Spotted: Location-informed Reidentification of Hyenas and Leopards in Camera Trap Surveys
Pith reviewed 2026-07-02 14:01 UTC · model grok-4.3
The pith
Integrating camera-trap locations with visual similarity improves re-identification of spotted hyenas and leopards while reducing expert comparisons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
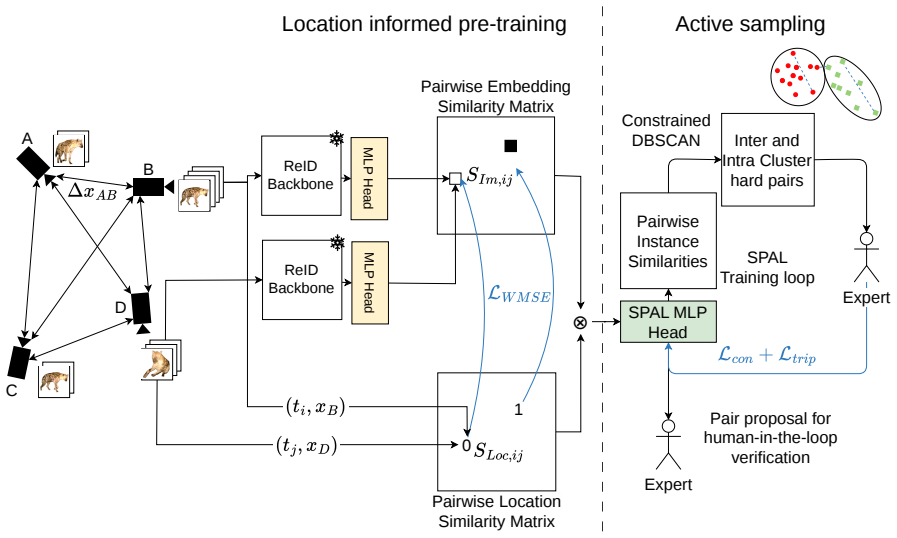
Spotted computes a feasibility score from the minimum travel speed required for two detections to belong to the same individual, uses these scores as pseudo-supervision to train a lightweight head on a frozen visual foundation model, fuses the adapted visual similarity with the feasibility score into a pairwise matching score, and applies an active pair sampling strategy that prioritizes uncertain predictions for human review.
What carries the argument
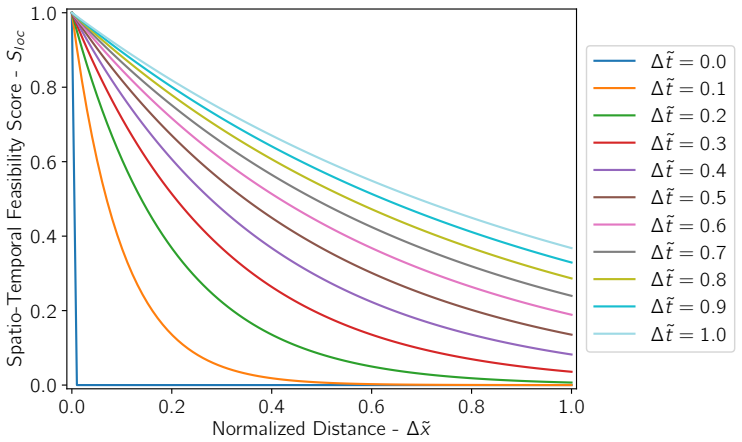
The minimum-travel-speed feasibility score derived from camera locations, used both as pseudo-supervision for model adaptation and as a direct term in the fused matching score.
Load-bearing premise
That the minimum travel speed between camera sites gives a reliable signal for whether two sightings can belong to one animal.
What would settle it
On a new camera-trap dataset, adding the feasibility score produces no gain in top-5 accuracy or the active sampler returns fewer positive matches than random sampling.
