Multi-Turn Agentic Scientific Literature Search via Workflow Induction
Pith reviewed 2026-07-02 13:12 UTC · model grok-4.3
The pith
Representing literature search as induction of editable operator workflows improves multi-turn agent performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
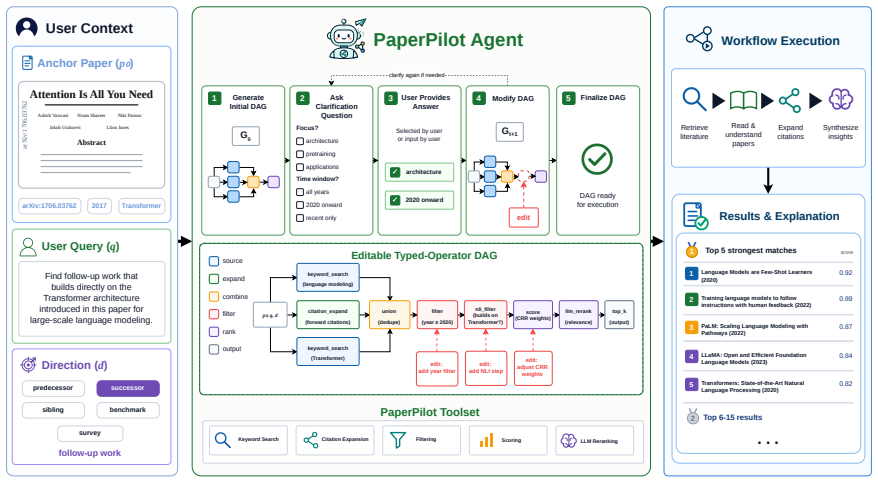
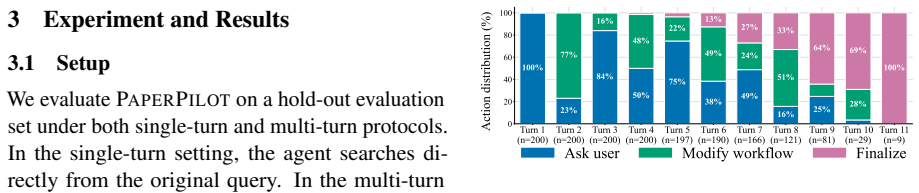
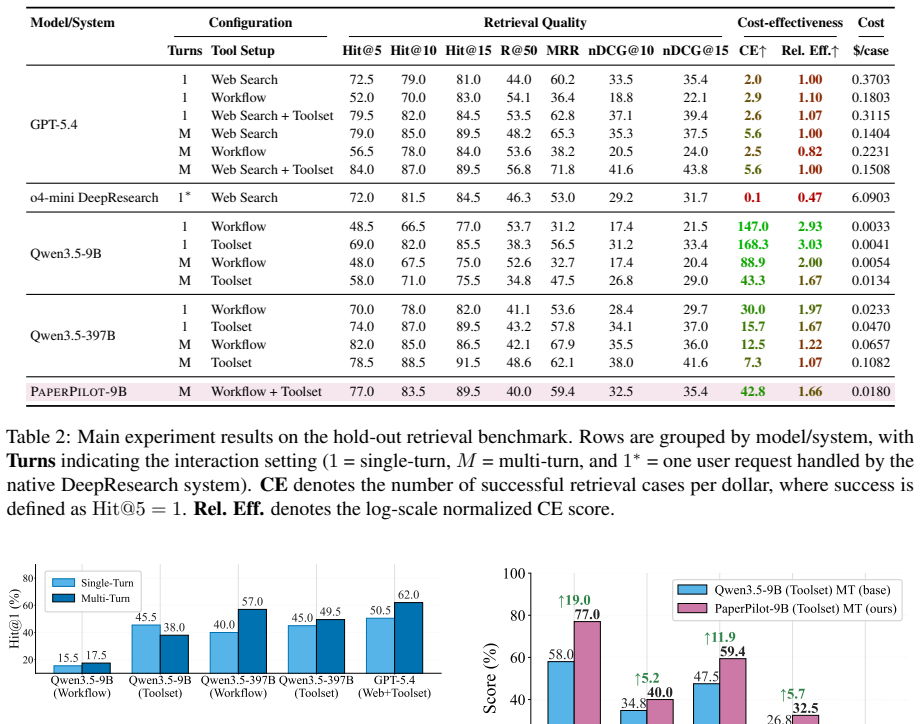
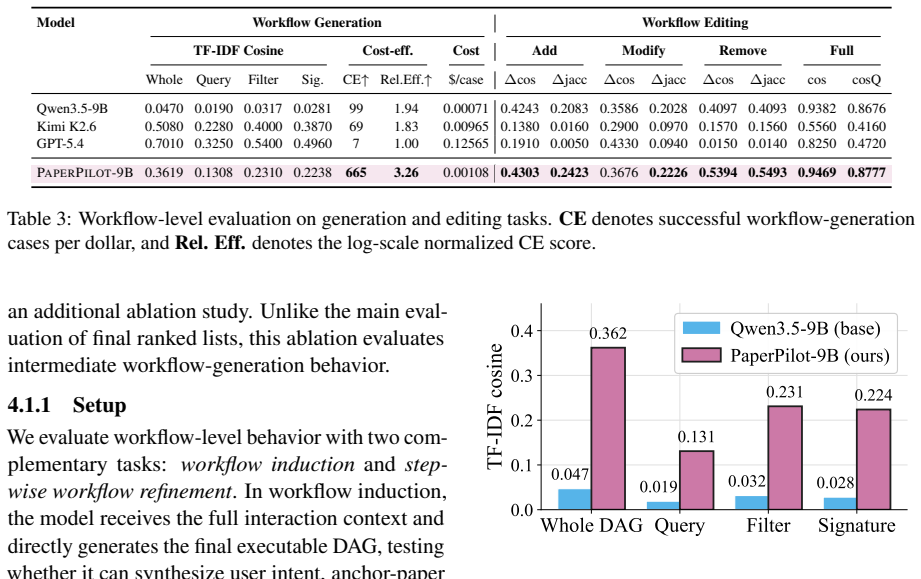
