From Registry to Repository: How AI Agent Skills Are Written, Adapted, and Maintained
Pith reviewed 2026-07-02 08:26 UTC · model grok-4.3
The pith
AI agent skills are mostly copied once from registries into personal repositories and then left largely unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
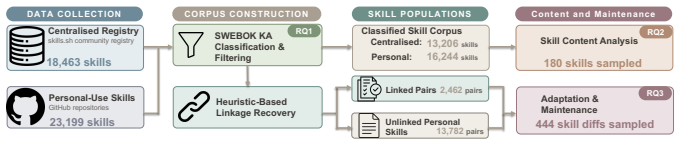
By identifying 3,709 reuse links across 18,463 registry skills and 23,199 GitHub skills, the study shows that reuse is largely a one-time copy operation: most reused skills remain near-verbatim, 53% are never modified after adoption, and subsequent local maintenance is overwhelmingly additive. Customisation primarily adapts skills to local environments, whereas evolution accretes new inline domain knowledge. Across both, a stable behavioural contract remains almost untouched.
What carries the argument
Reuse links between registry skills and GitHub skills, classified by LLM into SWEBOK areas and coded thematically for modification themes.
If this is right
- Maintenance effort should concentrate on project-specific bindings instead of rewriting the shared skill body.
- Registries and supporting tools should help consolidate the domain knowledge that developers currently re-author separately.
- Software Construction is the dominant knowledge area, with a long tail of specialised areas also present.
- Modifications most often rework operational specifications or adapt knowledge and resources rather than altering user interaction rules.
- Local changes tend to be additive, leaving the original skill structure intact.
Where Pith is reading between the lines
- Automated diff tools could flag when local additions might usefully flow back into the registry version.
- The observed stability of behavioural contracts may produce consistent agent behaviour even when the same skill is used across unrelated projects.
- The pattern could be tested in private or enterprise skill collections to see whether the one-time-copy habit persists outside public registries.
Load-bearing premise
The sampled registry skills, GitHub skills, and identified reuse links form a representative picture of real-world skill creation, copying, and change.
What would settle it
Finding a sizable collection of reuse cases in which the behavioural contract is routinely rewritten after copying would contradict the reported stability pattern.
Figures


read the original abstract
AI coding agents increasingly rely on skills: structured context bundles, typically a SKILL.md file with a YAML header and Markdown body, loaded on demand for domain knowledge, workflows, and scripts. Public registries such as skills.sh now host tens of thousands of skills, making them an emerging unit of reuse in agent-based software engineering. Yet skills have largely been viewed as agent capabilities rather than software artefacts whose content and evolution shape agent behaviour. We present the first empirical study of AI agent skills as engineered artefacts that are authored, reused, customised and maintained, across public registries and personal-use repositories. We mined 18,463 skills from skills.sh and 23,199 personal-use skills from 5,876 GitHub repositories, identifying 3,709 reuse links. LLM-based classification into SWEBOK knowledge areas (KAs) shows Software Construction dominates alongside a long tail of specialised areas. A thematic analysis of 180 skills identifies six content categories. Qualitative coding of 444 modifications reveals six themes, of which reworking operational specifications and adapting knowledge and resources are the primary target of change. Our findings show that reuse is largely a one-time copy operation: most reused skills remain near-verbatim, 53\% are never modified after adoption, and subsequent local maintenance is overwhelmingly additive. Customisation primarily adapts skills to local environments, whereas evolution accretes new inline domain knowledge. Across both, a stable behavioural contract -- how a skill interacts with users, monitors runtime state, and recovers from failures -- remains almost untouched. These results suggest maintenance effort should focus on project-specific bindings, and that registries and tool support should enable consolidating the domain knowledge skills re-author in isolation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to conduct the first empirical study of AI agent skills as software artefacts by mining 18,463 skills from the skills.sh registry and 23,199 personal-use skills from 5,876 GitHub repositories, identifying 3,709 reuse links. It uses LLM classification to map skills to SWEBOK knowledge areas (finding Software Construction dominant), performs thematic analysis on 180 skills to derive six content categories, and qualitatively codes 444 modifications to identify six themes. The central observational claim is that reuse is largely a one-time copy operation, with 53% of reused skills never modified post-adoption, local maintenance overwhelmingly additive, customisation focused on local environments, evolution adding inline domain knowledge, and a stable behavioural contract remaining untouched across changes.
