QCA: Query- and Content-Aware Keyframe Selection for Long Video Understanding
Pith reviewed 2026-07-02 14:07 UTC · model grok-4.3
The pith
QCA selects compact query-relevant keyframes from long videos by scoring segments on relevance and deviation, then picking diverse additions within budget, needing no training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
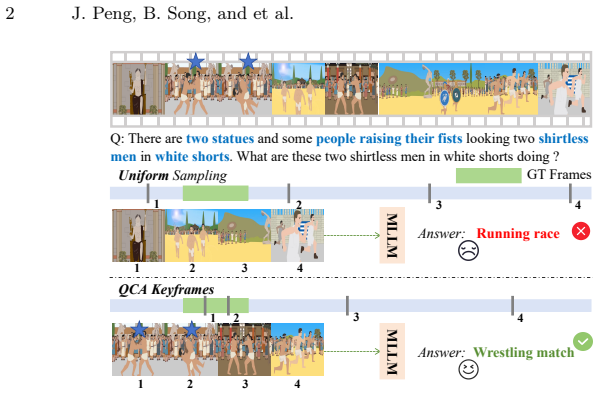
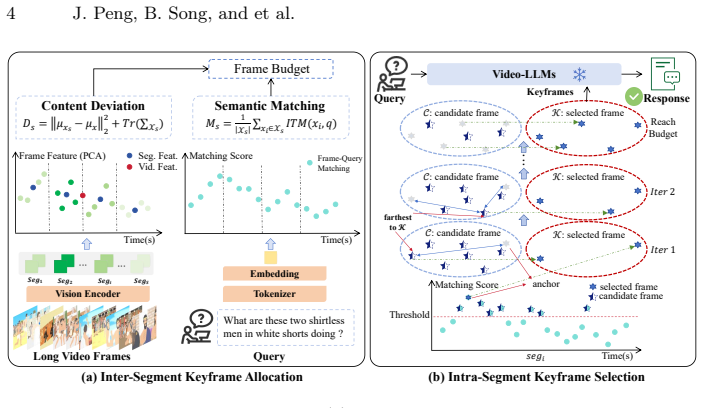
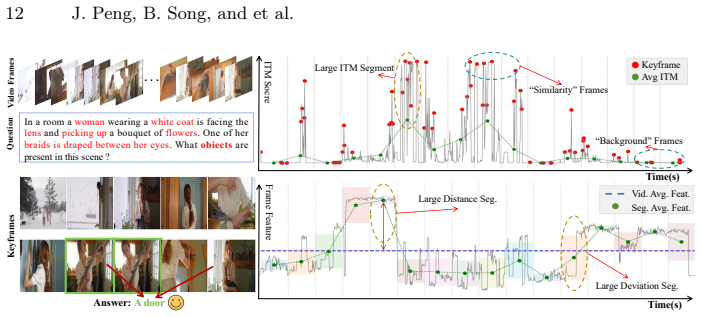
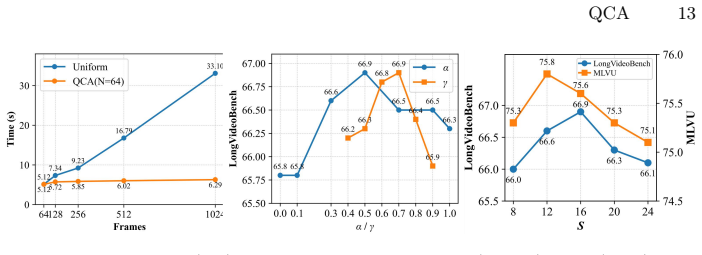
The QCA framework first partitions a long video into temporal segments, estimates each segment's information contribution through joint modeling of query relevance and content deviation, dynamically allocates a keyframe budget across segments, and within each segment anchors on the most query-relevant frame before iteratively adding frames that maximize diversity while preserving semantic relevance. This selection requires no additional training and integrates directly into Video-LLMs, producing state-of-the-art results such as 67.8 percent on LongVideoBench with only 128 frames.
What carries the argument
The QCA procedure that partitions video into segments, jointly scores query relevance and content deviation to allocate budgets, and iteratively selects diverse yet query-aligned frames inside each segment.
If this is right
- Video-LLMs can handle longer inputs at lower cost by processing only the selected keyframes.
- Performance scales with query-specific allocation rather than fixed uniform sampling across all videos.
- The same selection logic applies across multiple benchmarks without retraining the underlying model.
- Computational load during inference drops proportionally to the reduction in processed frames.
Where Pith is reading between the lines
- The approach could extend to live streams where segments arrive sequentially and budgets must be decided on the fly.
- Similar joint relevance-deviation scoring might reduce redundancy in long audio or document sequences fed to language models.