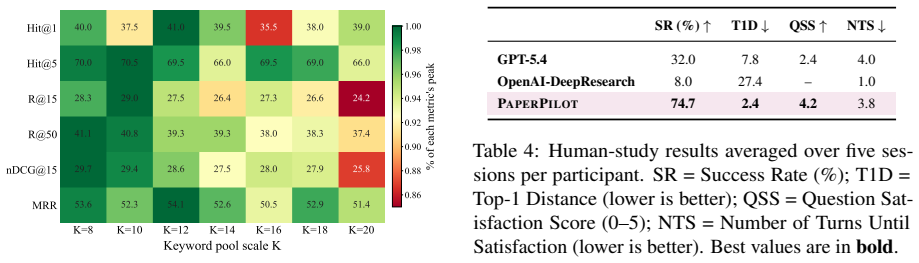
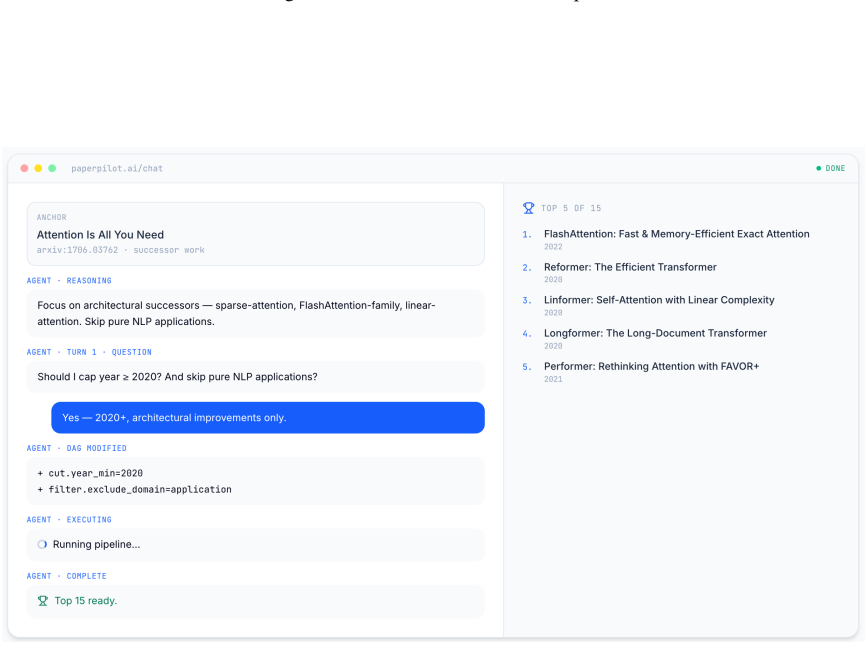
PaperPilot constructs an executable DAG of paper-search operators given an anchor paper and a user query, then uses feedback to refine both the query and the workflow itself; training via supervised workflow imitation and preference optimization over controlled corruptions produces an agent that raises Hit@5 from 58.0 to 77.0, MRR from 47.5 to 