Self-conditioned Flow Map Language Models via Fixed-point Flows
Pith reviewed 2026-07-02 12:59 UTC · model grok-4.3
The pith
Self-conditioned flow language models solve a fixed-point iteration that bootstraps the denoiser and enables distillation to strong one-step models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Flow language models with self-conditioning solve a fixed-point iteration that bootstraps the performance of the learned denoiser. Fixed-point flows define valid flow maps and can be distilled from self-conditioned models by compressing fixed-point iterations and the flow process, with FMLM* outperforming state-of-the-art self-conditioned models and few-step models in one- and few-step generation on OpenWebText.
What carries the argument
Fixed-point flows, a two-dimensional class of self-conditioned flows with one dimension for the flow process and one for the fixed-point iteration.
If this is right
- Fixed-point flows define valid flow maps.
- Self-conditioned models can be distilled into flow map language models via fixed-point distillation and flow map distillation.
- The distilled FMLM* outperforms state-of-the-art self-conditioned models and few-step models in one- and few-step generation on OpenWebText.
- The performance gains of self-conditioning arise from bootstrapping the denoiser through the fixed-point iteration.
Where Pith is reading between the lines
- The fixed-point view might extend to self-conditioning techniques used in non-language generative models such as images or audio.
- Explicit optimization of the fixed-point structure during training could yield further gains beyond current distillation.
- Flow map distillation may reduce inference latency enough to enable real-time applications that current iterative models cannot support.
- The correspondence between self-conditioning and fixed-point iteration could help analyze convergence rates in other iterative generative processes.
Load-bearing premise
That self-conditioning exactly matches a fixed-point iteration and that the proposed distillation steps preserve performance without extra assumptions on the denoiser or data.
What would settle it
Training a flow language model without self-conditioning and measuring whether its one-step generation performance matches or exceeds the self-conditioned version on the same benchmark.
Figures




read the original abstract
Self-conditioning is a core technique that enhances continuous flow-based language models, where the model learns to denoise generated text by conditioning on its own denoising estimate. While empirically successful, its performance improvements are poorly understood. Moreover, there is growing interest in the use of few-step generators based on flow maps, for which how to leverage self-conditioning is unclear. Here, we show that flow language models with self-conditioning solve a fixed-point iteration that bootstraps the performance of the learned denoiser. We use this viewpoint to formulate fixed-point flows, a two-dimensional class of self-conditioned flows, where the first dimension represents the flow process and the second represents the fixed-point iteration. We show that fixed-point flows define valid flow maps, and show that they can be distilled from self-conditioned flow models by compressing both fixed-point iterations and the flow process, the former with fixed-point distillation and the latter with flow map distillation. Our resulting flow map language model, FMLM$^\star$, outperforms state-of-the-art self-conditioned models and few-step models in one- and few-step generation on OpenWebText. Code is available at https://github.com/Ugness/self-conditioned-fmlm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that self-conditioning in flow language models corresponds to a fixed-point iteration bootstrapping the denoiser, introduces fixed-point flows as a two-dimensional class of self-conditioned flows (one dimension for the flow process, one for the iteration), proves these define valid flow maps, and shows they can be distilled from self-conditioned models via fixed-point distillation and flow-map distillation to yield FMLM* which outperforms SOTA self-conditioned and few-step models on one- and few-step generation on OpenWebText. Code is released.
