv:2508.12587, 2025
-
[7]
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens
Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, and Chuang Gan. Machine men- tal imagery: Empower multimodal reasoning with latent visual tokens.arXiv preprint arXiv:2506.17218, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Monet: Reasoning in latent visual space beyond images and language
Qixun Wang, Yang Shi, Yifei Wang, Yuanxing Zhang, Pengfei Wan, Kun Gai, Xianghua Ying, and Yisen Wang. Monet: Reasoning in latent visual space beyond images and language. In CVPR, 2026
2026
-
[9]
Plummer, Kate Saenko, Ranjay Krishna, Leonidas Guibas, and Wen-Sheng Chu
Arijit Ray, Ahmed Abdelkader, Chengzhi Mao, Bryan A. Plummer, Kate Saenko, Ranjay Krishna, Leonidas Guibas, and Wen-Sheng Chu. Mull-tokens: Modality-agnostic latent thinking, 2025
2025
-
[10]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[11]
Learning structured output representation using deep conditional generative models.Advances in neural information processing systems, 28, 2015
Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representation using deep conditional generative models.Advances in neural information processing systems, 28, 2015
2015
-
[12]
Ravr: Reference-answer-guided variational reasoning for large language models
Tianqianjin Lin, Xi Zhao, Xingyao Zhang, Rujiao Long, Yi Xu, Zhuoren Jiang, Wenbo Su, and Bo Zheng. Ravr: Reference-answer-guided variational reasoning for large language models. arXiv preprint arXiv:2510.25206, 2025
-
[13]
Regular: Variational latent reasoning guided by rendered chain-of-thought, 2026
Fanmeng Wang, Haotian Liu, Guojiang Zhao, Hongteng Xu, and Zhifeng Gao. Regular: Variational latent reasoning guided by rendered chain-of-thought, 2026. 10
2026
-
[14]
Minjie Hong, Zirun Guo, Yan Xia, Zehan Wang, Ziang Zhang, Tao Jin, and Zhou Zhao. Apo: Enhancing reasoning ability of mllms via asymmetric policy optimization.arXiv preprint arXiv:2506.21655, 2025
-
[15]
Vlm-r 3: Region recognition, reasoning, and refinement for enhanced multimodal chain-of-thought, 2025
Chaoya Jiang, Yongrui Heng, Wei Ye, Han Yang, Haiyang Xu, Ming Yan, Ji Zhang, Fei Huang, and Shikun Zhang. Vlm-r 3: Region recognition, reasoning, and refinement for enhanced multimodal chain-of-thought, 2025
2025
-
[16]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Mul- timodal chain-of-thought reasoning in language models.arXiv preprint arXiv:2302.00923, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Point-rft: Improving multimodal reasoning with visually grounded reinforcement finetuning, 2025
Minheng Ni, Zhengyuan Yang, Linjie Li, Chung-Ching Lin, Kevin Lin, Wangmeng Zuo, and Lijuan Wang. Point-rft: Improving multimodal reasoning with visually grounded reinforcement finetuning, 2025
2025
-
[18]
Vision-r1: Incentivizing reasoning capability in multimodal large language models
Wenxuan Huang, Bohan Jia, Shaosheng Cao, Zheyu Ye, Fei zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[19]
Perception-aware policy optimization for multimodal reasoning
Zhenhailong Wang, Xuehang Guo, Sofia Stoica, Haiyang Xu, Hongru WANG, Hyeonjeong Ha, Xiusi Chen, Yangyi Chen, Ming Yan, Fei Huang, and Heng Ji. Perception-aware policy optimization for multimodal reasoning. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[20]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Grounded Reinforcement Learning for Visual Reasoning
Gabriel Sarch, Snigdha Saha, Naitik Khandelwal, Ayush Jain, Michael J Tarr, Aviral Kumar, and Katerina Fragkiadaki. Grounded reinforcement learning for visual reasoning.arXiv preprint arXiv:2505.23678, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Xinyan Chen, Renrui Zhang, Dongzhi Jiang, Aojun Zhou, Shilin Yan, Weifeng Lin, and Hongsheng Li. Mint-cot: Enabling interleaved visual tokens in mathematical chain-of-thought reasoning.arXiv preprint arXiv:2506.05331, 2025
-
[23]
Don’t look only once: Towards multimodal interactive reasoning with selective visual revisitation
Jiwan Chung, Junhyeok Kim, Siyeol Kim, Jaeyoung Lee, Min Soo Kim, and Youngjae Yu. Don’t look only once: Towards multimodal interactive reasoning with selective visual revisitation. arXiv e-prints, pages arXiv–2505, 2025
2025
-
[24]
Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl.arXiv e-prints, pages arXiv–2505, 2025
Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, et al. Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl.arXiv e-prints, pages arXiv–2505, 2025
2025
-
[25]
Pixel reasoner: Incentivizing pixel space reasoning via curiosity-driven reinforcement learning
Alex Su, Haozhe Wang, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel space reasoning via curiosity-driven reinforcement learning. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[26]
