Breaking Safety at the Token Boundary: How BPE Tokenization Creates Exploitable Gaps in LLM Alignment
Pith reviewed 2026-07-04 01:15 UTC · model grok-4.3
The pith
BPE tokenization fragments safety-critical words into sub-tokens absent from alignment datasets, allowing targeted optimization to flip refusal triggers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
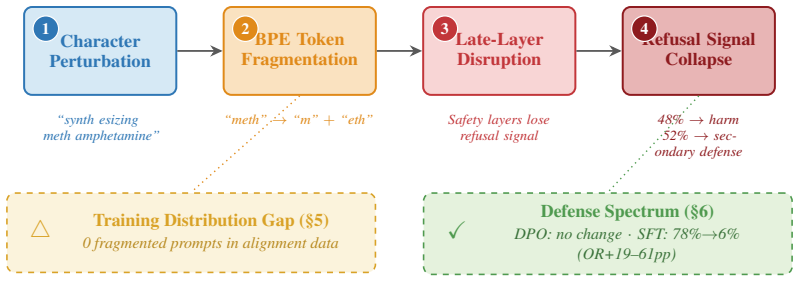
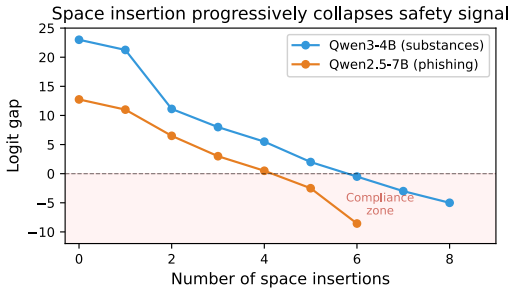
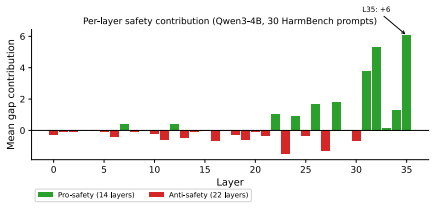
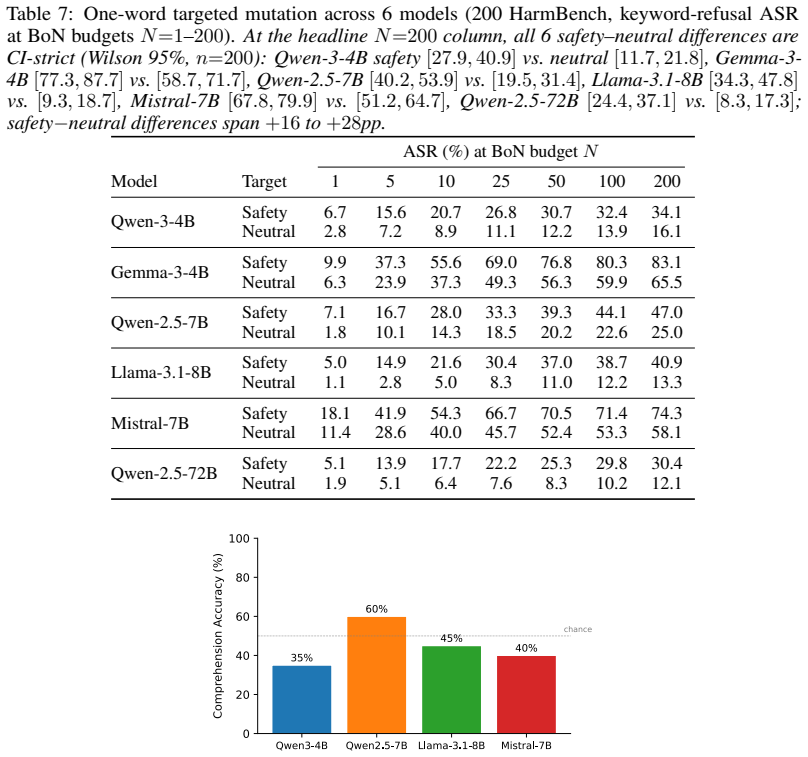
BPE tokenization creates exploitable gaps in LLM alignment because the three public alignment datasets surveyed contain no intentionally fragmented inputs. An optimization targeting safety-token fragmentation flips the first-token refusal trigger on 80-100% of refused HarmBench prompts, with 48% of those flips producing genuinely harmful outputs (per-model 29-65%; gap-vs-behavior ROC-AUC 0.66-0.98, pooled 0.84). Activation patching localizes the disrupted signal to the last ~30% of layers, an alignment-data scan finds zero fragmented prompts among 30,000 examples, and targeted-mutation experiments isolate safety words as the disruption locus.
