AutoSpeed: Annotation-Free Stage-Adaptive Motion Speed Learning for Robot Manipulation
Pith reviewed 2026-07-02 11:07 UTC · model grok-4.3
The pith
AutoSpeed lets visuomotor policies select stage-appropriate motion speeds by minimizing a composite cost over speed-varied trajectory candidates without any speed or stage labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
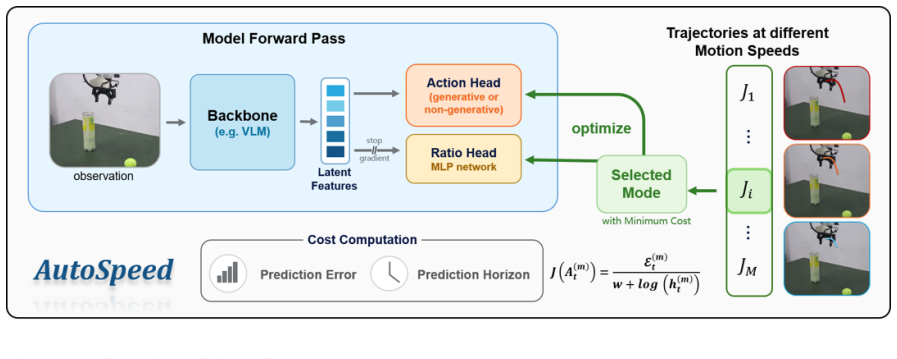
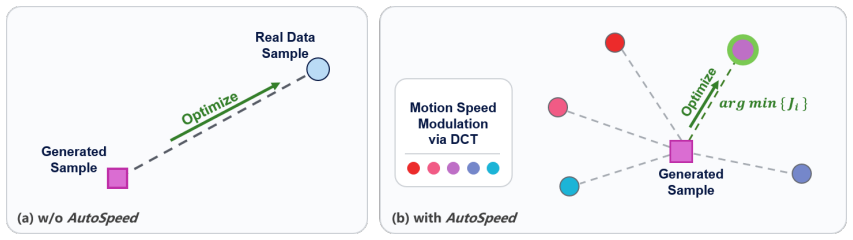
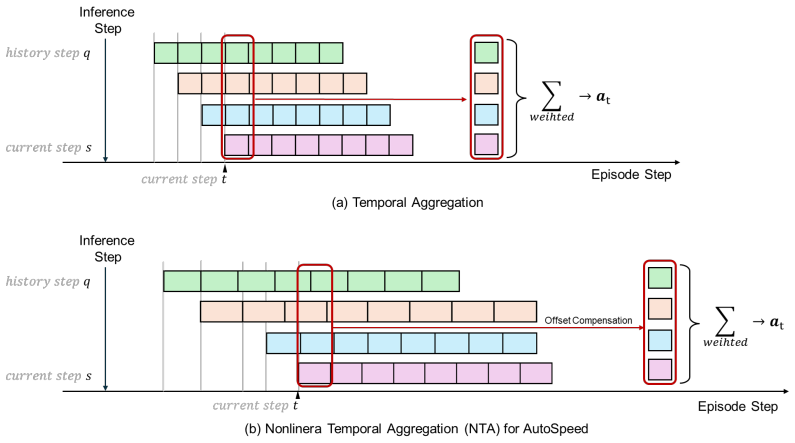
By treating future trajectories at different speeds as candidate optimization targets and selecting the minimum-cost candidate via a composite of prediction error and horizon length, a policy can be trained to produce stage-adaptive motion speeds; the speed change is realized by scaling the frequency content of the action sequence with the discrete cosine transform, which preserves continuity while allowing non-integer speed factors.
What carries the argument
The composite cost that trades prediction error against prediction-horizon length, applied to DCT-scaled trajectory candidates so that a fixed action length yields variable effective horizons.
If this is right
- Task execution time decreases because easy stages use longer effective horizons.
- Success rate rises because difficult stages receive shorter horizons and therefore more accurate short-term predictions.
- The policy remains compatible with any existing visuomotor architecture because the method is model-agnostic.
- Motion remains continuous because DCT scaling supports smooth non-integer speed factors.
- The chosen speeds align with task stages even though no stage labels were supplied during training.
