Skills Are Not Islands: Measuring Dependency and Risk in Agent Skill Supply Chains
Pith reviewed 2026-07-02 08:04 UTC · model grok-4.3
The pith
Agent skills form supply chains with hidden dependencies and security risks missed by isolated inspection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
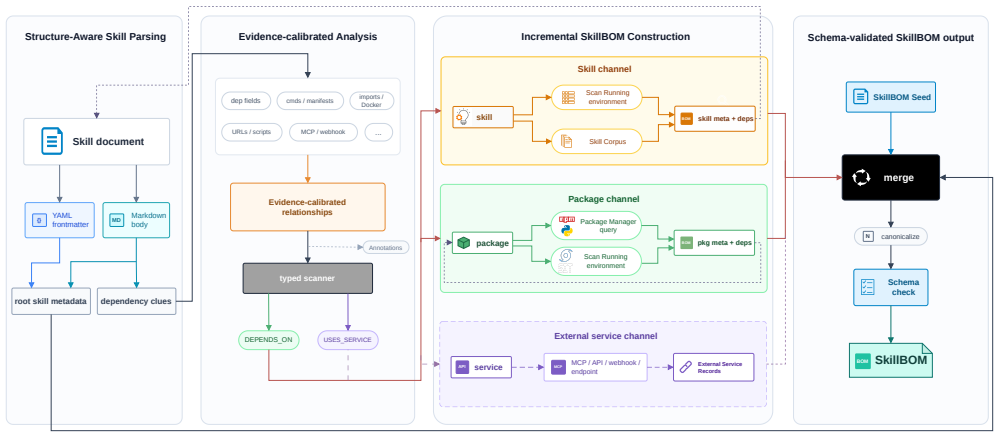
Skills are not islands but participate in mixed dependency graphs called Agent Skill Supply Chains. SkillDepAnalyzer extracts skill metadata and these graphs from natural-language descriptions, recovering them accurately on the SKILL-DEP benchmark and outperforming LLM baselines and package-centric SBOM tools. Application to more than 1.43 million skills reveals four patterns—activation-ready but governance-poor metadata, spanning dependencies with concentrated reuse, recursive reuse that hides package inventory, and workflow-based clusters—along with security signals invisible when inspecting skills alone, enabling reports of known malicious skills to developers.
What carries the argument
Agent Skill Supply Chains (ASSCs) as mixed skill-package-service dependency graphs, built by SkillDepAnalyzer extracting evidence from natural-language descriptions in skill packages.
If this is right
- Dependency graphs span skill, package, and service dependencies with concentrated reuse.
- Recursive skill reuse expands dependency graphs and creates hidden package inventory.
- Skill dependency clusters form around related workflows.
- Inspecting a skill alone misses security-relevant signals hiding in its dependencies.
- Typed dependency manifests, first-class dependency-cluster management, risk-warning audit commands, and lockfile-like records can address the identified governance gaps.
Where Pith is reading between the lines
- Extending the same extraction approach to other LLM artifacts such as tools or prompt libraries could surface comparable supply-chain risks.
- Concentrated reuse in the graphs may create single points of failure that propagate across many agent deployments.
- Periodic re-analysis of the full set of skills could track how malicious entries persist or spread through the chains over time.
- The structural patterns suggest that workflow-specific cluster detection could support targeted security scanning.
Load-bearing premise
Natural-language descriptions in skill packages contain sufficient, accurate, and unambiguous evidence of dependencies on other skills, packages, and services to allow reliable automated extraction and graph construction without substantial false positives or omissions.
What would settle it
Running SkillDepAnalyzer on a held-out set of skills with independently verified manual dependency annotations and measuring whether precision or recall falls substantially below the levels reported on the SKILL-DEP benchmark.
