BIFROST: Bridging Invariant Feature Representation for Observation-space Sim2Real Transfer
Pith reviewed 2026-07-03 20:06 UTC · model grok-4.3
The pith
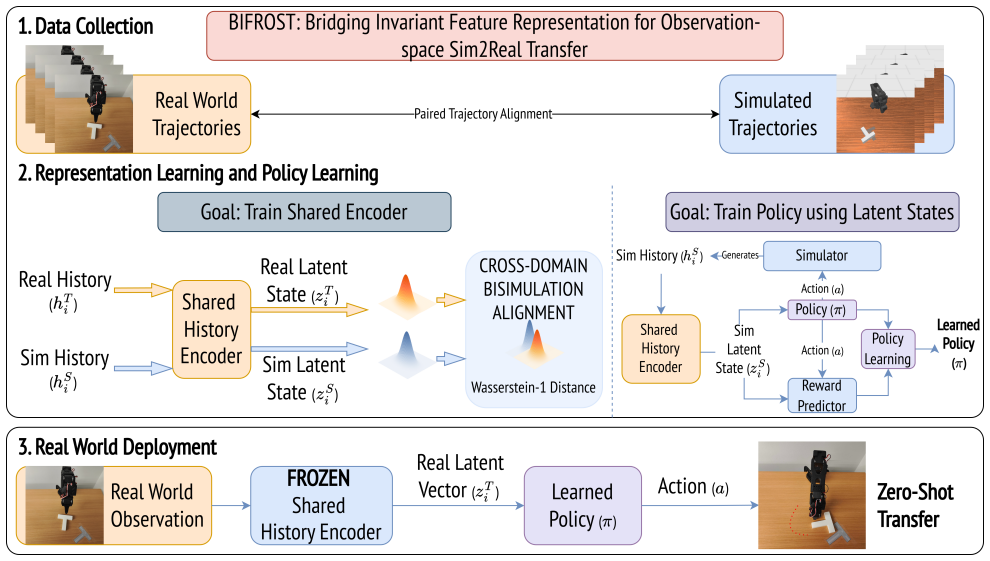
BIFROST learns a shared encoder that maps paired sim and real observation sequences to the same latent states when they lead to equivalent behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BIFROST trains a shared history encoder on paired cross-domain observation-action sequences using a cross-domain bisimulation objective. Sequences that produce equivalent long-term outcomes are encoded to nearby latent states irrespective of domain-specific rendering or physics. Robot policies trained in simulation using these latent states then transfer directly to the real world without further adaptation.
What carries the argument
The cross-domain bisimulation objective, which pulls latent states of behaviorally equivalent observation-action sequences closer together across domains.
Load-bearing premise
Paired sequences of observations and actions from simulation and reality that lead to the same long-term outcomes must be available to train the encoder.
What would settle it
A demonstration that latent states for equivalent behavior sequences remain distant across domains, or that policies trained on the latents fail to transfer despite using the paired data.
Figures

read the original abstract
Sim2real transfer for robot policy learning suffers due to mismatch between simulation and reality. Existing methods typically address each gap in isolation through separate adaptation modules, which are composed or layered when both gaps coexist. Yet the basis for attempting sim2real in the first place is that there is shared structure between a task in simulation and reality, where equivalent actions from equivalent configurations produce equivalent long term outcomes regardless of domain specific differences in rendering or physics. In this paper, we study whether we can identify and exploit this shared structure from raw observations to train a policy that enables zero shot transfer. We introduce BIFROST, which learns a shared history encoder on paired cross-domain data via cross-domain bisimulation objective: observation-action sequences leading to equivalent long-term behavior are mapped to nearby latent states, regardless of domain. Policies trained on these latent states in simulation transfer zero-shot to reality. We provide empirical evidence on sim2sim visual navigation and sim2real contact rich manipulation task and visual servoing task that BIFROST achieves effective transfer where domain adaptation and co-training baselines fail under both visual and dynamics domain gaps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BIFROST, a method that learns a shared history encoder via a cross-domain bisimulation objective on paired observation-action sequences from simulation and reality that lead to equivalent long-term behavior. Observation-action sequences are mapped to nearby latent states regardless of domain-specific differences in rendering or physics. Policies are trained on these latent states in simulation and transferred zero-shot to reality. The abstract claims empirical evidence on sim2sim visual navigation, sim2real contact-rich manipulation, and visual servoing tasks showing effective transfer where domain adaptation and co-training baselines fail under visual and dynamics domain gaps.