Figures

read the original abstract
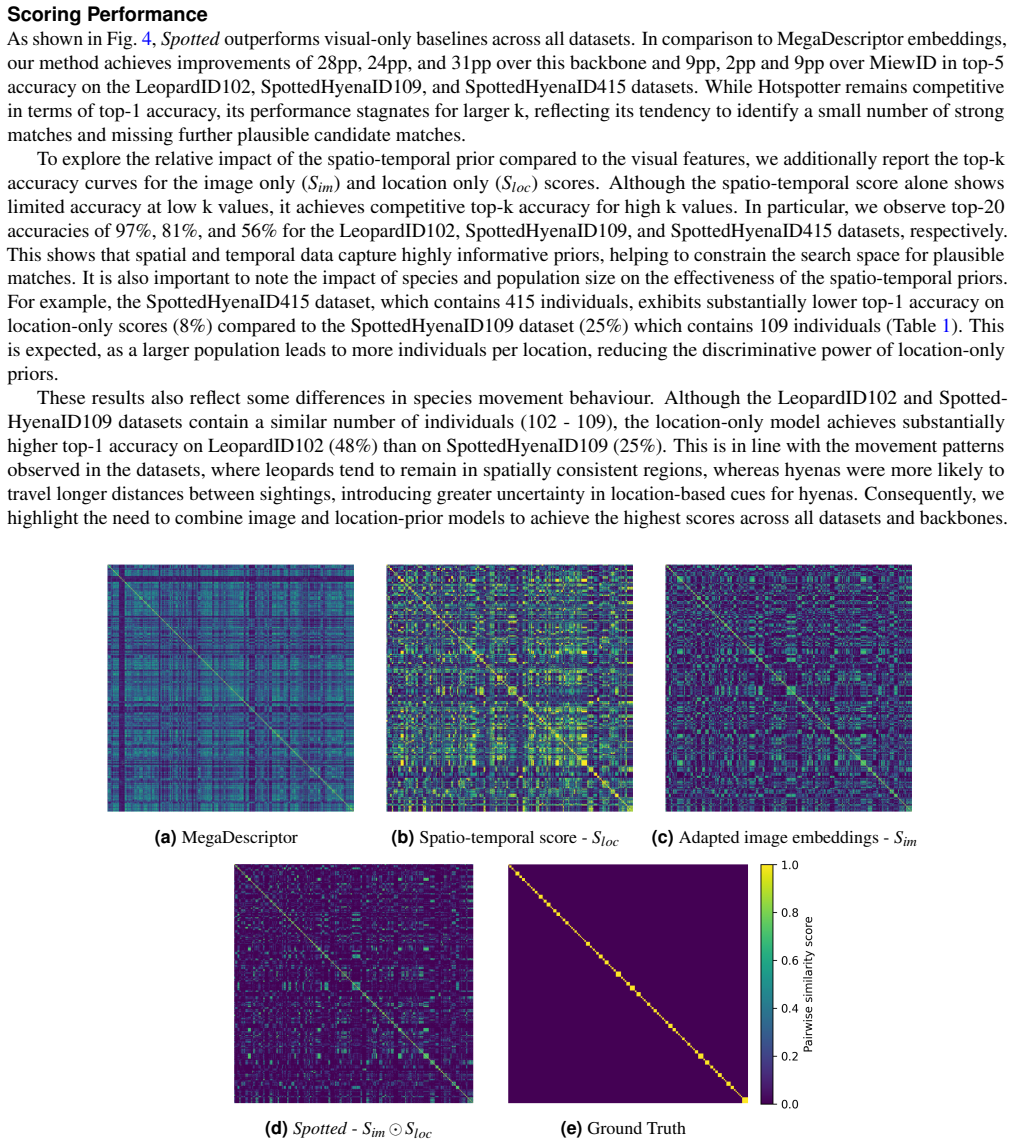
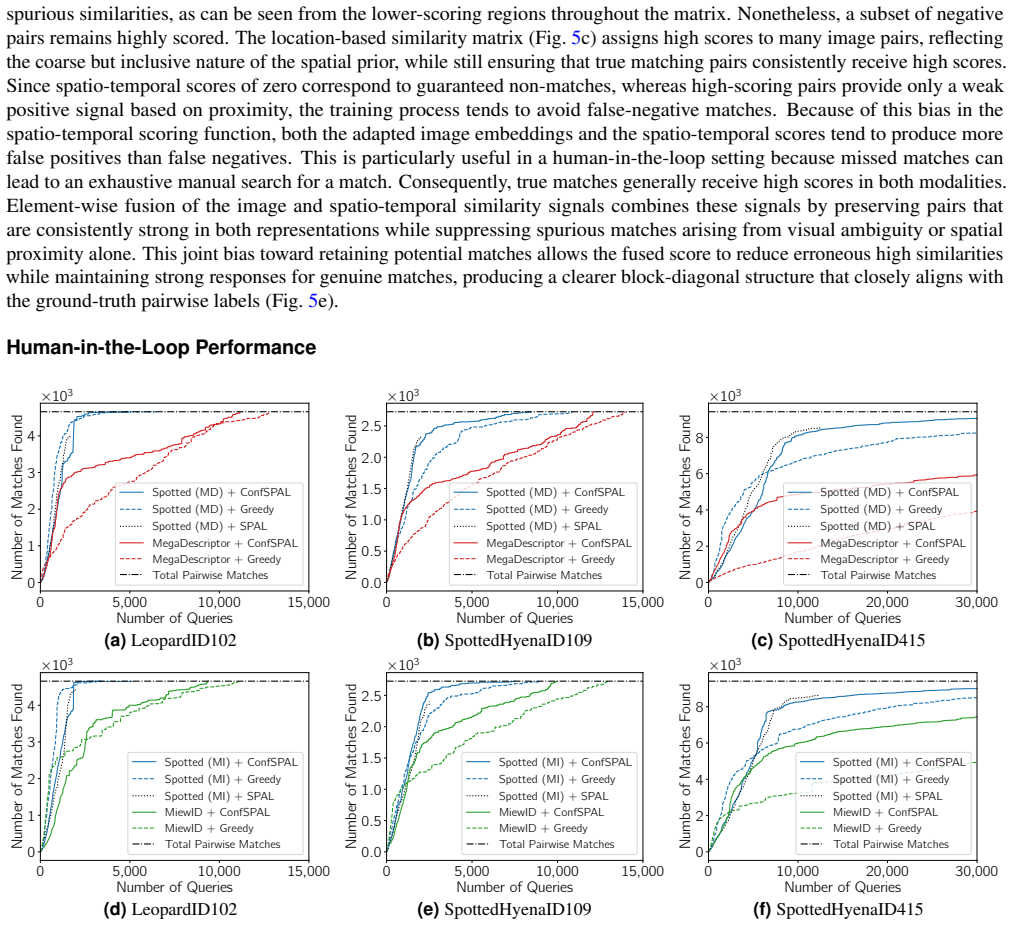
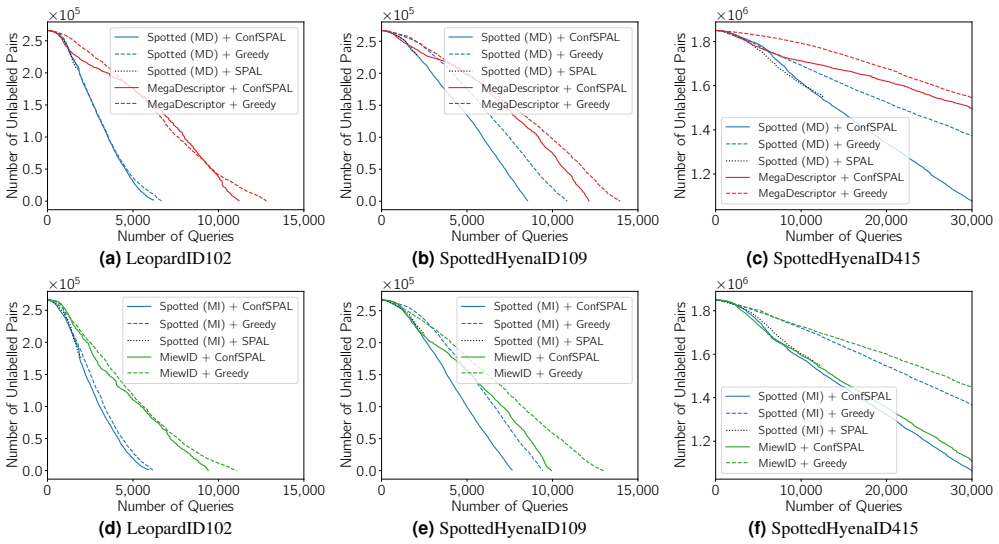
Animal re-identification (ReID) in camera-trap surveys remains challenging due to low image quality, strong variation in illumination and viewpoint, and highly imbalanced numbers of observations per individual. As a result, current ReID performance is often insufficient for fully automated use, and practical workflows typically depend on expert review of algorithmically proposed candidate matches. Moreover, most existing approaches focus almost exclusively on visual cues and overlook auxiliary information routinely available in field studies, such as image timestamps and camera-trap locations. We introduce Spotted, a location-informed, human-in-the-loop animal ReID framework that integrates visual similarity with spatio-temporal feasibility priors derived from camera locations, thereby reducing the amount of required expert review. Our method (i) computes an image-model-agnostic feasibility score based on the minimum travel speed required for two detections to correspond to the same individual, (ii) uses these feasibility cues as pseudo-supervision to train a lightweight head on top of a frozen visual foundation model, and (iii) fuses adapted visual similarity with spatio-temporal