Can Agents Generalize to the Open World? Unveiling the Fragility of Static Training in Tool Use
Pith reviewed 2026-07-02 12:14 UTC · model grok-4.3
The pith
Tool-use agents trained on fixed setups lose performance when queries, tools, or interactions change in open settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
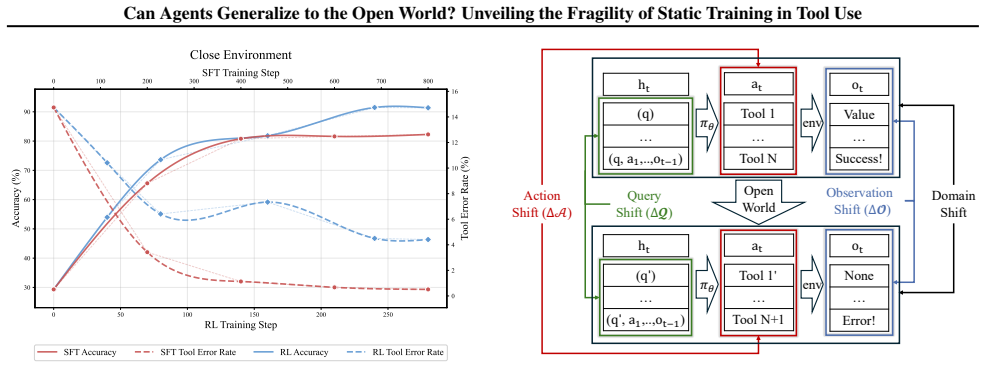
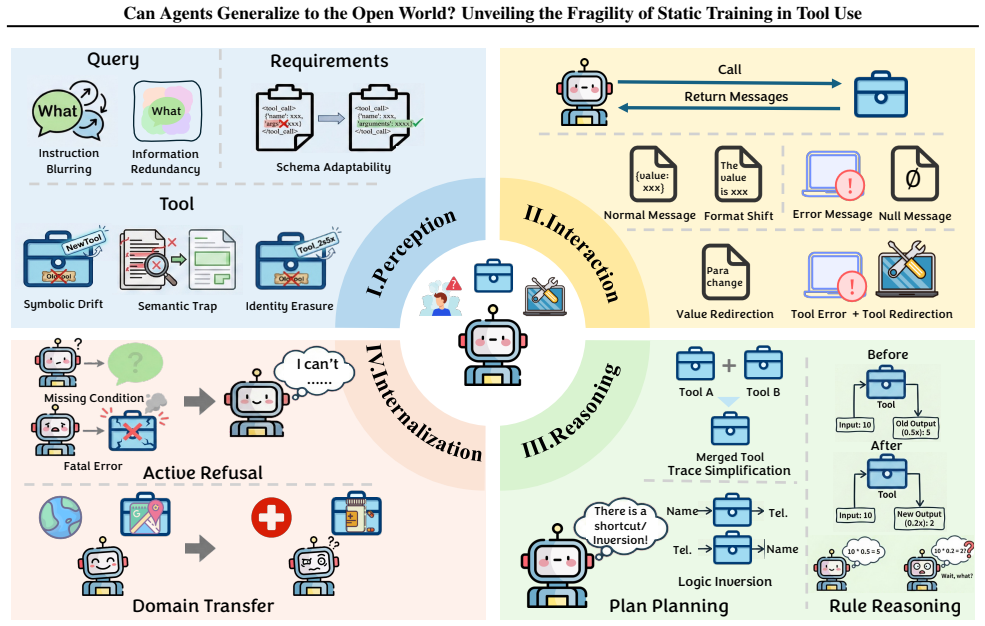
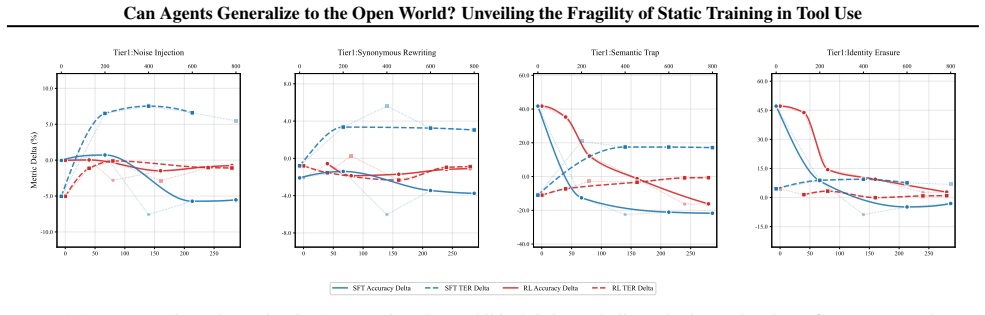