- Combining the method with existing compression techniques could push context lengths further while staying under fixed token limits.
Load-bearing premise
Joint modeling of query relevance and content deviation inside each temporal segment ranks information contribution accurately without any learned parameters or task-specific fine-tuning.
What would settle it
An evaluation on LongVideoBench showing that QCA with 128 frames does not reach or exceed the accuracy obtained by uniform sampling with the same 128 frames or by GPT-4o with 256 frames.
Figures


read the original abstract
Video understanding is often plagued by severe temporal redundancy, where processing dense frame sequences is both semantically inefficient and computationally expensive. This challenge is further amplified when only a small subset of frames is truly relevant to the given query. In this paper, we propose a Query- and Content-Aware (QCA) keyframe selection framework that can select a compact yet information-rich set of frames from long videos. QCA first partitions the video into temporal segments and estimates the information contribution of each segment by jointly modeling query relevance and content deviation, and dynamically allocates keyframe budget to each segment. Within each segment, QCA anchors on the most query-relevant frame and iteratively incorporates additional frames to maximize diversity while maintaining high semantic relevance to the query. Crucially, our method requires no additional training and can be seamlessly integrated into existing Video-LLMs. Extensive experiments across multiple long video understanding benchmarks demonstrate that our proposed approach achieves state-of-the-art performance and has strong generalization ability. For instance, QCA achieves 67.8\% on LongVideoBench using 128 frames, while GPT-4o achieves 66.7\% using 256 frames. Our codes are available in \href{https://github.com/hktk07/QCA}{GitHub}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes QCA, a parameter-free Query- and Content-Aware keyframe selection framework for long video understanding. The method partitions a video into temporal segments, estimates each segment's information contribution via joint modeling of query relevance and content deviation, dynamically allocates a keyframe budget per segment, and within segments anchors on the most query-relevant frame while iteratively adding frames to maximize diversity. It requires no training or fine-tuning and integrates with existing Video-LLMs. The central claim is state-of-the-art performance on long-video benchmarks, e.g., 67.8% on LongVideoBench using 128 frames versus GPT-4o's 66.7% using 256 frames.
Significance. If the heuristic for estimating per-segment contribution holds across queries and videos, the work would be significant for enabling more efficient long-video processing in multimodal models without learned parameters or task-specific adaptation. The open availability of code on GitHub is a positive factor for reproducibility.
major comments (2)
- [Abstract] Abstract: the central performance claim (67.8% on LongVideoBench with 128 frames) is presented without any description of the experimental protocol, number of evaluated videos, baseline implementations, or statistical analysis, which is load-bearing for assessing whether the reported gains follow from the proposed heuristic.
- [Abstract] Abstract: the joint modeling of query relevance and content deviation to estimate information contribution is described only at a high level with no explicit formulation, scoring function, or combination rule, which is load-bearing for the claim that this parameter-free procedure reliably ranks segments without learned parameters or task-specific fine-tuning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that both points identify areas where the abstract can be strengthened for self-containment and will revise it accordingly while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim (67.8% on LongVideoBench with 128 frames) is presented without any description of the experimental protocol, number of evaluated videos, baseline implementations, or statistical analysis, which is load-bearing for assessing whether the reported gains follow from the proposed heuristic.
Authors: We acknowledge the concern. The abstract's space constraints limited inclusion of these details, but the full manuscript (Sections 4.1 and 5) specifies the LongVideoBench evaluation protocol, the standard test split, baseline implementations drawn from official releases or public code, and results averaged across runs with standard deviations where applicable. We will revise the abstract to add a concise clause such as 'evaluated on the LongVideoBench test set following official protocols with comparisons to GPT-4o using its standard implementation' to make the claim more self-contained. revision: yes
-
Referee: [Abstract] Abstract: the joint modeling of query relevance and content deviation to estimate information contribution is described only at a high level with no explicit formulation, scoring function, or combination rule, which is load-bearing for the claim that this parameter-free procedure reliably ranks segments without learned parameters or task-specific fine-tuning.
Authors: We agree that an explicit high-level formulation would improve clarity in the abstract. The manuscript (Section 3) provides the full scoring functions and combination rule. We will revise the abstract to include a brief explicit description, for example 'via a parameter-free score combining query-frame embedding similarity and segment content deviation', to better support the parameter-free claim without exceeding length limits. revision: yes
Circularity Check
No circularity: deterministic heuristic with no fitted parameters or self-referential derivations.