Where Pith is reading between the lines
- The same cost-based selection could be applied to other sequential decision problems where difficulty varies across phases.
- Because no speed annotations are required, the approach could be used on existing demonstration datasets that were recorded at a single fixed speed.
- If the cost evaluation were moved online, the policy might adapt speed on the fly when unexpected difficulty appears.
Load-bearing premise
Evaluating candidate trajectories at different speeds with a cost that trades prediction error against horizon length will automatically produce stage-adaptive speeds that improve both speed and accuracy even when the training data contain no speed or stage information.
What would settle it
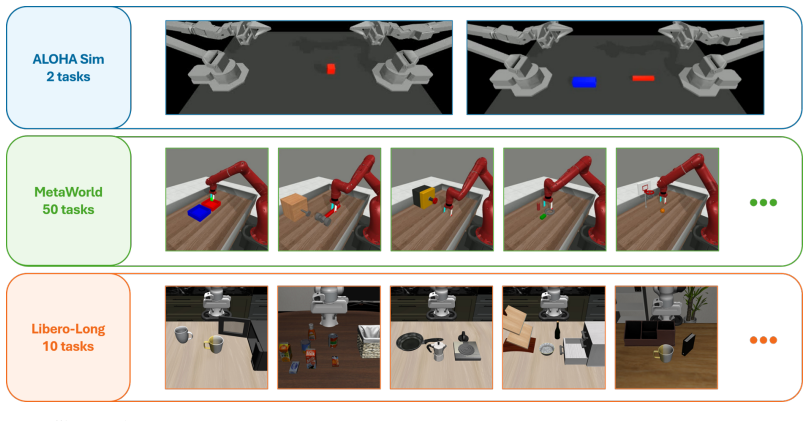
Train the same base policy once with AutoSpeed and once without it on an identical manipulation task, then measure whether total execution time decreases, success rate increases, and the selected speeds vary across the task stages.
Figures

read the original abstract
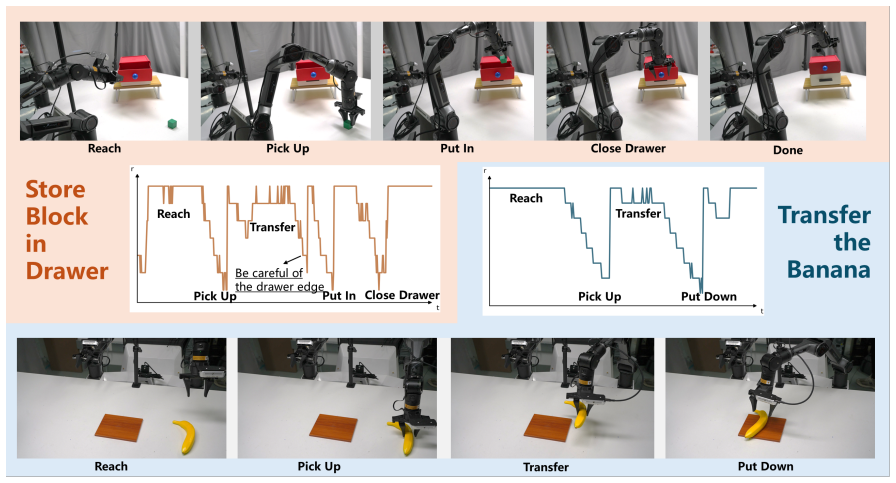
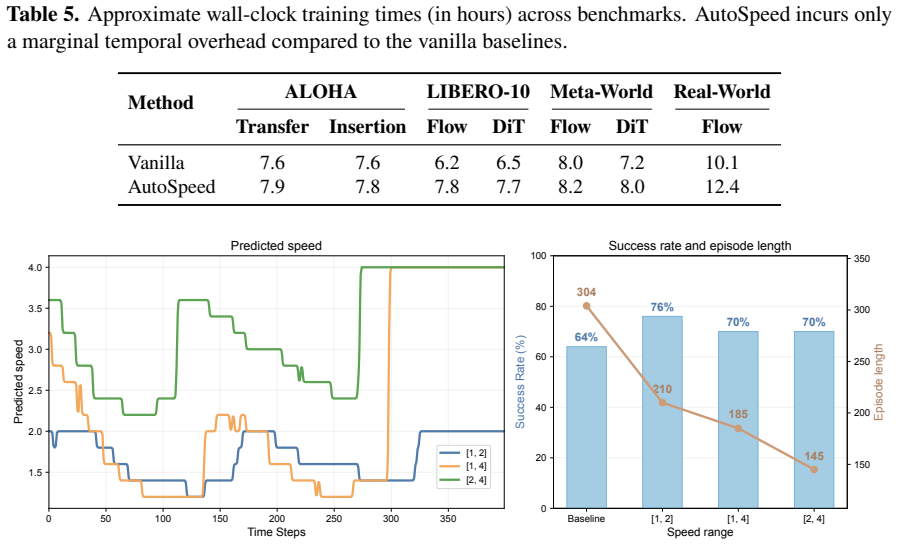
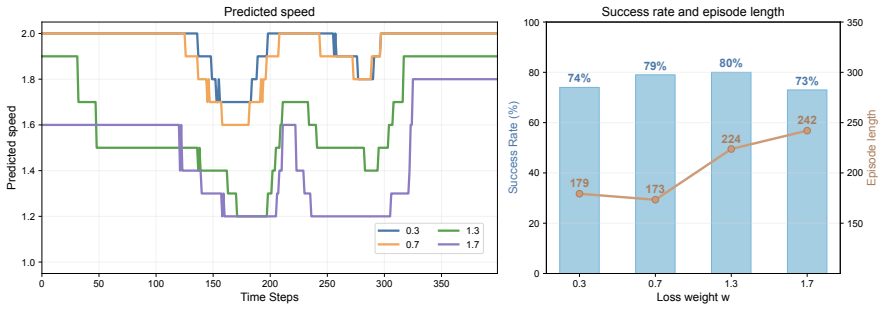
Different stages of manipulation tasks exhibit varying levels of difficulty, suggesting stage-dependent motion speeds and temporal prediction horizons. However, existing IL-based visuomotor policies typically imitate the execution speed of expert demonstrations and operate with a fixed temporal prediction horizon, limiting flexibility and overall task throughput. In this paper, we introduce AutoSpeed, a model-agnostic learning framework that enables existing visuomotor policies to predict trajectories with stage-adaptive motion speeds, without requiring speed or stage annotations. We treat future trajectories at different speeds as candidate optimization targets, evaluate each candidate using a composite cost that trades off prediction error against prediction horizon, and optimize the policy toward the minimum-cost candidate. With a fixed-length action sequence, speed modulation adjusts the effective temporal prediction horizon: simple stages are executed faster with a longer prediction horizon, whereas complex stages are executed more slowly with a shorter prediction