Post-Training Pruning for Diffusion Transformers
Pith reviewed 2026-07-02 13:52 UTC · model grok-4.3
The pith
DiT-Pruning uses an energy-based saliency metric and clustering-aware granularity to prune diffusion transformers while preserving image quality at high sparsity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DiT-Pruning improves post-training pruning of diffusion transformers by replacing LLM-derived saliency approximations with an energy-based criterion that balances weights and activations, while replacing uniform granularity with a clustering-aware allocation that matches distinct two-dimensional patterns in DiT weight space; this combination maintains generation quality far better than prior methods under high sparsity.
What carries the argument
Energy-based saliency metric that balances weight and activation contributions, paired with clustering-aware pruning granularity derived from two-dimensional weight-space patterns.
If this is right
- DiT-Pruning produces only a 0.001 CLIP score drop on FLUX.1-dev at 512x512 resolution and 50 percent sparsity on MJHQ.
- The method consistently outperforms recent pruning approaches on multiple DiT models while preserving image quality.
- Clustering-aware granularity enables more effective sparse allocation than structure-agnostic baselines.
- Post-training pruning becomes viable for DiTs without the severe degradation seen in LLM-adapted methods.
Where Pith is reading between the lines
- The same energy-balance approach might reduce memory footprint enough to run larger DiTs on consumer hardware.