Significance. If the results hold with the required paired data, the work would offer a unified approach to sim2real transfer that exploits shared task structure directly from raw observations rather than composing separate adaptation modules for visual and dynamics gaps. The bisimulation-based invariance is a conceptual strength for identifying equivalent long-term behavior across domains.
major comments (2)
- [Abstract] Abstract: The abstract asserts empirical success and effective transfer on three tasks where baselines fail, but provides no quantitative results, error bars, dataset sizes, ablation studies, or performance metrics. This prevents verification of the central zero-shot transfer claim.
- [Method] Method (cross-domain bisimulation objective): The approach presupposes the availability of paired cross-domain observation-action sequences that are correctly labeled for equivalent long-term behavior despite visual and dynamics gaps. The paper must detail how such pairings are obtained in practice (e.g., without privileged state access or exhaustive real-world rollouts), as this assumption is load-bearing for the bisimulation loss to produce a reliable invariant representation rather than collapsing to domain-specific features.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the manuscript's content and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts empirical success and effective transfer on three tasks where baselines fail, but provides no quantitative results, error bars, dataset sizes, ablation studies, or performance metrics. This prevents verification of the central zero-shot transfer claim.
Authors: The abstract is intended as a high-level summary of the approach and claims. Detailed quantitative results, including metrics, error bars from repeated trials, dataset sizes, and ablation studies, appear in Sections 4 and 5. We agree that incorporating a few key numbers would make the abstract more self-contained and will revise it accordingly in the next version. revision: yes
-
Referee: [Method] Method (cross-domain bisimulation objective): The approach presupposes the availability of paired cross-domain observation-action sequences that are correctly labeled for equivalent long-term behavior despite visual and dynamics gaps. The paper must detail how such pairings are obtained in practice (e.g., without privileged state access or exhaustive real-world rollouts), as this assumption is load-bearing for the bisimulation loss to produce a reliable invariant representation rather than collapsing to domain-specific features.
Authors: The current manuscript describes the bisimulation objective on paired sequences but does not provide an explicit protocol for obtaining the pairings. We will add a dedicated subsection in the method section that specifies the data-collection procedure used for each task (navigation, manipulation, servoing), confirming that pairings are generated from task rollouts without privileged state information. revision: yes
Circularity Check
No circularity; empirical method with explicit paired-data inputs
full rationale
The paper presents BIFROST as an empirical training procedure that consumes paired cross-domain observation-action sequences (assumed to share long-term equivalence) and applies a bisimulation loss to produce latent states for policy training. No derivation, equation, or central claim reduces by construction to its own fitted outputs or to a self-citation chain. The availability of correctly labeled pairs is stated as an input assumption rather than derived from the method itself. This matches the default case of a self-contained empirical approach with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption There exists shared structure between simulation and reality such that equivalent actions from equivalent configurations produce equivalent long-term outcomes regardless of domain-specific differences.