feasibility to obtain a robust pairwise matching score. We additionally integrate an active pair sampling strategy to accelerate annotation by initially prioritizing uncertain predictions. We evaluate Spotted on three challenging camera-trap ReID datasets comprised of spotted hyenas and leopards, which we release as part of this work. Our model improves average top-5 identification accuracy by 9pp, 2pp and 9pp over the best baseline on our LeopardID102, SpottedHyenaID109 and SpottedHyenaID415 datasets, respectively. Further, we show that our human-in-the-loop strategy reduces the number of queried comparisons by up to 69pp while achieving equivalent positive matches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Spotted, a location-informed human-in-the-loop framework for animal re-identification (ReID) in camera-trap surveys. It computes a spatio-temporal feasibility score from camera locations and minimum travel speed, uses this as pseudo-supervision to train a lightweight adaptation head on a frozen visual foundation model, fuses the adapted visual similarity with the feasibility prior for pairwise matching, and applies active pair sampling to prioritize uncertain predictions for expert review. The method is evaluated on three new released datasets (LeopardID102, SpottedHyenaID109, SpottedHyenaID415), claiming average top-5 accuracy gains of 9pp, 2pp, and 9pp over the best baseline, plus up to 69pp reduction in queried comparisons while maintaining equivalent positive matches.
Significance. If the reported gains are robust, the work has practical significance for scaling camera-trap surveys by reducing expert annotation burden through integration of routinely available location data. Dataset release is a clear strength. The human-in-the-loop active sampling component is a positive contribution if it preserves recall. However, the central adaptation mechanism rests on an unverified assumption about pseudo-supervision quality, which limits the strength of the significance claim until addressed.
major comments (2)
- [§3.2] §3.2 (Pseudo-supervision and adaptation): The manuscript does not report the precision of the feasibility-based pseudo-positive pairs used to train the lightweight head. Because feasible pairs (based on minimum travel speed) are expected to be overwhelmingly negatives in multi-individual data, low precision would mean the adaptation step primarily injects noise; the reported 2–9 pp gains and the human-in-the-loop savings would then depend almost entirely on the subsequent fusion step rather than the claimed adaptation. An ablation or precision estimate on held-out labeled pairs is required to substantiate the load-bearing claim.
