From Personas to Plot: Character-Grounded Multi-Agent Story Generation for Long-Form Narratives
Pith reviewed 2026-07-02 13:07 UTC · model grok-4.3
The pith
Multi-agent character agents grounded in personas and a shared world state generate longer coherent stories with fewer hallucinations than single-model baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
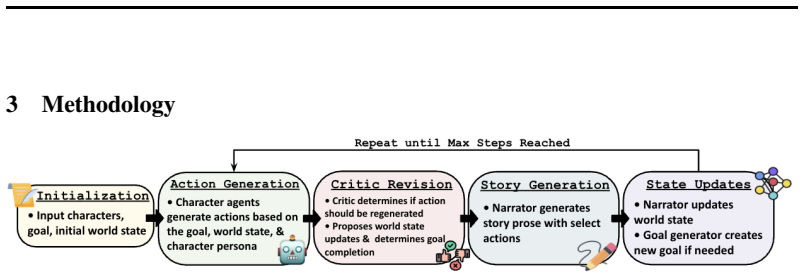
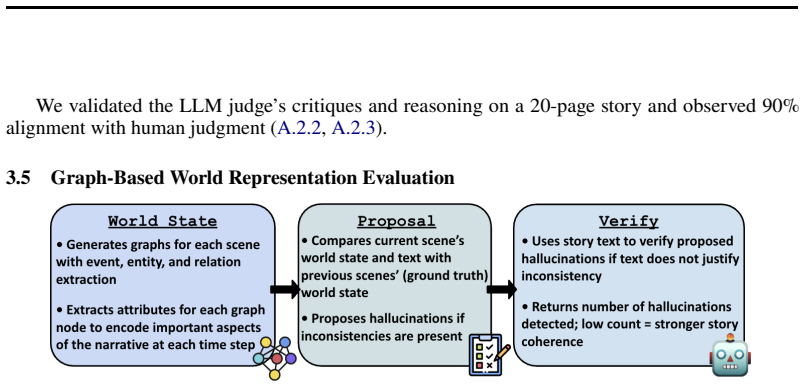
MAGNET generates stories with persona-grounded character agents that propose actions based on a shared world state and evolving story goals, while ATLAS is a graph-based pipeline that compares scene-level world representations across a generated story to detect hallucinations. By evaluating MAGNET using an LLM editor, pairwise rubric scoring, and ATLAS, the framework produces coherent narratives compared to single-model prompting and IBSEN. At 100 pages, MAGNET reduced annotations and hallucinations by 41 and 50 percent, respectively, compared to the single model baseline and by 34 and 45 percent, respectively, compared to IBSEN, with pairwise rubric evaluation showing similar results.
What carries the argument
MAGNET, the multi-agent goal-driven narrative engine in which persona-grounded agents propose actions from a shared world state and goals, paired with ATLAS, the graph-based pipeline that detects hallucinations by comparing scene-level world representations.
If this is right
- Explicit world-state tracking across agents can sustain plot consistency over lengths where monolithic generation fails.
- Goal-driven action proposals from separate character agents reduce the rate of introduced inconsistencies.
- Graph comparison of successive world states provides an automatic signal for locating hallucinations.
- The same multi-agent structure supports later editing or continuation without restarting from scratch.
- Pairwise human or LLM rubric comparisons can serve as an additional verification layer for long outputs.
Where Pith is reading between the lines
- The approach could be tested on interactive fiction where reader choices update the shared world state in real time.
- Replacing the current world-state representation with a more structured knowledge graph might further lower error rates.
- The reduction in hallucinations may depend on how richly the shared state encodes character motivations versus physical facts.
- Similar agent-plus-graph designs might apply to long technical reports or legal documents that require factual consistency.
Load-bearing premise
That LLM-based editing, pairwise rubric scoring, and the ATLAS graph comparisons supply unbiased measures of coherence and hallucination rather than artifacts of the same model family used to generate the stories.