Reference graph
Works this paper leans on
-
[1]
Domain randomization for transferring deep neural networks from simulation to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” in2017 IEEE/RSJ international con- ference on intelligent robots and systems (IROS). IEEE, 2017, pp. 23–30
work page 2017
-
[2]
Sim-to- real transfer of robotic control with dynamics randomization,
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel, “Sim-to- real transfer of robotic control with dynamics randomization,” in2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 3803–3810
work page 2018
-
[3]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on robot learning. PMLR, 2022, pp. 91–100
work page 2022
-
[4]
Sim-to-real transfer in deep reinforcement learning for robotics: a survey,
W. Zhao, J. P. Queralta, and T. Westerlund, “Sim-to-real transfer in deep reinforcement learning for robotics: a survey,” in2020 IEEE symposium series on computational intelligence (SSCI). IEEE, 2020, pp. 737–744
work page 2020
-
[5]
Preparing for the unknown: Learning a universal policy with online system identification,
W. Yu, J. Tan, C. K. Liu, and G. Turk, “Preparing for the unknown: Learning a universal policy with online system identification,” in Proceedings of Robotics: Science and Systems (RSS), 2017
work page 2017
-
[6]
Closing the sim-to-real loop: Adapting simula- tion randomization with real world experience,
Y . Chebotar, A. Handa, V . Makoviychuk, M. Macklin, J. Issac, N. Ratliff, and D. Fox, “Closing the sim-to-real loop: Adapting simula- tion randomization with real world experience,” in2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 8973–8979
work page 2019
-
[7]
Retinagan: An object-aware approach to sim-to-real transfer,
D. Ho, K. Rao, Z. Xu, E. Jang, M. Khansari, and Y . Bai, “Retinagan: An object-aware approach to sim-to-real transfer,” in2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 10 920–10 926
work page 2021
-
[8]
Bi-directional domain adap- tation for sim2real transfer of embodied navigation agents,
J. Truong, S. Chernova, and D. Batra, “Bi-directional domain adap- tation for sim2real transfer of embodied navigation agents,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 2634–2641, 2021
work page 2021
-
[9]
FLAMBE: Structural complexity and representation learning of low rank MDPs,
A. Agarwal, S. M. Kakade, A. Krishnamurthy, and W. Sun, “FLAMBE: Structural complexity and representation learning of low rank MDPs,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 20 095–20 107
work page 2020
-
[10]
Provable benefit of multitask representation learning in reinforcement learning,
Y . Cheng, S. Feng, J. Yang, H. Zhang, and Y . Liang, “Provable benefit of multitask representation learning in reinforcement learning,” Advances in Neural Information Processing Systems, vol. 35, pp. 31 741–31 754, 2022
work page 2022
-
[11]
Z. Tao, W. Xu, and X. You, “A generalized bisimulation metric of state similarity between markov decision processes: From theoretical propositions to applications,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=XR30K9zxFm
work page 2025
-
[12]
Learning invariant representations for reinforcement learning without recon- struction,
A. Zhang, R. McAllister, R. Calandra, Y . Gal, and S. Levine, “Learning invariant representations for reinforcement learning without recon- struction,” inInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[13]
Mico: Im- proved representations via sampling-based state similarity for markov decision processes,
P. S. Castro, T. Kastner, P. Panangaden, and M. Rowland, “Mico: Im- proved representations via sampling-based state similarity for markov decision processes,”Advances in Neural Information Processing Sys- tems, vol. 34, pp. 30 113–30 126, 2021
work page 2021
-
[14]
Learning agile and dynamic motor skills for legged robots,
J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V . Tsounis, V . Koltun, and M. Hutter, “Learning agile and dynamic motor skills for legged robots,”Science Robotics, vol. 4, no. 26, p. eaau5872, 2019
work page 2019
-
[15]
Cad2rl: Real single-image flight without a single real image,
F. Sadeghi and S. Levine, “Cad2rl: Real single-image flight without a single real image,” inProceedings of Robotics: Science and Systems (RSS), 2017
work page 2017
-
[16]
Learning dexterous in-hand manipulation,