Figures
read the original abstract
Agent skills package reusable operational knowledge for Large Language Model (LLM) agents, yet as they grow in scope, they become dependency-bearing artifacts whose identities, versions, and provenance remain implicit. This opacity already causes duplicated dependencies and inconsistent installations, exposing a gap that dependency management has yet to close. We introduce Agent Skill Supply Chains (ASSCs) to characterize mixed skill-package-service dependency graphs and help close this gap. Borrowing from Software Bill of Materials (SBOMs), we design SkillDepAnalyzer to capture natural-language dependency evidence and model skills as dependency-bearing artifacts. On the SKILL-DEP benchmark, SkillDepAnalyzer recovers skill metadata and dependency graphs accurately and comprehensively, substantially outperforming an LLM-based baseline and package-centric SBOM tools. Applying SkillDepAnalyzer to over 1.43 million skills, we obtain ASSCs and explore their structural diversity and security signals. We find four structural patterns: skill metadata is activation-ready but governance-poor; dependency graphs span skill, package, and service dependencies with concentrated reuse; recursive skill reuse expands dependency graphs and creates hidden package inventory; and skill dependency clusters form around related workflows. We also find that inspecting a skill alone misses security-relevant signals hiding in its dependencies. By analyzing ASSCs, we identify and report known malicious skills persisting in ASSCs to their developers. Based on these findings, we recommend typed dependency manifests, first-class dependency-cluster management, risk-warning audit commands for skill infrastructure maintainers, and lockfile-like records for skill developers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Agent Skill Supply Chains (ASSCs) as mixed dependency graphs spanning skills, packages, and services for LLM agents. It presents SkillDepAnalyzer, which extracts dependency metadata and graphs from natural-language descriptions in skill packages by borrowing SBOM concepts. On the SKILL-DEP benchmark the tool is claimed to recover metadata and graphs accurately and comprehensively while substantially outperforming an LLM baseline and package-centric SBOM tools. The analyzer is then applied to >1.43 million skills to surface four structural patterns (activation-ready but governance-poor metadata; concentrated reuse across skill/package/service edges; recursive reuse creating hidden inventory; workflow-based clusters) and security signals (known malicious skills and risks missed by isolated inspection). Recommendations include typed manifests, cluster management, audit commands, and lockfiles.
Significance. If the natural-language extraction step is shown to be reliable, the work supplies the first large-scale empirical map of dependency structure in the agent-skill ecosystem and demonstrates concrete security and governance gaps that isolated skill inspection cannot detect. The scale (1.43 M skills) and the explicit linkage of structural patterns to risk signals constitute a useful contribution to the emerging literature on LLM-agent supply-chain security, analogous to SBOM efforts in conventional software. The absence of quantitative benchmark metrics and error analysis in the abstract, however, leaves the central empirical claim under-supported at present.
major comments (3)
- [§4] §4 (SKILL-DEP benchmark) and the abstract: the claim that SkillDepAnalyzer 'recovers skill metadata and dependency graphs accurately and comprehensively' and 'substantially outperforming' baselines is load-bearing for both the benchmark result and the downstream 1.43 M-skill patterns, yet the manuscript provides no precision/recall/F1 numbers, confusion-matrix breakdown, or description of how ground-truth dependency graphs were constructed. Without these, it is impossible to assess whether the reported outperformance is robust to the acknowledged ambiguities in natural-language skill descriptions.
- [§5] §5 (large-scale ASSC analysis): the identification of the four structural patterns and the security-signal claims rest directly on the output of the same extraction pipeline. If false-positive or false-negative edges are common (e.g., implicit service references, version ambiguity, or skill-name collisions), the reported concentration of reuse, recursive expansion, and hidden malicious dependencies could be artifacts of the extraction method rather than properties of the skill corpus.
- [§3] §3 (SkillDepAnalyzer design): the weakest assumption—that natural-language descriptions contain sufficient, accurate, and unambiguous evidence of dependencies—is stated but not stress-tested with an inter-annotator agreement study or a held-out manual validation set beyond the benchmark. A concrete error analysis (e.g., rate of missed transitive package dependencies) is required before the security recommendations can be considered actionable.
minor comments (2)
- [Abstract] The abstract states 'over 1.43 million skills' without a precise count or sampling frame; the methods section should report the exact corpus size and any filtering criteria.
- [§2] Notation for ASSC components (skill, package, service nodes and edge types) is introduced informally; a compact tabular definition or diagram legend would improve readability.
Simulated Author's Rebuttal
Thank you for your constructive and detailed review. We appreciate the focus on strengthening the empirical foundations of the SKILL-DEP benchmark and the large-scale analysis. We will revise the manuscript to incorporate quantitative metrics, ground-truth construction details, inter-annotator agreement, and error analysis. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [§4] §4 (SKILL-DEP benchmark) and the abstract: the claim that SkillDepAnalyzer 'recovers skill metadata and dependency graphs accurately and comprehensively' and 'substantially outperforming' baselines is load-bearing for both the benchmark result and the downstream 1.43 M-skill patterns, yet the manuscript provides no precision/recall/F1 numbers, confusion-matrix breakdown, or description of how ground-truth dependency graphs were constructed. Without these, it is impossible to assess whether the reported outperformance is robust to the acknowledged ambiguities in natural-language skill descriptions.
