Prompt Framing Distorts Count-Based Evaluation of LLM Error Detection: Evidence from Numeric Anchoring
Pith reviewed 2026-07-04 01:48 UTC · model grok-4.3
The pith
Numeric anchoring in prompts inflates count-based F1 scores for LLM error detection without improving localization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
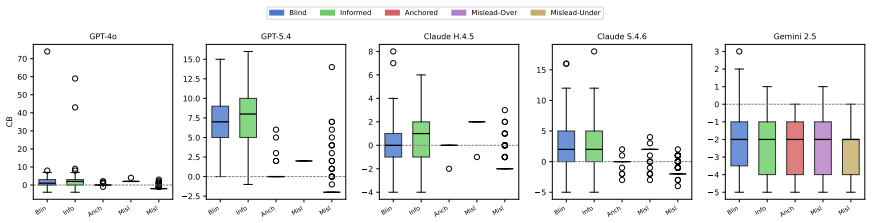
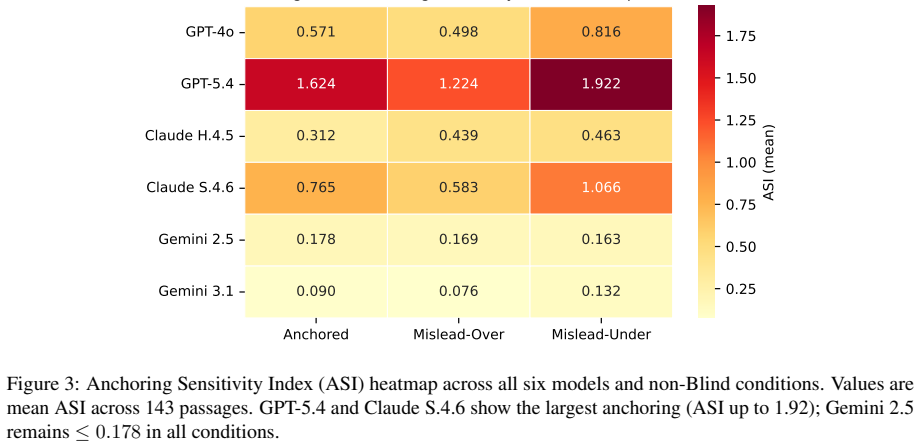
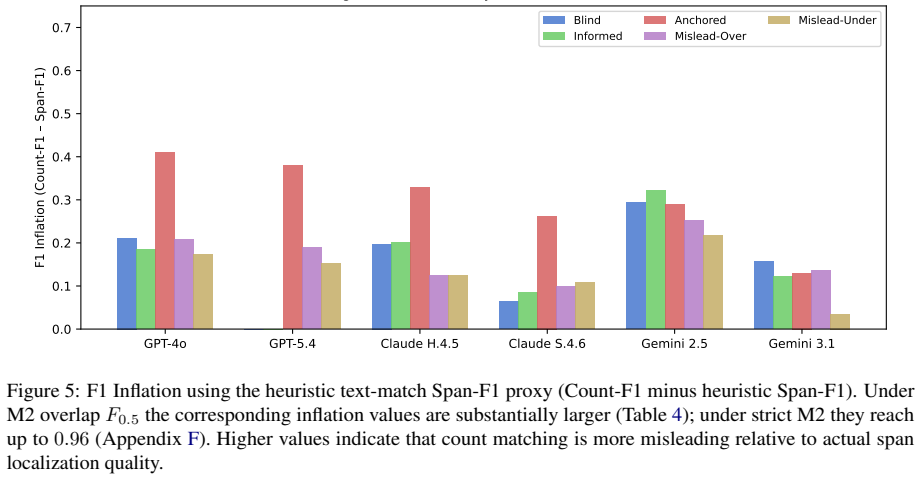
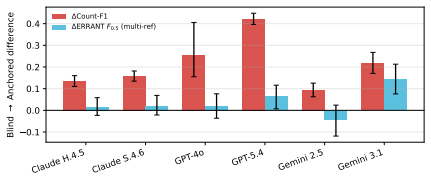
Under CoNLL-2014 M2-style scoring, anchored prompts produce up to 0.79 points of F1 Inflation, and up to 0.96 under strict matching. A 100-passage replication using the official ERRANT 3.0.0 pipeline and multi-reference scoring reproduces the pattern: averaged over six models, the Blind-to-Anchored prompt shift raises Count-F1 by +0.21 while raising multi-reference ERRANT F0.5 by only +0.04. The study finds larger count responses in highly instruction-compliant GPT/Claude systems and smaller responses in the Gemini family under this stress-test protocol.