- [§4] §4 (Experiments): No details are provided on how the three datasets were split for training the adaptation head versus evaluation, nor on whether the feasibility pseudo-labels were generated only on training data or leaked into test pairs. This directly affects whether the top-5 improvements can be attributed to the method rather than data leakage or optimistic evaluation.
minor comments (2)
- [Abstract] Abstract and §1: The claimed improvements are stated without any mention of the number of individuals, images per individual, or baseline methods used; this makes the quantitative claims hard to contextualize without reading the full experimental section.
- [§3.3] §3.3 (Fusion): The exact form of the fused score (e.g., weighted sum, product, learned combination) is not specified with an equation; readers cannot reproduce the matching score without this detail.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for additional validation of the pseudo-supervision mechanism and clearer experimental protocols. We address each major comment below and will revise the manuscript to incorporate the requested analyses and details.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Pseudo-supervision and adaptation): The manuscript does not report the precision of the feasibility-based pseudo-positive pairs used to train the lightweight head. Because feasible pairs (based on minimum travel speed) are expected to be overwhelmingly negatives in multi-individual data, low precision would mean the adaptation step primarily injects noise; the reported 2–9 pp gains and the human-in-the-loop savings would then depend almost entirely on the subsequent fusion step rather than the claimed adaptation. An ablation or precision estimate on held-out labeled pairs is required to substantiate the load-bearing claim.
Authors: We agree that quantifying the precision of feasibility-based pseudo-positive pairs is necessary to substantiate the adaptation step. The current manuscript does not report this metric or include the requested ablation. In the revision we will compute precision on held-out labeled pairs from each dataset and add an ablation comparing performance with and without the adaptation head (i.e., fusion alone). This will clarify the relative contributions of adaptation versus fusion to the observed gains. revision: yes
-
Referee: [§4] §4 (Experiments): No details are provided on how the three datasets were split for training the adaptation head versus evaluation, nor on whether the feasibility pseudo-labels were generated only on training data or leaked into test pairs. This directly affects whether the top-5 improvements can be attributed to the method rather than data leakage or optimistic evaluation.
Authors: We acknowledge the omission of split and leakage details. The manuscript currently provides no explicit description of how training versus evaluation partitions were formed or whether pseudo-label generation was restricted to training data. We will expand §4 to specify the splitting strategy (by individual identity with temporal separation where applicable) and explicitly state that feasibility scores used for pseudo-supervision were computed solely on the training partition, with no access to test pairs. This will confirm that the reported improvements are not due to leakage. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives its ReID improvements from an independent spatio-temporal feasibility score computed directly from camera locations and timestamps (minimum travel speed between sites), which serves as external pseudo-supervision for a lightweight adaptation head on a frozen visual model. This input is model-agnostic and not derived from visual features or prior model outputs. Reported gains are empirical comparisons on released datasets against baselines, with no self-citations, fitted parameters renamed as predictions, or uniqueness theorems invoked. The human-in-the-loop sampling and fusion steps operate on these external priors without reducing the central claims to self-definition or construction from the target outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- minimum travel speed threshold
axioms (1)
- domain assumption The minimum travel speed between two camera locations can be used as a proxy for whether two detections are the same individual
Reference graph
Works this paper leans on
-
[1]
Delisle, Z. J., Flaherty, E. A., Nobbe, M. R., Wzientek, C. M. & Swihart, R. K. Next-generation camera trapping: Systematic review of historic trends suggests keys to expanded research applications in ecology and conservation.Front. Ecol. Evol.V olume 9 - 2021, DOI: 10.3389/fevo.2021.617996 (2021)
-
[2]
& Picek, L
Adam, L., ˇCerm´ak, V ., Papafitsoros, K. & Picek, L. Seaturtleid2022: A long-span dataset for reliable sea turtle re- identification. InProceedings of the IEEE/CVF winter conference on applications of computer vision, 7146–7156 (2024)
2024
-
[3]
& Picek, L
Adam, L., ˇCerm´ak, V ., Papafitsoros, K. & Picek, L. Wildlifereid-10k: Wildlife re-identification dataset with 10k individual animals. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2090–2100 (IEEE, 2025)
2090
-
[4]
Powell, R. A. & Mitchell, M. S. What is a home range?J. Mammal.93, 948–958, DOI: 10.1644/11-MAMM-S-177.1 (2012). https://academic.oup.com/jmammal/article-pdf/93/4/948/2899018/93-4-948.pdf
-
[5]
Distinctive image features from scale-invariant keypoints,
Crall, J. P., Stewart, C. V ., Berger-Wolf, T. Y ., Rubenstein, D. I. & Sundaresan, S. R. Hotspotter—patterned species instance recognition. In2013 IEEE workshop on applications of computer vision (WACV), 230–237 (IEEE, 2013). 6.Lowe, D. G. Distinctive image features from scale-invariant keypoints.Int. J. Comput. Vis.60, 91–110, DOI: 10.1023/B: VISI.00000...