- If the clustering pattern generalizes, similar granularity rules could apply to other attention-heavy generative architectures.
- Combining this pruning with quantization could compound efficiency gains beyond what either technique achieves alone.
Load-bearing premise
The two-dimensional clustering patterns observed in DiT weight space remain stable enough across architectures and datasets that the same energy-balance parameter works without retuning.
What would settle it
Apply DiT-Pruning at 50 percent sparsity to a DiT variant outside the evaluated set and measure whether CLIP score degradation on a standard benchmark stays below 0.005.
Figures

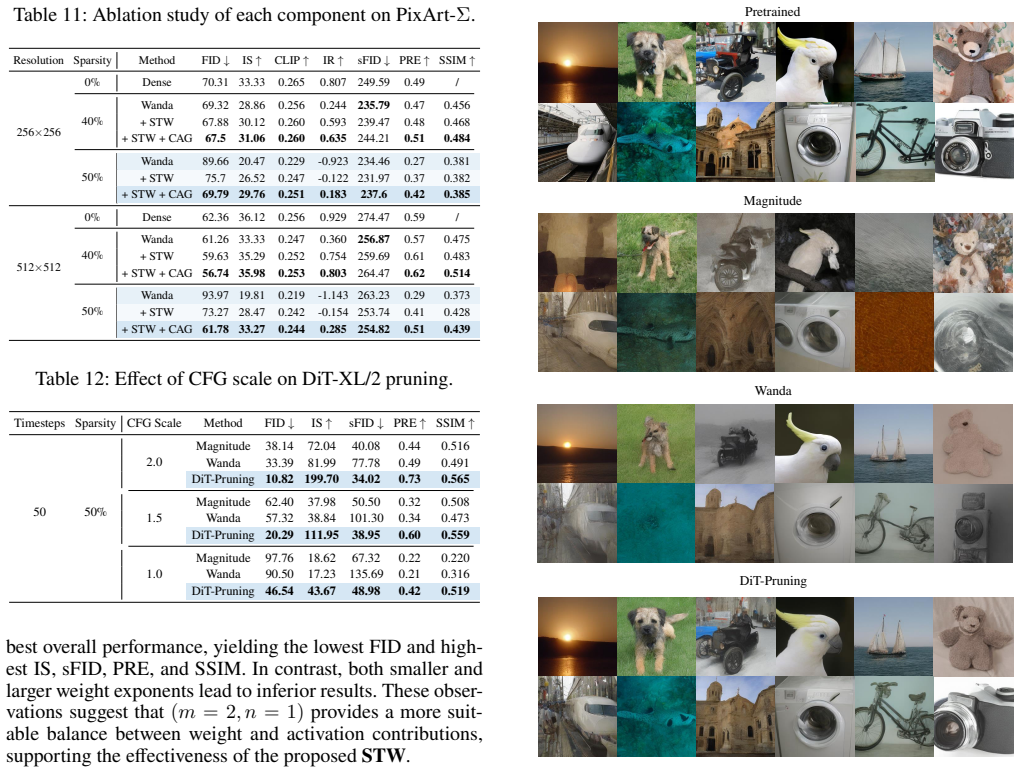


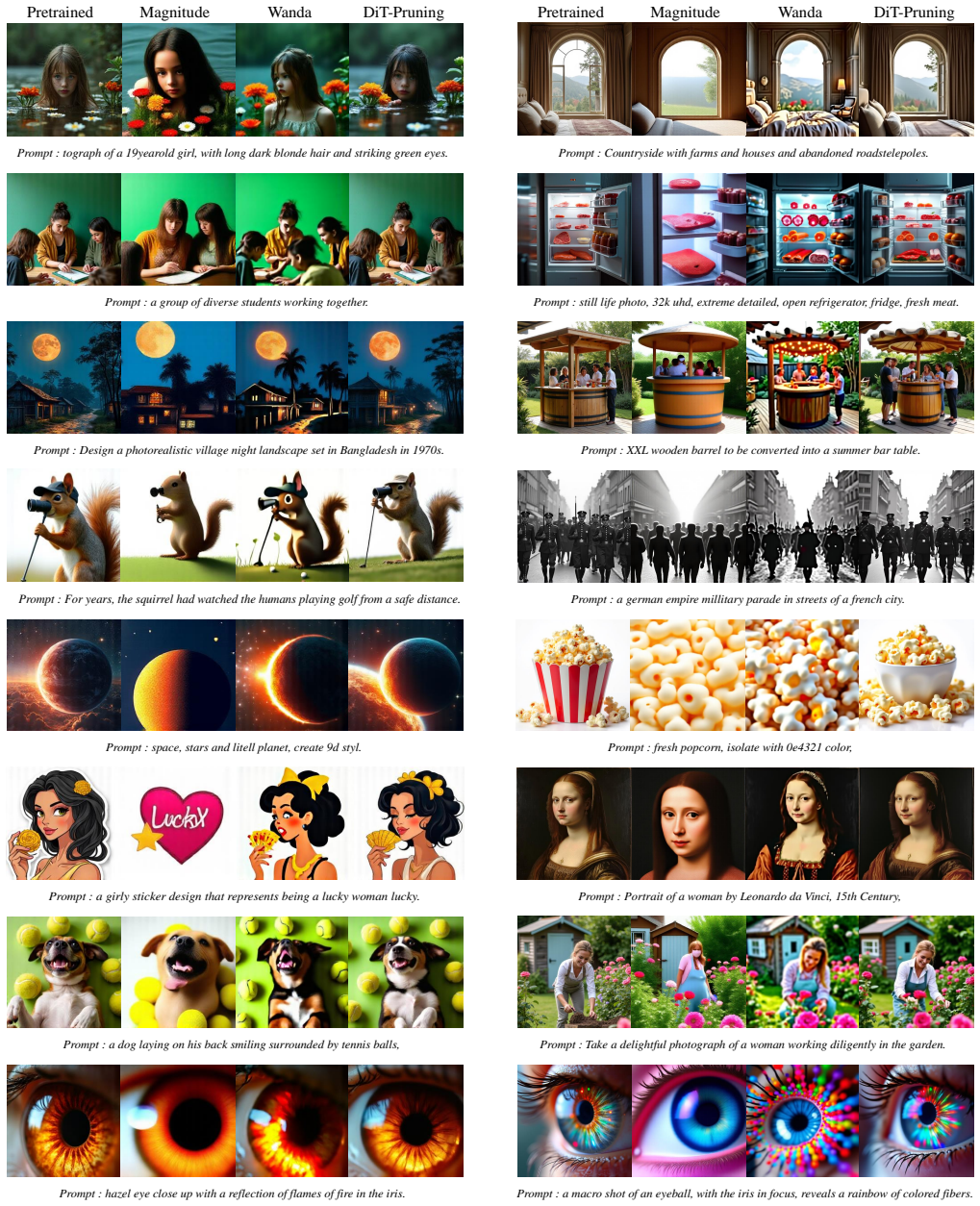
read the original abstract
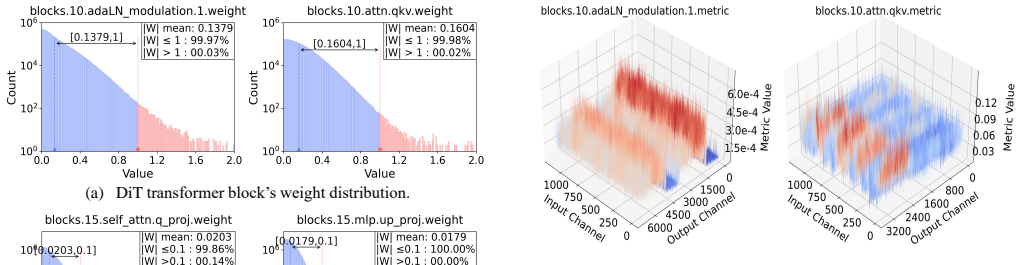
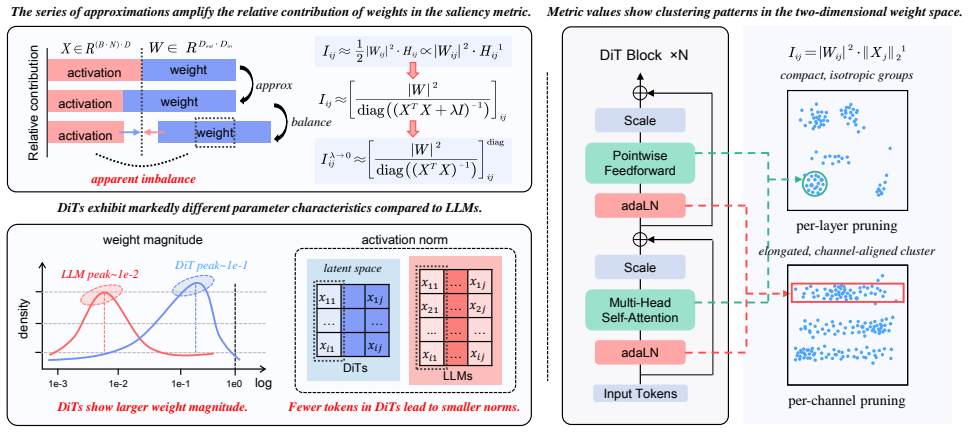
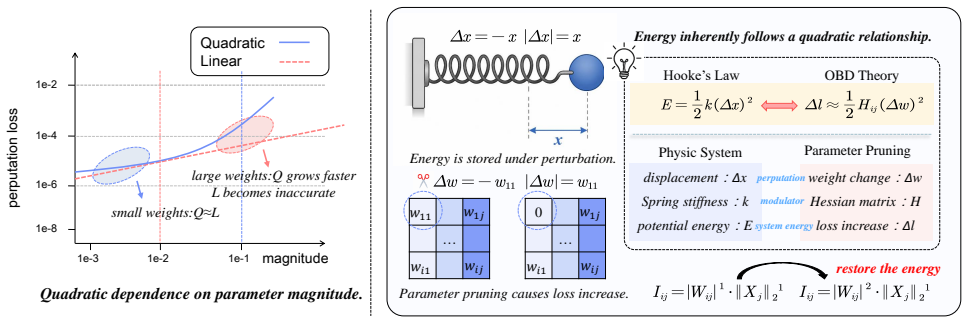
Diffusion Transformers (DiTs) have demonstrated impressive performance in image generation but suffer from substantial computational overhead and resource consumption. Post-training pruning offers a promising solution; however, due to DiTs' unique architectural design and parameter distribution, traditional pruning methods are inapplicable, leading to significant performance degradation. Specifically, prior methods developed for LLMs, which derive metrics through a series of approximations, amplify the relative contribution of weights in the saliency metric. In addition, weights in DiTs exhibit significantly larger magnitudes than those in LLMs. Moreover, existing pruning granularity overlooks variations in model structures. In this paper, we propose DiT-Pruning, which improves pruning performance by introducing customized saliency criteria and pruning granularity. We design a novel metric that balances the contributions of weights and activations from an energy-based perspective, enabling more effective identification of important elements. Furthermore, we observe distinct clustering patterns in the two-dimensional weight space. Accordingly, we adopt a clustering-aware pruning granularity, enabling effective sparse allocation. Extensive evaluations on various DiTs show that our method consistently preserves image quality, especially under high sparsity. For FLUX.1-dev at 512x512 resolution on MJHQ, DiT-Pruning achieves only a 0.001 loss in CLIP score at 50% sparsity, dramatically outperforming recent pruning methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DiT-Pruning, a post-training method for pruning Diffusion Transformers that replaces standard saliency metrics with a custom energy-based criterion balancing weight and activation contributions and adopts clustering-aware granularity based on observed 2D weight-space patterns. It reports that the approach preserves generation quality far better than prior LLM-derived methods at high sparsity levels, with a 0.001 CLIP-score drop at 50% sparsity on FLUX.1-dev (512×512, MJHQ) while outperforming recent baselines across multiple DiT models.