What carries the argument
Numeric anchoring in prompts that pre-specifies an expected error count, which leads to adjusted model outputs and F1 Inflation between count-based and span-based metrics.
If this is right
- LLM proofreading evaluations should avoid prompts with pre-populated error counts.
- Span-aware metrics should accompany count-based metrics in reports.
- Instruction-compliant models exhibit larger shifts in response counts.
- The inflation pattern holds in replication with multi-reference ERRANT scoring.
- Strict matching reveals higher inflation levels.
Where Pith is reading between the lines
- Evaluations could standardize on blind prompts to avoid this distortion.
- The effect may extend to other LLM tasks involving specified output quantities.
- Benchmark creators should test for sensitivity to numeric suggestions in prompts.
- Applications in document review may vary based on user-specified error expectations.
Load-bearing premise
The F1 score differences are attributable to the numeric anchoring rather than other differences in model behavior or passage selection.
What would settle it
A retest of the protocol where only the presence of the anchored count number varies while all other prompt elements stay fixed, showing no change in the Count-F1 difference.
Figures


read the original abstract
Count-based F1 is widely used as a proxy for LLM error-detection quality, but this paper shows that it can rise dramatically without a corresponding improvement in span localization, a gap termed F1 Inflation. The paper introduces ErrorBench, a controlled stress-test protocol for prompt-induced count distortion. ErrorBench evaluates six contemporary LLMs under five prompt conditions over 4,290 responses from 143 CoNLL-2014 passages. Under CoNLL-2014 M2-style scoring, anchored prompts produce up to 0.79 points of F1 Inflation, and up to 0.96 under strict matching. A 100-passage replication using the official ERRANT 3.0.0 pipeline and multi-reference scoring reproduces the pattern: averaged over six models, the Blind-to-Anchored prompt shift raises Count-F1 by +0.21 while raising multi-reference ERRANT F0.5 by only +0.04. The study finds larger count responses in highly instruction-compliant GPT/Claude systems and smaller responses in the Gemini family under this stress-test protocol. The findings suggest that LLM proofreading and document-review evaluations should avoid pre-populated error counts and should report span-aware metrics alongside count-based metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that count-based F1 metrics for LLM error detection are vulnerable to distortion from numeric anchoring in prompts, producing 'F1 Inflation' (large gains in Count-F1 without corresponding gains in span localization). It introduces the ErrorBench protocol and reports results from six LLMs on 4,290 responses from 143 CoNLL-2014 passages under five prompt conditions. Anchored prompts yield up to 0.79 F1 inflation under M2 scoring (0.96 under strict matching); a 100-passage replication with the official ERRANT 3.0.0 pipeline shows the Blind-to-Anchored shift raises average Count-F1 by +0.21 but multi-reference ERRANT F0.5 by only +0.04. The work concludes that proofreading evaluations should avoid pre-populated error counts and should pair count-based metrics with span-aware ones.
Significance. If the central empirical result holds, the paper identifies a practically important methodological artifact in LLM evaluation for grammatical error detection and document review. The controlled design across multiple models, the use of fixed external datasets, and the replication with the official ERRANT pipeline are strengths that make the finding falsifiable and reproducible. The work supplies concrete evidence that prompt framing can decouple count-based proxies from actual localization quality, which bears directly on how future benchmarks should be constructed.
