LLMs as Teaching Assistants for Mathematics Exam Grading: Reliability, and Practical Usability
Pith reviewed 2026-07-04 00:40 UTC · model grok-4.3
The pith
Liberal partial-credit prompts reduce question-level grading errors for every LLM tested on math exams.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
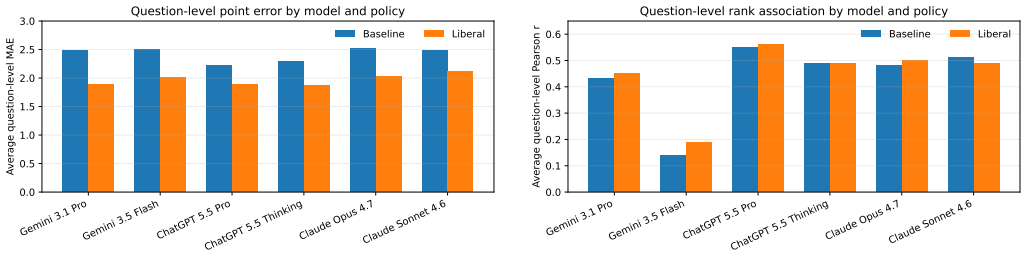
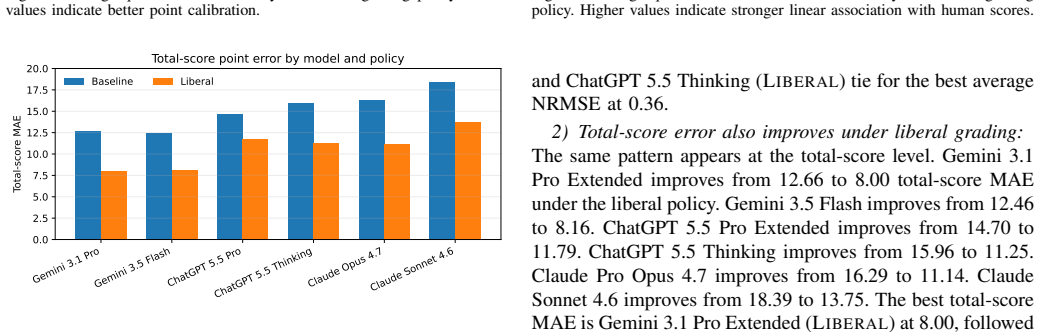
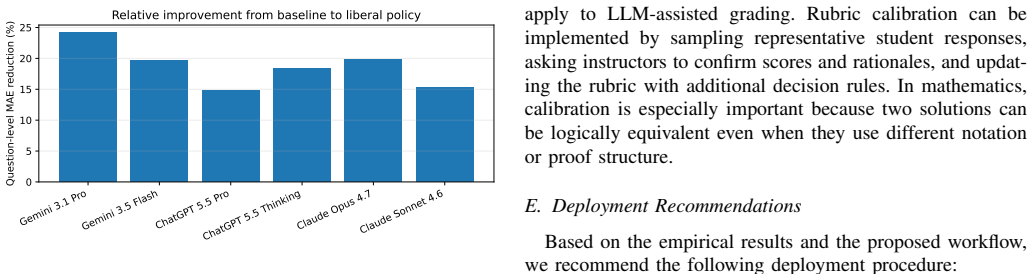
The central claim is that adopting a liberal partial-credit prompting policy reduces average question-level error relative to a baseline strict-rubric policy for every one of the six LLM configurations evaluated. ChatGPT 5.5 Thinking under the liberal policy records the lowest question-level MAE of 1.87 and RMSE of 2.53; Gemini 3.1 Pro Extended under the liberal policy records the lowest total-score MAE of 8.00 and RMSE of 10.66. The highest total-score Pearson correlation of 0.58 occurs under the baseline policy for Gemini 3.1 Pro Extended, showing that minimizing absolute deviation and preserving student rank order are distinct objectives.