work page doi:10.1023/b: 2013
-
[6]
Guo, S.et al.Automatic identification of individual primates with deep learning techniques.iScience23, 101412, DOI: https://doi.org/10.1016/j.isci.2020.101412 (2020)
- [7]
-
[8]
InProceedings of the IEEE/CVF International Conference on Computer Vision, 14369–14379 (2025)
Hou, S.et al.Openanimals: Revisiting person re-identification for animals towards better generalization. InProceedings of the IEEE/CVF International Conference on Computer Vision, 14369–14379 (2025)
2025
-
[9]
Otarashvili, L., Subramanian, T., Holmberg, J., Levenson, J. & Stewart, C. V . Multispecies animal re-id using a large community-curated dataset.arXiv preprint arXiv:2412.05602(2024)
-
[10]
& Papafitsoros, K
ˇCerm´ak, V ., Picek, L., Adam, L. & Papafitsoros, K. WildlifeDatasets: An Open-Source Toolkit for Animal Re-Identification. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 5953–5963 (2024)
2024
-
[11]
InEuropean conference on computer vision, 198–214 (Springer, 2022)
Zhu, K.et al.Pass: Part-aware self-supervised pre-training for person re-identification. InEuropean conference on computer vision, 198–214 (Springer, 2022)
2022
-
[12]
& Baktashmotlagh, M
Moskvyak, O., Maire, F., Dayoub, F. & Baktashmotlagh, M. Keypoint-aligned embeddings for image retrieval and re-identification. InProceedings of the IEEE/CVF winter conference on applications of computer vision, 676–685 (2021)
2021
-
[13]
& Baktashmotlagh, M
Moskvyak, O., Maire, F., Dayoub, F. & Baktashmotlagh, M. Learning landmark guided embeddings for animal re- identification. InProceedings of the IEEE/CVF winter conference on applications of computer vision workshops, 12–19 (2020)
2020
-
[14]
InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops(2019)
Shukla, A.et al.A hybrid approach to tiger re-identification. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops(2019)
2019
-
[15]
& Weinberger, K
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. Densely connected convolutional networks. InProceedings of the IEEE conference on computer vision and pattern recognition, 4700–4708 (2017)
2017
-
[16]
InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 10012–10022 (2021)
Liu, Z.et al.Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 10012–10022 (2021). 11/13
2021
-
[17]
& Zafeiriou, S
Deng, J., Guo, J., Xue, N. & Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2019)
2019
-
[18]
Tan, M. & Le, Q. Efficientnetv2: Smaller models and faster training. In Meila, M. & Zhang, T. (eds.)Proceedings of the 38th International Conference on Machine Learning, vol. 139 ofProceedings of Machine Learning Research, 10096–10106 (PMLR, 2021)
2021
-
[19]
Li, Y .et al.Metawild: A multimodal dataset for animal re-identification with environmental metadata. InProceedings of the 33rd ACM International Conference on Multimedia, MM ’25, 13009–13015, DOI: 10.1145/3746027.3758249 (Association for Computing Machinery, New York, NY , USA, 2025)
-
[20]
Kays, R., Hody, A., Jachowski, D. S. & Parsons, A. W. Empirical evaluation of the spatial scale and detection process of camera trap surveys.Mov. Ecol.9, 41, DOI: 10.1186/s40462-021-00277-3 (2021)
-
[21]
& Perona, P
Mac Aodha, O., Cole, E. & Perona, P. Presence-only geographical priors for fine-grained image classification. In Proceedings of the IEEE/cvf international conference on computer vision, 9596–9606 (2019)
2019
-
[22]
& Matas, J
