Beyond Activation Alignment:The Alignment-Diversity Tradeoff in Task-Aware LLM Quantization
Pith reviewed 2026-07-02 15:47 UTC · model grok-4.3
The pith
Appropriately allocated 3.5-bit LLMs match or surpass 4-bit baselines by balancing task-specific and general calibration data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
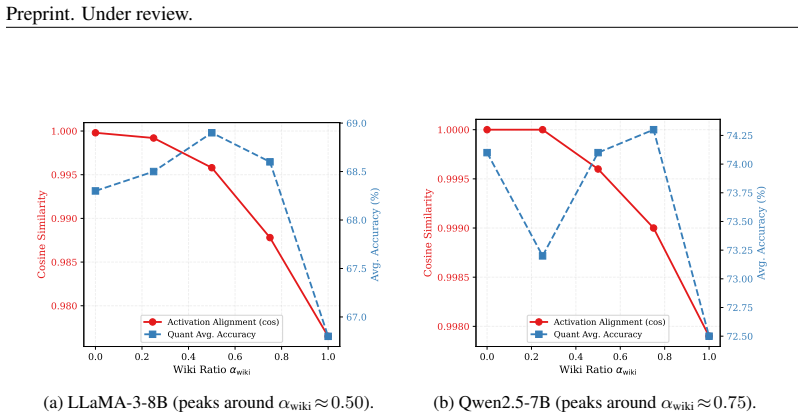
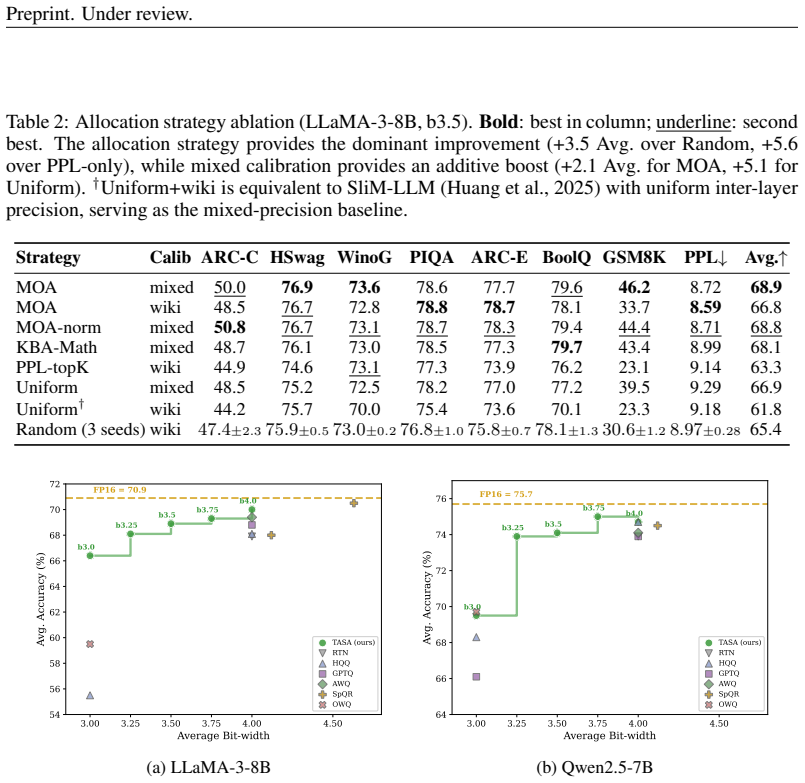
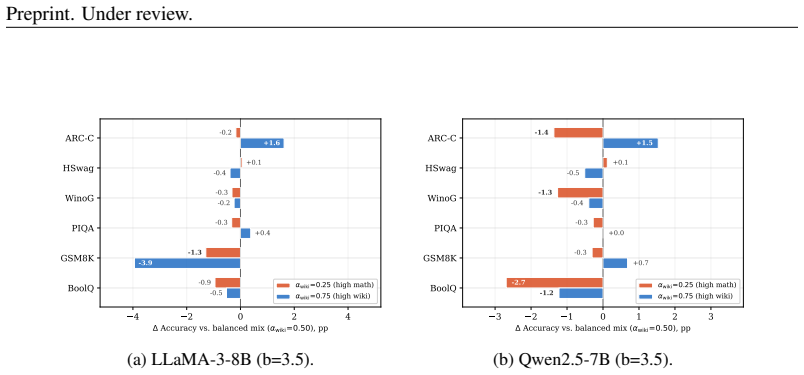
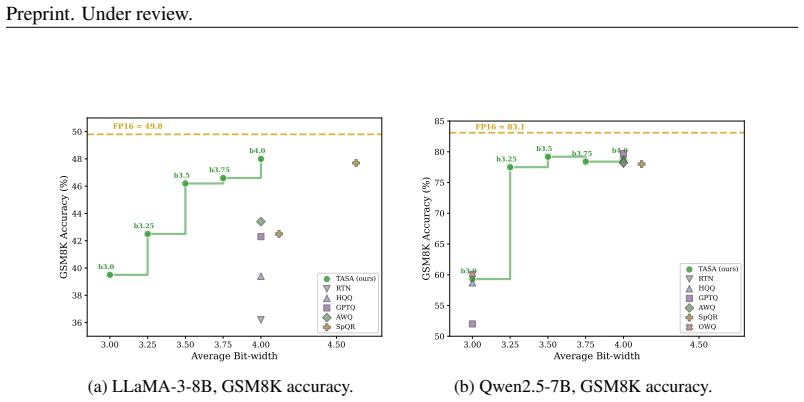
TASA jointly optimizes calibration-data composition via a training-free gradient-trace alignment criterion and mixed-precision bit allocation by aggregating perplexity and reasoning-oriented sensitivity signals. This produces a precision inversion in which 3.5-bit average models match or exceed