Hamm-Grams: An Algorithm for Mining Regular Expressions of Bytes
Pith reviewed 2026-07-03 19:58 UTC · model grok-4.3
The pith
Hamm-grams mined via locality-sensitive hashing and clustering produce more robust byte features than n-grams for malware classification and detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hamm-grams are a special class of regular expressions consisting of fixed-length byte sequences with exactly one single-character wildcard. They are mined by first using a new locality-sensitive hash designed to produce collisions among pairs with small Hamming distance, followed by clustering within each hash bucket to place the wildcard at the position of greatest variation. The paper states that these features are more robust than n-grams and yield better results in malware classification and detection tasks.
What carries the argument
The hamm-gram mining algorithm that applies locality-sensitive hashing tuned for small Hamming distance followed by intra-bucket clustering to insert wildcards.
If this is right
- Hamm-grams reduce the brittleness of static byte features to small mutations typical in malware variants.
- The LSH-plus-clustering procedure mines useful patterns more efficiently than exhaustive search over all possible wildcard placements.
- Regular-expression-style features with single wildcards capture structural similarities that exact n-grams miss.
- The same mining pipeline can be applied to any large corpus of byte sequences where small variations are expected.
Where Pith is reading between the lines
- If the method works, similar wildcard patterns could be tested on other noisy sequence domains such as network traffic or file-format parsing.
- Performance will depend on how frequency and utility thresholds are chosen in practice, since the abstract does not specify explicit cutoffs.
Load-bearing premise
The locality-sensitive hash and subsequent clustering step will reliably surface hamm-grams that are both frequent enough to be useful and sufficiently discriminative for malware tasks.
What would settle it
A head-to-head experiment on the same malware datasets where standard n-gram features achieve equal or higher classification accuracy than hamm-grams would falsify the claimed advantage.
Figures

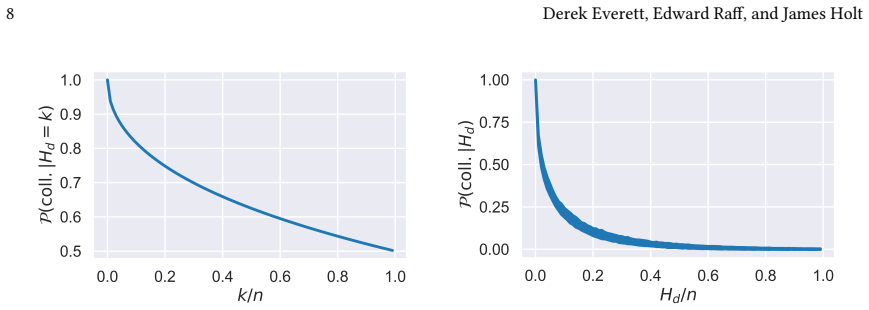
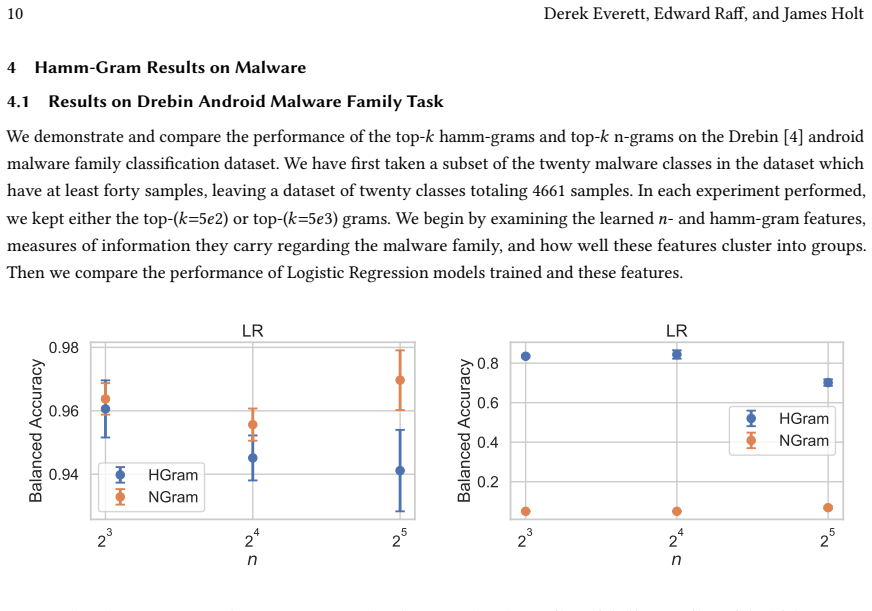
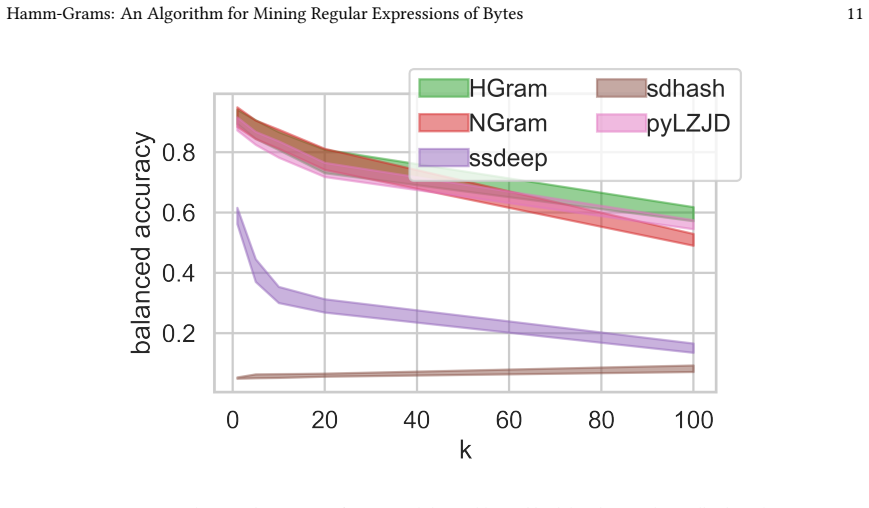
read the original abstract
Malware poses a critical and ever-evolving threat, and robust and effective systems for detecting and classifying malware are of essential importance. $n$-grams features are among the common static features used in effective machine learning systems for malware, but these features are inherently brittle. We propose an algorithm for constructing more robust features, hamm-grams, which are a special class of regular expressions having a fixed length and single-character