Aionoscope: Debugging Latent-State Accessibility in Time-Series Representations
Pith reviewed 2026-07-02 15:33 UTC · model grok-4.3
The pith
Time-series representations recover whether a signal type is present but often fail to expose its timing, phase, amplitude, frequency, or regime variables.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
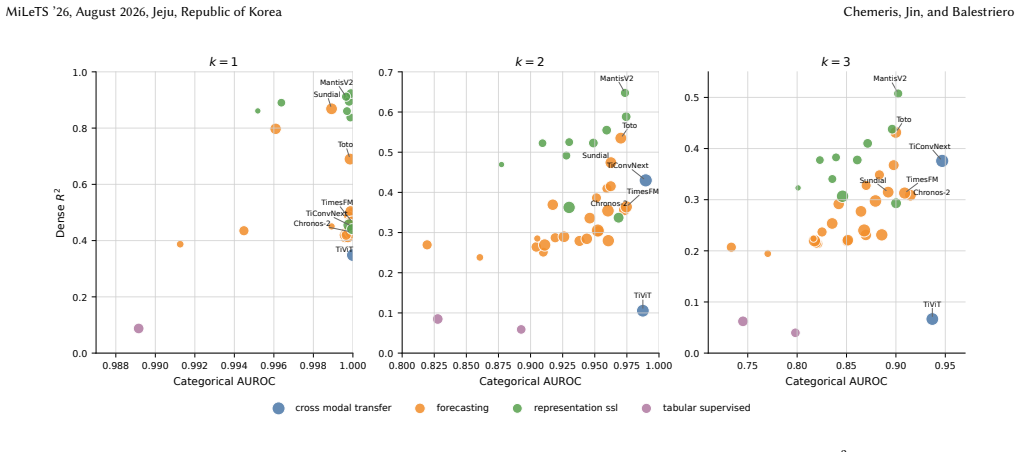
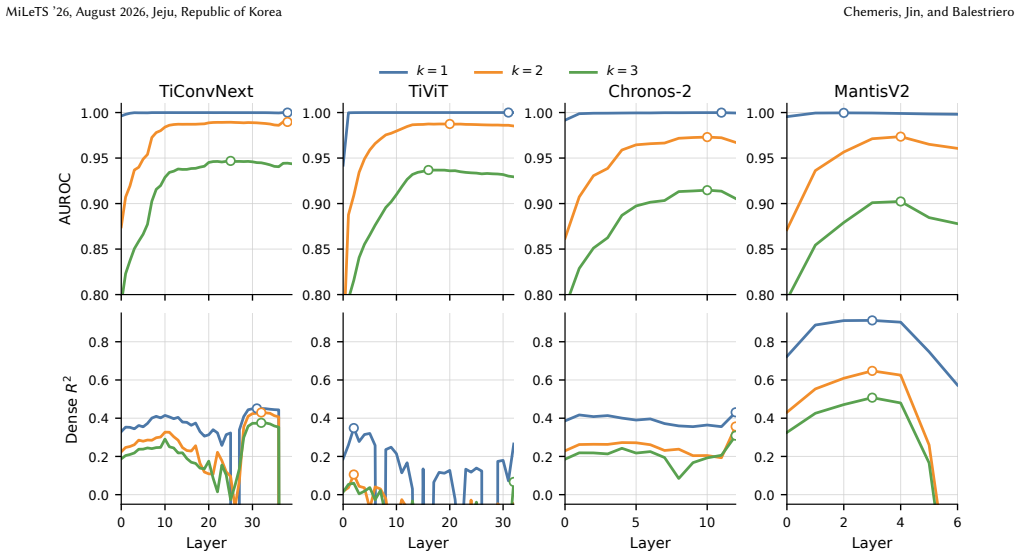
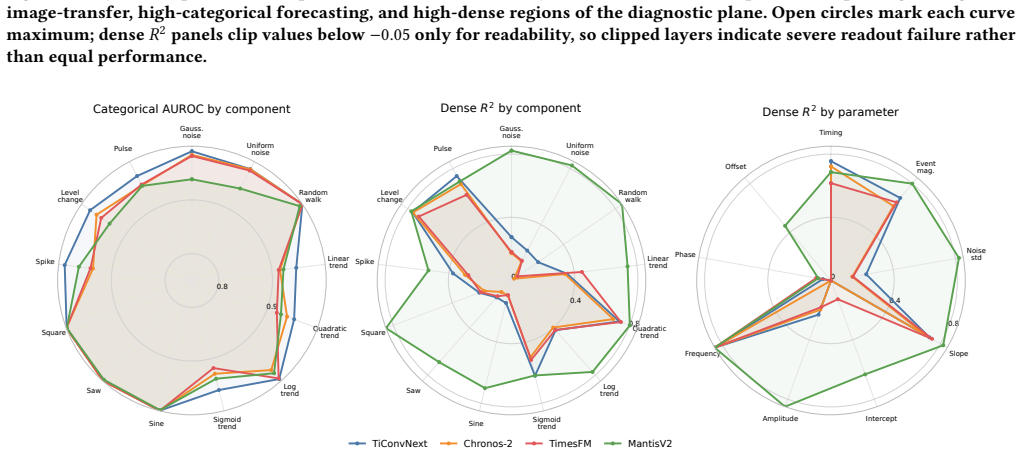
Aionoscope separates process generation from observation rendering to produce seeded synthetic streams carrying exact labels, and evaluation shows that most systems make component presence recoverable while exposing dense process state much less reliably, with the best dense probe at 0.689 mean masked R² versus 0.999 for a dense-feature oracle.
What carries the argument
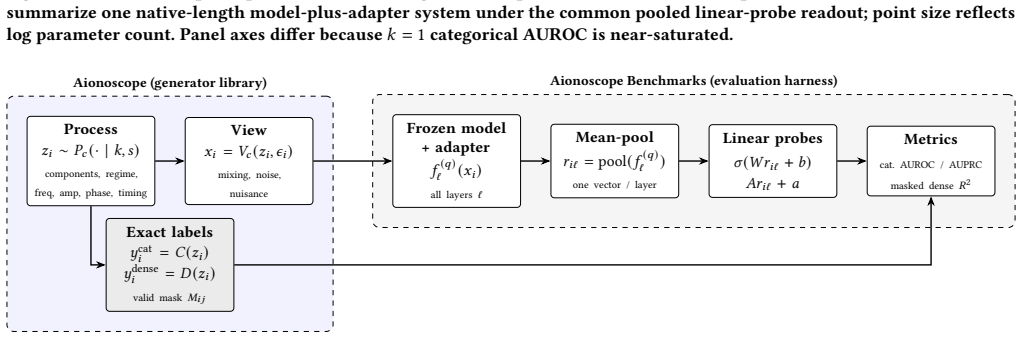
Aionoscope, a generator-based diagnostic tool that separates process generation from observation rendering to produce exact categorical and dense labels for probing.
If this is right
- Standard forecasting or classification scores can mask the absence of accessible dense state variables.
- Representations that pass coarse component tests may still block tasks that require precise timing, phase, or regime reconstruction.
- New training objectives or architectures would be needed to close the observed gap between coarse and fine-grained accessibility.
- The diagnostic can be applied to compare adapters or fine-tuning methods on the same frozen backbone.
Where Pith is reading between the lines
- If the synthetic mixtures capture essential nuisance structure from real data, the diagnostic could prioritize models for applications like anomaly detection or closed-loop control.
- Non-linear probes or attention readout methods might show higher dense accessibility than the linear protocol used here.
- The gap may explain why some time-series models struggle on downstream tasks that depend on internal phase or amplitude tracking.
Load-bearing premise
The linear-probe protocol on synthetic Primitive Process Mixtures data provides a faithful measure of latent-state accessibility that generalizes beyond the controlled mixtures.