less task-aware 4-bit baselines, including more than 20 absolute points on GSM8K for LLaMA-3-8B over the strongest W3 baseline.
What carries the argument
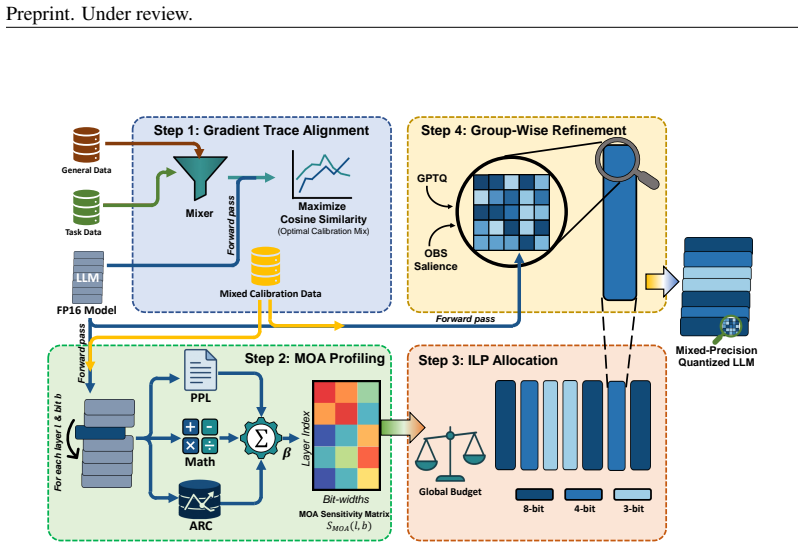
TASA, a two-level framework that first selects an optimal calibration-data mixture and then guides inter-layer and intra-layer bit allocation using combined sensitivity signals.
Load-bearing premise
The training-free gradient-trace alignment criterion accurately identifies calibration mixtures that improve downstream task performance without overfitting to the search metric.
What would settle it
If 3.5-bit TASA-quantized models consistently underperform 4-bit uniform baselines on multiple reasoning benchmarks across different model families, the claimed precision inversion would be disproved.