wildcards. We devise an efficient algorithm for finding common hamm-grams using a new locality-sensitive hash designed to produce collisions among pairs of small Hamming distance and a clustering within hash buckets to place wildcards. We then demonstrate the advantages of these features in malware classification and detection tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces hamm-grams, a class of fixed-length regular expressions over bytes that allow single-character wildcards. These are mined via a locality-sensitive hash (LSH) designed to collide on small Hamming distances, followed by intra-bucket clustering to determine wildcard positions. The central claim is that the resulting hamm-grams yield more robust features than conventional n-grams for malware classification and detection.
Significance. If the LSH-plus-clustering procedure can be shown to produce reproducible, discriminative hamm-grams that demonstrably improve robustness under realistic dataset shift, the work would supply a practical alternative to brittle n-gram features in static malware analysis pipelines.
major comments (2)
- [Mining algorithm description] Mining algorithm section: no concrete selection rule (support threshold, entropy cutoff, cross-validation score, or coverage criterion) is stated for deciding which candidate hamm-grams survive to the final feature set after LSH and clustering. Without such a rule the claimed robustness advantage cannot be reproduced and may depend on post-hoc choices rather than the LSH construction itself.
- [Experimental section] Experimental evaluation: the manuscript provides no description of how robustness is quantified or how controls for dataset shift (temporal splits, family-wise cross-validation, or adversarial variants) are implemented. This omission is load-bearing for the central claim that hamm-grams outperform n-grams in robustness.
minor comments (2)
- [Abstract] Abstract: the phrase 'demonstrate the advantages' is vague; the specific tasks, datasets, and metrics should be named.
- [Introduction / Preliminaries] Notation: an early concrete example of a hamm-gram (e.g., the byte pattern with wildcard positions) would clarify the definition before the algorithmic description.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The two major comments identify important omissions that affect reproducibility. We will revise the manuscript to address both points explicitly.
read point-by-point responses
-
Referee: [Mining algorithm description] Mining algorithm section: no concrete selection rule (support threshold, entropy cutoff, cross-validation score, or coverage criterion) is stated for deciding which candidate hamm-grams survive to the final feature set after LSH and clustering. Without such a rule the claimed robustness advantage cannot be reproduced and may depend on post-hoc choices rather than the LSH construction itself.