What would settle it
A controlled human study in which independent readers rate coherence and factual errors in matched 100-page stories from MAGNET versus the single-model baseline and find no reliable difference.
Figures
read the original abstract
Although large language models (LLMs) have demonstrated impressive creative fiction generation, they struggle to maintain narrative consistency and coherent plot lines in long-form stories. In this work, we introduce a unified framework for long-form narrative generation and verification. MAGNET, a multi-agent goal-driven narrative engine for storytelling, generates stories with persona-grounded character agents that propose actions based on a shared world state and evolving story goals, while ATLAS is a graph-based pipeline that compares scene-level world representations across a generated story to detect hallucinations. By evaluating MAGNET using an LLM editor, pairwise rubric scoring, and ATLAS, we show that our framework produces coherent narratives compared to single-model prompting and IBSEN. At 100 pages, MAGNET reduced annotations and hallucinations by 41 and 50%, respectively, compared to the single model baseline and by 34 and 45%, respectively, compared to IBSEN, with pairwise rubric evaluation showing similar results. These results suggest that long-form narratives can emerge from explicit world-state tracking and goal-driven multi-agent generation, providing a foundation for controllable and structurally coherent long-form narrative generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MAGNET, a multi-agent goal-driven narrative engine using persona-grounded character agents that propose actions from a shared world state and evolving story goals, paired with ATLAS, a graph-based pipeline for detecting hallucinations via scene-level world representation comparisons. It claims that this framework generates more coherent long-form narratives than single-model prompting or the IBSEN baseline, with MAGNET reducing annotations and hallucinations by 41% and 50% (vs. baseline) and 34% and 45% (vs. IBSEN) at 100 pages, supported by LLM editor, pairwise rubric scoring, and ATLAS evaluations.
Significance. If the quantitative claims hold under independent evaluation, the explicit world-state tracking and goal-driven multi-agent coordination represent a substantive advance over monolithic prompting for long-form coherence, offering a verifiable foundation for controllable narrative generation. The dual generation-verification design is a clear methodological strength.
major comments (3)
- [Evaluation Methodology] Evaluation section (and abstract): the central 41%/50% and 34%/45% reduction claims at 100 pages are measured exclusively via an LLM editor, pairwise rubric scoring, and ATLAS, yet no model identities, prompt templates, temperature settings, or cross-family controls are reported for the evaluator pipeline versus the MAGNET generators. This directly undermines assessment of whether the gains reflect genuine improvement or evaluator alignment.
- [Results] Results section: no statistical significance tests, variance estimates, or exact rubric definitions are supplied for the annotation/hallucination counts or pairwise scores, leaving the headline quantitative comparisons unassessable and load-bearing for the superiority claim over baselines.
- [ATLAS Pipeline] ATLAS pipeline description: the graph-based hallucination detection is presented as an independent verifier, but the manuscript provides no details on whether its world-representation construction or comparison logic shares model weights, training data, or prompting assumptions with the MAGNET agents, creating an untested independence assumption for the 50%/45% hallucination reductions.
minor comments (2)
- [Abstract] Abstract: expand the acronyms MAGNET and ATLAS on first use and briefly indicate that ATLAS is used for both detection and evaluation.
- [Methods] Notation: the shared world state and evolving goals are central but introduced without a compact formal definition or diagram reference early in the methods.
Simulated Author's Rebuttal
Thank you for your thorough review and valuable feedback on our manuscript. We appreciate the recognition of the methodological strengths of MAGNET and ATLAS. We address each of the major comments below, committing to revisions that enhance the transparency and rigor of our evaluation.
read point-by-point responses
-
Referee: [Evaluation Methodology] Evaluation section (and abstract): the central 41%/50% and 34%/45% reduction claims at 100 pages are measured exclusively via an LLM editor, pairwise rubric scoring, and ATLAS, yet no model identities, prompt templates, temperature settings, or cross-family controls are reported for the evaluator pipeline versus the MAGNET generators. This directly undermines assessment of whether the gains reflect genuine improvement or evaluator alignment.