59.4, and nDCG@10 from 26.8 to 32.5 while cutting workflow execution errors from 9.5 percent to zero.
What carries the argument
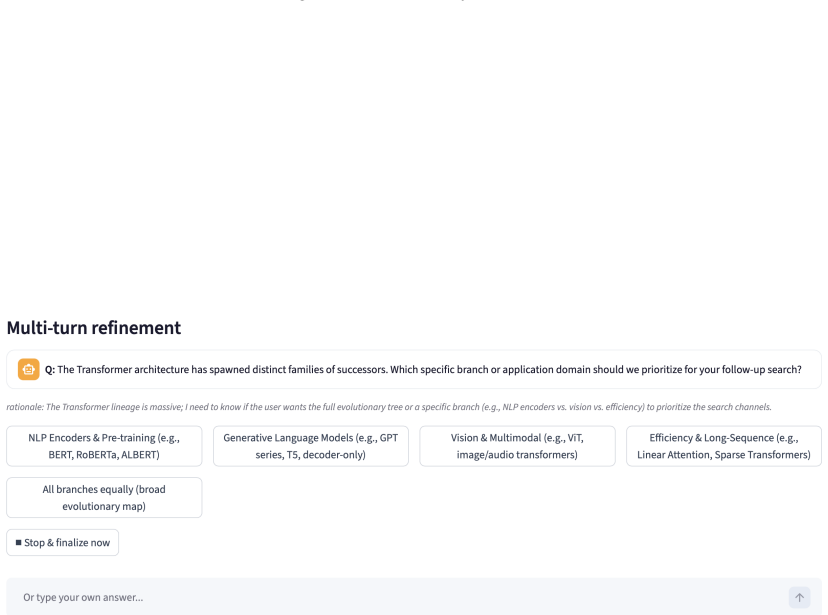
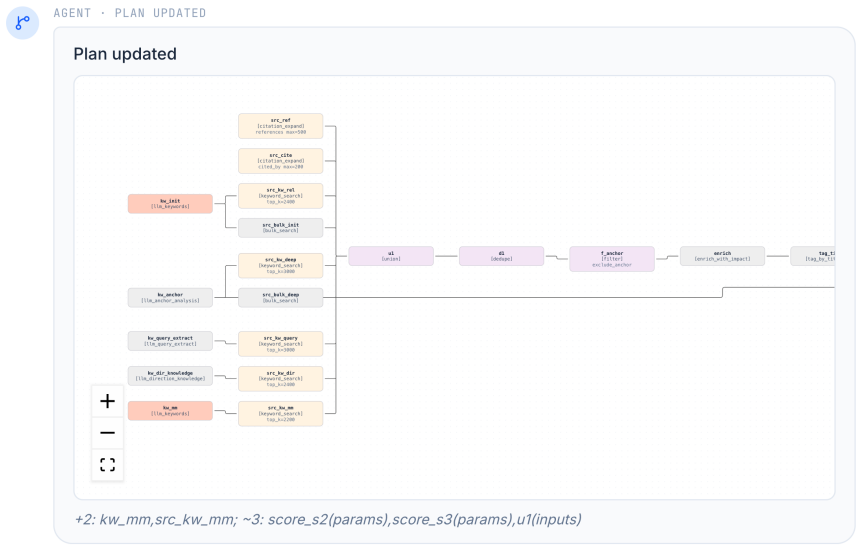
Workflow induction into an executable DAG of operators (keyword search, citation expansion, filtering, scoring, reranking, evidence extraction) that makes the search strategy explicit, inspectable, and refinable through user feedback.