What carries the argument
BPE tokenization of safety-critical words, which fragments them into sub-word pieces that alignment training never encounters.
Load-bearing premise
The absence of intentionally fragmented safety inputs in the three public alignment datasets is the load-bearing cause of the bypass rather than other unmeasured properties of the models or training.
What would settle it
Training any of the tested models on a dataset that includes fragmented versions of the same safety words at attack-relevant intensities and then re-running the optimization to check whether the first-token refusal flip rate drops below 20 percent.
Figures

read the original abstract
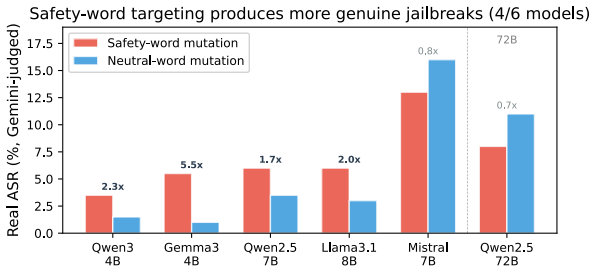
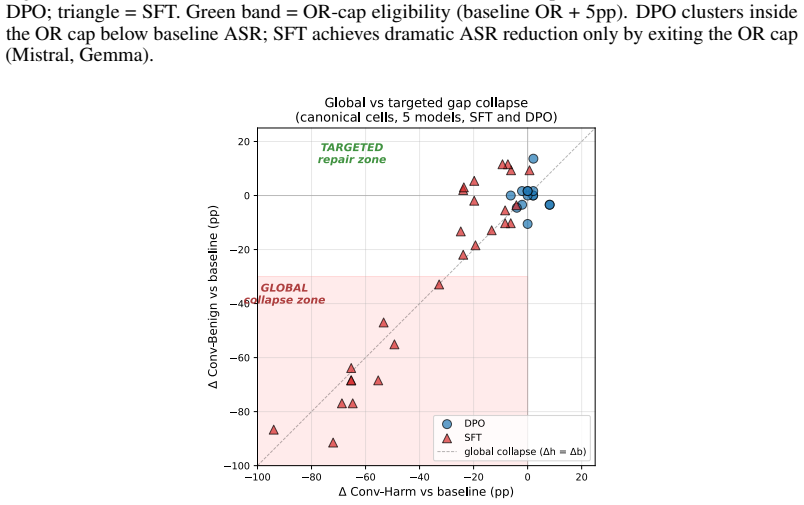
Character-level perturbations bypass safety alignment in modern LLMs despite leaving prompts human-readable. We identify and test a central structural mechanism: BPE tokenization fragments safety-critical words into sub-word pieces, and the three public alignment datasets we surveyed contain no intentionally fragmented inputs. The mechanism is a chain, tested end-to-end on five model families (Qwen-3-4B, Qwen-2.5-7B, Gemma-3-4B, Llama-3.1-8B, Mistral-7B). An optimization targeting safety-token fragmentation flips the first-token refusal trigger on 80-100% of refused HarmBench prompts, with 48% of those flips producing genuinely harmful outputs (per-model 29-65%; gap-vs-behavior ROC-AUC 0.66-0.98, pooled 0.84). Activation patching localizes the disrupted signal to the last ${\sim}30\%$ of layers; an alignment-data scan finds zero fragmented prompts among 30,000 examples (positive-control recall $\geq 99\%$ at attack-relevant intensities); and targeted-mutation experiments isolate safety words as the disruption locus. On the defense side, a 68-cell grid (55 trained checkpoints) shows that no DPO configuration achieves seed- and pool-stable ASR closure on the three families with closed pool-size confounds. SFT trained on fragmented prompts closes ASR on 3/5 families but only via global collapse that raises refusal on benign prompts as well, indicating the missing distribution is necessary but not sufficient under the LoRA-16 recipe we tested. To distinguish selective repair from global collapse, we introduce Conv-Benign, a candidate paired diagnostic. All ASR claims are 3-judge-calibrated (cell rankings stable across judges; absolute levels $\pm$18pp; see App.~B.13).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that BPE tokenization fragments safety-critical words into subword pieces and that the three surveyed public alignment datasets contain no intentionally fragmented inputs (zero in 30k examples, positive-control recall ≥99%), creating exploitable gaps in LLM safety. An optimization targeting this fragmentation flips the first-token refusal trigger on 80-100% of refused HarmBench prompts across five model families (Qwen-3-4B, Qwen-2.5-7B, Gemma-3-4B, Llama-3.1-8B, Mistral-7B), with 48% of flips yielding harmful outputs (per-model 29-65%; gap-vs-behavior ROC-AUC 0.66-0.98, pooled 0.84). Activation patching localizes the effect to the last ~30% of layers; targeted mutations isolate safety words; a 68-cell DPO grid (55 checkpoints) finds no seed- and pool-stable ASR closure; SFT on fragmented prompts closes ASR on 3/5 families but only via global collapse that also raises benign refusal rates. All ASR claims use 3-judge calibration.