Significance. If the energy metric and clustering structure prove stable without per-model retuning, the work would supply a practical, architecture-aware pruning recipe that materially reduces the inference cost of large DiTs while keeping image quality nearly intact; the headline empirical margin is large enough to matter for deployment. The absence of derivation details, hyper-parameter sensitivity, and cross-architecture validation, however, leaves the central claim dependent on unverified assumptions.
major comments (3)
- [§3.1] §3.1 (Energy-based Saliency Metric): the balance scalar that weights the energy contributions of weights versus activations is introduced without an explicit equation, derivation, or procedure for its selection; because the entire saliency ranking depends on this scalar, the lack of any sensitivity analysis or cross-model stability test makes the reported 0.001 CLIP margin impossible to reproduce or generalize.
- [§3.2] §3.2 (Clustering-aware Granularity): the claim that 2D weight-space clustering patterns are stable across DiT architectures and permit effective sparse allocation is supported only by observations on the models used for the main tables; no ablation transferring the same clustering thresholds or patterns to held-out DiT variants is provided, directly undermining the assertion of consistent outperformance.
- [Results tables] Results tables (e.g., Table 2, FLUX.1-dev row): the headline metrics are reported as single-point values with neither error bars nor multiple random seeds, so it is impossible to determine whether the margin over baselines exceeds run-to-run variance.
minor comments (1)
- [Abstract / §3.2] The abstract states that patterns were 'observed' but supplies no figure or quantitative description of the 2D clustering; a brief illustration in §3.2 would clarify the granularity choice.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects for improving reproducibility and generalizability. We address each major comment below and will revise the manuscript to incorporate the suggested additions.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Energy-based Saliency Metric): the balance scalar that weights the energy contributions of weights versus activations is introduced without an explicit equation, derivation, or procedure for its selection; because the entire saliency ranking depends on this scalar, the lack of any sensitivity analysis or cross-model stability test makes the reported 0.001 CLIP margin impossible to reproduce or generalize.
Authors: We agree that the balance scalar requires an explicit formulation for reproducibility. In the revised version, we will add the precise equation defining the energy-based saliency metric (incorporating the scalar λ that balances weight and activation energy terms), a brief derivation from the energy perspective, and the selection procedure (calibration on a small held-out set). We will also include a sensitivity analysis varying λ across a range of values and report results on multiple DiT models to demonstrate stability of the 0.001 CLIP margin. revision: yes
-
Referee: [§3.2] §3.2 (Clustering-aware Granularity): the claim that 2D weight-space clustering patterns are stable across DiT architectures and permit effective sparse allocation is supported only by observations on the models used for the main tables; no ablation transferring the same clustering thresholds or patterns to held-out DiT variants is provided, directly undermining the assertion of consistent outperformance.
Authors: The clustering patterns were derived from empirical observations on the primary models. To strengthen the claim of stability, the revision will add an ablation study that applies the identical clustering thresholds and granularity rules to at least one additional held-out DiT architecture, reporting the resulting performance to confirm transferability and consistent outperformance. revision: yes
-
Referee: Results tables (e.g., Table 2, FLUX.1-dev row): the headline metrics are reported as single-point values with neither error bars nor multiple random seeds, so it is impossible to determine whether the margin over baselines exceeds run-to-run variance.
Authors: We acknowledge that single-point reporting limits variance assessment. Although the core pruning procedure is deterministic given fixed calibration data, the revision will include additional runs with varied random seeds for calibration-set sampling and will report means accompanied by standard deviations (error bars) in the updated tables. revision: yes
Circularity Check
No significant circularity; empirical design choices evaluated on held-out metrics
full rationale
The paper introduces an energy-based saliency metric and clustering-aware granularity based on observed 2D weight patterns, presented as empirical observations rather than a derivation chain. No equations, self-citations, or fitted parameters are shown that reduce the reported CLIP-score preservation or outperformance claims to quantities defined from the same data by construction. The strongest claim is an empirical result on held-out MJHQ evaluations, making the proposal self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- energy balance scalar
- clustering thresholds
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[2]
Chen, Junsong and Yu, Jincheng and Ge, Chongjian and Yao, Lewei and Xie, Enze and Wu, Yue and Wang, Zhongdao and Kwok, James and Luo, Ping and Lu, Huchuan and others , journal=. Pixart-
-
[3]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
FLUX. 1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space , author=. arXiv preprint arXiv:2506.15742 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Advances in neural information processing systems , volume=
Optimal brain damage , author=. Advances in neural information processing systems , volume=
-
[5]
IEEE international conference on neural networks , pages=
Optimal brain surgeon and general network pruning , author=. IEEE international conference on neural networks , pages=. 1993 , organization=
1993
-
[6]
Advances in neural information processing systems , volume=
Learning both weights and connections for efficient neural network , author=. Advances in neural information processing systems , volume=
-