major comments (2)
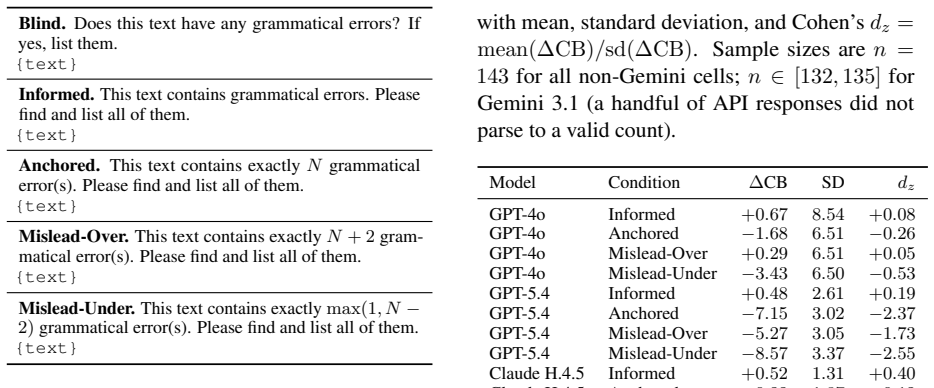
- [Methods / ErrorBench protocol] The central claim requires that the five prompt conditions in ErrorBench differ only in the numeric anchor. The manuscript does not reproduce the exact wording of the five conditions (Methods section or Appendix). Without this, it remains possible that uncontrolled differences in phrasing, length, or compliance cues—not the numeric anchor itself—drive the reported +0.21 Count-F1 versus +0.04 ERRANT F0.5 gap.
- [Results] Table reporting the per-model Count-F1 and ERRANT F0.5 deltas (results section) should include the raw per-passage counts and the exact exclusion rules applied to the 4,290 responses. The current aggregate numbers leave open whether passage selection or response filtering interacts with model family (GPT/Claude vs. Gemini) in ways that amplify the observed inflation.
minor comments (2)
- [Abstract] The abstract states 'up to 0.79 points of F1 Inflation' but does not define the baseline against which inflation is measured; a one-sentence clarification in the abstract would improve readability.
- [Figures] Figure captions for the prompt-condition comparisons should explicitly state the scoring protocol (M2 vs. strict vs. ERRANT) rather than relying on the main text.
Simulated Author's Rebuttal
We thank the referee for these detailed comments on reproducibility and data transparency. Both points identify areas where the manuscript can be strengthened without altering the core findings. We will revise accordingly.
read point-by-point responses
-
Referee: [Methods / ErrorBench protocol] The central claim requires that the five prompt conditions in ErrorBench differ only in the numeric anchor. The manuscript does not reproduce the exact wording of the five conditions (Methods section or Appendix). Without this, it remains possible that uncontrolled differences in phrasing, length, or compliance cues—not the numeric anchor itself—drive the reported +0.21 Count-F1 versus +0.04 ERRANT F0.5 gap.
Authors: We agree that the exact prompt templates must be provided for full reproducibility and to rule out confounding phrasing differences. The five conditions were constructed by holding all non-numeric elements constant and varying only the anchor value (or its absence). In the revised manuscript we will add the complete verbatim prompts to a new Appendix section, along with a table documenting token length and structural equivalence across conditions. This will allow readers to verify that the observed F1 inflation is attributable to the numeric anchor. revision: yes
-
Referee: [Results] Table reporting the per-model Count-F1 and ERRANT F0.5 deltas (results section) should include the raw per-passage counts and the exact exclusion rules applied to the 4,290 responses. The current aggregate numbers leave open whether passage selection or response filtering interacts with model family (GPT/Claude vs. Gemini) in ways that amplify the observed inflation.
Authors: We will expand the results section with a supplementary table that reports, for each model and prompt condition: (i) the raw number of responses before and after filtering, (ii) the exact exclusion criteria (invalid JSON, empty outputs, or responses exceeding token limits), and (iii) per-passage Count-F1 and ERRANT F0.5 values (or at minimum summary statistics stratified by model family). This will make any potential interaction between filtering and model family transparent and allow direct inspection of whether the inflation pattern holds uniformly. revision: yes
Circularity Check
No circularity: empirical measurement study with external benchmarks
full rationale
The paper reports experimental measurements of F1 differences across fixed prompt conditions on CoNLL-2014 data using standard M2 and ERRANT scoring pipelines. No equations, derivations, or first-principles claims appear; the reported inflation values (+0.21 Count-F1 vs +0.04 ERRANT F0.5) are direct outputs of the external evaluation protocol rather than quantities fitted or defined inside the paper. Self-citations are absent from the load-bearing steps, and the design relies on publicly available datasets and scoring code, satisfying the criteria for an independent empirical result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CoNLL-2014 passages and their M2 annotations constitute a valid test distribution for LLM error detection.