O. M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. Mc- Grew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Rayet al., “Learning dexterous in-hand manipulation,”The International Journal of Robotics Research, vol. 39, no. 1, pp. 3–20, 2020
work page 2020
-
[17]
Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control,
Z. Li, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath, “Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control,”The International Journal of Robotics Research, vol. 44, no. 5, pp. 840–888, 2025
work page 2025
-
[18]
Asymmetric actor critic for image-based robot learning,
L. Pinto, M. Andrychowicz, P. Welinder, W. Zaremba, and P. Abbeel, “Asymmetric actor critic for image-based robot learning,” inProceed- ings of Robotics: Science and Systems (RSS), 2018
work page 2018
-
[19]
Learning quadrupedal locomotion over challenging terrain,
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning quadrupedal locomotion over challenging terrain,”Science robotics, vol. 5, no. 47, p. eabc5986, 2020
work page 2020
-
[20]
Learning robust perceptive locomotion for quadrupedal robots in the wild,
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning robust perceptive locomotion for quadrupedal robots in the wild,”Science robotics, vol. 7, no. 62, p. eabk2822, 2022
work page 2022
-
[21]
Metrics for finite markov decision processes
N. Ferns, P. Panangaden, and D. Precup, “Metrics for finite markov decision processes.” inUAI, vol. 4, 2004, pp. 162–169
work page 2004
-
[22]
Bisimulation metrics for continuous markov decision pro- cesses,
——, “Bisimulation metrics for continuous markov decision pro- cesses,”SIAM Journal on Computing, vol. 40, no. 6, pp. 1662–1714, 2011
work page 2011
-
[23]
J. Subramanian, A. Sinha, R. Seraj, and A. Mahajan, “Approximate information state for approximate planning and reinforcement learning in partially observed systems,”Journal of Machine Learning Research, vol. 23, no. 12, pp. 1–83, 2022
work page 2022
-
[24]
SMDP homomorphisms: An algebraic approach to abstraction in semi-Markov decision processes,
B. Ravindran and A. G. Barto, “SMDP homomorphisms: An algebraic approach to abstraction in semi-Markov decision processes,” inIJCAI, 2003, pp. 1011–1016
work page 2003
-
[25]
Continuous MDP homomorphisms and homomorphic policy gradi- ent,
S. Rezaei-Shoshtari, R. Zhao, P. Panangaden, D. Meger, and D. Precup, “Continuous MDP homomorphisms and homomorphic policy gradi- ent,” inNeurIPS, 2022, pp. 20 189–20 204
work page 2022
-
[26]
Using bisimulation for policy transfer in MDPs,
P. S. Castro and D. Precup, “Using bisimulation for policy transfer in MDPs,” inAAAI, 2010, pp. 1065–1070
work page 2010
-
[27]
Cross-domain imitation learning via optimal transport,
A. Fickinger, S. Cohen, S. Russell, and B. Amos, “Cross-domain imitation learning via optimal transport,” inInternational Conference on Learning Representations (ICLR), 2022
work page 2022
-
[28]
Sample complexity of multi-task reinforce- ment learning,
E. Brunskill and L. Li, “Sample complexity of multi-task reinforce- ment learning,” inProceedings of the Twenty-Ninth Conference on Uncertainty in Artificial Intelligence (UAI), 2013
work page 2013
-
[29]
Sim-and-real co-training: A simple recipe for vision-based robotic manipulation,
A. Maddukuri, Z. Jiang, L. Y . Chen, S. Nasiriany, Y . Xie, Y . Fang, W. Huang, Z. Wang, Z. Xu, N. Chernyadev, S. Reed, K. Goldberg, A. Mandlekar, L. Fan, and Y . Zhu, “Sim-and-real co-training: A simple recipe for vision-based robotic manipulation,” inProceedings of Robotics: Science and Systems (RSS), 2025
work page 2025
-
[30]
Empirical analysis of sim-and-real cotraining of diffusion policies for planar pushing from pixels,
A. Weiet al., “Empirical analysis of sim-and-real cotraining of diffusion policies for planar pushing from pixels,”arXiv preprint arXiv:2503.22634, 2025
-
[31]
Villaniet al.,Optimal transport: old and new
C. Villaniet al.,Optimal transport: old and new. Springer, 2008, vol. 338
work page 2008
-
[32]
Rma: Rapid motor adaptation for legged robots,
A. Kumar, Z. Fu, D. Pathak, and J. Malik, “Rma: Rapid motor adaptation for legged robots,” inProceedings of Robotics: Science and Systems (RSS), 2021
work page 2021
-
[33]
Offline reinforcement learning with implicit q-learning,
I. Kostrikov, A. Nair, and S. Levine, “Offline reinforcement learning with implicit q-learning,” inInternational Conference on Learning Representations (ICLR), 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.