full rationale
The paper describes a parameter-free keyframe selection procedure that partitions videos into segments, models query relevance and content deviation to allocate budgets, and selects frames for diversity. No equations, fitted quantities, or predictions that reduce to inputs by construction are present. No self-citation chains or uniqueness theorems are invoked to justify the core method. Performance numbers are empirical benchmark results, not derived claims. The derivation chain is self-contained as a heuristic algorithm.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems35, 23716– 23736 (2022) 3
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022) 3
2022
-
[2]
arXiv preprint arXiv:2306.13176 (2023) 2, 4
Arslan, S., Tanberk, S.: Key frame extraction with attention based deep neural networks. arXiv preprint arXiv:2306.13176 (2023) 2, 4
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Token Merging: Your ViT But Faster
Bolya, D., Fu, C.Y., Dai, X., Zhang, P., Feichtenhofer, C., Hoffman, J.: Token merging: Your vit but faster. arXiv preprint arXiv:2210.09461 (2022) 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Advances in neural information processing systems33, 1877–1901 (2020) 1
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020) 1
1901
-
[7]
In: European Conference on Computer Vision
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In: European Conference on Computer Vision. pp. 19–35. Springer (2024) 4
2024
-
[8]
Chen, T., Ju, S., Wu, Q., Fang, C., Zhang, K., Peng, J., Li, H., Zhou, Y., Ji, R.: Towards effective and efficient long video understanding of multimodal large language models via one-shot clip retrieval. arXiv preprint arXiv:2512.08410 (2025) 8, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Chen, W., Zeng, Y., Luo, Y., Xie, T., Lin, L., Ji, J., Zhang, Y., Zheng, X.: Wavelet- based frame selection by detecting semantic boundary for long video understand- ing.In:ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPattern Recognition. pp. 24052–24061 (2026) 4
2026
-
[10]
Pattern Recognition130, 108797 (2022) 2
Dong, W., Zhang, Z., Song, C., Tan, T.: Identifying the key frames: An attention- aware sampling method for action recognition. Pattern Recognition130, 108797 (2022) 2
2022
-
[11]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024) 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24108–24118 (2025) 1, 3, 7 QCA 17
2025
-
[13]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Hu, K., Gao, F., Nie, X., Zhou, P., Tran, S., Neiman, T., Wang, L., Shah, M., Hamid, R., Yin, B., et al.: M-llm based video frame selection for efficient video understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13702–13712 (2025) 4
2025
-
[14]
arXiv preprint arXiv:2504.17447 (2025) 8, 9
Huang, D.A., Radhakrishnan, S., Yu, Z., Kautz, J.: Frag: Frame selection aug- mented generation for long video and long document understanding. arXiv preprint arXiv:2504.17447 (2025) 8, 9
-
[15]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024) 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ju, S., Song, B., Chen, T., Zhang, J., Wu, Q., Chang, C., Wang, H., Zhou, Y., Ji, R.: Forestprune: High-ratio visual token compression for video multimodal large language models via spatial-temporal forest modeling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8326– 8336 (2026) 4, 15
2026
-
[17]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024) 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023) 6, 8
2023
-
[19]
Science China Information Sciences 68(10), 200102 (2025) 3
Li, K., He, Y., Wang, Y., Li, Y., Wang, W., Luo, P., Wang, Y., Wang, L., Qiao, Y.: Videochat: Chat-centric video understanding. Science China Information Sciences 68(10), 200102 (2025) 3
2025
-
[20]
arXiv preprint arXiv:2407.03104 (2024) 4
Liang, H., Li, J., Bai, T., Huang, X., Sun, L., Wang, Z., He, C., Cui, B., Chen, C., Zhang, W.: Keyvideollm: Towards large-scale video keyframe selection. arXiv preprint arXiv:2407.03104 (2024) 4
-
[21]
Advances in neural information processing systems36, 34892–34916 (2023) 1, 3
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023) 1, 3
2023
-
[22]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Liu, S., Zhao, C., Xu, T., Ghanem, B.: Bolt: Boost large vision-language model without training for long-form video understanding. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 3318–3327 (2025) 4, 8
2025
-
[23]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, Z., Zhu, L., Shi, B., Zhang, Z., Lou, Y., Yang, S., Xi, H., Cao, S., Gu, Y., Li, D., et al.: Nvila: Efficient frontier visual language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 4122–4134 (2025) 9
2025
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Soldan, M., Pardo, A., Alcázar, J.L., Caba, F., Zhao, C., Giancola, S., Ghanem, B.: Mad: A scalable dataset for language grounding in videos from movie audio descriptions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5026–5035 (2022) 1
2022
-
[25]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Song, B., Peng, J., Zhang, Y., Chen, G., Yang, F., Guo, J.: KTV: Keyframes and key tokens selection for efficient training-free video LLMs. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 9060–9068 (2026). https://doi.org/10.1609/aaai.v40i11.378624
-
[26]
arXiv preprint arXiv:2510.02262 (2025) 4
Sun, G., Singhal, A., Uzkent, B., Shah, M., Chen, C., Kessler, G.: From frames to clips: Efficient key clip selection for long-form video understanding. arXiv preprint arXiv:2510.02262 (2025) 4
-
[27]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tang, X., Qiu, J., Xie, L., Tian, Y., Jiao, J., Ye, Q.: Adaptive keyframe sampling for long video understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29118–29128 (2025) 4, 8, 9, 14 18 J. Peng, B. Song, and et al
2025
-
[28]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Team, G., Georgiev, P., Lei, V.I., Burnell, R., Bai, L., Gulati, A., Tanzer, G., Vin- cent,D.,Pan,Z.,Wang,S.,etal.:Gemini1.5:Unlockingmultimodalunderstanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 (2024) 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Team, K., Du, A., Yin, B., Xing, B., Qu, B., Wang, B., Chen, C., Zhang, C., Du, C., Wei, C., Wang, C., Zhang, D., Du, D., Wang, D., Yuan, E., Lu, E., Li, F., Sung, F., Wei, G., Lai, G., Zhu, H., Ding, H., Hu, H., Yang, H., Zhang, H., Wu, H., Yao, H., Lu, H., Wang, H., Gao, H., Zheng, H., Li, J., Su, J., Wang, J., Deng, J., Qiu, J., Xie, J., Wang, J., Liu,...