Figures
read the original abstract
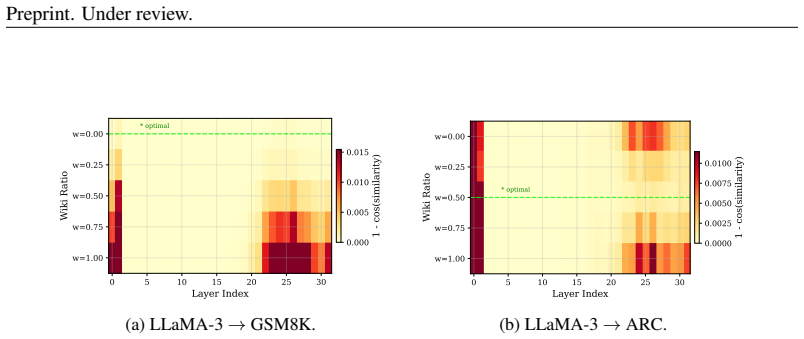
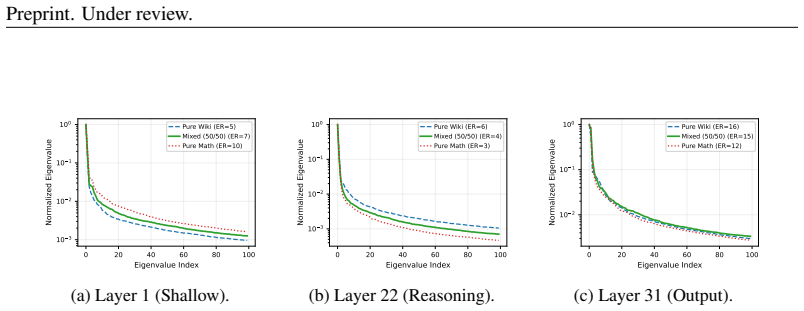
Mixed-precision quantization (MPQ) has become a key technique for deploying large language models under stringent memory and compute constraints. We first identify a phenomenon that we term the Perplexity Illusion: layers ranked as important by perplexity-based sensitivity show little rank correlation with those that are most influential for complex reasoning performance, with Kendall $\tau \approx 0$ in our analysis. We further reveal an Alignment-Diversity Tradeoff: using only target-task calibration data can degrade post-quantization performance, whereas incorporating general-domain data stabilizes sensitivity estimation and improves robustness across tasks. Based on these observations, we propose TASA (Task-Aware Sensitivity Analysis), a two-level framework that jointly optimizes calibration-data composition and mixed-precision bit allocation. Specifically, TASA searches for a calibration-data mixture using a training-free gradient-trace alignment criterion, and then aggregates perplexity and reasoning-oriented sensitivity signals to guide both inter-layer and intra-layer bit allocation. Experiments on LLaMA-3-8B and Qwen2.5-7B reveal a precision inversion: appropriately allocated 3.5-bit models can match or surpass less task-aware 4-bit baselines. At an average precision of 3.5 bits, TASA matches or outperforms several competitive 4-bit uniform baselines in aggregate accuracy, and improves over the strongest W3 baseline on GSM8K by more than 20 absolute points on LLaMA-3-8B. These results show that calibration-data composition substantially affects task-sensitive quantization, a factor underexplored in prior work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a 'Perplexity Illusion' (Kendall τ ≈ 0 between perplexity sensitivity rankings and reasoning-task importance) and an 'Alignment-Diversity Tradeoff' (pure target-task calibration degrades post-quantization performance while mixing general-domain data stabilizes it). It proposes TASA, a two-level training-free framework that first searches calibration-data mixtures via a gradient-trace alignment criterion and then aggregates perplexity and reasoning sensitivities for inter- and intra-layer bit allocation. On LLaMA-3-8B and Qwen2.5-7B the method is claimed to produce 3.5-bit models that match or exceed several 4-bit uniform baselines in aggregate accuracy and improve over the strongest W3 baseline by >20 points on GSM8K.
Significance. If the reported gains are reproducible and not artifacts of the search procedure, the work would usefully highlight that calibration-data composition is a first-class, underexplored factor in task-aware MPQ and that modest average-bit reductions can still preserve complex-reasoning performance when allocation is informed by both alignment and diversity signals.
major comments (2)
- [Abstract] Abstract: the central empirical claim (3.5-bit TASA matching/outperforming 4-bit baselines and +20 pt GSM8K gain on LLaMA-3-8B) rests on a two-level procedure whose first stage selects the calibration mixture by a training-free gradient-trace alignment score; the manuscript supplies neither the exact search protocol, the candidate mixture pool, nor any ablation demonstrating that the selected mixtures improve downstream task accuracy rather than merely optimizing the internal trace metric.