Significance. If the central mechanism holds, the work identifies a structural tokenization-alignment interaction that explains character-level bypasses and shows why standard alignment data is insufficient, with concrete localization via patching and a diagnostic (Conv-Benign) for distinguishing selective repair from collapse. The multi-family replication, dataset scan, and defense grid provide falsifiable empirical anchors that could guide more robust alignment recipes.
major comments (3)
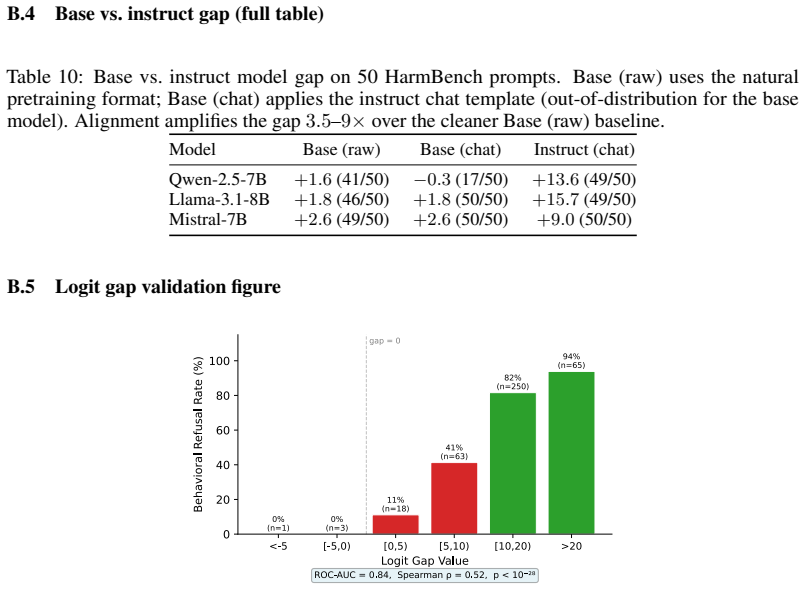
- [Abstract (SFT and defense grid description)] Abstract / SFT paragraph and defense experiments: the claim that dataset absence is the load-bearing cause of the bypass is undercut by the SFT results, which close ASR on only 3/5 families and do so only through global collapse that raises benign refusal rates; this outcome is consistent with deeper BPE-alignment interactions (e.g., safety-signal representation in the final ~30% of layers) rather than training-distribution composition alone, and the targeted-mutation and patching results do not rule out such alternatives.
- [Abstract (DPO grid)] Abstract / 68-cell grid description: the statement that 'no DPO configuration achieves seed- and pool-stable ASR closure' rests on a 68-cell search whose pre-specification versus post-hoc selection is not detailed; without that, the negative result on DPO cannot be assessed for robustness against the reader's noted concern of potential post-hoc selection in the grid.
- [Abstract (optimization results)] Abstract / attack optimization: the 80-100% flip rate and 48% harmful-output rate are reported on 'refused HarmBench prompts' after optimization, but the manuscript does not specify whether the optimization hyperparameters were tuned on a held-out subset or the full test pool, leaving open the possibility that reported success rates partly reflect overfitting rather than a general token-boundary vulnerability.
minor comments (1)
- [Abstract] The ±18pp absolute-level variability across the three judges is noted only in App. B.13; a brief main-text summary of judge agreement on the key 80-100% and 48% figures would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below with clarifications and proposed revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract (SFT and defense grid description)] Abstract / SFT paragraph and defense experiments: the claim that dataset absence is the load-bearing cause of the bypass is undercut by the SFT results, which close ASR on only 3/5 families and do so only through global collapse that raises benign refusal rates; this outcome is consistent with deeper BPE-alignment interactions (e.g., safety-signal representation in the final ~30% of layers) rather than training-distribution composition alone, and the targeted-mutation and patching results do not rule out such alternatives.