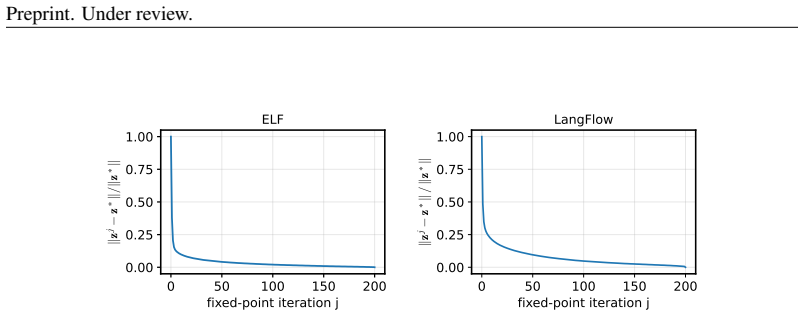
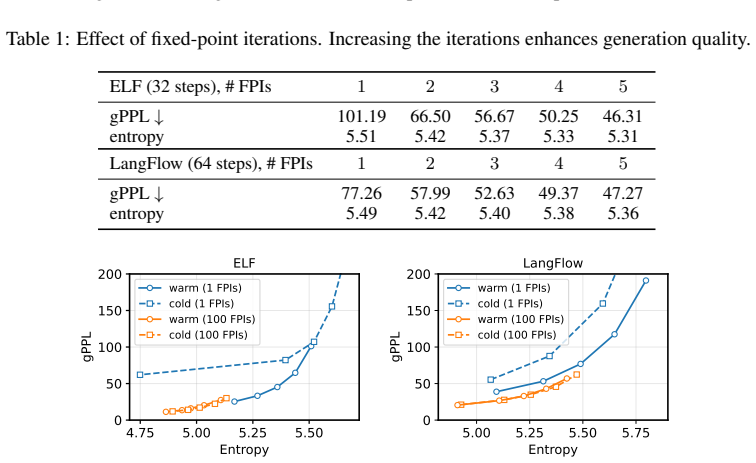
Significance. If the fixed-point equivalence and distillation preservation hold without unstated assumptions on the denoiser (e.g., contraction properties), the work supplies a theoretical grounding for an empirical technique and a route to efficient few-step flow-map LMs. Public code is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that self-conditioning 'exactly' solves a fixed-point iteration (bootstrapping the denoiser) is asserted without an explicit derivation or statement of the required conditions (e.g., Lipschitz continuity or contraction mapping on the discrete token embedding space). This equivalence is load-bearing for both the 2D fixed-point flow construction and the subsequent distillation claims; if it is only approximate, the validity of the flow maps and the performance preservation in FMLM* do not follow.
- [Abstract] Abstract (distillation paragraph): the statement that fixed-point flows 'can be distilled ... by compressing both fixed-point iterations and the flow process' with no loss of validity or performance is presented without the precise compression operators or any verification that the resulting map remains a valid flow map. This is load-bearing for the claim that FMLM* outperforms baselines.
minor comments (1)
- The abstract mentions 'continuous flow-based language models' but does not clarify how the discrete token nature interacts with the continuous flow formulation; a brief note on embedding/rounding would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We respond to each major comment below and indicate where revisions will be made to improve clarity without altering the core technical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that self-conditioning 'exactly' solves a fixed-point iteration (bootstrapping the denoiser) is asserted without an explicit derivation or statement of the required conditions (e.g., Lipschitz continuity or contraction mapping on the discrete token embedding space). This equivalence is load-bearing for both the 2D fixed-point flow construction and the subsequent distillation claims; if it is only approximate, the validity of the flow maps and the performance preservation in FMLM* do not follow.
Authors: Section 3 of the manuscript provides the explicit derivation establishing that self-conditioning corresponds to a fixed-point iteration, under the assumption that the denoiser acts as a contraction mapping on the token embedding space. The abstract summarizes this result at a high level. We agree that referencing the key condition would strengthen the abstract and will revise it accordingly in the next version to state the contraction mapping requirement. revision: yes
-
Referee: [Abstract] Abstract (distillation paragraph): the statement that fixed-point flows 'can be distilled ... by compressing both fixed-point iterations and the flow process' with no loss of validity or performance is presented without the precise compression operators or any verification that the resulting map remains a valid flow map. This is load-bearing for the claim that FMLM* outperforms baselines.
Authors: Sections 4 and 5 define the fixed-point distillation and flow-map distillation operators and include proofs that the resulting map remains a valid flow map with preserved performance. The abstract provides a concise overview. We will revise the abstract to note that validity and performance are preserved under the operators defined in the main text. revision: yes
Circularity Check
Self-conditioning to fixed-point iteration equivalence and distillation by construction
specific steps
-
self definitional
[Abstract]
"we show that flow language models with self-conditioning solve a fixed-point iteration that bootstraps the performance of the learned denoiser. We use this viewpoint to formulate fixed-point flows, a two-dimensional class of self-conditioned flows, where the first dimension represents the flow process and the second represents the fixed-point iteration."
The paper presents the equivalence of self-conditioning to a fixed-point iteration as a result to be shown, then immediately uses 'this viewpoint' to define the new two-dimensional class. The bootstrapping performance is thereby tied directly to the iteration that is itself the self-conditioning mechanism, making the derivation self-definitional rather than independently derived.