If this is right
- Explicit workflows make search strategies controllable and inspectable rather than opaque.
- Multi-turn user feedback can directly edit both the query and the induced workflow.
- Retrieval metrics improve while workflow execution errors drop to zero.
- The method supplies a controllable interface for aligning agents with complex scientific intent.
Where Pith is reading between the lines
- The same induction method could be tested on agent tasks outside literature search once suitable operator sets are defined.
- Human review of the induced DAGs could serve as a debugging and trust mechanism for agent outputs.
- Failure cases on intents outside the current operator vocabulary would directly bound the method's coverage.
Load-bearing premise
The chosen set of paper-search operators is expressive enough to represent complex, evolving scientific search intents.
What would settle it
A multi-turn literature search task whose required behavior cannot be expressed by any sequence of the listed operators, so that even a correctly induced workflow fails to satisfy the intent.
Figures


read the original abstract
Scientific literature search often requires more than retrieving papers from a single query: users' intents are underspecified, preference-dependent, and evolve through interaction. Existing search agents typically rely on fixed pipelines or implicit language-only reasoning, making their search strategies difficult to control, inspect, and refine. We introduce PaperPilot, a multi-turn literature search agent that frames scientific search as workflow induction. Given an anchor paper and a user query, PaperPilot constructs an executable DAG of paper-search operators, including keyword search, citation expansion, filtering, scoring, reranking, and evidence extraction. User feedback is then used to refine both the query and the workflow itself. We train PaperPilot with supervised workflow imitation and preference optimization over controlled workflow corruptions. Experiments show that PaperPilot-9B improves over the base Qwen3.5-9B toolset agent under multi-turn interaction, increasing Hit@5 from 58.0 to 77.0, MRR from 47.5 to 59.4, and nDCG@10 from 26.8 to 32.5, while reducing workflow execution errors from 9.5% to 0%. These results show that explicit, editable search workflows provide an effective and controllable interface for aligning literature search agents with complex scientific intent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PaperPilot, a multi-turn literature search agent that frames scientific search as workflow induction: given an anchor paper and user query, it constructs an executable DAG over a fixed set of operators (keyword search, citation expansion, filtering, scoring, reranking, evidence extraction), refines the workflow and query from user feedback, and is trained via supervised workflow imitation plus preference optimization over controlled corruptions. Experiments report that the 9B model improves over a base Qwen3.5-9B toolset agent, raising Hit@5 from 58.0 to 77.0, MRR from 47.5 to 59.4, and nDCG@10 from 26.8 to 32.5 while dropping workflow execution errors from 9.5% to 0%.
Significance. If the empirical gains prove robust, the explicit, editable DAG workflow approach supplies a controllable and inspectable interface for aligning agents with underspecified, preference-dependent, and evolving scientific intents, offering a concrete alternative to purely implicit language-based reasoning.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the reported metric gains (Hit@5 58.0→77.0, MRR 47.5→59.4, nDCG@10 26.8→32.5, error rate 9.5%→0%) are presented without any description of dataset construction, statistical significance tests, baseline implementation details, or potential confounds; these omissions make the central empirical claim unverifiable from the supplied information.