Reference graph
Works this paper leans on
-
[1]
Ng, Hwee Tou, Siew Mei Wu, Ted Briscoe, Christian Hadiwinoto, Raymond Hendy Susanto, and Christopher Bryant. 2014. The CoNLL -2014 shared task on grammatical error correction. In Proceedings of the CoNLL Shared Task, pages 1--14
2014
-
[2]
Bryant, Christopher, Mariano Felice, . E. Andersen, and Ted Briscoe. 2019. The BEA -2019 shared task on grammatical error correction. In Proceedings of the 14th Workshop on Innovative Use of NLP for Building Educational Applications, pages 52--75
2019
-
[3]
Bryant, Christopher, Zheng Yuan, Muhammad Reza Qorib, Hannan Cao, Hwee Tou Ng, and Ted Briscoe. 2023. Grammatical error correction: A survey of the state of the art. Computational Linguistics, 49(3):643--701
2023
-
[4]
Bryant, Christopher, Mariano Felice, and Ted Briscoe. 2017. Automatic annotation and evaluation of error types for grammatical error correction. In Proceedings of ACL, pages 793--805
2017
-
[5]
Anthropic. 2025. Claude Haiku 4.5 and Claude Sonnet 4.6 model cards. Technical report. https://www.anthropic.com/
2025
- [6]
-
[7]
Tyser, A., A. Zhukova, Q. Yang, A. Khatun, V. D. Lai, R. Clark, and T. H. Nguyen. 2024. AI -assisted peer review. arXiv preprint arXiv:2402.16754
-
[8]
Fang, Tao, Shu Yang, Kaixin Lan, Derek F. Wong, Jinpeng Hu, Lidia S. Chao, and Yue Zhang. 2023. Is ChatGPT a highly fluent grammatical error correction system? A comprehensive evaluation. arXiv preprint arXiv:2304.01746
-
[9]
Dycke, N., and Iryna Gurevych. 2025. Synthetic counterfactual error insertion for scientific paper review. In Proceedings of EACL 2025
2025
-
[10]
Zhao, Tony Z., Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improving few-shot performance of language models. In Proceedings of ICML, pages 12697--12706
2021
-
[11]
Lu, Yao, Max Bartolo, Alistair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. Fantastically ordered prompts and where to find them. In Proceedings of ACL, pages 8086--8098
2022
-
[12]
Min, Sewon, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. Rethinking the role of demonstrations: What makes in-context learning work? In Proceedings of EMNLP, pages 11048--11064
2022
-
[13]
Perez, Ethan, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing ( EMNLP )
2022
-
[14]
Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R
Sharma, Mrinank, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. 2023. Towards understanding sycophancy in language models. In P...