-
fitted input called prediction
[Abstract]
"We show that fixed-point flows define valid flow maps, and show that they can be distilled from self-conditioned flow models by compressing both fixed-point iterations and the flow process, the former with fixed-point distillation and the latter with flow map distillation. Our resulting flow map language model, FMLM*, outperforms state-of-the-art self-conditioned models and few-step models"
The distillation (fixed-point and flow map) is defined by compressing the iterations and process already present in the self-conditioned model; the claim that FMLM* outperforms is then presented as a prediction, but the construction ensures the distilled model inherits the original mechanisms by design.
full rationale
The paper's central claim equates self-conditioning with solving a fixed-point iteration and then uses that to define fixed-point flows and their distillation. This equivalence is asserted in the abstract as something 'shown,' but the provided text frames it as a viewpoint that directly motivates the new formulation and compression steps without external grounding or independent verification of the iteration property. Distillation is presented as preserving validity by compressing the same mechanisms, risking reduction to rephrasing. This yields partial circularity on the load-bearing claims, though the paper may contain independent empirical results on OpenWebText.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Georgios Batzolis, Mark Girolami, and Luca Ambrogioni. Towards closing the autoregressive gap in language modeling via entropy-gated continuous bitstream diffusion.arXiv preprint arXiv:2605.07013,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Spherical Flows for Sampling Categorical Data
10 Preprint. Under review. Jannis Chemseddine, Gregor Kornhardt, and Gabriele Steidl. Spherical flows for sampling categorical data.arXiv preprint arXiv:2605.05629,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Ting Chen, Ruixiang Zhang, and Geoffrey Hinton. Analog bits: Generating discrete data using diffusion models with self-conditioning.arXiv preprint arXiv:2208.04202,
-
[4]
LangFlow: Continuous Diffusion Rivals Discrete in Language Modeling
Yuxin Chen, Chumeng Liang, Hangke Sui, Ruihan Guo, Chaoran Cheng, Jiaxuan You, and Ge Liu. Langflow: Continuous diffusion rivals discrete in language modeling.arXiv preprint arXiv:2604.11748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Beyond autoregression: Fast llms via self-distillation through time.arXiv preprint arXiv:2410.21035,
Justin Deschenaux and Caglar Gulcehre. Beyond autoregression: Fast llms via self-distillation through time.arXiv preprint arXiv:2410.21035,
-
[6]
Language Modeling with Hyperspherical Flows
Justin Deschenaux and Caglar Gulcehre. Language modeling with hyperspherical flows.arXiv preprint arXiv:2605.11125,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Continuous diffusion for categorical data
Sander Dieleman, Laurent Sartran, Arman Roshannai, Nikolay Savinov, Yaroslav Ganin, Pierre H Richemond, Arnaud Doucet, Robin Strudel, Chris Dyer, Conor Durkan, et al. Continuous diffusion for categorical data.arXiv preprint arXiv:2211.15089,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Distillation of discrete diffusion through dimensional correlations.arXiv preprint arXiv:2410.08709,