horizon. Specifically, we implement speed modulation in the frequency domain via the discrete cosine transform (DCT), which enables smooth, non-integer speed scaling and thus preserves motion continuity. Extensive evaluations show that AutoSpeed substantially reduces task execution time while also improving success rates. Under the AutoSpeed framework, the inferred motion speeds exhibit a strong correspondence with task stages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AutoSpeed, a model-agnostic framework that enables existing visuomotor policies to produce stage-adaptive motion speeds without speed or stage annotations. Candidate trajectories at different speeds are evaluated via a composite cost trading prediction error against prediction horizon; the policy is optimized toward the minimum-cost candidate. Speed modulation is realized in the frequency domain using the discrete cosine transform (DCT) on fixed-length action sequences, allowing simple stages to use longer effective horizons (faster execution) and complex stages shorter horizons (slower execution). The authors report that the approach reduces task execution time, raises success rates, and yields inferred speeds that align with task stages.
Significance. If the empirical claims hold, the framework provides a practical, annotation-free route to higher-throughput imitation-learned manipulation by letting policies modulate speed according to local difficulty. The DCT-based implementation is a clean technical device for achieving non-integer, continuous speed scaling while preserving motion smoothness.
major comments (1)
- [Method (optimization and cost definition)] The central optimization (described in the method) defines the composite cost using the policy's own prediction error on each speed-modulated candidate. This construction risks circular dependence: the error term is evaluated under the current policy parameters, so the minimum-cost selection may simply reinforce already-fitted behavior rather than discover genuinely stage-adaptive speeds. The manuscript must specify whether the error is computed with a frozen copy of the policy, on held-out data, or via an auxiliary model, and must demonstrate that the resulting fixed point is non-trivial.