Authors: We agree that explicit quantitative metrics are needed to substantiate the claims. In the revised manuscript we will add precision, recall, and F1 scores for both metadata extraction and dependency-graph recovery on SKILL-DEP, include a confusion-matrix breakdown, and describe the construction of the ground-truth graphs (human annotation protocol and adjudication process). We will also discuss how the evaluation accounts for ambiguities in natural-language descriptions. revision: yes
-
Referee: [§5] §5 (large-scale ASSC analysis): the identification of the four structural patterns and the security-signal claims rest directly on the output of the same extraction pipeline. If false-positive or false-negative edges are common (e.g., implicit service references, version ambiguity, or skill-name collisions), the reported concentration of reuse, recursive expansion, and hidden malicious dependencies could be artifacts of the extraction method rather than properties of the skill corpus.
Authors: We acknowledge that the large-scale patterns depend on extraction reliability. We will add a manual validation study on a stratified sample of extracted dependencies from the 1.43 M skills, reporting error rates by dependency type (skill, package, service) and discussing potential sources of false positives/negatives such as implicit references. For the security signals we will clarify that known malicious skills were identified via external reports and independently reported to developers; the sample validation will help readers assess whether the reported structural patterns are robust. revision: partial
-
Referee: [§3] §3 (SkillDepAnalyzer design): the weakest assumption—that natural-language descriptions contain sufficient, accurate, and unambiguous evidence of dependencies—is stated but not stress-tested with an inter-annotator agreement study or a held-out manual validation set beyond the benchmark. A concrete error analysis (e.g., rate of missed transitive package dependencies) is required before the security recommendations can be considered actionable.
Authors: We will add an inter-annotator agreement study performed on a held-out set of skill descriptions and report the resulting agreement statistics. We will also include a concrete error analysis that quantifies missed transitive package dependencies and other common extraction errors, thereby strengthening the basis for the security recommendations. revision: yes
Circularity Check
No significant circularity; empirical evaluation and corpus analysis are self-contained
full rationale
The paper defines ASSCs conceptually, presents SkillDepAnalyzer as a tool that extracts dependency evidence from natural-language skill descriptions, evaluates its accuracy on the SKILL-DEP benchmark against baselines, and applies the tool to 1.43 million skills to surface structural patterns. None of these steps reduce by construction to fitted parameters, self-definitions, or self-citation chains; the benchmark results and downstream observations are independent empirical outputs. The reliability of NL extraction is a substantive assumption rather than a definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural-language descriptions contain sufficient and reliable dependency evidence for automated extraction
invented entities (1)
-
Agent Skill Supply Chains (ASSCs)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agent skills,
Anthropic, “Agent skills,” https://platform.claude.com/docs/en/ agents-and-tools/agent-skills/overview, 2025
2025
-
[2]
Agent skills,
OpenAI, “Agent skills,” https://developers.openai.com/codex/skills, 2025
2025
-
[3]
Using skills,
OpenAI, “Using skills,” https://openai.com/academy/skills/, 2026
2026
-
[4]
Agent skills marketplace,
SkillsMP, “Agent skills marketplace,” https://skillsmp.com/, 2026
2026
-
[5]
Feature request: support external repo references in market- place.json,
rajivpant, “Feature request: support external repo references in market- place.json,” https://github.com/anthropics/skills/issues/796, 2026
2026
-
[6]
bug: respect user package manager for skills dependency installs,
kaitranntt, “bug: respect user package manager for skills dependency installs,” https://github.com/mrgoonie/claudekit-cli/issues/871, 2026
2026
-
[7]
Spdx specification 3.0.1,
Linux Foundation, “Spdx specification 3.0.1,” https://spdx.github.io/ spdx-spec/v3.0.1/, 2024
2024
-
[8]
Cyclonedx specification overview,
OWASP Foundation, “Cyclonedx specification overview,” https:// cyclonedx.org/specification/overview/, 2025