Picek, L., Neumann, L. & Matas, J. Animal identification with independent foreground and background modeling. In Cremers, D.et al.(eds.)Pattern Recognition, 241–257 (Springer Nature Switzerland, Cham, 2025)
2025
-
[23]
J., Abu Baker, M., Tang, C
Rosa, M. J., Abu Baker, M., Tang, C. M. & Littlemore, J. Gcn-id: A benchmark dataset for great crested newt re- identification using ai foundation models. InProceedings of the BMVC(2025)
2025
-
[24]
Li, S., Li, J., Tang, H., Qian, R. & Lin, W. Atrw: A benchmark for amur tiger re-identification in the wild. InProceedings of the 28th ACM International Conference on Multimedia, MM ’20, 2590–2598, DOI: 10.1145/3394171.3413569 (Association for Computing Machinery, New York, NY , USA, 2020)
-
[25]
Panthera pardus csv custom export (2022)
Botswana Predator Conservation Trust. Panthera pardus csv custom export (2022). Retrieved from African Carnivore Wildbook on 2022-04-28
2022
-
[26]
W., Linquist, S
Schneider, S., Taylor, G. W., Linquist, S. & Kremer, S. C. Past, present and future approaches using computer vision for animal re-identification from camera trap data.Methods Ecol. Evol.10, 461–470 (2019). 28.Osner, N. TrapTagger
2019
-
[27]
Sani, D., Khurana, M. & Anand, S. Active learning for animal re-identification with ambiguity-aware sampling (2025). 2511.06658
-
[28]
S.et al.A deep active learning system for species identification and counting in camera trap images
Norouzzadeh, M. S.et al.A deep active learning system for species identification and counting in camera trap images. Methods Ecol. Evol.12, 150–161, DOI: https://doi.org/10.1111/2041-210X.13504 (2021). https://besjournals.onlinelibrary. wiley.com/doi/pdf/10.1111/2041-210X.13504. 31.Jin, D. & Li, M. Towards fewer labels: Support pair active learning for pe...
-
[29]
& Tao, D
Liu, Z., Wang, J., Gong, S., Lu, H. & Tao, D. Deep reinforcement active learning for human-in-the-loop person re-identification. InProceedings of the IEEE/CVF international conference on computer vision, 6122–6131 (2019)
2019
-
[30]
Mallapragada, P. K., Jin, R. & Jain, A. K. Active query selection for semi-supervised clustering. In2008 19th International Conference on Pattern Recognition, 1–4, DOI: 10.1109/ICPR.2008.4761792 (2008)
-
[31]
Zhao, W., He, Q., Ma, H. & Shi, Z. Effective semi-supervised document clustering via active learning with instance-level constraints.Knowl. Inf. Syst.30, 569–587, DOI: 10.1007/s10115-011-0389-1 (2012)
-
[32]
Miao, Z.et al.Iterative human and automated identification of wildlife images.Nat. Mach. Intell.3, 885–895, DOI: 10.1038/s42256-021-00393-0 (2021)
-
[33]
Bodesheim, P.et al.Pre-trained models are not enough: active and lifelong learning is important for long-term visual monitoring of mammals in biodiversity research—individual identification and attribute prediction with image features from deep neural networks and decoupled decision models applied to elephants and great apes.Mammalian Biol.102, 875–897, D...
-
[34]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Perez, G., Sheldon, D., Van Horn, G. & Maji, S. Human-in-the-loop visual re-id for population size estimation. In European Conference on Computer Vision (ECCV)(2024). 38.Ren, T.et al.Grounded sam: Assembling open-world models for diverse visual tasks (2024). 2401.14159. Acknowledgements All figures were prepared by H.S.K. with assistance from J.H. 12/13 A...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.