[7]
Advances in Neural Information Processing Systems , volume=
Optimal brain compression: A framework for accurate post-training quantization and pruning , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Rethinking the Value of Network Pruning
Rethinking the value of network pruning , author=. arXiv preprint arXiv:1810.05270 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Proceedings of machine learning and systems , volume=
What is the state of neural network pruning? , author=. Proceedings of machine learning and systems , volume=
-
[10]
Pruning Convolutional Neural Networks for Resource Efficient Inference
Pruning convolutional neural networks for resource efficient inference , author=. arXiv preprint arXiv:1611.06440 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Advances in neural information processing systems , volume=
Are sixteen heads really better than one? , author=. Advances in neural information processing systems , volume=
-
[12]
International conference on machine learning , pages=
Sparsegpt: Massive language models can be accurately pruned in one-shot , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[13]
A Simple and Effective Pruning Approach for Large Language Models
A simple and effective pruning approach for large language models , author=. arXiv preprint arXiv:2306.11695 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in Neural Information Processing Systems , year=
Structural pruning for diffusion models , author=. Advances in Neural Information Processing Systems , year=
-
[15]
International Conference on Medical image computing and computer-assisted intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical image computing and computer-assisted intervention , pages=. 2015 , organization=
2015
-
[16]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[17]
The Thirteenth International Conference on Learning Representations , year=
SANA: Efficient high-resolution text-to-image synthesis with linear diffusion transformers , author=. The Thirteenth International Conference on Learning Representations , year=
-
[18]
Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding , author=. arXiv preprint arXiv:1510.00149 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Advances in Neural Information Processing Systems , volume=
A fast post-training pruning framework for transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
arXiv preprint arXiv:2002.04809 , year=
Lookahead: A far-sighted alternative of magnitude-based pruning , author=. arXiv preprint arXiv:2002.04809 , year=
-
[21]
Advances in neural information processing systems , volume=
Llm-pruner: On the structural pruning of large language models , author=. Advances in neural information processing systems , volume=
-
[22]
Advances in Neural Information Processing Systems , volume=
Slimgpt: Layer-wise structured pruning for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Structured optimal brain pruning for large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[24]
European conference on computer vision , pages=
Microsoft coco: Common objects in context , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[25]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Q-diffusion: Quantizing diffusion models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[26]
European Conference on Computer Vision , pages=
Mixdq: Memory-efficient few-step text-to-image diffusion models with metric-decoupled mixed precision quantization , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[27]
International conference on machine learning , pages=
Improved denoising diffusion probabilistic models , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Post-training quantization on diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[29]
Advances in neural information processing systems , volume=
Ptq4dit: Post-training quantization for diffusion transformers , author=. Advances in neural information processing systems , volume=
-
[30]
International journal of computer vision , volume=
Imagenet large scale visual recognition challenge , author=. International journal of computer vision , volume=. 2015 , publisher=
2015
-
[31]
Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
Playground v2. 5: Three insights towards enhancing aesthetic quality in text-to-image generation , author=. arXiv preprint arXiv:2402.17245 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Q-dit: Accurate post-training quantization for diffusion transformers , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[33]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[34]
arXiv preprint arXiv:2103.03841 , year=
Generating images with sparse representations , author=. arXiv preprint arXiv:2103.03841 , year=
-
[35]
Improved Techniques for Training GANs , volume =
Salimans, Tim and Goodfellow, Ian and Zaremba, Wojciech and Cheung, Vicki and Radford, Alec and Chen, Xi and Chen, Xi , booktitle =. Improved Techniques for Training GANs , volume =
-
[36]
A note on the inception score , author=. arXiv preprint arXiv:1801.01973 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Clipscore: A reference-free evaluation metric for image captioning , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[38]
Advances in Neural Information Processing Systems , volume=
Imagereward: Learning and evaluating human preferences for text-to-image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Advances in neural information processing systems , volume=
Improved precision and recall metric for assessing generative models , author=. Advances in neural information processing systems , volume=
-
[40]
IEEE transactions on image processing , volume=
Image quality assessment: from error visibility to structural similarity , author=. IEEE transactions on image processing , volume=. 2004 , publisher=
2004
-
[41]
Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis , pages=
Dasp: Specific dense matrix multiply-accumulate units accelerated general sparse matrix-vector multiplication , author=. Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis , pages=
-
[42]
arXiv preprint arXiv:2511.13061 , year=
MACKO: Sparse Matrix-Vector Multiplication for Low Sparsity , author=. arXiv preprint arXiv:2511.13061 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.