Deepeyes: Incentivizing ”thinking with images” via reinforcement learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and XingYu. Deepeyes: Incentivizing ”thinking with images” via reinforcement learning. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[27]
Soft tokens, hard truths.arXiv preprint arXiv:2509.19170, 2025
Natasha Butt, Ariel Kwiatkowski, Ismail Labiad, Julia Kempe, and Yann Ollivier. Soft tokens, hard truths.arXiv preprint arXiv:2509.19170, 2025
-
[28]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartold- son, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach.arXiv preprint arXiv:2502.05171, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Codi: Com- pressing chain-of-thought into continuous space via self-distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. Codi: Com- pressing chain-of-thought into continuous space via self-distillation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 677–693, 2025
2025
-
[31]
Jianwei Wang, Ziming Wu, Fuming Lai, Shaobing Lian, and Ziqian Zeng. Synadapt: Learning adaptive reasoning in large language models via synthetic continuous chain-of-thought.arXiv preprint arXiv:2508.00574, 2025
-
[32]
Think before you speak: Training language models with pause tokens, 2024
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens, 2024
2024
-
[33]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space, 2024.URL https://arxiv. org/abs/2412.06769, 98, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Deep unordered composition rivals syntactic methods for text classification
Mohit Iyyer, Varun Manjunatha, Jordan Boyd-Graber, and Hal Daumé III. Deep unordered composition rivals syntactic methods for text classification. InProceedings of the 53rd an- nual meeting of the association for computational linguistics and the 7th international joint conference on natural language processing (volume 1: Long papers), pages 1681–1691, 2015
2015
-
[35]
Lagging Inference Networks and Posterior Collapse in Variational Autoencoders
Junxian He, Daniel Spokoyny, Graham Neubig, and Taylor Berg-Kirkpatrick. Lagging inference networks and posterior collapse in variational autoencoders.arXiv preprint arXiv:1901.05534, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[36]
beta-V AE: Learning basic visual concepts with a constrained variational framework
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-V AE: Learning basic visual concepts with a constrained variational framework. InInternational Conference on Learning Representations, 2017
2017
-
[37]
Amortizing intractable inference in large language models.arXiv preprint arXiv:2310.04363, 2023
Edward J Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, and Nikolay Malkin. Amortizing intractable inference in large language models.arXiv preprint arXiv:2310.04363, 2023
-
[38]
Variational reasoning for language models.arXiv preprint arXiv:2509.22637, 2025
Xiangxin Zhou, Zichen Liu, Haonan Wang, Chao Du, Min Lin, Chongxuan Li, Liang Wang, and Tianyu Pang. Variational reasoning for language models.arXiv preprint arXiv:2509.22637, 2025
-
[39]
Deep mutual learning
Ying Zhang, Tao Xiang, Timothy M Hospedales, and Huchuan Lu. Deep mutual learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4320–4328, 2018
2018
-
[40]
Generating sentences from a continuous space
Samuel Bowman, Luke Vilnis, Oriol Vinyals, Andrew Dai, Rafal Jozefowicz, and Samy Bengio. Generating sentences from a continuous space. InProceedings of the 20th SIGNLL conference on computational natural language learning, pages 10–21, 2016
2016
-
[41]
Learning discourse-level diversity for neural dialog models using conditional variational autoencoders
Tiancheng Zhao, Ran Zhao, and Maxine Eskenazi. Learning discourse-level diversity for neural dialog models using conditional variational autoencoders. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 654–664, 2017
2017
-
[42]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[43]
Root mean square layer normalization.Advances in neural information processing systems, 32, 2019
Biao Zhang and Rico Sennrich. Root mean square layer normalization.Advances in neural information processing systems, 32, 2019
2019
-
[44]
Stochastic backpropagation and approximate inference in deep generative models
Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic backpropagation and approximate inference in deep generative models. InInternational conference on machine learning, pages 1278–1286. PMLR, 2014
2014
-
[45]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025. 12
2025
-
[46]