What would settle it
Demonstrating a time-series representation that achieves mean masked R² above 0.95 on dense process variables using the same pooled linear-probe protocol on Primitive Process Mixtures data would falsify the reported mismatch.
Figures
read the original abstract
Time-series models are often evaluated by what they can forecast or classify, but those scores do not show whether their representations preserve the process state a user may want to inspect: event timing, phase, amplitude, frequency, or regime variables. We introduce Aionoscope, a generator-based diagnostic tool for debugging latent-state accessibility in frozen time-series representations. Aionoscope separates process generation from observation rendering, producing seeded synthetic streams with exact categorical and dense labels across mixture complexity and nuisance variation. We instantiate Aionoscope as Primitive Process Mixtures and evaluate 37 model-plus-adapter systems with a common pooled linear-probe protocol. The main result is a mismatch between coarse and fine-grained accessibility. Most systems make component presence easy to recover, but expose dense process state much less reliably: the highest observed dense-probe row reaches 0.689 mean masked $R^2$, while a dense-feature oracle reaches 0.999. This is the failure mode Aionoscope is designed to surface: a representation can look informative at the level of "what kind of signal is present" while hiding the timing, phase, amplitude, frequency, or regime variables needed for debugging.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Aionoscope, a generator-based diagnostic tool that separates process generation from observation rendering to produce seeded synthetic time-series streams (instantiated as Primitive Process Mixtures) with exact categorical and dense labels. It applies a common pooled linear-probe protocol to evaluate 37 model-plus-adapter systems and reports a systematic mismatch: component presence is readily recoverable, but dense process state accessibility is limited, with the highest mean masked R² reaching only 0.689 versus 0.999 for a dense-feature oracle.
Significance. If the linear-probe results on the controlled synthetic mixtures hold, the work supplies a reproducible diagnostic for surfacing gaps in latent-state accessibility that standard forecasting or classification metrics do not reveal. The explicit use of externally generated data with ground-truth labels and an oracle baseline is a clear strength that enables precise quantification of the reported mismatch.
major comments (1)
- [Evaluation protocol (as described following the abstract)] The central mismatch claim (0.689 mean masked R² vs. 0.999 oracle) rests on the linear-probe protocol over Primitive Process Mixtures, yet the manuscript provides insufficient detail on data-generation parameters, probe implementation, and statistical controls. This is load-bearing for interpreting whether the observed gap reflects a genuine accessibility limitation or an artifact of the evaluation setup.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the need for greater specificity in the evaluation protocol. We agree that the central mismatch result depends on a reproducible setup and will expand the manuscript to include the requested details. We address the single major comment below.
read point-by-point responses
-
Referee: The central mismatch claim (0.689 mean masked R² vs. 0.999 oracle) rests on the linear-probe protocol over Primitive Process Mixtures, yet the manuscript provides insufficient detail on data-generation parameters, probe implementation, and statistical controls. This is load-bearing for interpreting whether the observed gap reflects a genuine accessibility limitation or an artifact of the evaluation setup.