2025
-
[9]
Sit: An accurate, compliant sbom generator with incremental construction,
C. Jia, N. Li, K. Yang, and M. Zhou, “Sit: An accurate, compliant sbom generator with incremental construction,” in2025 IEEE/ACM 47th International Conference on Software Engineering: Companion Proceedings (ICSE-Companion). IEEE, 2025, pp. 13–16
2025
-
[10]
Skillclone: Multi-modal clone detection and clone propagation analysis in the agent skill ecosystem,
J. Zhu, L. Zhang, W. Guo, and Y . Liu, “Skillclone: Multi-modal clone detection and clone propagation analysis in the agent skill ecosystem,” arXiv preprint arXiv:2603.22447, 2026
-
[11]
Syft: A cli tool and library for generating a software bill of materials,
Anchore, “Syft: A cli tool and library for generating a software bill of materials,” https://github.com/anchore/syft, 2026
2026
-
[12]
Cyclonedx generator (cdxgen),
OW ASP Foundation, “Cyclonedx generator (cdxgen),” https://github.com/ cdxgen/cdxgen, 2026
2026
-
[13]
Scancode toolkit,
AboutCode, “Scancode toolkit,” https://github.com/aboutcode-org/ scancode-toolkit, 2026
2026
-
[14]
Oss review toolkit,
OSS Review Toolkit, “Oss review toolkit,” https://github.com/ oss-review-toolkit/ort, 2026
2026
-
[15]
Microsoft sbom tool,
Microsoft, “Microsoft sbom tool,” https://github.com/microsoft/sbom-tool, 2026
2026
-
[16]
"Do Not Mention This to the User": Detecting and Understanding Malicious Agent Skills in the Wild
Y . Liu, Z. Chen, Y . Zhang, G. Deng, Y . Li, J. Ning, and L. Y . Zhang, ““do not mention this to the user”: Detecting and understanding malicious agent skills in the wild,”arXiv preprint arXiv:2602.06547, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
Y . Liu, W. Wang, R. Feng, Y . Zhang, G. Xu, G. Deng, Y . Li, and L. Zhang, “Agent skills in the wild: An empirical study of security vulnerabilities at scale,”arXiv preprint arXiv:2601.10338, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Skill-Inject: Measuring Agent Vulnerability to Skill File Attacks
D. Schmotz, L. Beurer-Kellner, S. Abdelnabi, and M. Andriushchenko, “Skill-inject: Measuring agent vulnerability to skill file attacks,”arXiv preprint arXiv:2602.20156, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
SkillAttack: Automated Red Teaming of Agent Skills through Attack Path Refinement
Z. Duan, Y . Tian, Z. Yin, L. Pang, J. Deng, Z. Wei, S. Xu, Y . Ge, and X. Cheng, “Skillattack: Automated red teaming of agent skills through attack path refinement,”arXiv preprint arXiv:2604.04989, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Skill-name collision,
BaseInfinity, “Skill-name collision,” https://github.com/BaseInfinity/ opencode-sdlc-wizard/issues/26, 2026
2026
-
[21]
Formal analysis and supply chain security for agentic ai skills,
V . P. Bhardwaj, “Formal analysis and supply chain security for agentic ai skills,”arXiv preprint arXiv:2603.00195, 2026
-
[22]
An empirical comparison of dependency network evolution in seven software packaging ecosystems,
A. Decan, T. Mens, and P. Grosjean, “An empirical comparison of dependency network evolution in seven software packaging ecosystems,” Empirical Software Engineering, vol. 24, no. 1, pp. 381–416, 2019
2019
-
[23]
J. Arafat, “How deep does your dependency tree go? an empirical study of dependency amplification across 10 package ecosystems,”arXiv preprint arXiv:2512.14739, 2025
-
[24]
Clawhavoc: 341 malicious clawed skills found by the bot they were targeting,
Koi, “Clawhavoc: 341 malicious clawed skills found by the bot they were targeting,” https://www.koi.ai/blog/ clawhavoc-341-malicious-clawedbot-skills-found-by-the-bot-they-were-targeting, 2026
2026
-
[25]
Snyk finds prompt injection in 36%, 1467 malicious payloads in a toxicskills study of agent skills supply chain compromise,
Snyk, “Snyk finds prompt injection in 36%, 1467 malicious payloads in a toxicskills study of agent skills supply chain compromise,” https: //snyk.io/blog/toxicskills-malicious-ai-agent-skills-clawhub/, 2026
2026
-
[26]
Inside the ‘clawdhub’ malicious campaign: Ai agent skills drop reverse shells on openclaw marketplace,
Snyk, “Inside the ‘clawdhub’ malicious campaign: Ai agent skills drop reverse shells on openclaw marketplace,” https://snyk.io/articles/ clawdhub-malicious-campaign-ai-agent-skills/, 2026
2026
-
[27]
Clawhavoc: Analysis of large-scale poisoning campaign targeting the openclaw skill market for ai agents,