- [Abstract] Abstract: the claim that the fixed operator vocabulary (keyword search, citation expansion, filtering, scoring, reranking, evidence extraction) suffices for arbitrary complex, evolving scientific intents is load-bearing for the workflow-induction framing, yet no experiments or analysis address coverage on intents requiring operators outside this set (e.g., temporal filtering across dates or cross-field analogy detection).
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important issues of verifiability and scope. We address each major comment below and commit to revisions that improve transparency without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the reported metric gains (Hit@5 58.0→77.0, MRR 47.5→59.4, nDCG@10 26.8→32.5, error rate 9.5%→0%) are presented without any description of dataset construction, statistical significance tests, baseline implementation details, or potential confounds; these omissions make the central empirical claim unverifiable from the supplied information.
Authors: We agree that the abstract and Experiments section omit key details required for independent verification. The full manuscript contains the underlying dataset and baseline code, but these were not sufficiently summarized. In the revision we will expand the Experiments section with: (1) a complete description of dataset construction and split statistics, (2) implementation details for all baselines including prompt templates and tool-use configurations, (3) results of paired statistical significance tests (e.g., bootstrap or McNemar), and (4) explicit discussion of potential confounds such as query distribution and interaction length. Corresponding clarifications will be added to the abstract. revision: yes
-
Referee: [Abstract] Abstract: the claim that the fixed operator vocabulary (keyword search, citation expansion, filtering, scoring, reranking, evidence extraction) suffices for arbitrary complex, evolving scientific intents is load-bearing for the workflow-induction framing, yet no experiments or analysis address coverage on intents requiring operators outside this set (e.g., temporal filtering across dates or cross-field analogy detection).
Authors: The abstract does not claim the operator set covers every conceivable scientific intent; it states that the set enables controllable alignment with the complex intents arising in our multi-turn literature-search setting. We acknowledge that no dedicated coverage analysis for out-of-vocabulary operators (temporal filtering, cross-field analogy, etc.) is provided. In revision we will (a) rephrase the abstract to avoid any implication of universal coverage and (b) add a dedicated limitations paragraph that enumerates the current operator vocabulary, justifies its selection from observed user intents, and outlines straightforward extensions for missing operators. No new experiments are planned for this revision. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper frames literature search as workflow induction over a fixed operator set and reports empirical gains from supervised imitation plus preference optimization. No equations, derivations, or load-bearing self-citations appear; all central claims reduce to direct comparisons against an external baseline (Qwen3.5-9B toolset agent) on held-out metrics. The operator vocabulary is an explicit modeling choice, not derived from the results themselves, so no reduction by construction occurs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
AdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints , author=. arXiv preprint arXiv:2606.05622 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
CostBench: Evaluating Multi-Turn Cost-Optimal Planning and Adaptation in Dynamic Environments for LLM Tool-Use Agents , author=. arXiv preprint arXiv:2511.02734 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
NOVA: NOise-aware Verbal Confidence CAlibration for Robust Large Language Models in RAG Systems
NAACL: Noise-AwAre Verbal Confidence Calibration for LLMs in RAG Systems , author=. arXiv preprint arXiv:2601.11004 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Publications Manual , year = "1983", publisher =
1983
-
[6]
NOVA: NOise-aware Verbal Confidence CAlibration for Robust Large Language Models in RAG Systems
Jiayu Liu and Rui Wang and Qing Zong and Qingcheng Zeng and Tianshi Zheng and Haochen Shi and Dadi Guo and Baixuan Xu and Chunyang Li and Yangqiu Song , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2601.11004 , eprinttype =. 2601.11004 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.11004 2026
-
[7]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[8]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[9]