minor comments (1)
- [Experiments] The abstract states performance gains but the main text should include explicit quantitative tables (success rate, execution time, speed histograms per stage) with baselines and ablations so readers can verify the stage-adaptive claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the optimization and cost definition in AutoSpeed. We address the concern about potential circular dependence below and have revised the manuscript to provide the requested clarifications and supporting analysis.
read point-by-point responses
-
Referee: [Method (optimization and cost definition)] The central optimization (described in the method) defines the composite cost using the policy's own prediction error on each speed-modulated candidate. This construction risks circular dependence: the error term is evaluated under the current policy parameters, so the minimum-cost selection may simply reinforce already-fitted behavior rather than discover genuinely stage-adaptive speeds. The manuscript must specify whether the error is computed with a frozen copy of the policy, on held-out data, or via an auxiliary model, and must demonstrate that the resulting fixed point is non-trivial.
Authors: We thank the referee for highlighting this important point. The composite cost is evaluated using the policy's prediction error on the speed-modulated candidates as part of the candidate selection step. To prevent simple reinforcement of fitted behavior, the error is computed with a frozen copy of the policy parameters from the start of each optimization iteration; the selected minimum-cost candidate then serves as the target for the subsequent policy update. We have revised Section 3 to explicitly describe this procedure (including the use of the frozen copy) and added an analysis in the supplementary material demonstrating that the fixed point is non-trivial: the selected speeds vary meaningfully across task stages rather than converging to a uniform value, and ablating the cost leads to degraded performance. These clarifications and results will appear in the revised manuscript. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract and provided description present AutoSpeed as an optimization framework that selects among speed-modulated trajectory candidates via a composite cost on prediction error versus horizon length, implemented through DCT modulation. No equations, self-citations, or derivation steps are quoted that reduce the claimed stage-adaptive behavior to a self-definition, a fitted input renamed as prediction, or a load-bearing self-citation chain. The cost function is an explicit design choice trading off two quantities; the resulting policy is trained toward the selected targets rather than being equivalent to its inputs by construction. The approach is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A composite cost trading prediction error against prediction horizon will select trajectories whose effective speeds correspond to natural task stages.
Reference graph
Works this paper leans on
-
[1]
Nadun Ranawaka Arachchige, Zhenyang Chen, Wonsuhk Jung, Woo Chul Shin, Rohan Bansal, Pierre Barroso, Yu Hang He, Yingyang Celine Lin, Benjamin Joffe, Shreyas Kousik, et al. Sail: Faster-than-demonstration execution of imitation learning policies.arXiv preprint arXiv:2506.11948, 2025
-
[2]
Cognitive control.Annual Review of Psychology, 76(1):167–195, 2025
David Badre. Cognitive control.Annual Review of Psychology, 76(1):167–195, 2025
2025
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.𝜋0: A vision-language-action flow model for general robot control. corr, abs/2410.24164, 2024. doi: 10.48550.arXiv preprint ARXIV.2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Real-Time Execution of Action Chunking Flow Policies
Kevin Black, Manuel Y Galliker, and Sergey Levine. Real-time execution of action chunking flow policies.arXiv preprint arXiv:2506.07339, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
TonyBonnaire,RaphaëlUrfin,GiulioBiroli,andMarcMézard. Whydiffusionmodelsdon’tmem- orize: The role of implicit dynamical regularization in training.arXiv preprint arXiv:2505.17638, 2025