Significance. If the reuse-link detection and qualitative coding hold without selection bias or validation gaps, the work provides the first large-scale view of skills as reusable engineering artefacts rather than mere agent capabilities. The dataset scale (over 41k skills and 3.7k reuses) and the distinction between additive maintenance versus untouched contracts could usefully inform registry design and tool support for consolidating domain knowledge. No machine-checked proofs or parameter-free derivations are present, but the purely observational mining approach is appropriate for the research questions if the sampling and detection methods are shown to be unbiased.
major comments (3)
- [§3.2] §3.2 (Reuse Link Identification): The criteria and thresholds used to detect the 3,709 reuse links are not specified in sufficient detail. If the method relies on textual similarity, embedding cosine thresholds, or exact filename matches (standard in mining studies), then the sample is biased toward near-verbatim copies; this would render the claims that 'most reused skills remain near-verbatim' and '53% are never modified' partly definitional rather than observational, as heavily customised reuses would be systematically excluded.
- [§4.3] §4.3 (Qualitative Coding of Modifications): No inter-rater reliability statistics, sampling criteria for the 444 modifications, or validation details for the LLM-based SWEBOK classification are reported. This directly affects the soundness of the six themes (reworking operational specifications and adapting knowledge/resources as primary) and the inference that maintenance is 'overwhelmingly additive'.
- [§5] §5 (Discussion and Implications): The claim that the 18,463 + 23,199 skills and 3,709 links form a representative sample of real-world AI agent skill usage is asserted without justification or comparison to other adoption channels (e.g., private registries or non-GitHub repositories), weakening the generalisability of the 'one-time copy' and 'stable behavioural contract' conclusions.
minor comments (3)
- [§4] The mapping between the six content categories from the thematic analysis of 180 skills and the six modification themes is not explicitly cross-referenced in the results tables or figures, reducing clarity.
- [Results] Figure 2 (or equivalent distribution plot) lacks axis labels or legends clarifying the proportion of unmodified vs. modified reused skills, making the 53% statistic harder to verify visually.
- [Abstract and §4] The abstract states 'six content categories' and 'six themes' but the full text does not provide a concise summary table linking them to SWEBOK areas; adding one would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical study of AI agent skills. We address each major comment below, indicating planned revisions to improve clarity, methodological transparency, and discussion of limitations.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Reuse Link Identification): The criteria and thresholds used to detect the 3,709 reuse links are not specified in sufficient detail. If the method relies on textual similarity, embedding cosine thresholds, or exact filename matches (standard in mining studies), then the sample is biased toward near-verbatim copies; this would render the claims that 'most reused skills remain near-verbatim' and '53% are never modified' partly definitional rather than observational, as heavily customised reuses would be systematically excluded.
Authors: We agree the reuse-link detection criteria require fuller specification. In revision we will expand §3.2 with the exact matching procedure (including any similarity metric, threshold, or filename-based rule) and any manual validation performed. We will also add an explicit limitations paragraph noting that the method privileges detectable near-verbatim copies and that heavily customised reuses may be under-represented; the observational claim therefore applies to the class of reuses our detector can identify. revision: yes
-
Referee: [§4.3] §4.3 (Qualitative Coding of Modifications): No inter-rater reliability statistics, sampling criteria for the 444 modifications, or validation details for the LLM-based SWEBOK classification are reported. This directly affects the soundness of the six themes (reworking operational specifications and adapting knowledge/resources as primary) and the inference that maintenance is 'overwhelmingly additive'.
Authors: We will revise §4.3 to report (a) the sampling frame and selection criteria used to obtain the 444 modifications, (b) any inter-rater reliability statistics obtained during thematic coding, and (c) validation steps (e.g., human review of a subsample) for the LLM SWEBOK classifier. These additions will allow readers to assess the reliability of the six themes and the additive-maintenance inference. revision: yes
-
Referee: [§5] §5 (Discussion and Implications): The claim that the 18,463 + 23,199 skills and 3,709 links form a representative sample of real-world AI agent skill usage is asserted without justification or comparison to other adoption channels (e.g., private registries or non-GitHub repositories), weakening the generalisability of the 'one-time copy' and 'stable behavioural contract' conclusions.