- [Abstract] Abstract: no experimental protocol, baseline definitions, statistical tests, or ablation results are provided to support the stated improvements or the claim that the discovered mixture generalizes beyond the search objective itself, rendering the support for the Alignment-Diversity Tradeoff unverifiable from the given text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for greater methodological transparency. We will revise the manuscript to address the concerns by expanding key descriptions while preserving conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (3.5-bit TASA matching/outperforming 4-bit baselines and +20 pt GSM8K gain on LLaMA-3-8B) rests on a two-level procedure whose first stage selects the calibration mixture by a training-free gradient-trace alignment score; the manuscript supplies neither the exact search protocol, the candidate mixture pool, nor any ablation demonstrating that the selected mixtures improve downstream task accuracy rather than merely optimizing the internal trace metric.
Authors: We agree the abstract is high-level and does not supply these specifics. In revision we will add a concise description of the search protocol (gradient-trace alignment computed as layer-wise cosine similarity between calibration and task gradients, optimized via a training-free grid search), the candidate mixture pool (combinations of target-task subsets and general-domain corpora), and a brief reference to ablations showing downstream accuracy gains from alignment-selected mixtures over target-only or random baselines. Full protocol and ablation tables will be expanded in the main text. revision: yes
-
Referee: [Abstract] Abstract: no experimental protocol, baseline definitions, statistical tests, or ablation results are provided to support the stated improvements or the claim that the discovered mixture generalizes beyond the search objective itself, rendering the support for the Alignment-Diversity Tradeoff unverifiable from the given text.
Authors: We acknowledge that the abstract provides insufficient detail on these elements, making verification difficult from the abstract alone. The revision will incorporate brief mentions of the experimental protocol (models, datasets, evaluation metrics), baseline definitions (uniform 4-bit and W3 methods from prior work), robustness via multiple random seeds, and key ablation outcomes supporting the Alignment-Diversity Tradeoff and cross-task generalization. We will also add explicit section references so readers can locate the supporting evidence. revision: yes
Circularity Check
No significant circularity; empirical method and results are independent of inputs
full rationale
The paper's chain consists of empirical observations (Perplexity Illusion via Kendall τ correlation, Alignment-Diversity Tradeoff via calibration experiments) followed by a proposed two-level TASA procedure whose outputs are validated directly against downstream task accuracies on LLaMA-3-8B and Qwen2.5-7B. No equations reduce a claimed prediction to a fitted parameter by construction, no load-bearing premise rests on self-citation, and the gradient-trace alignment criterion is presented as a search heuristic whose effectiveness is measured externally rather than defined into the result. The central claim therefore remains falsifiable outside the paper's own search metric.
Axiom & Free-Parameter Ledger
free parameters (2)
- calibration data mixture ratio
- inter/intra-layer bit allocation weights
axioms (2)
- domain assumption Gradient-trace alignment criterion reliably identifies beneficial calibration data mixtures for task performance
- domain assumption Combining perplexity and reasoning-oriented sensitivity signals produces superior bit allocations compared to single-signal baselines
invented entities (2)
-
Perplexity Illusion
no independent evidence
-
Alignment-Diversity Tradeoff
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaif, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
GEMQ: Global Expert-Level Mixed-Precision Quantization for MoE LLMs
Jianing Deng, Song Wang, Dongwei Wang, Zijie Liu, Tianlong Chen, Huanrui Yang, and Jingtong Hu. GEMQ: Global expert-level mixed-precision quantization for MoE LLMs.arXiv preprint arXiv:2605.23078,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Razvan-Gabriel Dumitru, Vikas Yadav, Rishabh Maheshwary, Paul-Ioan Clotan, Sathwik Tejaswi Madhusudhan, and Mihai Surdeanu. Layer-wise quantization: A pragmatic and effective method for quantizing LLMs beyond integer bit-levels.arXiv preprint arXiv:2406.17415,