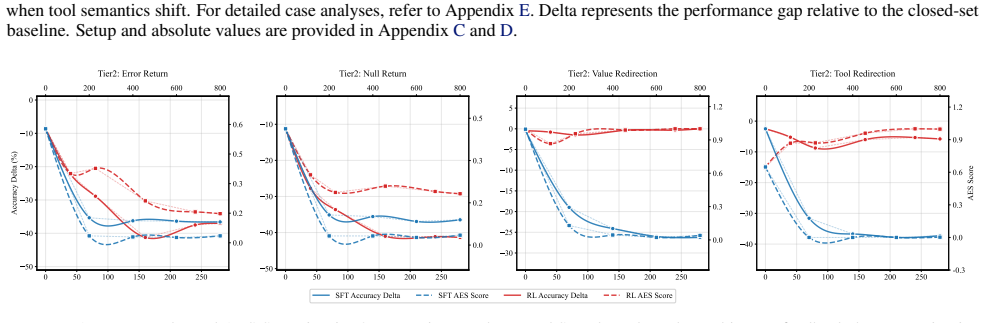
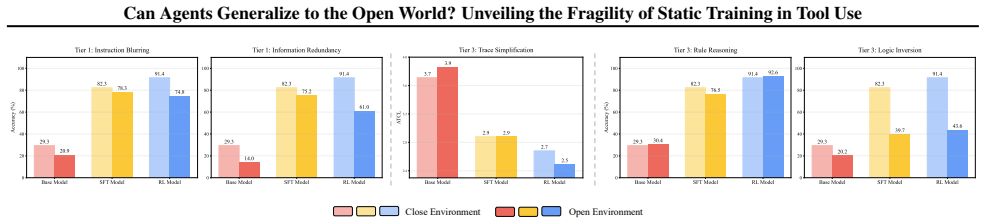
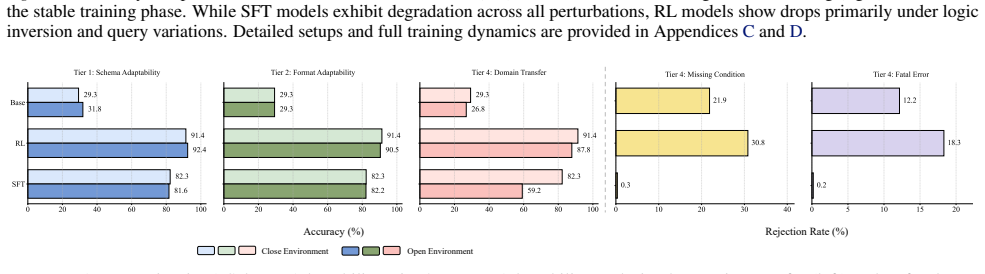
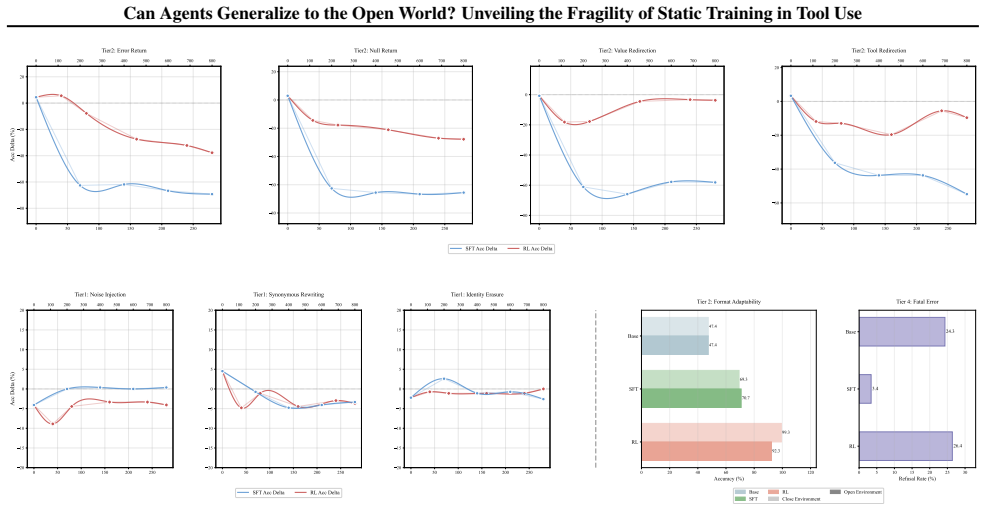
Agents trained via Supervised Fine-Tuning and Reinforcement Learning suffer from varying degrees of performance degradation when confronting open environmental shifts across the four-tier hierarchy of Perception, Interaction, Reasoning, and Internalization in the OpenAgent setting.