Authors: We agree that detailed reporting of the evaluator configuration is necessary to allow readers to assess potential biases from model alignment. In the revised version, we will add a dedicated subsection in the Evaluation section detailing the models used for the LLM editor, the exact prompt templates employed, temperature settings, and any cross-family controls or ablations performed. This will clarify that the evaluation was conducted with appropriate safeguards against evaluator-generator alignment. revision: yes
-
Referee: [Results] Results section: no statistical significance tests, variance estimates, or exact rubric definitions are supplied for the annotation/hallucination counts or pairwise scores, leaving the headline quantitative comparisons unassessable and load-bearing for the superiority claim over baselines.
Authors: We acknowledge the importance of statistical rigor and precise definitions for the reported metrics. We will revise the Results section to include statistical significance tests (such as paired t-tests with p-values), variance estimates across multiple story generations, and provide the exact rubric definitions and scoring criteria either in the main text or as a supplementary appendix. This will make the quantitative claims fully assessable and reproducible. revision: yes
-
Referee: [ATLAS Pipeline] ATLAS pipeline description: the graph-based hallucination detection is presented as an independent verifier, but the manuscript provides no details on whether its world-representation construction or comparison logic shares model weights, training data, or prompting assumptions with the MAGNET agents, creating an untested independence assumption for the 50%/45% hallucination reductions.
Authors: We will expand the description of the ATLAS pipeline to explicitly detail its independence from the MAGNET generation process. We will specify the model configurations, prompting strategies, and any measures taken to ensure no shared weights, training data, or assumptions between the verifier and the generators. This will substantiate the independence assumption underlying the hallucination reduction claims. revision: yes
Circularity Check
No circularity in claimed results or evaluation pipeline
full rationale
The paper presents an empirical multi-agent framework (MAGNET) and graph-based detector (ATLAS) for long-form story generation, with performance quantified via LLM editor, rubric scoring, and ATLAS comparisons. No derivation chain, first-principles prediction, fitted parameter, or self-citation is described that reduces by construction to its own inputs. The reported reductions (41%/50% vs baseline, 34%/45% vs IBSEN) are presented as measured outcomes from the evaluation methods rather than self-definitional or statistically forced quantities. The abstract and described text contain no equations, ansatzes, uniqueness theorems, or renamings that match the enumerated circularity patterns. The evaluation pipeline is treated as an external verification step without evidence of definitional interdependence with the generator.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs prompted as character agents will propose actions consistent with a fixed persona and shared world state over long horizons.
- domain assumption Scene-level world representations can be extracted and compared by graph methods to detect hallucinations.
invented entities (2)
-
MAGNET multi-agent goal-driven narrative engine
no independent evidence
-
ATLAS graph-based hallucination detection pipeline
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
2024
-
[2]
2019 , eprint=
Plan-And-Write: Towards Better Automatic Storytelling , author=. 2019 , eprint=
2019
-
[3]
2026 , eprint=