Authors: We will strengthen §5 by (i) explicitly stating the scope of the sampled sources (public skills.sh registry and GitHub personal repositories), (ii) comparing coverage where public data permit, and (iii) adding a dedicated limitations subsection that qualifies generalisability to other channels such as private registries. The core observational findings will be framed as applying to the studied public corpus rather than asserted as universally representative. revision: yes
Circularity Check
No circularity: purely observational empirical study with no derivations or self-referential reductions
full rationale
The paper conducts data mining of public registries and GitHub repositories followed by LLM classification, thematic analysis, and qualitative coding. No equations, fitted parameters, predictions derived from subsets, or self-citation chains appear in the abstract or described approach. The 3,709 reuse links and modification counts are presented as direct observational outputs rather than constructed by definition. The skeptic concern about detection thresholds cannot be evaluated as circularity without an explicit paper quote showing the identification method reduces the 'near-verbatim' claim to a definitional artifact; per rules, no such reduction is exhibited. The study is self-contained against external benchmarks of mined artifacts.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SWEBOK knowledge areas provide an appropriate taxonomy for classifying AI agent skill content.
- domain assumption Identified reuse links and modification histories accurately reflect actual adoption and maintenance behavior.
Reference graph
Works this paper leans on
-
[1]
Codereval: A benchmark of pragmatic code generation with generative pre-trained models,
H. Yu, B. Shen, D. Ran, J. Zhang, Q. Zhang, Y . Ma, G. Liang, Y . Li, Q. Wang, and T. Xie, “Codereval: A benchmark of pragmatic code generation with generative pre-trained models,” inProceedings of the 46th IEEE/ACM International Conference on Software Engineering, 2024, pp. 1–12
2024
-
[2]
Codere- viewqa: The code review comprehension assessment for large language models,
H. Y . Lin, C. Liu, H. Gao, P. Thongtanunam, and C. Treude, “Codere- viewqa: The code review comprehension assessment for large language models,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 9138–9166
2025
-
[3]
Repairagent: An autonomous, llm-based agent for program repair,
I. Bouzenia, P. Devanbu, and M. Pradel, “Repairagent: An autonomous, llm-based agent for program repair,” in2025 IEEE/ACM 47th Interna- tional Conference on Software Engineering (ICSE). IEEE, 2025, pp. 2188–2200
2025
-
[4]
An empirical evaluation of using large language models for automated unit test generation,
M. Sch ¨afer, S. Nadi, A. Eghbali, and F. Tip, “An empirical evaluation of using large language models for automated unit test generation,”IEEE Transactions on Software Engineering, vol. 50, no. 1, pp. 85–105, 2023
2023
-
[5]
Does my readme file need to be updated? exploring llm-based readme maintenance,
H. Gao, H. Y . Lin, C. Treude, G. Gay, and M. Zahedi, “Does my readme file need to be updated? exploring llm-based readme maintenance,”arXiv preprint arXiv:2603.00489, 2026
-
[6]
The Agent Skills Directory — skills.sh,
“The Agent Skills Directory — skills.sh,” https://www.skills.sh/, [Ac- cessed 28-06-2026]
2026
-
[7]
G. Ling, S. Zhong, and R. Huang, “Agent skills: A data-driven analysis of claude skills for extending large language model functionality,”arXiv preprint arXiv:2602.08004, 2026
-
[8]
Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
Y . Liu, W. Wang, R. Feng, Y . Zhang, G. Xu, G. Deng, Y . Li, and L. Zhang, “Agent skills in the wild: An empirical study of security vulnerabilities at scale,”arXiv preprint arXiv:2601.10338, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
How Your Credentials Are Leaked by LLM Agent Skills: An Empirical Study
Z. Chen, Y . Zhang, Y . Liu, G. Deng, Y . Li, Y . Zhang, J. Ning, L. Y . Zhang, L. Ma, and Z. Li, “Credential leakage in llm agent skills: A large-scale empirical study,”arXiv preprint arXiv:2604.03070, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