What carries the argument
The four-tier hierarchy of environmental shifts (Perception, Interaction, Reasoning, Internalization) that diagnoses how distributional changes affect agent tool use.
If this is right
- Both SFT and RL agents exhibit performance drops under shifts in any of the four tiers.
- Degradation severity differs across perception, interaction, reasoning, and internalization shifts.
- Perturbation-augmented fine-tuning during SFT reduces the observed degradation.
Where Pith is reading between the lines
- Static training benchmarks may systematically overstate agent reliability once real users or tool providers alter conditions.
- The sandbox hierarchy offers a template for testing generalization in other agent domains such as planning or multi-step web tasks.
- Continuous monitoring of shift types during deployment could guide when retraining is needed.
Load-bearing premise
The four controlled shift types in the sandbox capture the distributional changes that matter most in real open-world tool-use deployments.
What would settle it
Measure whether success rates remain high when agents encounter new tools or altered interaction rules after training on the original static set.
Figures
read the original abstract
While Large Language Model (LLM) agents demonstrate proficiency in static benchmarks, their deployment in real-world scenarios is hindered by the dynamic nature of user queries, tool sets, and interaction dynamics. To address this generalization gap, we formalize OpenAgent (Tool-Use Agent in Open-World), a problem setting characterized by distributional shifts across query, action, observation, and domain dimensions. To systematically diagnose its impact, we construct a controlled sandbox environment where we define fine-grained environmental shifts across a four-tier hierarchy, Perception, Interaction, Reasoning, and Internalization, and conduct a comprehensive series of experiments. Our analysis yields a series of key insights, demonstrating that agents trained via both Supervised Fine-Tuning(SFT) and Reinforcement Learning suffer from varying degrees of performance degradation when confronting open environmental shifts. Building on these insights, we propose Perturbation-Augmented Fine-Tuning, a disturbance-based intervention strategy for SFT that lays the foundation for enhancing agent robustness and utility in realistic environments. Our code will be released at: https://github. com/LAMDA-NeSy/OpenAgent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the OpenAgent setting for tool-use LLM agents facing distributional shifts across query, action, observation, and domain dimensions. It constructs a controlled sandbox implementing a four-tier hierarchy of shifts (Perception, Interaction, Reasoning, Internalization), runs experiments showing performance degradation for both SFT- and RL-trained agents under these shifts, and proposes Perturbation-Augmented Fine-Tuning as a disturbance-based SFT intervention to improve robustness, with code release promised.
Significance. If the empirical findings hold under more rigorous validation, the work would usefully document the fragility of static training regimes for agents and supply a concrete mitigation strategy. The promised code release is a clear strength for reproducibility.
major comments (3)
- [§4] §4 (Sandbox and four-tier hierarchy): the claim that the Perception/Interaction/Reasoning/Internalization tiers diagnose open-world fragility is load-bearing, yet the manuscript supplies no external mapping, user-study validation, or comparison against live tool-deployment logs showing that these controlled perturbations are representative of real distributional shifts.