-
[6]
Better-than-demonstrator imitation learning viaautomatically-rankeddemonstrations
Daniel S Brown, Wonjoon Goo, and Scott Niekum. Better-than-demonstrator imitation learning viaautomatically-rankeddemonstrations. InConferenceonrobotlearning,pages330–359.PMLR, 2020
2020
-
[7]
SARM: Stage-Aware Reward Modeling for Long Horizon Robot Manipulation
Qianzhong Chen, Justin Yu, Mac Schwager, Pieter Abbeel, Yide Shentu, and Philipp Wu. Sarm: Stage-aware reward modeling for long horizon robot manipulation.arXiv preprint arXiv:2509.25358, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[9]
A century later: Woodworth’s (1899) two-component model of goal-directed aiming.Psychological bulletin, 127(3):342, 2001
Digby Elliott, Werner F Helsen, and Romeo Chua. A century later: Woodworth’s (1899) two-component model of goal-directed aiming.Psychological bulletin, 127(3):342, 2001
2001
-
[10]
Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation
Yiguo Fan, Shuanghao Bai, Xinyang Tong, Pengxiang Ding, Yuyang Zhu, Hongchao Lu, Fengqi Dai, Wei Zhao, Yang Liu, Siteng Huang, et al. Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation. InConference on Robot Learning, pages 2018–2037. PMLR, 2025
2018
-
[11]
Lingxiao Guo, Zhengrong Xue, Zijing Xu, and Huazhe Xu. Demospeedup: Accelerating visuo- motor policies via entropy-guided demonstration acceleration.arXiv preprint arXiv:2506.05064, 2025
-
[12]
Baku: An efficient transformer for multi-task policy learning.Advances in Neural Information Processing Systems, 37:141208–141239, 2024
Siddhant Haldar, Zhuoran Peng, and Lerrel Pinto. Baku: An efficient transformer for multi-task policy learning.Advances in Neural Information Processing Systems, 37:141208–141239, 2024
2024
-
[13]
Robot data curation with mutual information estimators.arXiv preprint arXiv:2502.08623, 2025
Joey Hejna, Suvir Mirchandani, Ashwin Balakrishna, Annie Xie, Ayzaan Wahid, Jonathan Tompson, Pannag Sanketi, Dhruv Shah, Coline Devin, and Dorsa Sadigh. Robot data curation with mutual information estimators.arXiv preprint arXiv:2502.08623, 2025
-
[14]
The impact of speed-accuracy instructions on spatial congruency effects.Journal of Cognition, 6(1):49, 2023
Herbert Heuer and Peter Wühr. The impact of speed-accuracy instructions on spatial congruency effects.Journal of Cognition, 6(1):49, 2023
2023
-
[15]
Mixture of Horizons in Action Chunking
DongJing,GangWang,JiaqiLiu,WeiliangTang,ZelongSun,YunchaoYao,ZhenyuWei,Yunhui Liu, Zhiwu Lu, and Mingyu Ding. Mixture of horizons in action chunking.arXiv preprint 15 arXiv:2511.19433, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
The discrete cosine transform (dct): theory and application.Michigan State University, 114(1):31, 2003
Syed Ali Khayam. The discrete cosine transform (dct): theory and application.Michigan State University, 114(1):31, 2003
2003
-
[17]
ESPADA: Execution Speedup via Semantics Aware Demonstration Data Downsampling for Imitation Learning
ByungjuKim,JinuPahk,ChungwooLee,JaejoonKim,JanghaLee,TheoTaeyeongKim,Kyuhwan Shim, Jun Ki Lee, and Byoung-Tak Zhang. Espada: Execution speedup via semantics aware demonstration data downsampling for imitation learning.arXiv preprint arXiv:2512.07371, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Bfa: Best-feature-aware fusion for multi-view fine-grained manipulation.IEEE Robotics and Automation Letters, 2025
ZihanLan,WeixinMao,HaoshengLi,LeWang,TiancaiWang,HaoqiangFan,andOsamuYoshie. Bfa: Best-feature-aware fusion for multi-view fine-grained manipulation.IEEE Robotics and Automation Letters, 2025
2025
-
[19]
Implicit Maximum Likelihood Estimation
Ke Li and Jitendra Malik. Implicit maximum likelihood estimation.arXiv preprint arXiv:1809.09087, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[23]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Yuejiang Liu, Jubayer Ibn Hamid, Annie Xie, Yoonho Lee, Maximilian Du, and Chelsea Finn. Bidirectional decoding: Improving action chunking via guided test-time sampling.arXiv preprint arXiv:2408.17355, 2024