What carries the argument
The LIBERAL versus BASELINE prompting policies, where the liberal version relaxes demands for complete explicit evidence to recognize valid partial reasoning.
If this is right
- Liberal partial-credit prompting reduces average question-level error for every evaluated model family.
- ChatGPT 5.5 Thinking (LIBERAL) achieves the lowest question-level MAE of 1.87 and RMSE of 2.53.
- Gemini 3.1 Pro Extended (LIBERAL) achieves the lowest total-score MAE of 8.00 and RMSE of 10.66.
- Gemini 3.1 Pro Extended (BASELINE) produces the strongest total-score Pearson correlation of 0.58, separating absolute accuracy from rank preservation.
- Quantitative agreement metrics are accompanied by practical usability observations for classroom use.
Where Pith is reading between the lines
- Instructors could combine LLM initial scores with targeted human review for the subset of answers where models still diverge most from expected standards.
- The observed separation between point accuracy and correlation suggests that grading policies might need to be chosen according to whether the goal is absolute fairness or relative ranking.
- Error reductions achieved here could be tested on exams from other mathematics courses to check whether the liberal-prompt benefit generalizes beyond discrete mathematics.
- Wider adoption might shift instructor effort from initial scoring toward writing richer feedback on conceptual misconceptions.
Load-bearing premise
Human-assigned grades are treated as the authoritative ground truth without reported statistics on consistency among multiple human graders.
What would settle it
Re-grade the same exams independently with several human graders, then compare the typical disagreement among the humans against the typical disagreement between each LLM and a single human grader.
Figures

read the original abstract
Open-ended mathematics exams are valuable because they assess reasoning, proof construction, algorithmic thinking, and communication of intermediate steps. They are also difficult to grade at scale because instructors must apply partial-credit rubrics consistently while giving feedback that helps students repair misconceptions. This paper evaluates six contemporary large language model (LLM) configurations, Gemini 3.1 Pro Extended, Gemini 3.5 Flash, ChatGPT 5.5 Pro Extended, ChatGPT 5.5 Thinking, Claude Pro Opus 4.7, and Claude Sonnet 4.6, as grading assistants for an undergraduate discrete mathematics examination. The study compares two grading policies. The BASELINE policy uses a stricter rubric-following prompt that emphasizes explicit evidence and complete justification. The LIBERAL policy was added after preliminary grading showed that the baseline condition sometimes applied harsh point deductions and failed to recognize valid partial reasoning. Agreement with human grading is measured at both the question and exam-total levels using mean absolute error, root mean squared error, normalized root mean squared error, Pearson correlation, and exact agreement. The results show that liberal partial-credit prompting reduces average question-level error for every evaluated model family. ChatGPT 5.5 Thinking (LIBERAL) has the lowest average question-level MAE (1.87) and RMSE (2.53), while Gemini 3.1 Pro Extended (LIBERAL) has the lowest total-score MAE (8.00) and RMSE (10.66). However, the strongest total-score Pearson correlation occurs under Gemini 3.1 Pro Extended (BASELINE) at 0.58, showing that point calibration and rank preservation remain distinct goals. We also report practical usability observations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates six LLM configurations (Gemini 3.1 Pro Extended, Gemini 3.5 Flash, ChatGPT 5.5 Pro Extended, ChatGPT 5.5 Thinking, Claude Pro Opus 4.7, Claude Sonnet 4.6) as grading assistants for an undergraduate discrete mathematics exam. It compares BASELINE (strict rubric) and LIBERAL (partial-credit) prompting policies, reporting agreement with human grades via MAE, RMSE, NRMSE, Pearson correlation, and exact agreement at question and total-score levels. The central result is that LIBERAL prompting reduces average question-level error for every model family, with ChatGPT 5.5 Thinking (LIBERAL) achieving the lowest question-level MAE (1.87) and RMSE (2.53), and Gemini 3.1 Pro Extended (LIBERAL) the lowest total-score MAE (8.00) and RMSE (10.66); the highest total-score Pearson correlation is 0.58 under Gemini 3.1 Pro Extended (BASELINE). Practical usability observations are also reported.