2025
-
[30]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang,W.,He,Z.,Hong,W.,Cheng,Y.,Zhang,X.,Qi,J.,Ding,M.,Gu,X.,Huang, S., Xu, B., et al.: Lvbench: An extreme long video understanding benchmark. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 22958–22967 (2025) 7
2025
-
[31]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025) 1, 7, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Advances in Neural Information Pro- cessing Systems37, 28828–28857 (2024) 3, 7
Wu, H., Li, D., Chen, B., Li, J.: Longvideobench: A benchmark for long-context interleaved video-language understanding. Advances in Neural Information Pro- cessing Systems37, 28828–28857 (2024) 3, 7
2024
-
[33]
Pattern Recognition 157, 110818 (2025) 1
Wu, W., Zhao, Y., Li, Z., Li, J., Zhou, H., Shou, M.Z., Bai, X.: A large cross- modal video retrieval dataset with reading comprehension. Pattern Recognition 157, 110818 (2025) 1
2025
-
[34]
arXiv preprint arXiv:2508.01546 (2025) 8, 9
Xu, Z., Zhang, J., Wang, Q., Liu, Y.: E-vrag: Enhancing long video under- standing with resource-efficient retrieval augmented generation. arXiv preprint arXiv:2508.01546 (2025) 8, 9
-
[35]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025) 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
Ye, J., Xu, H., Liu, H., Hu, A., Yan, M., Qian, Q., Zhang, J., Huang, F., Zhou, J.: mplug-owl3: Towards long image-sequence understanding in multi-modal large language models. arXiv preprint arXiv:2408.04840 (2024) 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Zhang, H., Li, X., Bing, L.: Video-llama: An instruction-tuned audio-visual lan- guage model for video understanding. arXiv preprint arXiv:2306.02858 (2023) 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
arXiv preprint arXiv:2506.22139 (2025) 8, 9, 14
Zhang, S., Yang, J., Yin, J., Luo, Z., Luan, J.: Q-frame: Query-aware frame selection and multi-resolution adaptation for video-llms. arXiv preprint arXiv:2506.22139 (2025) 8, 9, 14
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, Y., Zhao, Z., Chen, Z., Ding, Z., Yang, X., Sun, Y.: Beyond training: Dynamic token merging for zero-shot video understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 22046–22055 (2025) 4
2025
-
[40]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Zhang, Y., Wu, J., Li, W., Li, B., Ma, Z., Liu, Z., Li, C.: Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713 (2024) 2, 3, 4, 7, 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
QCA 19 In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhou, J., Shu, Y., Zhao, B., Wu, B., Liang, Z., Xiao, S., Qin, M., Yang, X., Xiong, Y., Zhang, B., et al.: Mlvu: Benchmarking multi-task long video understanding. QCA 19 In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13691–13701 (2025) 7
2025
-
[42]
arXiv preprint arXiv:2510.27280 (2025) 4
Zhu, Z., Xu, H., Luo, Y., Liu, Y., Sarkar, K., Yang, Z., You, Y.: Focus: Efficient keyframe selection for long video understanding. arXiv preprint arXiv:2510.27280 (2025) 4
-
[43]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zohar, O., Wang, X., Dubois, Y., Mehta, N., Xiao, T., Hansen-Estruch, P., Yu, L., Wang, X., Juefei-Xu, F., Zhang, N., et al.: Apollo: An exploration of video understanding in large multimodal models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18891–18901 (2025) 9
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.