- [§5] §5 (Experiments): the reported degradation results for SFT and RL agents lack any mention of statistical tests, run-to-run variance, confidence intervals, or explicit baseline comparisons against non-perturbed training, making it impossible to assess whether the observed drops are reliable or merely artifacts of the sandbox design.
- [§6] §6 (Perturbation-Augmented Fine-Tuning): the proposal is presented as directly addressing the diagnosed fragility, but the manuscript does not specify how the perturbation distribution is chosen or whether it was tuned on held-out shift types, leaving open the possibility that the improvement is specific to the same artificial tiers rather than generalizable.
minor comments (2)
- [Abstract] Abstract: the GitHub URL contains an extraneous space ("github. com"); correct for proper linking.
- [§3] Notation: the four-tier hierarchy is introduced without a compact tabular summary of which shift type affects which dimension (query/action/observation/domain), which would aid readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Sandbox and four-tier hierarchy): the claim that the Perception/Interaction/Reasoning/Internalization tiers diagnose open-world fragility is load-bearing, yet the manuscript supplies no external mapping, user-study validation, or comparison against live tool-deployment logs showing that these controlled perturbations are representative of real distributional shifts.
Authors: We acknowledge that the four-tier hierarchy is a controlled abstraction and that the manuscript does not provide external validation such as user studies or direct comparisons to production logs. The tiers were derived from common failure modes observed in tool-use literature and our own preliminary deployments; the sandbox enables isolation of individual shift types that would be difficult to disentangle in live systems. We will add an expanded limitations subsection that explicitly discusses the gap between controlled perturbations and real-world distributions and outlines planned follow-up work on external validation. revision: partial
-
Referee: [§5] §5 (Experiments): the reported degradation results for SFT and RL agents lack any mention of statistical tests, run-to-run variance, confidence intervals, or explicit baseline comparisons against non-perturbed training, making it impossible to assess whether the observed drops are reliable or merely artifacts of the sandbox design.
Authors: The referee is correct that the current experimental reporting is insufficient. In the revision we will report means and standard deviations across multiple random seeds, include 95% confidence intervals, apply appropriate statistical tests (paired t-tests or Wilcoxon signed-rank where normality assumptions fail), and add explicit comparisons against agents trained without any perturbation augmentation. revision: yes
-
Referee: [§6] §6 (Perturbation-Augmented Fine-Tuning): the proposal is presented as directly addressing the diagnosed fragility, but the manuscript does not specify how the perturbation distribution is chosen or whether it was tuned on held-out shift types, leaving open the possibility that the improvement is specific to the same artificial tiers rather than generalizable.
Authors: We will clarify the construction of the perturbation distribution: it is sampled uniformly from the same four-tier taxonomy used in the evaluation, with no hyperparameter search performed on held-out shift categories. This design choice means the reported gains are within-distribution with respect to the taxonomy; we will add an explicit statement that out-of-taxonomy generalization remains untested and constitutes an important direction for future work. revision: partial
Circularity Check
No circularity: purely empirical diagnosis with no derivation chain
full rationale
The paper is an empirical study that formalizes OpenAgent, builds a controlled sandbox with a four-tier shift hierarchy (Perception, Interaction, Reasoning, Internalization), runs SFT/RL experiments, observes degradation, and proposes Perturbation-Augmented Fine-Tuning based on those observations. No equations, fitted parameters, or predictions are claimed; the four-tier hierarchy is an explicit experimental design choice, not a derived result. No self-citation load-bearing steps or reductions by construction exist. The work is self-contained against its own sandbox benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
OpenAgent problem setting
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Z...