Significance. If the results hold, the work offers actionable evidence that liberal partial-credit prompting improves LLM grading consistency across model families on open-ended math exams, with a useful distinction between calibration (MAE/RMSE) and rank preservation (Pearson). This could inform prompt design for educational AI tools. The empirical comparison using standard metrics is a strength, but the significance is limited by the absence of details needed to interpret the human ground truth.
major comments (2)
- [Abstract] Abstract (and results paragraph on agreement metrics): The central claim that LIBERAL prompting reduces question-level MAE/RMSE for every model family, with specific winners at MAE 1.87 etc., rests on treating human-assigned grades as authoritative ground truth. No information is provided on the number of independent human graders, inter-rater reliability (ICC, kappa, or pairwise agreement), or score reconciliation procedure. In discrete-math grading with partial credit for reasoning, grader variability is expected; without quantifying it, the reported error reductions cannot be distinguished from alignment to idiosyncratic human judgments.
- [Abstract] Abstract: No sample size, number of exam questions, or statistical tests (e.g., paired t-tests or confidence intervals on the MAE/RMSE differences) are reported for the claim that LIBERAL reduces error for every model family. This leaves the numerical improvements only partially verifiable and undermines assessment of whether the reductions are robust or practically meaningful.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback emphasizing the need for transparency on human grading procedures and statistical support for the reported improvements. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and results paragraph on agreement metrics): The central claim that LIBERAL prompting reduces question-level MAE/RMSE for every model family, with specific winners at MAE 1.87 etc., rests on treating human-assigned grades as authoritative ground truth. No information is provided on the number of independent human graders, inter-rater reliability (ICC, kappa, or pairwise agreement), or score reconciliation procedure. In discrete-math grading with partial credit for reasoning, grader variability is expected; without quantifying it, the reported error reductions cannot be distinguished from alignment to idiosyncratic human judgments.
Authors: We agree that the absence of details on the human grading process limits interpretation of the results. The grading was performed by a single course instructor using a pre-defined rubric; no multiple independent graders or reconciliation procedure were employed. As a result, inter-rater reliability metrics cannot be computed. We will revise the manuscript to describe the grading procedure explicitly and to discuss this as a limitation, noting that some observed agreement may reflect alignment with the specific instructor's judgments. revision: partial
-
Referee: [Abstract] Abstract: No sample size, number of exam questions, or statistical tests (e.g., paired t-tests or confidence intervals on the MAE/RMSE differences) are reported for the claim that LIBERAL reduces error for every model family. This leaves the numerical improvements only partially verifiable and undermines assessment of whether the reductions are robust or practically meaningful.
Authors: We will revise the abstract and results sections to report the sample size and number of exam questions, and to include statistical tests (such as paired t-tests) along with confidence intervals on the MAE/RMSE differences between BASELINE and LIBERAL conditions. This will allow readers to assess the robustness of the observed error reductions. revision: yes
- Inter-rater reliability cannot be reported because the study used grading by a single human instructor.
Circularity Check
No circularity; direct empirical comparison to external human grades
full rationale
The paper reports an empirical evaluation of LLM grading performance against human-assigned scores on a discrete mathematics exam, using standard error metrics (MAE, RMSE, Pearson correlation) at question and total-score levels. No derivation chain, equations, fitted parameters, or self-referential constructions appear in the abstract or described methods. Claims about LIBERAL vs BASELINE prompting rest on direct numerical comparisons to an external benchmark (human grades), not on quantities defined in terms of themselves or on self-citations. The work is self-contained against that external reference and exhibits none of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human grading constitutes a reliable and consistent ground truth for measuring LLM performance.
- domain assumption The chosen undergraduate discrete mathematics exam is representative of open-ended math assessments in general.