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Unleashing chain-of-thought reasoning in multi-modal language models.arXiv preprint arXiv:2403.16999, 2, 2024
-
[47]
Refocus: Visual editing as a chain of thought for structured image understanding
Xingyu Fu, Minqian Liu, Zhengyuan Yang, John Richard Corring, Yijuan Lu, Jianwei Yang, Dan Roth, Dinei Florencio, and Cha Zhang. Refocus: Visual editing as a chain of thought for structured image understanding. InInternational Conference on Machine Learning, pages 17783–17805. PMLR, 2025
2025
-
[48]
Cogcom: A visual language model with chain-of-manipulations reasoning
Ji Qi, Ming Ding, Weihan Wang, Yushi Bai, Qingsong Lv, Wenyi Hong, Bin Xu, Lei Hou, Juanzi Li, Yuxiao Dong, and Jie Tang. Cogcom: A visual language model with chain-of-manipulations reasoning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[49]
Wang, Deqing Fu, Kaiyu Yue, Zikui Cai, Wang Bill Zhu, Ollie Liu, Peng Guo, Willie Neiswanger, Furong Huang, Tom Goldstein, and Micah Goldblum
Ang Li, Charles L. Wang, Deqing Fu, Kaiyu Yue, Zikui Cai, Wang Bill Zhu, Ollie Liu, Peng Guo, Willie Neiswanger, Furong Huang, Tom Goldstein, and Micah Goldblum. Zebra-cot: A dataset for interleaved vision-language reasoning. InThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[50]
V?: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V?: Guided visual search as a core mechanism in multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084–13094, 2024
2024
-
[51]
Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models, 2024
Wenbin Wang, Liang Ding, Minyan Zeng, Xiabin Zhou, Li Shen, Yong Luo, and Dacheng Tao. Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models, 2024
2024
-
[52]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024
2024
-
[53]
Preventing Posterior Collapse with delta-VAEs
Ali Razavi, Aäron van den Oord, Ben Poole, and Oriol Vinyals. Preventing posterior collapse with delta-vaes.arXiv preprint arXiv:1901.03416, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[54]
Z-forcing: Training stochastic recurrent networks.Advances in neural information processing systems, 30, 2017
Anirudh Goyal ALIAS PARTH GOY AL, Alessandro Sordoni, Marc-Alexandre Côté, Nan Rose- mary Ke, and Yoshua Bengio. Z-forcing: Training stochastic recurrent networks.Advances in neural information processing systems, 30, 2017
2017
-
[55]
Towards Deeper Understanding of Variational Autoencoding Models
Shengjia Zhao, Jiaming Song, and Stefano Ermon. Towards deeper understanding of variational autoencoding models.arXiv preprint arXiv:1702.08658, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[56]
wake-sleep
Geoffrey E Hinton, Peter Dayan, Brendan J Frey, and Radford M Neal. The" wake-sleep" algorithm for unsupervised neural networks.Science, 268(5214):1158–1161, 1995
1995
-
[57]
Sandwiching the marginal likelihood using bidirectional Monte Carlo
Roger B Grosse, Zoubin Ghahramani, and Ryan P Adams. Sandwiching the marginal likelihood using bidirectional monte carlo.arXiv preprint arXiv:1511.02543, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[58]
Divergence measures and message passing, 2005
Tom Minka et al. Divergence measures and message passing, 2005
2005
-
[59]
Springer, 2006
Christopher M Bishop and Nasser M Nasrabadi.Pattern recognition and machine learning. Springer, 2006
2006
-
[60]
Elbo surgery: yet another way to carve up the variational evidence lower bound
Matthew D Hoffman and Matthew J Johnson. Elbo surgery: yet another way to carve up the variational evidence lower bound. InWorkshop in advances in approximate Bayesian inference, NIPS, volume 1, 2016
2016
-
[61]
InfoVAE: Information Maximizing Variational Autoencoders
Shengjia Zhao, Jiaming Song, and Stefano Ermon. Infovae: Information maximizing variational autoencoders.arXiv preprint arXiv:1706.02262, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[62]
Fixing a broken elbo
Alexander Alemi, Ben Poole, Ian Fischer, Joshua Dillon, Rif A Saurous, and Kevin Murphy. Fixing a broken elbo. InInternational conference on machine learning, pages 159–168. PMLR, 2018. 13
2018
-
[63]
Pangea: A fully open multilingual multimodal llm for 39 languages
Xiang Yue, Yueqi Song, Akari Asai, Seungone Kim, Jean de Dieu Nyandwi, Simran Khanuja, Anjali Kantharuban, Lintang Sutawika, Sathyanarayanan Ramamoorthy, and Graham Neu- big. Pangea: A fully open multilingual multimodal llm for 39 languages. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[64]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024. 14 A Main Notation Introduction For clarity, Table 5 summarizes the main notations used throughout the paper. Table 5: Meanings of the main notations ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.