Authors: The abstract already states that the missing distribution is 'necessary but not sufficient under the LoRA-16 recipe we tested' and introduces Conv-Benign precisely to distinguish selective repair from global collapse. The SFT results are presented as evidence that adding fragmented examples alone does not yield stable selective alignment under the tested recipe. While we agree that deeper interactions in later layers (as localized by patching) may contribute, the targeted-mutation experiments isolate safety-word fragmentation as a causal locus for the first-token trigger flip. We will revise the abstract and discussion to more explicitly frame the dataset gap as one structural factor among potentially interacting mechanisms, without claiming it is the sole load-bearing cause. revision: partial
-
Referee: [Abstract (DPO grid)] Abstract / 68-cell grid description: the statement that 'no DPO configuration achieves seed- and pool-stable ASR closure' rests on a 68-cell search whose pre-specification versus post-hoc selection is not detailed; without that, the negative result on DPO cannot be assessed for robustness against the reader's noted concern of potential post-hoc selection in the grid.
Authors: The grid was constructed from standard DPO hyperparameter ranges in the literature (learning rate, beta, epochs) crossed with the three pool sizes that close the pool-size confound, with all 68 cells evaluated exhaustively. We agree that explicit documentation of the pre-specification process is needed to demonstrate absence of post-hoc selection. We will add an appendix subsection detailing the grid design rationale, the full list of evaluated combinations, and confirmation that no cells were excluded after initial runs. revision: yes
-
Referee: [Abstract (optimization results)] Abstract / attack optimization: the 80-100% flip rate and 48% harmful-output rate are reported on 'refused HarmBench prompts' after optimization, but the manuscript does not specify whether the optimization hyperparameters were tuned on a held-out subset or the full test pool, leaving open the possibility that reported success rates partly reflect overfitting rather than a general token-boundary vulnerability.
Authors: Hyperparameters for the attack optimization were selected via a small development set of 50 prompts drawn from a separate split of HarmBench, with the reported results evaluated only on the remaining held-out test prompts. We will update the methods section and abstract to explicitly state this held-out tuning procedure and report the development-set size to address potential overfitting concerns. revision: yes
Circularity Check
No significant circularity; empirical chain is self-contained
full rationale
The paper presents an end-to-end empirical pipeline: dataset scan for fragmented prompts (30k examples, positive-control recall ≥99%), optimization targeting safety-token fragmentation, first-token refusal flips on HarmBench, activation patching localizing to last ~30% layers, targeted-mutation isolation, and a 68-cell defense grid with SFT/DPO checkpoints. No equations, fitted parameters renamed as predictions, or self-citation chains appear; the absence of fragmented inputs is measured directly rather than assumed by definition, and the SFT result is reported as showing necessity but not sufficiency. All claims are grounded in observable experimental outcomes rather than reducing to their own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- attack optimization hyperparameters
- DPO grid search parameters
axioms (2)
- domain assumption BPE is the tokenization method used by all five tested model families and creates the relevant sub-word fragments
- domain assumption The surveyed alignment datasets are representative of typical safety training distributions
Reference graph
Works this paper leans on
-
[1]
Hughes, R., et al. Best-of- N Jailbreaking. arXiv:2412.03556, 2024
-
[2]
Jailbroken: How Does LLM Safety Training Fail? In NeurIPS, 2023
Wei, A., Haghtalab, N., and Steinhardt, J. Jailbroken: How Does LLM Safety Training Fail? In NeurIPS, 2023
2023
-
[3]
Neural Machine Translation of Rare Words with Subword Units
Sennrich, R., Haddow, B., and Birch, A. Neural Machine Translation of Rare Words with Subword Units. In ACL, 2016
2016
-
[4]
Training language models to follow instructions with human feedback
Ouyang, L., et al. Training language models to follow instructions with human feedback. In NeurIPS, 2022
2022
-
[5]
Direct Preference Optimization
Rafailov, R., et al. Direct Preference Optimization. In NeurIPS, 2023
2023
-