X. Li, W. Chen, Y . Liu, S. Zheng, X. Chen, Y . He, Y . Li, B. You, H. Shen, J. Sunet al., “Skillsbench: Benchmarking how well agent skills work across diverse tasks,”arXiv preprint arXiv:2602.12670, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
On the untriviality of trivial packages: An empirical study of npm javascript packages,
M. A. R. Chowdhury, R. Abdalkareem, E. Shihab, and B. Adams, “On the untriviality of trivial packages: An empirical study of npm javascript packages,”IEEE Transactions on Software Engineering, vol. 48, no. 8, pp. 2695–2708, 2021
2021
-
[12]
Small world with high risks: A study of security threats in the npm ecosystem,
M. Zimmermann, C.-A. Staicu, C. Tenny, and M. Pradel, “Small world with high risks: A study of security threats in the npm ecosystem,” in28th USENIX Security symposium (USENIX security 19), 2019, pp. 995–1010
2019
-
[13]
An empirical comparison of dependency network evolution in seven software packaging ecosystems,
A. Decan, T. Mens, and P. Grosjean, “An empirical comparison of dependency network evolution in seven software packaging ecosystems,” Empirical Software Engineering, vol. 24, no. 1, pp. 381–416, 2019
2019
-
[14]
Adapting installation instructions in rapidly evolving software ecosystems,
H. Gao, C. Treude, and M. Zahedi, “Adapting installation instructions in rapidly evolving software ecosystems,”IEEE Transactions on Software Engineering, 2025
2025
-
[15]
Software documentation issues unveiled,
E. Aghajani, C. Nagy, O. L. Vega-M ´arquez, M. Linares-V ´asquez, L. Moreno, G. Bavota, and M. Lanza, “Software documentation issues unveiled,” in2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 2019, pp. 1199–1210
2019
-
[16]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Large language models for software engi- neering: A systematic literature review,
X. Hou, Y . Zhao, Y . Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, and H. Wang, “Large language models for software engi- neering: A systematic literature review,”ACM Transactions on Software Engineering and Methodology, vol. 33, no. 8, 2024
2024
-
[18]
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
J. White, Q. Fu, S. Hays, M. Sandborn, C. Olea, H. Gilbert, A. El- nashar, J. Spencer-Smith, and D. C. Schmidt, “A prompt pattern catalog to enhance prompt engineering with chatgpt,”arXiv preprint arXiv:2302.11382, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR), 2023
2023
-
[20]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[21]
SWE-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[22]
SWE-bench: Can language models resolve real-world GitHub issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “SWE-bench: Can language models resolve real-world GitHub issues?” inInternational Conference on Learning Representa- tions (ICLR), 2024
2024
-
[23]
Large Language Model-Based Agents for Software Engineering: A Survey
J. Liu, K. Wang, Y . Chen, X. Peng, Z. Chen, L. Zhang, and Y . Lou, “Large language model-based agents for software engineering: A sur- vey,”arXiv preprint arXiv:2409.02977, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
X. Hou, Y . Zhao, S. Wang, and H. Wang, “Model context protocol (MCP): Landscape, security threats, and future research directions,” arXiv preprint arXiv:2503.23278, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
M. M. Hasan, H. Li, E. Fallahzadeh, G. K. Rajbahadur, B. Adams, and A. E. Hassan, “Model context protocol (MCP) at first glance: Study- ing the security and maintainability of MCP servers,”arXiv preprint arXiv:2506.13538, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Agent READMEs: An empirical study of context files for agentic coding,
W. Chatlatanagulchai, H. Li, Y . Kashiwa, B. Reid, K. Thonglek, P. Lee- laprute, A. Rungsawang, B. Manaskasemsak, B. Adams, A. E. Hassan, and H. Iida, “Agent READMEs: An empirical study of context files for agentic coding,”arXiv preprint arXiv:2511.12884, 2025
-
[27]
On the use of agentic coding manifests: An empirical study of Claude Code,
W. Chatlatanagulchai, K. Thonglek, B. Reid, Y . Kashiwa, P. Leelaprute, A. Rungsawang, B. Manaskasemsak, and H. Iida, “On the use of agentic coding manifests: An empirical study of Claude Code,”arXiv preprint arXiv:2509.14744, 2025