-
[2]
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Ye Mo and Chuan Zhou and Fengxiang Cheng and Jialin Yu and Liangming Pan and Fenrong Liu and Sheng Zhou and Haoxuan Li and Zhouchen Lin and Philip Torr , booktitle=
-
[4]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
arXiv preprint arXiv:2502.07374 , year=
LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters! , author=. arXiv preprint arXiv:2502.07374 , year=
-
[7]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
Rotbench: A multi-level benchmark for evaluating the robustness of large language models in tool learning , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
2024
-
[8]
arXiv preprint arXiv:2407.03007 , year=
What affects the stability of tool learning? an empirical study on the robustness of tool learning frameworks , author=. arXiv preprint arXiv:2407.03007 , year=
-
[9]
Multi-modal Agent Tuning: Building a VLM-Driven Agent for Efficient Tool Usage , booktitle =
Zhi Gao and Bofei Zhang and Pengxiang Li and Xiaojian Ma and Tao Yuan and Yue Fan and Yuwei Wu and Yunde Jia and Song. Multi-modal Agent Tuning: Building a VLM-Driven Agent for Efficient Tool Usage , booktitle =
-
[10]
Feng, Jiazhan and Huang, Shijue and Qu, Xingwei and Zhang, Ge and Qin, Yujia and Zhong, Baoquan and Jiang, Chengquan and Chi, Jinxin and Zhong, Wanjun , booktitle=
-
[11]
Le and Sergey Levine and Yi Ma , title =
Tianzhe Chu and Yuexiang Zhai and Jihan Yang and Shengbang Tong and Saining Xie and Dale Schuurmans and Quoc V. Le and Sergey Levine and Yi Ma , title =. Proceedings of the 42nd International Conference on Machine Learning , year =
-
[12]
Advances in Neural Information Processing Systems , volume=
Qian, Cheng and Acikgoz, Emre Can and He, Qi and Wang, Hongru and Chen, Xiusi and Hakkani-T. Advances in Neural Information Processing Systems , volume=
-
[13]
Tool documentation enables zero-shot tool-usage with large language models , author =
-
[14]
Liu, Weiwen and Huang, Xu and Zeng, Xingshan and Hao, Xinlong and Yu, Shuai and Li, Dexun and Wang, Shuai and Gan, Weinan and Liu, Zhengying and Yu, Yuanqing and Wang, Zezhong and Wang, Yuxian and Ning, Wu and Hou, Yutai and Wang, Bin and Wu, Chuhan and Wang, Xinzhi and Liu, Yong and Wang, Yasheng and Tang, Duyu and Tu, Dandan and Shang, Lifeng and Jiang,...
-
[15]
Qu, Changle and Dai, Sunhao and Wei, Xiaochi and Cai, Hengyi and Wang, Shuaiqiang and Yin, Dawei and Xu, Jun and Wen, Ji-Rong , booktitle=
-
[16]
The Twelfth International Conference on Learning Representations , year =
Lifan Yuan and Yangyi Chen and Xingyao Wang and Yi Fung and Hao Peng and Heng Ji , title =. The Twelfth International Conference on Learning Representations , year =
-
[17]
Easytool: Enhancing llm-based agents with concise tool instruction , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , year=
2025
-
[18]
Learning to Use Tools via Cooperative and Interactive Agents , booktitle =
Zhengliang Shi and Shen Gao and Xiuyi Chen and Yue Feng and Lingyong Yan and Haibo Shi and Dawei Yin and Pengjie Ren and Suzan Verberne and Zhaochun Ren , editor =. Learning to Use Tools via Cooperative and Interactive Agents , booktitle =
-
[19]
Sun, Weiwei and Shi, Zhengliang and Wu, Jiulong and Yan, Lingyong and Ma, Xinyu and Liu, Yiding and Cao, Min and Yin, Dawei and Ren, Zhaochun , booktitle=
-
[20]
Liu, Zuxin and Hoang, Thai and Zhang, Jianguo and Zhu, Ming and Lan, Tian and Tan, Juntao and Yao, Weiran and Liu, Zhiwei and Feng, Yihao and RN, Rithesh and others , booktitle=
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Tanmay Gupta and Aniruddha Kembhavi , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[22]
and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , booktitle=
Qin, Yujia and Liang, Shi and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Ya-Ting and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Marc H. and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , booktitle=
-
[23]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Abductive Learning for Neuro-Symbolic Grounded Imitation , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1 , year=
-
[24]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , year=
Neuro-symbolic artificial intelligence: towards improving the reasoning abilities of large language models , author=. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , year=