Reference graph
Works this paper leans on
-
[1]
Towards llm-based autograd- ing for short textual answers,
J. Schneider, B. Schenk, and C. Niklaus, “Towards llm-based autograd- ing for short textual answers,”arXiv preprint arXiv:2309.11508, 2023
-
[2]
Using large language models for automated grading of student writing about science,
C. Impey, M. Wenger, N. Garuda, S. Golchin, and S. Stamer, “Using large language models for automated grading of student writing about science,”International Journal of Artificial Intelligence in Education, vol. 35, no. 4, pp. 1825–1859, 2025
2025
-
[3]
College exam grader using llm ai mod- els,
J. X. Lee and Y .-T. Song, “College exam grader using llm ai mod- els,” in2024 IEEE/ACIS 27th International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD). IEEE, 2024, pp. 282–289
2024
-
[4]
Automating autograding: Large language models as test suite generators for introductory pro- gramming,
U. Alkafaween, I. Albluwi, and P. Denny, “Automating autograding: Large language models as test suite generators for introductory pro- gramming,”Journal of Computer Assisted Learning, vol. 41, no. 1, p. e13100, 2025
2025
-
[5]
Automated grading approach for open-ended stem answers using llm,
P. Satcharattanachot and S. Usanavasin, “Automated grading approach for open-ended stem answers using llm,” in2025 20th International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP). IEEE, 2025, pp. 1–6
2025
-
[6]
Automated feedback in math education: A com- parative analysis of llms for open-ended responses,
S. Baral, E. Worden, W.-C. Lim, Z. Luo, C. Santorelli, A. Gurung, and N. Heffernan, “Automated feedback in math education: A com- parative analysis of llms for open-ended responses,”arXiv preprint arXiv:2411.08910, 2024
-
[7]
Personalized auto-grading and feedback system for constructive geometry tasks using large language models on an online math platform,
Y . O. Lee, B. Bang, J. Lee, and S. Oh, “Personalized auto-grading and feedback system for constructive geometry tasks using large language models on an online math platform,”IEEE Access, 2026
2026
-
[8]
Automatic short answer grading in the llm era: Does gpt-4 with prompt engineering beat traditional models?
R. Ferreira Mello, C. Pereira Junior, L. Rodrigues, F. D. Pereira, L. Cabral, N. Costa, G. Ramalho, and D. Gasevic, “Automatic short answer grading in the llm era: Does gpt-4 with prompt engineering beat traditional models?” inProceedings of the 15th international learning analytics and knowledge conference, 2025, pp. 93–103
2025
-
[9]
Large language models for education: A survey and outlook,
S. Wang, T. Xu, H. Li, C. Zhang, J. Liang, J. Tang, P. S. Yu, and Q. Wen, “Large language models for education: A survey and outlook,” IEEE Signal Processing Magazine, vol. 42, no. 6, pp. 51–63, 2026
2026
-
[10]
LLM agents for education: Advances and applications,
Z. Chu, S. Wang, J. Xie, T. Zhu, Y . Yan, J. Ye, A. Zhong, X. Hu, J. Liang, P. S. Yuet al., “Llm agents for education: Advances and applications,” arXiv preprint arXiv:2503.11733, vol. 2, 2025
-
[11]
A llm-powered automatic grading framework with human-level guidelines optimization,
Y . Chu, H. Li, K. Yang, H. Shomer, H. Liu, Y . Copur-Gencturk, and J. Tang, “A llm-powered automatic grading framework with human-level guidelines optimization,”arXiv preprint arXiv:2410.02165, 2024
-
[12]
Llm-based automated grading with human-in-the-loop,
Y . Chu, H. Li, K. Yang, Y . Copur-Gencturk, and J. Tang, “Llm-based automated grading with human-in-the-loop,” in2025 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE). IEEE, 2025, pp. 1–8
2025
-
[13]
Grade like a human: Rethinking automated assessment with large language models,
W. Xie, J. Niu, C. J. Xue, and N. Guan, “Grade like a human: Rethinking automated assessment with large language models,” inProceedings of the International Conference on Research in Adaptive and Convergent Systems, 2025, pp. 1–8
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.