Satoshi Hayakawa, Yuhta Takida, Masaaki Imaizumi, Hiromi Wakaki, and Yuki Mitsufuji. Distillation of discrete diffusion through dimensional correlations.arXiv preprint arXiv:2410.08709,
-
[9]
Keya Hu, Linlu Qiu, Yiyang Lu, Hanhong Zhao, Tianhong Li, Yoon Kim, Jacob Andreas, and Kaiming He. Elf: Embedded language flows.arXiv preprint arXiv:2605.10938,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Numerical methods for mean field games and mean field type control.arXiv preprint arXiv:2106.06231,
Mathieu Lauriere. Numerical methods for mean field games and mean field type control.arXiv preprint arXiv:2106.06231,
-
[11]
Flow Map Language Models: One-step Language Modeling via Continuous Denoising
Chanhyuk Lee, Jaehoon Yoo, Manan Agarwal, Sheel Shah, Jerry Huang, Aditi Raghunathan, Se- unghoon Hong, Nicholas M Boffi, and Jinwoo Kim. Flow map language models: One-step language modeling via continuous denoising.arXiv preprint arXiv:2602.16813,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Consistency Deep Equilibrium Models
Junchao Lin, Zenan Ling, Jingwen Xu, and Robert C Qiu. Consistency deep equilibrium models. arXiv preprint arXiv:2602.03024,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
One-step Latent-free Image Generation with Pixel Mean Flows
Yiyang Lu, Susie Lu, Qiao Sun, Hanhong Zhao, Zhicheng Jiang, Xianbang Wang, Tianhong Li, Zhengyang Geng, and Kaiming He. One-step latent-free image generation with pixel mean flows. arXiv preprint arXiv:2601.22158,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
How to Train Your Latent Diffusion Language Model Jointly With the Latent Space
11 Preprint. Under review. Viacheslav Meshchaninov, Alexander Shabalin, Egor Chimbulatov, Nikita Gushchin, Ilya Koziev, Alexander Korotin, and Dmitry Vetrov. How to train your latent diffusion language model jointly with the latent space.arXiv preprint arXiv:2605.07933,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Fixed-Point Reasoners: Stable and Adaptive Deep Looped Transformers
Sajad Movahedi, Vera Milovanovi ´c, Shlomo Libo Feigin, Alexander Theus, Thomas Hofmann, Valentina Boeva, T Konstantin Rusch, and Antonio Orvieto. Fixed-point reasoners: Stable and adaptive deep looped transformers.arXiv preprint arXiv:2606.18206,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Peter Potaptchik, Jason Yim, Adhi Saravanan, Peter Holderrieth, Eric Vanden-Eijnden, and Michael S Albergo. Discrete flow maps.arXiv preprint arXiv:2604.09784,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Candi: Hybrid discrete-continuous diffusion models
Patrick Pynadath, Jiaxin Shi, and Ruqi Zhang. Candi: Hybrid discrete-continuous diffusion models. arXiv preprint arXiv:2510.22510,
-
[19]
Categorical flow maps.arXiv preprint arXiv:2602.12233,
Daan Roos, Oscar Davis, Floor Eijkelboom, Michael Bronstein, Max Welling, Ismail Ilkan Cey- lan, Luca Ambrogioni, and Jan-Willem van de Meent. Categorical flow maps.arXiv preprint arXiv:2602.12233,
-
[20]
The diffusion duality.arXiv preprint arXiv:2506.10892,
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin Chiu, and V olodymyr Kuleshov. The diffusion duality.arXiv preprint arXiv:2506.10892,
-
[21]