-
[25]
The Fourteenth International Conference on Learning Representations , year=
ChinaTravel: An Open-Ended Travel Planning Benchmark with Compositional Constraint Validation for Language Agents , author=. The Fourteenth International Conference on Learning Representations , year=
-
[26]
Proceedings of the 43rd International Conference on Machine Learning , year =
VT-Bench: A Unified Benchmark for Visual-Tabular Multi-Modal Learning , author =. Proceedings of the 43rd International Conference on Machine Learning , year =
-
[27]
Proceedings of the 43rd International Conference on Machine Learning , year =
On the Learnability of Test-Time Adaptation: A Recovery Complexity Perspective , author =. Proceedings of the 43rd International Conference on Machine Learning , year =
-
[28]
arXiv preprint arXiv:2603.24004 , year=
Thinking with Tables: Enhancing Multi-Modal Tabular Understanding via Neuro-Symbolic Reasoning , author=. arXiv preprint arXiv:2603.24004 , year=
-
[29]
Shen, Yongliang and Song, Kaitao and Tan, Xu and Li, Dongsheng and Lu, Weiming and Zhuang, Yueting , booktitle=
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
Toolvqa: A dataset for multi-step reasoning vqa with external tools , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
-
[31]
Zheng, Ziwei and Yang, Michael and Hong, Jack and Zhao, Chenxiao and Xu, Guohai and Yang, Le and Shen, Chao and Yu, Xing , booktitle=
-
[32]
Hong, Jack and Zhao, Chenxiao and Zhu, ChengLin and Lu, Weiheng and Xu, Guohai and Yu, Xing , booktitle=
-
[33]
Wang, Zhenting and Chang, Qi and Patel, Hemani and Biju, Shashank and Wu, Cheng-En and Liu, Quan and Ding, Aolin and Rezazadeh, Alireza and Shah, Ankit and Bao, Yujia and Siow, Eugene , booktitle=
-
[34]
arXiv preprint arXiv:2509.01055 , year=
Verltool: Towards holistic agentic reinforcement learning with tool use , author=. arXiv preprint arXiv:2509.01055 , year=
-
[35]
StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models , booktitle =
Zhicheng Guo and Sijie Cheng and Hao Wang and Shihao Liang and Yujia Qin and Peng Li and Zhiyuan Liu and Maosong Sun and Yang Liu , editor =. StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models , booktitle =
-
[36]
The Twelfth International Conference on Learning Representations , year=
Gaia: a benchmark for general ai assistants , author=. The Twelfth International Conference on Learning Representations , year=
-
[37]
Pan and Pei Zhou , editor =
Jie He and Jennifer Neville and Mengting Wan and Longqi Yang and Hui Liu and Xiaofeng Xu and Xia Song and Jeff Z. Pan and Pei Zhou , editor =. GenTool: Enhancing Tool Generalization in Language Models through Zero-to-One and Weak-to-Strong Simulation , booktitle =
-
[38]
The Fourteenth International Conference on Learning Representations , year=
In-the-Flow Agentic System Optimization for Effective Planning and Tool Use , author =. The Fourteenth International Conference on Learning Representations , year=
-
[39]
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
Openthinkimg: Learning to think with images via visual tool reinforcement learning , author=. arXiv preprint arXiv:2505.08617 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
arXiv preprint arXiv:2510.01179 , year=
Toucan: Synthesizing 1.5 m tool-agentic data from real-world mcp environments , author=. arXiv preprint arXiv:2510.01179 , year=
-
[41]
Narasimhan and Yuan Cao , title =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R. Narasimhan and Yuan Cao , title =. The Eleventh International Conference on Learning Representations , year =
-
[42]
arXiv preprint arXiv:2508.21104 , year=
PVPO: Pre-Estimated Value-Based Policy Optimization for Agentic Reasoning , author=. arXiv preprint arXiv:2508.21104 , year=
-
[43]
Wang, Jize and Zerun, Ma and Li, Yining and Zhang, Songyang and Chen, Cailian and Chen, Kai and Le, Xinyi , booktitle=
-
[44]
MCPE val: Automatic MCP -based Deep Evaluation for AI Agent Models
Liu, Zhiwei and Qiu, Jielin and Wang, Shiyu and Zhang, Jianguo and Liu, Zuxin and Ram, Roshan and Chen, Haolin and Yao, Weiran and Heinecke, Shelby and Savarese, Silvio and Wang, Huan and Xiong, Caiming. MCPE val: Automatic MCP -based Deep Evaluation for AI Agent Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processin...