Authors: We agree that the current manuscript does not state an explicit selection rule. In the revised version we will add a subsection under the mining algorithm that specifies the exact criteria used: a minimum support threshold of 0.01 (fraction of samples) combined with an entropy cutoff of 0.8 on the wildcard positions, chosen via a small held-out validation set. This rule will be applied uniformly after the clustering step. revision: yes
-
Referee: [Experimental section] Experimental evaluation: the manuscript provides no description of how robustness is quantified or how controls for dataset shift (temporal splits, family-wise cross-validation, or adversarial variants) are implemented. This omission is load-bearing for the central claim that hamm-grams outperform n-grams in robustness.
Authors: We acknowledge the omission. The revised experimental section will define robustness as the relative drop in F1-score when the test distribution is shifted (temporal split by collection date and family-wise cross-validation). We will report results under both a random split and the temporal split, and will include a brief description of how the temporal split was constructed from the dataset metadata. revision: yes
Circularity Check
No circularity: algorithmic construction without self-referential derivations or fitted predictions
full rationale
The paper presents an algorithmic procedure for mining hamm-grams via LSH for small Hamming distance followed by clustering to insert wildcards. No equations, parameter fits, predictions of derived quantities, or self-citations appear in the abstract or described method. The central claim is that the resulting features are more robust than n-grams for malware tasks, but this is an empirical assertion about the algorithm's output rather than a derivation that reduces to its own inputs by construction. The absence of any load-bearing self-definition, fitted-input-as-prediction, or uniqueness theorem means the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. S. Anderson and P. Roth. 2018. EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models.ArXiv e-prints(April 2018). arXiv:1804.04637 [cs.CR]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Dana Angluin. 1982. Inference of Reversible Languages.J. ACM29, 3 (jul 1982), 741–765. doi:10.1145/322326.322334
-
[3]
Dana Angluin, Sarah Eisenstat, and Dana Fisman. 2015. Learning Regular Languages via Alternating Automata. InProceedings of the 24th International Conference on Artificial Intelligence (IJCAI’15). AAAI Press, 3308–3314
2015
-
[4]
Daniel Arp, Michael Spreitzenbarth, Malte Hubner, Hugo Gascon, Konrad Rieck, and CERT Siemens. 2014. Drebin: Effective and explainable detection of android malware in your pocket.. InNdss, Vol. 14. 23–26
2014
-
[5]
Marcus Botacin, Felipe Duarte Domingues, Fabrício Ceschin, Raphael Machnicki, Marco Antonio Zanata Alves, Paulo Lício de Geus, and André Grégio. 2021. AntiViruses under the Microscope: A Hands-On Perspective.Computers & Securityi (oct 2021), 102500. doi:10.1016/j.cose.2021.102500
-
[6]
Zdenek Ceska, Ivo Hanak, and Roman Tesar. 2007. Teraman: A Tool for N-gram Extraction from Large Datasets. In2007 IEEE International Conference on Intelligent Computer Communication and Processing. IEEE, 209–216. doi:10.1109/ICCP.2007.4352162
-
[7]
F Coste and J Nicolas. 1997. Regular inference as a graph coloring problem.Workshop on Grammatical Inference, Automata Induction, and Language Acquisition (ICML’97)(1997). citeseer.nj.nec.com/coste97regular.html
1997
-
[8]
Curtin, Fred Lu, Edward Raff, and Priyanka Ranade
Ryan R. Curtin, Fred Lu, Edward Raff, and Priyanka Ranade. 2026. Intermediate N-Gramming: Deterministic and Fast N-Grams For Large N and Large Datasets. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. arXiv. doi:10.48550/arXiv.2511.14955 arXiv:2511.14955 [cs]
-
[9]
Jake Drew, Tyler Moore, and Michael Hahsler. 2016. Polymorphic Malware Detection Using Sequence Classification Methods. In2016 IEEE Security and Privacy Workshops (SPW). IEEE, 81–87. doi:10.1109/SPW.2016.30
-
[10]