-
[28]
On the impact of agents.md files on the efficiency of ai coding agents,
J. L. Lulla, S. Mohsenimofidi, M. Galster, J. M. Zhang, S. Baltes, and C. Treude, “On the impact of agents.md files on the efficiency of ai coding agents,” inProceedings of the 1st Journal Ahead Workshop (JAWs) at the International Conference on Software Engineering (ICSE), 2026, accepted. [Online]. Available: https://arxiv.org/abs/2601.20404
-
[29]
An empirical study of usages, updates and risks of third-party libraries in Java projects,
Y . Wang, B. Chen, K. Huang, B. Shi, C. Xu, X. Peng, Y . Wu, and Y . Liu, “An empirical study of usages, updates and risks of third-party libraries in Java projects,” in2020 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2020
2020
-
[30]
Backstabber’s knife collection: A review of open source software supply chain attacks,
M. Ohm, H. Plate, A. Sykosch, and M. Meier, “Backstabber’s knife collection: A review of open source software supply chain attacks,” in International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment (DIMVA). Springer, 2020
2020
-
[31]
SoK: Taxonomy of attacks on open-source software supply chains,
P. Ladisa, H. Plate, M. Martinez, and O. Barais, “SoK: Taxonomy of attacks on open-source software supply chains,” in2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2023
2023
-
[32]
An empirical study of pre-trained model reuse in the Hugging Face deep learning model registry,
W. Jiang, N. Synovic, M. Hyatt, T. R. Schorlemmer, R. Sethi, Y .- H. Lu, G. K. Thiruvathukal, and J. C. Davis, “An empirical study of pre-trained model reuse in the Hugging Face deep learning model registry,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2023
2023
-
[33]
PeaTMOSS: A dataset and initial analysis of pre-trained models in open-source software,
W. Jiang, J. Yasmin, J. Jones, N. Synovic, J. Kuo, N. Bielanski, Y . Tian, G. K. Thiruvathukal, and J. C. Davis, “PeaTMOSS: A dataset and initial analysis of pre-trained models in open-source software,” in 2024 IEEE/ACM 21st International Conference on Mining Software Repositories (MSR). IEEE, 2024
2024
-
[34]
Programs, life cycles, and laws of software evolution,
M. M. Lehman, “Programs, life cycles, and laws of software evolution,” Proceedings of the IEEE, vol. 68, no. 9, pp. 1060–1076, 1980
1980
-
[35]
A large-scale empirical study on code-comment inconsistencies,
F. Wen, C. Nagy, G. Bavota, and M. Lanza, “A large-scale empirical study on code-comment inconsistencies,” in2019 IEEE/ACM 27th International Conference on Program Comprehension (ICPC). IEEE, 2019, pp. 53–64
2019
-
[36]
Docable: Evaluating the executability of software tutorials,
S. Mirhosseini and C. Parnin, “Docable: Evaluating the executability of software tutorials,” inProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2020, pp. 375–385
2020
-
[37]
Cat- egorizing the content of GitHub README files,
G. A. A. Prana, C. Treude, F. Thung, T. Atapattu, and D. Lo, “Cat- egorizing the content of GitHub README files,”Empirical Software Engineering, vol. 24, pp. 1296–1327, 2019
2019
-
[38]
Augmenting api documentation with insights from stack overflow,
C. Treude and M. P. Robillard, “Augmenting api documentation with insights from stack overflow,” inProceedings of the 38th International Conference on Software Engineering, 2016, pp. 392–403
2016
-
[39]
Improving api caveats accessibility by mining api caveats knowledge graph,
H. Li, S. Li, J. Sun, Z. Xing, X. Peng, M. Liu, and X. Zhao, “Improving api caveats accessibility by mining api caveats knowledge graph,” in 2018 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 2018, pp. 183–193
2018
-
[40]
J. W. Tukey,Exploratory Data Analysis. Reading, MA: Addison- Wesley, 1977
1977
-
[41]
Software Engineering Body of Knowledge (SWEBOK) — com- puter.org,
“Software Engineering Body of Knowledge (SWEBOK) — com- puter.org,” https://www.computer.org/education/bodies-of-knowledge/ software-engineering#about, [Accessed 24-06-2026]
2026
-
[42]
Can llms re- place manual annotation of software engineering artifacts?