Dan Gusfield , title =. 1997
1997
-
[10]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[11]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[12]
BioInsight: Multi-Agent Orchestration for Interactive Biomedical Knowledge Discovery
BioInsight: Multi-Agent Orchestration for Interactive Biomedical Knowledge Discovery , author=. arXiv preprint arXiv:2606.20997 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Control Large Language Models via Divide and Conquer
Li, Bingxuan and Wang, Yiwei and Meng, Tao and Chang, Kai-Wei and Peng, Nanyun. Control Large Language Models via Divide and Conquer. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.850
-
[14]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Li, Bingxuan and Cui, Yiming and He, Yicheng and Wang, Yiwei and Zhang, Shu and Wen, Longyin and Niu, Yulei , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2026 , pages =
2026
-
[15]
arXiv preprint arXiv:2603.07978 , year=
Osexpert: Computer-use agents learning professional skills via exploration , author=. arXiv preprint arXiv:2603.07978 , year=
-
[16]
METAL : A Multi-Agent Framework for Chart Generation with Test-Time Scaling
Li, Bingxuan and Wang, Yiwei and Gu, Jiuxiang and Chang, Kai-Wei and Peng, Nanyun. METAL : A Multi-Agent Framework for Chart Generation with Test-Time Scaling. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1452
-
[17]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[20]
and Moazam, Hanna and Miller, Heather and Zaharia, Matei and Potts, Christopher , booktitle =
Khattab, Omar and Singhvi, Arnav and Maheshwari, Paridhi and Zhang, Zhiyuan and Santhanam, Keshav and Vardhamanan, Sri and Haq, Saiful and Sharma, Ashutosh and Joshi, Thomas T. and Moazam, Hanna and Miller, Heather and Zaharia, Matei and Potts, Christopher , booktitle =
-
[21]
Zhang, Jiayi and Xiang, Jinyu and Yu, Zhaoyang and Teng, Fengwei and Chen, Xionghui and Chen, Jiaqi and Zhuge, Mingchen and Cheng, Xin and Hong, Sirui and Wang, Jinlin and Zheng, Bingnan and Liu, Bang and Luo, Yuyu and Wu, Chenglin , booktitle =
-
[22]
PEARL: Self-Evolving Assistant for Time Management with Reinforcement Learning
PEARL: Self-Evolving Assistant for Time Management with Reinforcement Learning , author=. arXiv preprint arXiv:2601.11957 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Search-o1: Agentic Search-Enhanced Large Reasoning Models , author =. arXiv preprint arXiv:2501.05366 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
2025 , howpublished =
2025
-
[25]
Li, Yutong and Yuan, Lu and Chen, Yuming and Wang, Pengfei and Zhang, Ningyu , journal =
-
[26]
Lu, Chris and Lu, Cong and Lange, Robert Tjarko and Foerster, Jakob and Clune, Jeff and Ha, David , journal =. The
-
[27]
Li, Kaichen and Zhao, Tian and Yang, Quanyu and Wu, Yong and Cao, Yu , journal =
-
[28]
Whitfield, Sonia and Hofmann, Matthew Axel , journal =. Elicit:
-
[29]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Symbolic representation for any-to-any generative tasks , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[30]
arXiv preprint arXiv:2402.01788 , year=
Litllm: A toolkit for scientific literature review , author=. arXiv preprint arXiv:2402.01788 , year=
-
[31]
Language agents achieve superhuman synthesis of scientific knowledge , author=. arXiv preprint arXiv:2409.13740 , year=
-
[32]
arXiv preprint arXiv:2411.14199 , year=
Openscholar: Synthesizing scientific literature with retrieval-augmented lms , author=. arXiv preprint arXiv:2411.14199 , year=
-
[33]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Pasa: An llm agent for comprehensive academic paper search , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[34]
Researchagent: Iterative research idea generation over scientific literature with large language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[35]
arXiv preprint arXiv:2405.15784 , year=
Clarinet: Augmenting language models to ask clarification questions for retrieval , author=. arXiv preprint arXiv:2405.15784 , year=
-
[36]
Proceedings of the web conference 2020 , pages=
Generating clarifying questions for information retrieval , author=. Proceedings of the web conference 2020 , pages=
2020
-
[37]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Assisting in writing wikipedia-like articles from scratch with large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[38]
Advances in neural information processing systems , volume=
Autosurvey: Large language models can automatically write surveys , author=. Advances in neural information processing systems , volume=
-
[39]
2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.