The Assistant Axis: Situating and Stabilizing the Default Persona of Language Models , author=. 2026 , eprint=
2026
-
[4]
2023 , eprint=
Character-LLM: A Trainable Agent for Role-Playing , author=. 2023 , eprint=
2023
-
[5]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[6]
2024 , eprint=
RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models , author=. 2024 , eprint=
2024
-
[7]
2024 , eprint=
AgentScope: A Flexible yet Robust Multi-Agent Platform , author=. 2024 , eprint=
2024
-
[8]
2023 , eprint=
Generative Agents: Interactive Simulacra of Human Behavior , author=. 2023 , eprint=
2023
-
[9]
2026 , eprint=
Lost in Stories: Consistency Bugs in Long Story Generation by LLMs , author=. 2026 , eprint=
2026
-
[10]
2024 , eprint=
StoryVerse: Towards Co-authoring Dynamic Plot with LLM-based Character Simulation via Narrative Planning , author=. 2024 , eprint=
2024
-
[11]
2025 , eprint=
Agents' Room: Narrative Generation through Multi-step Collaboration , author=. 2025 , eprint=
2025
-
[12]
2026 , eprint=
Narrative Theory-Driven LLM Methods for Automatic Story Generation and Understanding: A Survey , author=. 2026 , eprint=
2026
-
[13]
2025 , url=
A Survey on LLMs for Story Generation , author=. 2025 , url=
2025
-
[14]
2021 , eprint=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2021 , eprint=
2021
-
[15]
2023 , eprint=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
2023
-
[16]
Ha, David and Schmidhuber, Jürgen , title =. 2018 , copyright =. doi:10.5281/ZENODO.1207631 , url =
-
[17]
2026 , eprint=
TDGNet: Hallucination Detection in Diffusion Language Models via Temporal Dynamic Graphs , author=. 2026 , eprint=
2026
-
[18]
2026 , eprint=
CausalGaze: Unveiling Hallucinations via Counterfactual Graph Intervention in Large Language Models , author=. 2026 , eprint=
2026
-
[19]
2025 , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
2025
-
[20]
2026 , url=
Claude Opus 4.7 , author=. 2026 , url=
2026
-
[21]
2026 , url=
Claude Sonnet 4.6 , author=. 2026 , url=
2026
-
[22]
2026 , url=
Gemma 4 model card , author=. 2026 , url=
2026
-
[23]
2026 , url=
GPT-5.4 mini Model , author=. 2026 , url=
2026
-
[24]
2026 , url=
GPT-5.4 Model , author=. 2026 , url=
2026
-
[25]
2025 , eprint=
StoryWriter: A Multi-Agent Framework for Long Story Generation , author=. 2025 , eprint=
2025
-
[26]
2024 , eprint=
IBSEN: Director-Actor Agent Collaboration for Controllable and Interactive Drama Script Generation , author=. 2024 , eprint=
2024
-
[27]
2024 , eprint=
MemGPT: Towards LLMs as Operating Systems , author=. 2024 , eprint=
2024
-
[28]
2026 , eprint=
From World-Gen to Quest-Line: A Dependency-Driven Prompt Pipeline for Coherent RPG Generation , author=. 2026 , eprint=
2026
-
[29]
2023 , eprint=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. 2023 , eprint=
2023
-
[30]
2025 , eprint=
WoW: Towards a World omniscient World model Through Embodied Interaction , author=. 2025 , eprint=
2025
-
[31]
2025 , eprint=
Understanding World or Predicting Future? A Comprehensive Survey of World Models , author=. 2025 , eprint=
2025
-
[32]
2026 , eprint=
From Word to World: Can Large Language Models be Implicit Text-based World Models? , author=. 2026 , eprint=
2026
-
[33]
2026 , eprint=
Beyond State Consistency: Behavior Consistency in Text-Based World Models , author=. 2026 , eprint=
2026
-
[34]
2019 , eprint=
TextWorld: A Learning Environment for Text-based Games , author=. 2019 , eprint=
2019
-
[35]
2026 , eprint=
STAGE: A Full-Screenplay Benchmark for Reasoning over Evolving Storie , author=. 2026 , eprint=
2026
-
[36]
2025 , eprint=
LongEval: A Comprehensive Analysis of Long-Text Generation Through a Plan-based Paradigm , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
SCORE: Story Coherence and Retrieval Enhancement for AI Narratives , author=. 2025 , eprint=
2025