-
[25]
Variable-frequency imitation learning for variable-speed motion
Nozomu Masuya, Sho Sakaino, and Toshiaki Tsuji. Variable-frequency imitation learning for variable-speed motion. In2025 IEEE International Conference on Mechatronics (ICM), pages 1–6. IEEE, 2025
2025
-
[26]
SpeedAug: Policy Acceleration via Tempo-Enriched Policy and RL Fine-Tuning
Taewook Nam and Sung Ju Hwang. Speedaug: Policy acceleration via tempo-enriched policy and rl fine-tuning.arXiv preprint arXiv:2512.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Unifying speed-accuracy trade-off and cost-benefit trade-off in human reaching movements.Frontiers in human neuroscience, 11:615, 2017
Luka Peternel, Olivier Sigaud, and Jan Babič. Unifying speed-accuracy trade-off and cost-benefit trade-off in human reaching movements.Frontiers in human neuroscience, 11:615, 2017
2017
-
[28]
Changesincorticalbetapowerpredictmotorcontrol flexibility, not vigor.Communications Biology, 8(1):1041, 2025
Emeline Pierrieau, Claire Dussard, Axel Plantey-Veux, Cloé Guerrini, Brian Lau, Léa Pillette, NathalieGeorge,andCamilleJeunet-Kelway. Changesincorticalbetapowerpredictmotorcontrol flexibility, not vigor.Communications Biology, 8(1):1041, 2025
2025
-
[29]
Shang, Y ., Zhang, X., Tang, Y ., Jin, L., Gao, C., Wu, W., and Li, Y
Han Qi, Haocheng Yin, Aris Zhu, Yilun Du, and Heng Yang. Strengthening generative robot policies through predictive world modeling.arXiv preprint arXiv:2502.00622, 2025
- [30]
-
[31]
Junhyuk So, Chiwoong Lee, Shinyoung Lee, Jungseul Ok, and Eunhyeok Park. Improving genera- tive behavior cloning via self-guidance and adaptive chunking.arXiv preprint arXiv:2510.12392, 2025. 16
-
[32]
A survey of robot manipulation in contact.Robotics and Autonomous Systems, 156:104224, 2022
Markku Suomalainen, Yiannis Karayiannidis, and Ville Kyrki. A survey of robot manipulation in contact.Robotics and Autonomous Systems, 156:104224, 2022
2022
-
[33]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
VLA Knows Its Limits: Adaptive Execution Horizons for Robot Policies
Haoxuan Wang, Gengyu Zhang, Yan Yan, Ramana Rao Kompella, and Gaowen Liu. Vla knows its limits.arXiv preprint arXiv:2602.21445, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Temporal Action Selection for Action Chunking
Yueyang Weng, Xiaopeng Zhang, Yongjin Mu, Yingcong Zhu, Yanjie Li, and Qi Liu. Temporal action selection for action chunking.arXiv preprint arXiv:2511.04421, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Subconscious robotic imitation learning.arXiv preprint arXiv:2412.20368, 2024
Jun Xie, Zhicheng Wang, Jianwei Tan, Huanxu Lin, and Xiaoguang Ma. Subconscious robotic imitation learning.arXiv preprint arXiv:2412.20368, 2024
-
[37]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
TianheYu,DeirdreQuillen,ZhanpengHe,RyanJulian,KarolHausman,ChelseaFinn,andSergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning, pages 1094–1100. PMLR, 2020
2020
-
[38]
Flowpolicy: Enablingfastandrobust3dflow-basedpolicyviaconsistencyflowmatchingforrobot manipulation
Qinglun Zhang, Zhen Liu, Haoqiang Fan, Guanghui Liu, Bing Zeng, and Shuaicheng Liu. Flowpolicy: Enablingfastandrobust3dflow-basedpolicyviaconsistencyflowmatchingforrobot manipulation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 14754–14762, 2025
2025
-
[39]
DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge
WenyaoZhang, HongsiLiu, ZekunQi, YunnanWang, XinqiangYu, JiazhaoZhang, RunpeiDong, Jiawei He, Fan Lu, He Wang, et al. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge.arXiv preprint arXiv:2507.04447, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Freqpolicy: Frequency autoregressive visuomotor policy with continuous tokens
Yiming Zhong, Yumeng Liu, Chuyang Xiao, Zemin Yang, Youzhuo Wang, Yufei Zhu, Ye Shi, Yujing Sun, Xinge Zhu, and Yuexin Ma. Freqpolicy: Frequency autoregressive visuomotor policy with continuous tokens. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 17 We provide further details on the following aspects: •The AutoSpeed...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.