-
[6]
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao
URLhttps://zenodo.org/records/12608602. Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. An investigation into neural net optimization via hessian eigenvalue density. InInternational Conference on Machine Learning, pp. 2232– 2241,
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, An- gela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, et al. The llama 3 herd of models.arXiv preprint arX...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
You Had One Job: Per-Task Quantization Using LLMs' Hidden Representations
12 Preprint. Under review. Amit LeVi, Raz Lapid, Rom Himelstein, Chaim Baskin, Ravid Shwartz-Ziv, and Avi Mendelson. You had one job: Per-task quantization using LLMs’ hidden representations.arXiv preprint arXiv:2511.06516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Zhen Li, Yupeng Su, Runming Yang, Congkai Xie, Zheng Wang, Zhongwei Xie, Ngai Wong, and Hongxia Yang. Quantization meets reasoning: Exploring llm low-bit quantization degradation for mathematical reasoning.arXiv preprint arXiv:2501.03035,
-
[10]
OSAQ: Outlier Self-Absorption for Accurate Low-bit LLM Quantization
Zhikai Li, Zhen Dong, Xuewen Liu, Jing Zhang, and Qingyi Gu. OSAQ: Outlier self-absorption for accurate low-bit LLM quantization.arXiv preprint arXiv:2605.04738,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Ryan Lucas, Mehdi Makni, Xiang Meng, Adam Deng, and Rahul Mazumder. ADMM-Q: An im- proved hessian-based weight quantizer for post-training quantization of large language models. arXiv preprint arXiv:2605.11222,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Self-calibration for language model quantization and pruning
Miles Williams, George Chrysostomou, and Nikolaos Aletras. Self-calibration for language model quantization and pruning. InProceedings of the 2025 Conference of the Nations of the Ameri- cas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 10149–10167,
2025
-
[13]
Fitting Is Not Enough: Smoothness in Extremely Quantized LLMs
Yuzhuang Xu, Xu Han, Yuxuan Li, Pengzhan Li, and Wanxiang Che. Fitting is not enough: Smooth- ness in extremely quantized LLMs.arXiv preprint arXiv:2605.08894,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
13 Preprint. Under review. An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runj...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
CoopQ: Cooperative game inspired layerwise mixed precision quantization for LLMs
Junchen Zhao, Ali Derakhshan, Jayden Kana Hyman, Junhao Dong, Sangeetha Abdu Jyothi, and Ian Harris. CoopQ: Cooperative game inspired layerwise mixed precision quantization for LLMs. arXiv preprint arXiv:2509.15455,
-
[16]
Saliency-Aware Regularized Quantization Calibration for Large Language Models
Yanlong Zhao, Xiaoyuan Cheng, Huihang Liu, Baihua He, Xinyu Zhang, Harrison Bo Hua Zhu, Wenlong Chen, Li Zeng, and Zhuo Sun. Saliency-aware regularized quantization calibration for large language models.arXiv preprint arXiv:2605.05693,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Chenxi Zhou, Pengfei Cao, Jiang Li, Bohan Yu, Jinyu Ye, Jun Zhao, and Kang Liu. From signal degradation to computation collapse: Uncovering the two failure modes of LLM quantization. arXiv preprint arXiv:2604.19884,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Under review
14 Preprint. Under review. Table 4: Comparison of mixed-precision quantization approaches along three design dimensions. TASA jointly optimizes the sensitivity metric, calibration data, and allocation granularity in a task- aware manner. Method Sensitivity Metric Calib Data Granularity Task-Aware? HAWQ Hessian eigenvalue Generic Layer No HAWQ-V2 Hessian t...
2048
-
[19]
We delib- 15 Preprint
while keeping all other layers at FP16, and measure the resulting degradation in three metrics. We delib- 15 Preprint. Under review. Table 5: Baseline implementation details. All methods use group sizeg= 128and WikiText-2 calibration with 128 samples. Method Implementation Notes RTN Custom (symmetric MinMax) Standard round-to-nearest with per-group scales...
2023
-
[20]
(2024), group size 16, bilevel 3-bit OWQ Official codebase Lee et al
SpQR Official codebase Dettmers et al. (2024), group size 16, bilevel 3-bit OWQ Official codebase Lee et al. (2024), default configuration SliM-LLM Official codebase Huang et al. (2025), integrated into our pipeline erately use RTN rather than GPTQ for profiling: RTN applies a pure rounding perturbation without second-order error compensation, so the meas...