Authors: We acknowledge that the current text describes the protocol at a high level but does not enumerate the concrete parameters required for exact replication. In the revised version we will add a dedicated subsection (tentatively §3.2) that specifies: (i) data-generation parameters including the exact ranges and distributions for phase, amplitude, frequency, component counts, mixture weights, and nuisance factors; (ii) probe implementation details such as the linear model architecture, regularization strength, training procedure, masking strategy for the R² metric, and cross-validation scheme; and (iii) statistical controls including the number of random seeds, reported variance or confidence intervals, and any sensitivity checks. These additions will be accompanied by a table of hyperparameters and pseudocode for the generator. We believe the expanded description will allow readers to confirm that the reported gap is not an artifact of the chosen setup. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical diagnostic using externally generated synthetic Primitive Process Mixtures data with explicit ground-truth categorical and dense labels. Linear probes are trained on frozen representations to recover those labels, and results are compared to an oracle baseline on the original features. This produces direct measurements (e.g., mean masked R² values) without any reduction of outputs to fitted parameters by construction, self-definitional loops, or load-bearing self-citations. The protocol is self-contained against the controlled synthetic benchmark and does not rely on renaming known results or smuggling ansatzes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Guillaume Alain and Yoshua Bengio. 2016. Understanding Intermediate Layers Us- ing Linear Classifier Probes. https://arxiv.org/abs/1610.01644 arXiv:1610.01644
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Chronos: Learning the Language of Time Series
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebas- tian Pineda Arango, Shubham Kapoor, Jasper Zschiegner, Danielle C. Mad- dix, Hao Wang, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, and Yuyang Wang. 2024. Chronos: Learning the...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [4]
-
[5]
Yonatan Belinkov. 2022. Probing Classifiers: Promises, Shortcomings, and Ad- vances.Computational Linguistics48, 1 (2022), 207–219. doi:10.1162/coli_a_00422
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[6]
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. 2024. A Decoder- Only Foundation Model for Time-Series Forecasting. InProceedings of the 41st International Conference on Machine Learning. https://arxiv.org/abs/2310.10688 arXiv:2310.10688
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [7]
- [8]
-
[9]
John Hewitt and Percy Liang. 2019. Designing and Interpreting Probes with Control Tasks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. 2733–2743. doi:10.18653/v1/D19-1275
- [10]
- [11]
- [12]
-
[13]
Jungwoo Oh, Gyubok Lee, Seongsu Bae, Joon-myoung Kwon, and Edward Choi. 2023. ECG-QA: A Comprehensive Question Answering Dataset Com- bined With Electrocardiogram. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. https://proceedings.neurips.cc/paper_files/paper/2023/f...
2023
-
[14]
Aston, Ashish Sun- dar, Claus Graf, Jørgen K
Nils Strodthoff, Temesgen Mehari, Claudia Nagel, Philip J. Aston, Ashish Sun- dar, Claus Graf, Jørgen K. Kanters, Wilhelm Haverkamp, Olaf Dössel, Axel Loewe, Markus Bär, and Tobias Schaeffter. 2023. PTB-XL+, a comprehen- sive electrocardiographic feature dataset.Scientific Data10, 1 (2023), 279. doi:10.1038/s41597-023-02153-8
- [15]
-
[16]
Lunze, Wojciech Samek, and Tobias Schaeffter
Patrick Wagner, Nils Strodthoff, Ralf-Dieter Bousseljot, Dieter Kreiseler, Fatima I. Lunze, Wojciech Samek, and Tobias Schaeffter. 2020. PTB-XL, a large publicly available electrocardiography dataset.Scientific Data7, 1 (2020), 154. doi:10.1038/ s41597-020-0495-6
2020
-
[17]
Tianze Wang, Sofiane Ennadir, John Pertoft, Gabriela Zarzar Gandler, Lele Cao, Zineb Senane, Styliani Katsarou, Sahar Asadi, Axel Karlsson, and Oleg Smirnov
-
[18]
https://arxiv.org/abs/2511.05619 arXiv:2511.05619
Frequency Matters: When Time Series Foundation Models Fail Under Spectral Shift. https://arxiv.org/abs/2511.05619 arXiv:2511.05619
-
[19]
Andrew Robert Williams, Arjun Ashok, Étienne Marcotte, Valentina Zantedeschi, Jithendaraa Subramanian, Roland Riachi, James Requeima, Alexandre Lacoste, Irina Rish, Nicolas Chapados, and Alexandre Drouin. 2024. Context is Key: A Benchmark for Forecasting with Essential Textual Information. https://arxiv. org/abs/2410.18959 arXiv:2410.18959
- [20]
-
[21]
Shifeng Xie, Vasilii Feofanov, Ambroise Odonnat, Lei Zan, Marius Alonso, Jian- feng Zhang, Themis Palpanas, Lujia Pan, Keli Zhang, and Ievgen Redko. 2025. CauKer: Classification Time Series Foundation Models Can Be Pretrained on Synthetic Data. https://arxiv.org/abs/2508.02879 arXiv:2508.02879
- [22]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.