2023
-
[15]
Tversky, Amos, and Daniel Kahneman. 1974. Judgment under uncertainty: Heuristics and biases. Science, 185(4157):1124--1131
1974
-
[16]
Luchins, Abraham S. 1942. Mechanization in problem solving: The effect of Einstellung . Psychological Monographs, 54(6):1--95
1942
-
[17]
OpenAI. 2024. GPT -4o system card. https://openai.com/
2024
-
[18]
OpenAI. 2025. GPT -5.4 technical report. https://openai.com/
2025
-
[19]
Google DeepMind . 2025. Gemini 2.5 Flash technical report
2025
-
[20]
Epley, Nicholas, and Thomas Gilovich. 2006. The anchoring-and-adjustment heuristic: Why the adjustments are insufficient. Psychological Science, 17(4):311--318
2006
-
[21]
Macmillan-Scott, Olivia, and Mirco Musolesi. 2024. ( Ir )rationality and cognitive biases in large language models. Royal Society Open Science, 11(6):240255. https://doi.org/10.1098/rsos.240255
-
[22]
Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge
Ye, Jiayi, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, Nitesh V. Chawla, and Xiangliang Zhang. 2024. Justice or prejudice? Q uantifying biases in LLM -as-a-judge. arXiv preprint arXiv:2410.02736
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Proceedings of the Eighteenth Conference on Computational Natural Language Learning: Shared Task , year =
Ng, Hwee Tou and Wu, Siew Mei and Briscoe, Ted and Hadiwinoto, Christian and Susanto, Raymond Hendy and Bryant, Christopher , title =. Proceedings of the Eighteenth Conference on Computational Natural Language Learning: Shared Task , year =
-
[24]
Bryant, Christopher and Felice, Mariano and Andersen,. The. Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications , year =
-
[25]
Computational Linguistics , year =
Bryant, Christopher and Yuan, Zheng and Qorib, Muhammad Reza and Cao, Hannan and Ng, Hwee Tou and Briscoe, Ted , title =. Computational Linguistics , year =
-
[26]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
Bryant, Christopher and Felice, Mariano and Briscoe, Ted , title =. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[27]
Claude Haiku 4.5 System Card , year =
-
[28]
Claude Sonnet 4.6 System Card , year =
-
[29]
, title =
Liu, Ryan and Shah, Nihar B. , title =. 2023 , eprint =
2023
-
[30]
and Hu, Jinpeng and Chao, Lidia S
Fang, Tao and Yang, Shu and Lan, Kaixin and Wong, Derek F. and Hu, Jinpeng and Chao, Lidia S. and Zhang, Yue , title =. 2023 , eprint =
2023
-
[31]
Humanities and Social Sciences Communications , year =
Checco, Alessandro and Bracciale, Lorenzo and Loreti, Pierpaolo and Pinfield, Stephen and Bianchi, Giuseppe , title =. Humanities and Social Sciences Communications , year =
-
[32]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
Dycke, Nils and Kuznetsov, Ilia and Gurevych, Iryna , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[33]
Proceedings of the 38th International Conference on Machine Learning , year =
Zhao, Zihao and Wallace, Eric and Feng, Shi and Klein, Dan and Singh, Sameer , title =. Proceedings of the 38th International Conference on Machine Learning , year =
-
[34]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus , title =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[35]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year =
Min, Sewon and Lyu, Xinxi and Holtzman, Ari and Artetxe, Mikel and Lewis, Mike and Hajishirzi, Hannaneh and Zettlemoyer, Luke , title =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year =
2022
-
[36]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year =
Perez, Ethan and Huang, Saffron and Song, Francis and Cai, Trevor and Ring, Roman and Aslanides, John and Glaese, Amelia and McAleese, Nat and Irving, Geoffrey , title =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year =
2022
-
[37]
and Durmus, Esin and Hatfield-Dodds, Zac and Johnston, Scott R
Sharma, Mrinank and Tong, Meg and Korbak, Tomasz and Duvenaud, David and Askell, Amanda and Bowman, Samuel R. and Durmus, Esin and Hatfield-Dodds, Zac and Johnston, Scott R. and Kravec, Shauna M. and Maxwell, Timothy and McCandlish, Sam and Ndousse, Kamal and Rausch, Oliver and Schiefer, Nicholas and Yan, Da and Zhang, Miranda and Perez, Ethan , title =. ...
-
[38]
Science , year =
Tversky, Amos and Kahneman, Daniel , title =. Science , year =
-
[39]
, title =
Luchins, Abraham S. , title =. Psychological Monographs , year =
-
[40]
2024 , howpublished =
2024
-
[41]
2026 , howpublished =
2026
-
[42]
Gemini 2.5 Flash , year =
-
[43]
Psychological Science , year =
Epley, Nicholas and Gilovich, Thomas , title =. Psychological Science , year =
-
[44]
Royal Society Open Science , year =
Macmillan-Scott, Olivia and Musolesi, Mirco , title =. Royal Society Open Science , year =
-
[45]
and Zhang, Xiangliang , title =
Ye, Jiayi and Wang, Yanbo and Huang, Yue and Chen, Dongping and Zhang, Qihui and Moniz, Nuno and Gao, Tian and Geyer, Werner and Huang, Chao and Chen, Pin-Yu and Chawla, Nitesh V. and Zhang, Xiangliang , title =. 2024 , eprint =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.