2025
-
[45]
arXiv preprint arXiv:2505.16700 , year=
Mcp-radar: A multi-dimensional benchmark for evaluating tool use capabilities in large language models , author=. arXiv preprint arXiv:2505.16700 , year=
-
[46]
2024 , howpublished =
Introducing the Model Context Protocol , author =. 2024 , howpublished =
2024
-
[47]
arXiv preprint arXiv:2507.15296 , year=
Butterfly effects in toolchains: A comprehensive analysis of failed parameter filling in llm tool-agent systems , author=. arXiv preprint arXiv:2507.15296 , year=
-
[48]
2026 , journal=
Towards Customized Multimodal Role-Play , author=. 2026 , journal=
2026
-
[49]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3.2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Glm-4.5: Agentic, reasoning, and coding (arc) foundation models , author=. arXiv preprint arXiv:2508.06471 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
arXiv preprint arXiv:2509.01322 , year=
Longcat-flash technical report , author=. arXiv preprint arXiv:2509.01322 , year=
-
[53]
arXiv preprint arXiv:2503.23383 , year=
Torl: Scaling tool-integrated rl , author=. arXiv preprint arXiv:2503.23383 , year=
-
[54]
Yu, Qiying and Zhang, Zheng and Zhu, Ruofei and Yuan, Yufeng and Zuo, Xiaochen and Yue, Yu and Dai, Weinan and Fan, Tiantian and Liu, Gaohong and Liu, Lingjun and others , booktitle=
-
[55]
API-Bank:
Minghao Li and Yingxiu Zhao and Bowen Yu and Feifan Song and Hangyu Li and Haiyang Yu and Zhoujun Li and Fei Huang and Yongbin Li , editor =. API-Bank:. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
2023
-
[56]
The Twelfth International Conference on Learning Representations , year =
Yue Huang and Jiawen Shi and Yuan Li and Chenrui Fan and Siyuan Wu and Qihui Zhang and Yixin Liu and Pan Zhou and Yao Wan and Neil Zhenqiang Gong and Lichao Sun , title =. The Twelfth International Conference on Learning Representations , year =
-
[57]
Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and others , journal=
-
[58]
Proceedings of the 31st International Conference on Computational Linguistics , year =
Junjie Ye and Guanyu Li and Songyang Gao and Caishuang Huang and Yilong Wu and Sixian Li and Xiaoran Fan and Shihan Dou and Tao Ji and Qi Zhang and Tao Gui and Xuanjing Huang , title =. Proceedings of the 31st International Conference on Computational Linguistics , year =
-
[59]
The Twelfth International Conference on Learning Representations , year =
Xingyao Wang and Zihan Wang and Jiateng Liu and Yangyi Chen and Lifan Yuan and Hao Peng and Heng Ji , title =. The Twelfth International Conference on Learning Representations , year =
-
[60]
Frontiers Comput
Lei Wang and Chen Ma and Xueyang Feng and Zeyu Zhang and Hao Yang and Jingsen Zhang and Zhiyuan Chen and Jiakai Tang and Xu Chen and Yankai Lin and Wayne Xin Zhao and Zhewei Wei and Jirong Wen , title =. Frontiers Comput. Sci. , volume =
-
[61]
Tool learning with large language models: a survey , journal =
Changle Qu and Sunhao Dai and Xiaochi Wei and Hengyi Cai and Shuaiqiang Wang and Dawei Yin and Jun Xu and Ji. Tool learning with large language models: a survey , journal =
-
[62]
Thyme: Think beyond images , author=. arXiv preprint arXiv:2508.11630 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and Zhang, Shudan and Deng, Xiang and Zeng, Aohan and Du, Zhengxiao and Zhang, Chenhui and Shen, Sheng and Zhang, Tianjun and Su, Yu and Sun, Huan and Huang, Minlie and Dong, Yuxiao and Tang, Jie , booktitle =
-
[64]
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle =
-
[65]
and Del Verme, Manuel and Marty, Tom and Boisvert, L