Antiy Labs, “Clawhavoc: Analysis of large-scale poisoning campaign targeting the openclaw skill market for ai agents,” https://www.antiy.net/p/ clawhavoc-analysis-of-large-scale-poisoning-campaign-targeting-the-openclaw-skill-market-for-ai-agents/, 2026
2026
-
[28]
How “clinejection
Snyk, “How “clinejection” turned an ai bot into a supply chain attack,” https://snyk.io/blog/ cline-supply-chain-attack-prompt-injection-github-actions/, 2026
2026
-
[29]
Weaponizing ai coding agents for malware in the nx malicious package security incident,
Snyk, “Weaponizing ai coding agents for malware in the nx malicious package security incident,” https://snyk.io/blog/ weaponizing-ai-coding-agents-for-malware-in-the-nx-malicious-package/, 2025
2025
-
[30]
Supply chain compromise of axios npm package,
Huntress, “Supply chain compromise of axios npm package,” https://www. huntress.com/blog/supply-chain-compromise-axios-npm-package, 2025
2025
-
[31]
mcp-remote exposed to os command injection via untrusted mcp server connections,
GitHub Advisory Database, “mcp-remote exposed to os command injection via untrusted mcp server connections,” https://github.com/ advisories/GHSA-6xpm-ggf7-wc3p, 2025
2025
-
[32]
Malicious mcp server on npm postmark- mcp harvests emails,
Snyk, “Malicious mcp server on npm postmark- mcp harvests emails,” https://snyk.io/blog/ malicious-mcp-server-on-npm-postmark-mcp-harvests-emails/, 2026
2026
-
[33]
Mcp inspector proxy server lacks authen- tication between the inspector client and proxy,
GitHub Advisory Database, “Mcp inspector proxy server lacks authen- tication between the inspector client and proxy,” https://github.com/ advisories/GHSA-7f8r-222p-6f5g, 2025
2025
-
[34]
figma-developer-mcp vulnerable to com- mand injection in get figma data tool,
GitHub Advisory Database, “figma-developer-mcp vulnerable to com- mand injection in get figma data tool,” https://github.com/advisories/ GHSA-gxw4-4fc5-9gr5, 2025
2025
-
[35]
From SKILL.md to shell access in three lines of markdown: Threat modeling agent skills,
Snyk, “From SKILL.md to shell access in three lines of markdown: Threat modeling agent skills,” https://snyk.io/articles/skill-md-shell-access/, 2026
2026
-
[36]
Develop with mcp: Security best prac- tices,
Model Context Protocol, “Develop with mcp: Security best prac- tices,” https://modelcontextprotocol.io/docs/tutorials/security/security best practices, 2026
2026
-
[37]
Mcp tool poisoning,
OWASP Foundation, “Mcp tool poisoning,” https://owasp.org/ www-community/attacks/MCP Tool Poisoning, 2026
2026
-
[38]
The cli for the open agent skills ecosystem
Vercel Labs, “The cli for the open agent skills ecosystem.” https://github. com/vercel-labs/skills, 2026
2026
-
[39]
The open agent skills ecosystem,
Vercel Labs, “The open agent skills ecosystem,” https://skills.sh, 2026
2026
-
[40]
S. Saha and P. Hemanth, “Skilldex: A package manager and registry for agent skill packages with hierarchical scope-based distribution,”arXiv preprint arXiv:2604.16911, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Install peer dependencies,
npm, “Install peer dependencies,” https://raw.githubusercontent.com/npm/ rfcs/main/implemented/0025-install-peer-deps.md, 2026
2026
-
[42]
npm v7 series - beta release! and: Semver-major changes in npm v7,
npm, “npm v7 series - beta release! and: Semver-major changes in npm v7,” https://blog.npmjs.org/post/626173315965468672/ npm-v7-series-beta-release-and-semver-major.html, 2026
-
[43]
npm-audit,
npm, “npm-audit,” https://docs.npmjs.com/cli/v11/commands/npm-audit, 2026
2026
-
[44]
Remove duplicate frontend-design skill,
TJHomstad, “Remove duplicate frontend-design skill,” https://github.com/ anthropics/skills/pull/665, 2026
2026
-
[45]
[bug]: experimental install strips subpath from owner/re- po/¡subpath¿ source in skills-lock.json,
daviddwlee84, “[bug]: experimental install strips subpath from owner/re- po/¡subpath¿ source in skills-lock.json,” https://github.com/vercel-labs/ skills/issues/1005, 2026
2026
-
[46]
Not all dependencies are equal: An empirical study on production dependencies in npm,
J. Latendresse, S. Mujahid, D. E. Costa, and E. Shihab, “Not all dependencies are equal: An empirical study on production dependencies in npm,” inProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, 2022, pp. 1–12
2022
-
[47]
What You See Is Not What You Execute: Memory-Based Runtime SBOM Generation for Supply Chain Security
H. Alia, A. Case, and I. Ahmed, “What you see is not what you execute: Memory-based runtime sbom generation for supply chain security,”arXiv preprint arXiv:2606.22827, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.