T. Ahmed, P. Devanbu, C. Treude, and M. Pradel, “Can llms re- place manual annotation of software engineering artifacts?” in2025 IEEE/ACM 22nd International Conference on Mining Software Reposi- tories (MSR). IEEE, 2025, pp. 526–538
2025
-
[43]
Interrater reliability: the kappa statistic,
M. L. McHugh, “Interrater reliability: the kappa statistic,”Biochemia medica, vol. 22, no. 3, pp. 276–282, 2012
2012
-
[44]
Specification - Agent Skills — agentskills.io,
“Specification - Agent Skills — agentskills.io,” https://agentskills.io/ specification, [Accessed 28-06-2026]
2026
-
[45]
Sampling in software engineering research: A critical review and guidelines,
S. Baltes and P. Ralph, “Sampling in software engineering research: A critical review and guidelines,”Empirical Software Engineering, vol. 27, no. 4, p. 94, 2022
2022
-
[46]
Recommended steps for thematic synthesis in software engineering,
D. S. Cruzes and T. Dyba, “Recommended steps for thematic synthesis in software engineering,” in2011 international symposium on empirical software engineering and measurement. IEEE, 2011, pp. 275–284
2011
-
[47]
Self-organizing roles on agile soft- ware development teams,
R. Hoda, J. Noble, and S. Marshall, “Self-organizing roles on agile soft- ware development teams,”IEEE Transactions on Software Engineering, vol. 39, no. 3, pp. 422–444, 2012
2012
-
[48]
Fisher’s exact test,
G. J. Upton, “Fisher’s exact test,”Journal of the Royal Statistical Society: Series A (Statistics in Society), vol. 155, no. 3, pp. 395–402, 1992
1992
-
[49]
Controlling the false discovery rate: a practical and powerful approach to multiple testing,
Y . Benjamini and Y . Hochberg, “Controlling the false discovery rate: a practical and powerful approach to multiple testing,”Journal of the Royal statistical society: series B (Methodological), vol. 57, no. 1, pp. 289–300, 1995
1995
-
[50]
Cohen,Statistical Power Analysis for the Behavioral Sciences, 2nd ed
J. Cohen,Statistical Power Analysis for the Behavioral Sciences, 2nd ed. Hillsdale, NJ: Lawrence Erlbaum Associates, 1988
1988
-
[51]
On a test of whether one of two random variables is stochastically larger than the other,
H. B. Mann and D. R. Whitney, “On a test of whether one of two random variables is stochastically larger than the other,”The annals of mathematical statistics, pp. 50–60, 1947
1947
-
[52]
Dominance statistics: Ordinal analyses to answer ordinal questions
N. Cliff, “Dominance statistics: Ordinal analyses to answer ordinal questions.”Psychological bulletin, vol. 114, no. 3, p. 494, 1993
1993
-
[53]
EASYTOOL: Enhancing LLM-based agents with concise tool instruction,
S. Yuan, K. Song, J. Chen, X. Tan, Y . Shen, K. Ren, D. Li, and D. Yang, “EASYTOOL: Enhancing LLM-based agents with concise tool instruction,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), L. Chiruzzo, A. Ritter, and L. Wang...
2025
-
[54]
SkillOps: Managing LLM Agent Skill Libraries as Self-Maintaining Software Ecosystems
H. Pu, X. Song, and L. Zhao, “Skillops: Managing llm agent skill libraries as self-maintaining software ecosystems,”arXiv preprint arXiv:2605.13716, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
An empirical study of the non-determinism of chatgpt in code generation,
S. Ouyang, J. M. Zhang, M. Harman, and M. Wang, “An empirical study of the non-determinism of chatgpt in code generation,”ACM Transactions on Software Engineering and Methodology, vol. 34, no. 2, pp. 1–28, 2025
2025
-
[56]
Let me speak freely? a study on the impact of format restrictions on large language model performance
Z. R. Tam, C.-K. Wu, Y .-L. Tsai, C.-Y . Lin, H.-y. Lee, and Y .-N. Chen, “Let me speak freely? a study on the impact of format restrictions on large language model performance.” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, 2024, pp. 1218–1236
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.