2024
-
[21]
Baseline implementations.Tab
This procedure yields a sensitivity vectors (k) ∈R L for each objectivek∈ {ppl,math,arc}, where each entry records the contribution of layerlto objectivekunder quantization perturbation. Baseline implementations.Tab. 5 lists the implementation source for each baseline method. All baselines use the same group size (g= 128), calibration data (WikiText-2,n= ...
2023
-
[22]
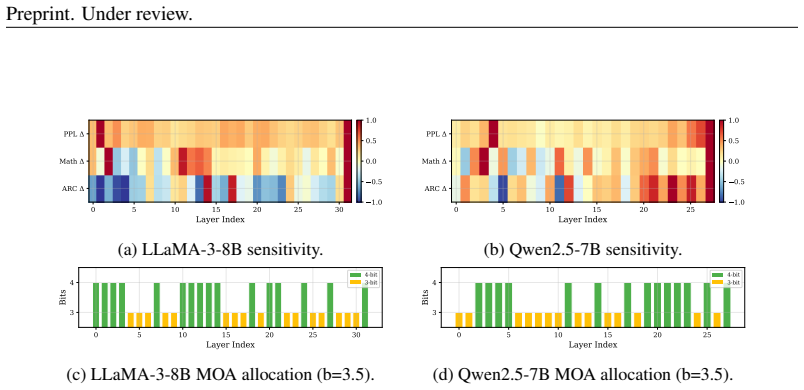
The time complexity isO(L· Btotal · |B|), which is negligible (<1second for all configurations). The resulting allocation produces a heterogeneous per-layer bit pattern that interleaves 3-bit, 4-bit, and occasionally 8-bit layers according to the multi-objective sensitivity landscape (see Tab. 15). For instance, at a 3.5-bit average budget on LLaMA-3-8B, ...
2025
-
[23]
for completeness. B.5 CROSS-TASKOVERLAPANALYSIS A set-theoretic analysis of the top-Kmost sensitive layers corroborates the rank correlation results discussed in the main text. On LLaMA-3-8B, the top-8 PPL-sensitive layers are{1,3,6,16,18,20,21,31}. In contrast, the top-8 math-sensitive layers are{2,10,11,12,13,14,20,31}, and the top-8 ARC-sensitive layer...
-
[24]
We note that the A100 does not support native INT4/INT3 compute; all quantized operations are performed with 26 Preprint
for benchmarking. We note that the A100 does not support native INT4/INT3 compute; all quantized operations are performed with 26 Preprint. Under review. Algorithm 1TASA: Task-Aware Sensitivity Analysis Input: Modelθ, layersL, bit candidatesB, budgetB, general dataD g, task dataD t, candidate ratiosA, MOA weightβ Output: Mixed-precision quantized model ˆθ...
2023
-
[25]
task circuits,
takes a different approach to task-aware quantization. Rather than balanc- ing alignment and diversity at the calibration level, TACQ uses backward-pass gradient attribution to identify “task circuits,” the 0.35% of weight parameters most critical for a specific target task, and preserves them at higher precision while uniformly quantizing the remainder t...
2025
-
[26]
and its modern extension to LLM quantization (Frantar et al., 2023). Following standard assumptions in post-training quantization, the raw rounding errorϵfor each weight column is modeled as uncorrelated zero-mean noise with varianceσ 2 q determined by the bit-width. Under OBS, however, quantizing each weight triggers a compensating update to the re- main...
2023
-
[27]
whereH α =αH gen + (1−α)H task is the calibration Hessian under mixing ratioα, andH test = X⊤ testXtest/nis the Hessian on the test distribution
exhibit reversed behavior due to their high sensitivity to token distributions. whereH α =αH gen + (1−α)H task is the calibration Hessian under mixing ratioα, andH test = X⊤ testXtest/nis the Hessian on the test distribution. This trace formula admits a spectral decomposition that reveals a classicalbias-variance dilemma. Let{(λ i,u i)}be the eigen-pairs ...
2018
-
[28]
and matrix analysis (Bhatia, 2007). SinceHα is a positive affine function of αand is strictly positive definite for allα∈(0,1](guaranteed by Item (i)), the composite function f(α) = tr(H test H−1 α )is strictly convex on(0,1]. Step 2: Boundary behavior asα→0.Asα→0, we haveH α →H task. Consider the spectral contribution of the trailing eigenvectorvfrom Ite...
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.