Why Gaussian Diffusion Models Fail on Discrete Data and How to Prevent It?
Alexander Shabalin, Simon Elistratov, Viacheslav Meshchaninov, Ildus Sadrtdinov, and Dmitry Vetrov. Why gaussian diffusion models fail on discrete data?arXiv preprint arXiv:2604.02028,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Self-conditioned embedding diffusion for text generation.arXiv preprint arXiv:2211.04236,
Robin Strudel, Corentin Tallec, Florent Altch ´e, Yilun Du, Yaroslav Ganin, Arthur Mensch, Will Grathwohl, Nikolay Savinov, Sander Dieleman, Laurent Sifre, et al. Self-conditioned embedding diffusion for text generation.arXiv preprint arXiv:2211.04236,
-
[23]
Continuous Diffusion Scales Competitively with Discrete Diffusion for Language
Zhihan Yang, Wei Guo, Shuibai Zhang, Subham Sekhar Sahoo, Yongxin Chen, Arash Vahdat, Morteza Mardani, and John Thickstun. Continuous diffusion scales competitively with discrete diffusion for language.arXiv preprint arXiv:2605.18530,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
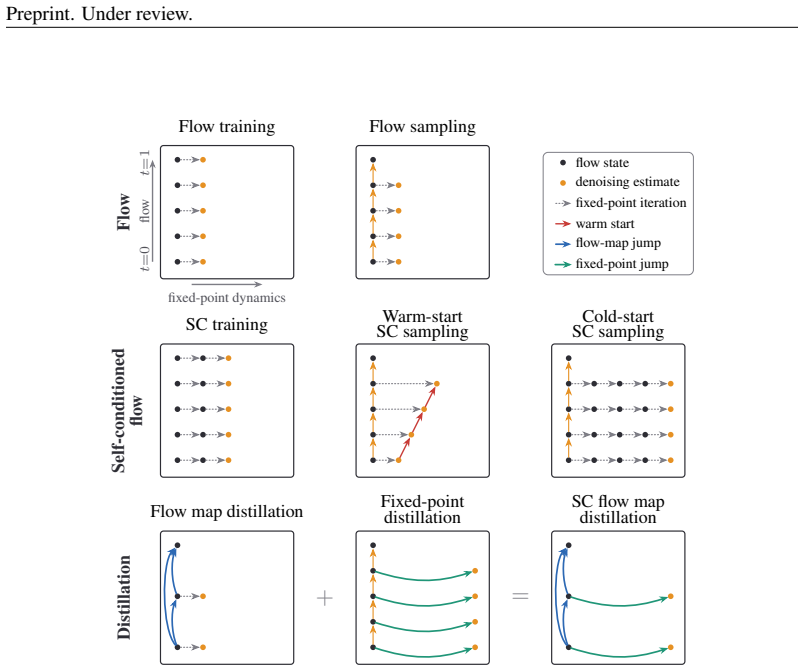
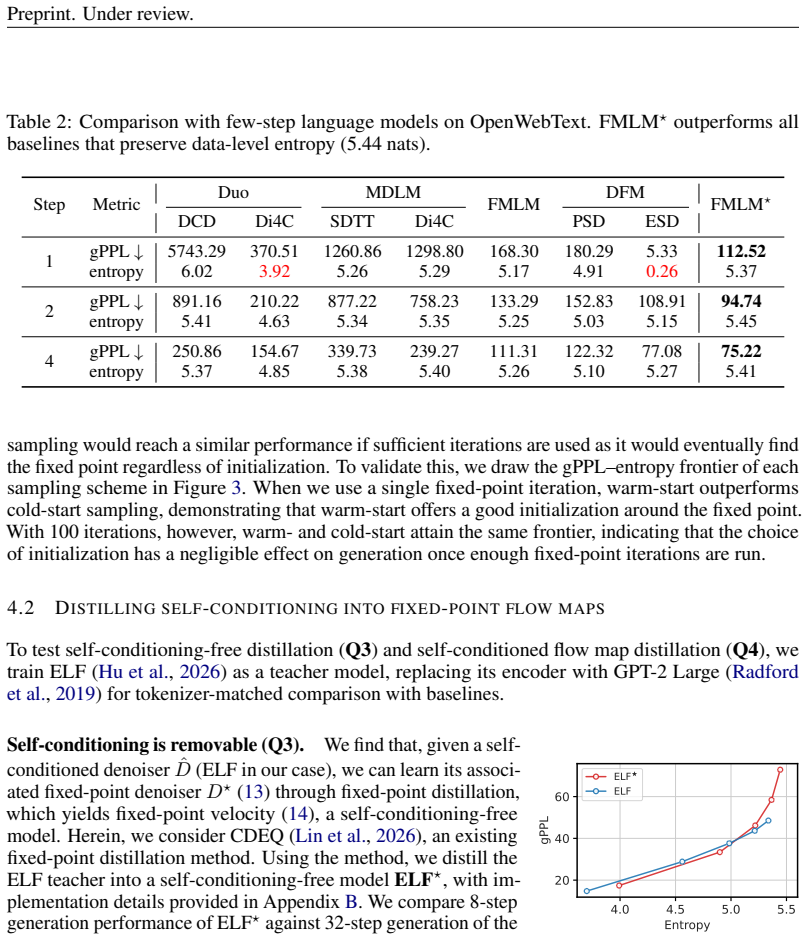
with consistency deep equilibrium (CDEQ) distillation (Lin et al., 2026). The distillation compresses the fixed-point iteration (10) into a single forward that predicts its limit z⋆, so the resulting model matches the converged self-conditioned denoiser without iterating at inference. Architecture.ELF (Hu et al.,
2026
-
[25]
conditions on the flow time t through a bank of four learned prefix tokens, prepended to the latent sequence, to which an embedding of t is added; the self- conditioning guidance weight enters through a second such bank. Following this design, to let the student track progress along the iteration, we condition it on a consistency timeτ which represents th...
2026
-
[26]
Aside from this modification, we strictly follow the original ELF architecture and train this variant using the identical hyperparameters
with the last hidden states of a pretrained GPT-2 Large model (Radford et al., 2019). Aside from this modification, we strictly follow the original ELF architecture and train this variant using the identical hyperparameters. We follow the hyperparameter settings of the original ELF model. Both models are trained for 5 epochs with a global batch size of 51...
2019
-
[27]
C QUALITATIVE RESULTS We provide generation samples from the FMLM ⋆ model
with γ= 0.75 and 1.0, respectively. C QUALITATIVE RESULTS We provide generation samples from the FMLM ⋆ model. The one-step, two-step, and four-step samples are shown in Figure 6, Figure 7, and Figure 8, respectively. 22 Preprint. Under review. Sampling Steps: 1gPPL: 92.37, Entropy: 5.27 are related to increasing the short-term size of the water cover, or...
1990
-
[28]
To clarify, the specific environmental impacts of Nij’ water over the year will have a significant influence on N&es and H
Station areas in wetlands could cause an increase by increasing water usage, by by drying up access to aater [23 and environmental degradation by by developing improved water quality from floods, the extent of water’s rocks and also water. To clarify, the specific environmental impacts of Nij’ water over the year will have a significant influence on N&es ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.