-
[38]
2024 , eprint=
EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models , author=. 2024 , eprint=
2024
-
[39]
Echoes in AI: Quantifying lack of plot diversity in LLM outputs , volume=
Xu, Weijia and Jojic, Nebojsa and Rao, Sudha and Brockett, Chris and Dolan, Bill , year=. Echoes in AI: Quantifying lack of plot diversity in LLM outputs , volume=. Proceedings of the National Academy of Sciences , publisher=. doi:10.1073/pnas.2504966122 , number=
-
[40]
2025 , eprint=
How Does Response Length Affect Long-Form Factuality , author=. 2025 , eprint=
2025
-
[41]
Transactions of the Association for Computational Linguistics , volume =
The NarrativeQA Reading Comprehension Challenge , author =. Transactions of the Association for Computational Linguistics , volume =. 2018 , doi =
2018
-
[42]
arXiv preprint arXiv:2305.06590 , year =
FactKG: Fact Verification via Reasoning on Knowledge Graphs , author =. arXiv preprint arXiv:2305.06590 , year =
-
[43]
Grapheval: A knowledge- graph based llm hallucination evaluation framework,
GraphEval: A Knowledge-Graph Based LLM Hallucination Evaluation Framework , author =. arXiv preprint arXiv:2407.10793 , year =
-
[44]
2025 , eprint=
FactTrack: Time-Aware World State Tracking in Story Outlines , author=. 2025 , eprint=
2025
-
[45]
2025 , eprint=
NarraBench: A Comprehensive Framework for Narrative Benchmarking , author=. 2025 , eprint=
2025
-
[46]
arXiv preprint arXiv:2105.08920 , year=
OpenMEVA: A Benchmark for Evaluating Open-ended Story Generation Metrics , author=. arXiv preprint arXiv:2105.08920 , year=
-
[47]
arXiv preprint arXiv:2208.11646 , year=
Of Human Criteria and Automatic Metrics: A Benchmark of the Evaluation of Story Generation , author=. arXiv preprint arXiv:2208.11646 , year=
-
[48]
arXiv preprint arXiv:2210.08459 , year=
StoryER: Automatic Story Evaluation via Ranking, Rating and Reasoning , author=. arXiv preprint arXiv:2210.08459 , year=
-
[49]
arXiv preprint arXiv:2210.06774 , year=
Re3: Generating Longer Stories With Recursive Reprompting and Revision , author=. arXiv preprint arXiv:2210.06774 , year=
-
[50]
arXiv preprint arXiv:2503.05244 , year=
WritingBench: A Comprehensive Benchmark for Generative Writing , author=. arXiv preprint arXiv:2503.05244 , year=
-
[51]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[52]
2023 , eprint=
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , author=. 2023 , eprint=
2023
-
[53]
2026 , eprint=
EvolvR: Self-Evolving Pairwise Reasoning for Story Evaluation to Enhance Generation , author=. 2026 , eprint=
2026
-
[54]
2026 , eprint=
Autorubric: Unifying Rubric-based LLM Evaluation , author=. 2026 , eprint=
2026
-
[55]
Wang, Ruiqi and Guo, Jiyu and Gao, Cuiyun and Fan, Guodong and Chong, Chun Yong and Xia, Xin , year=. Can LLMs Replace Human Evaluators? An Empirical Study of LLM-as-a-Judge in Software Engineering , volume=. Proceedings of the ACM on Software Engineering , publisher=. doi:10.1145/3728963 , number=
-
[56]
2024 , eprint=
Prometheus: Inducing Fine-grained Evaluation Capability in Language Models , author=. 2024 , eprint=
2024
-
[57]
2025 , eprint=
A Survey on LLM-as-a-Judge , author=. 2025 , eprint=
2025
-
[58]
2025 , eprint=
Aligning with Human Judgement: The Role of Pairwise Preference in Large Language Model Evaluators , author=. 2025 , eprint=
2025
-
[59]
2024 , eprint=
LLM-State: Open World State Representation for Long-horizon Task Planning with Large Language Model , author=. 2024 , eprint=
2024
-
[60]
2024 , eprint=
HelloBench: Evaluating Long Text Generation Capabilities of Large Language Models , author=. 2024 , eprint=
2024
-
[61]
2025 , eprint=
HalluLens: LLM Hallucination Benchmark , author=. 2025 , eprint=
2025
-
[62]
2023 , eprint=
HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.