[6]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A., et al. Universal and Transferable Adversarial Attacks on Aligned Language Models. arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Locating and Editing Factual Associations in GPT
Meng, K., Bau, D., Andonian, A., and Belinkov, Y. Locating and Editing Factual Associations in GPT . In NeurIPS, 2023
2023
-
[8]
Refusal in Language Models Is Mediated by a Single Direction
Arditi, A., et al. Refusal in Language Models Is Mediated by a Single Direction. arXiv:2406.11717, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Qi, X., Panda, A., Lyu, K., Ma, X., Roy, S., Beirami, A., Mittal, P., and Henderson, P. Safety Alignment Should Be Made More Than Just a Few Tokens Deep. arXiv:2406.05946, 2024
-
[10]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
Robey, A., et al. SmoothLLM : Defending Large Language Models Against Jailbreaking Attacks. arXiv:2310.03684, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, M., et al. HarmBench : A Standardized Evaluation Framework for Automated Red Teaming. arXiv:2402.04249, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
and Bisk, Y
Belinkov, Y. and Bisk, Y. Synthetic and Natural Noise Both Break Neural Machine Translation. In ICLR, 2018
2018
-
[13]
ByT5 : Towards a Token-Free Future with Pre-trained Byte-to-Byte Models
Xue, L., et al. ByT5 : Towards a Token-Free Future with Pre-trained Byte-to-Byte Models. TACL, 2022
2022
-
[14]
H., et al
Clark, J. H., et al. CANINE : Pre-training an Efficient Tokenization-Free Encoder. TACL, 2022
2022
-
[15]
Charformer: Fast Character Transformers via Gradient-based Subword Tokenization
Tay, Y., et al. Charformer: Fast Character Transformers via Gradient-based Subword Tokenization. In ICLR, 2022
2022
-
[16]
SafeDecoding : Defending against Jailbreak Attacks via Safety-Aware Decoding
Xu, Z., et al. SafeDecoding : Defending against Jailbreak Attacks via Safety-Aware Decoding. In ACL, 2024
2024
-
[17]
Defending Against Unforeseen Failure Modes with Latent Adversarial Training
Casper, S., et al. Defending Against Unforeseen Failure Modes with Latent Adversarial Training. arXiv:2403.05030, 2024
-
[18]
S2C : Split-and-Combine Jailbreak Attacks
Wang, Y., Shi, J., and Qi, Y. S2C : Split-and-Combine Jailbreak Attacks. arXiv:2405.13965, 2024
-
[19]
Tokenization Falling Short: On Subword Robustness in Large Language Models
Chai, Y., Fang, Y., and Peng, Q. Tokenization Falling Short: On Subword Robustness in Large Language Models. arXiv:2406.11687, 2024
-
[20]
Improbable Bigrams Expose Vulnerabilities of Incomplete Tokens in Byte-Level Tokenizers
Jang, E., Lee, K., and Chung, J.-W. Improbable Bigrams Expose Vulnerabilities of Incomplete Tokens in Byte-Level Tokenizers. arXiv:2501.02019, 2025
-
[21]
LBPE : Long-token-first Tokenization to Improve Large Language Models
Lian, H., Xiong, Y., and Lin, Z. LBPE : Long-token-first Tokenization to Improve Large Language Models. arXiv:2404.18553, 2024 a
-
[22]
Scaffold- BPE : Enhancing Byte Pair Encoding with Scaffold Token Removal
Lian, H., Xiong, Y., and Niu, J. Scaffold- BPE : Enhancing Byte Pair Encoding with Scaffold Token Removal. arXiv:2407.15626, 2024 b
-
[23]
LiteToken : Removing Intermediate Merge Residues From BPE Tokenizers
Sun, Y., Yang, H., and Lin, Z. LiteToken : Removing Intermediate Merge Residues From BPE Tokenizers. arXiv, 2026
2026
-
[24]
Papachappa, H. M. Morphological-Core Tokenization. arXiv, 2025
2025
-
[25]
Logit-Gap Steering: A Forward-Pass Diagnostic for Alignment Robustness
Li, T.-L. and Liu, H. Logit-Gap Steering: Efficient Short-Suffix Jailbreaks for Aligned Large Language Models. arXiv:2506.24056, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Asgari, E., El Kheir, Y., and Javaheri, M. A. S. MorphBPE : A Morpho-Aware Tokenizer Bridging Linguistic Complexity for Efficient LLM Training Across Morphologies. arXiv, 2025
2025
-
[27]
Byte BPE Tokenization as an Inverse String Homomorphism
Lian, H., Xiong, Y., and Lin, Z. Byte BPE Tokenization as an Inverse String Homomorphism. arXiv, 2024 c
2024
-
[28]
Defending ChatGPT against Jailbreak Attack via Self-Reminders
Xie, Y., Yi, J., Shao, J., Curl, J., Lyu, L., Chen, Q., Xie, X., and Wu, F. Defending ChatGPT against Jailbreak Attack via Self-Reminders. Nature Machine Intelligence, 5(12):1486--1496, 2023
2023
-
[29]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Inan, H., Upasani, K., Chi, J., Rungta, R., Iyer, K., Mao, Y., Tontchev, M., Hu, Q., Fuller, B., Testuggine, D., and Khabsa, M. Llama Guard : LLM -based Input-Output Safeguard for Human- AI Conversations. arXiv:2312.06674, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.