Drouin, Alexandre and Gasse, Maxime and Caccia, Massimo and Laradji, Issam H. and Del Verme, Manuel and Marty, Tom and Boisvert, L. Proceedings of the 41st International Conference on Machine Learning , year =
-
[66]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle =
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle =
-
[67]
Koh, Jing Yu and Lo, Robert and Jang, Lawrence and Duvvur, Vikram and Lim, Ming Chong and Huang, Po-Yu and Neubig, Graham and Zhou, Shuyan and Salakhutdinov, Ruslan and Fried, Daniel , booktitle =
-
[68]
Trivedi, Harsh and Khot, Tushar and Hartmann, Mareike and Manku, Ruskin and Dong, Vinty and Li, Edward and Gupta, Shashank and Sabharwal, Ashish and Balasubramanian, Niranjan , booktitle =
-
[69]
Ma, Chang and Zhang, Junlei and Zhu, Zhihao and Yang, Cheng and Yang, Yujiu and Jin, Yaohui and Lan, Zhenzhong and Kong, Lingpeng and He, Junxian , booktitle =
-
[70]
Xie, Tianbao and Zhang, Danyang and Chen, Jixuan and Li, Xiaochuan and Zhao, Siheng and Cao, Ruisheng and Hua, Toh Jing and Cheng, Zhoujun and Shin, Dongchan and Lei, Fangyu and Liu, Yitao and Xu, Yiheng and Zhou, Shuyan and Savarese, Silvio and Xiong, Caiming and Zhong, Victor and Yu, Tao , booktitle =
-
[71]
Andriushchenko, Maksym and Souly, Alexandra and Dziemian, Mateusz and Duenas, Derek and Lin, Maxwell and Wang, Justin and Hendrycks, Dan and Zou, Andy and Kolter, Zico and Fredrikson, Matt and Winsor, Eric and Wynne, Jerome and Gal, Yarin and Davies, Xander , booktitle =
-
[72]
Agent Security Bench (
Zhang, Hanrong and Huang, Jingyuan and Mei, Kai and Yao, Yifei and Wang, Zhenting and Zhan, Chenlu and Wang, Hongwei and Zhang, Yongfeng , booktitle =. Agent Security Bench (
-
[73]
and Song, Yufan and Li, Boxuan and Tang, Yuxuan and Jain, Kritanjali and Bao, Mengxue and Wang, Zora Z
Xu, Frank F. and Song, Yufan and Li, Boxuan and Tang, Yuxuan and Jain, Kritanjali and Bao, Mengxue and Wang, Zora Z. and Zhou, Xuhui and Guo, Zhitong and Cao, Murong and Yang, Mingyang and Lu, Hao Yang and Martin, Amaad and Su, Zhe and Maben, Leander and Mehta, Raj and Chi, Wayne and Jang, Lawrence and Xie, Yiqing and Zhou, Shuyan and Neubig, Graham , booktitle =
-
[74]
Advances in Neural Information Processing Systems , volume=
Pengxiang Li and Zhi Gao and Bofei Zhang and Tao Yuan and Yuwei Wu and Mehrtash Harandi and Yunde Jia and Song. Advances in Neural Information Processing Systems , volume=
-
[75]
Advances in Neural Information Processing Systems , volume=
Sirius: Self-improving multi-agent systems via bootstrapped reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[76]
Aligning Agents via Planning: A Benchmark for Trajectory-Level Reward Modeling
Aligning Agents via Planning: A Benchmark for Trajectory-Level Reward Modeling , author=. arXiv preprint arXiv:2604.08178 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
National Science Review , volume=
Open-environment machine learning , author=. National Science Review , volume=
-
[78]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Towards Safe Weakly Supervised Learning , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[79]
Proceedings of the 37th International Conference on Machine Learning , year=
Safe Deep Semi-Supervised Learning for Unseen-Class Unlabeled Data , author=. Proceedings of the 37th International Conference on Machine Learning , year=
-
[80]
Proceedings of the 39th International Conference on Machine Learning , year=
Class-Imbalanced Semi-Supervised Learning with Adaptive Thresholding , author=. Proceedings of the 39th International Conference on Machine Learning , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.