Pierre Dupont, Laurent Miclet, and Enrique Vidal. 1994. What Is the Search Space of the Regular Inference?. InProceedings of the Second International Colloquium on Grammatical Inference and Applications (ICGI ’94). Springer-Verlag, Berlin, Heidelberg, 25–37
1994
-
[11]
Siddhant Gupta, Fred Lu, Andrew Barlow, Edward Raff, Francis Ferraro, Cynthia Matuszek, Charles Nicholas, and James Holt. 2024. Living off the Analyst: Harvesting Features from Yara Rules for Malware Detection. In2024 IEEE International Conference on Big Data (BigData). 2624–2634. doi:10.1109/BigData62323.2024.10825735 ISSN: 2573-2978
-
[12]
2014.Robust Static Analysis of Portable Executable Malware
Katja Hahn. 2014.Robust Static Analysis of Portable Executable Malware. Master thesis. HTWK Leipzig
2014
-
[13]
R. W. Hamming. 1950. Error detecting and error correcting codes.The Bell System Technical Journal29, 2 (1950), 147–160. doi:10.1002/j.1538- 7305.1950.tb00463.x
-
[14]
Paul Jaccard. 1912. The distribution of the flora in the alpine zone. 1.New phytologist11, 2 (1912), 37–50
1912
-
[15]
Jiyong Jang, David Brumley, and Shobha Venkataraman. 2011. BitShred: Feature Hashing Malware for Scalable Triage and Semantic Analysis. InProceedings of the 18th ACM conference on Computer and communications security - CCS. ACM Press, New York, New York, USA, 309–320. doi:10.1145/2046707.2046742
-
[16]
Robert J Joyce, Dev Amlani, Charles Nicholas, and Edward Raff. 2022. MOTIF: A Large Malware Reference Dataset with Ground Truth Family Labels. InThe AAAI-22 Workshop on Artificial Intelligence for Cyber Security (AICS). doi:10.48550/arXiv.2111.15031 arXiv: 2111.15031v1
-
[17]
Joyce, Derek Everett, Maya Fuchs, Edward Raff, and James Holt
Robert J. Joyce, Derek Everett, Maya Fuchs, Edward Raff, and James Holt. 2025. ClarAVy: A Tool for Scalable and Accurate Malware Family Labeling. InCompanion Proceedings of the ACM on Web Conference 2025 (WWW ’25). Association for Computing Machinery, New York, NY, USA, 277–286. doi:10.1145/3701716.3715212 14 Derek Everett, Edward Raff, and James Holt
-
[18]
Robert J Joyce, Edward Raff, and Charles Nicholas. 2021. A Framework for Cluster and Classifier Evaluation in the Absence of Reference Labels. In Proceedings of the 14th ACM Workshop on Artificial Intelligence and Security (AISec ’21). Association for Computing Machinery. doi:10.1145/3474369. 3486867 arXiv: 2109.11126v1
-
[19]
Jeffrey O Kephart, Gregory B Sorkin, William C Arnold, David M Chess, Gerald J Tesauro, and Steve R White. 1995. Biologically Inspired Defenses Against Computer Viruses. InProceedings of the 14th International Joint Conference on Artificial Intelligence - Volume 1 (IJCAI’95). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 985–996. http://dl.acm....
-
[20]
Jeremy Z. Kolter and Marcus A. Maloof. 2004. Learning to detect malicious executables in the wild. InProceedings of the 2004 ACM SIGKDD international conference on Knowledge discovery and data mining - KDD ’04. ACM Press, New York, New York, USA, 470–478. doi:10.1145/1014052. 1014105
-
[21]
Jesse Kornblum. 2006. Identifying almost identical files using context triggered piecewise hashing.Digital investigation3 (2006), 91–97
2006
-
[22]
Mineichi Kudo and Masaru Shimbo. 1988. Efficient regular grammatical inference techniques by the use of partial similarities and their logical relationships.Pattern Recognition21, 4 (1988), 401–409. doi:10.1016/0031-3203(88)90053-2
-
[23]
Ralph Langner. 2011. Stuxnet: Dissecting a Cyberwarfare Weapon.IEEE Security & Privacy9, 3 (2011), 49–51. doi:10.1109/MSP.2011.67
-
[24]
Kirill Levchenko, Andreas Pitsillidis, Neha Chachra, Brandon Enright, Márk Félegyházi, Chris Grier, Tristan Halvorson, Chris Kanich, Christian Kreibich, He Liu, Damon McCoy, Nicholas Weaver, Vern Paxson, Geoffrey M Voelker, and Stefan Savage. 2011. Click Trajectories: End-to-End Analysis of the Spam Value Chain. InProceedings of the 2011 IEEE Symposium on...
-
[25]
Ji Lin, Wei-Ming Chen, John Cohn, Chuang Gan, and Song Han. 2020. MCUNet: Tiny Deep Learning on IoT Devices. InAnnual Conference on Neural Information Processing Systems (NeurIPS)
2020
-
[26]
2008.Introduction to information retrieval
Christopher D Manning. 2008.Introduction to information retrieval. Syngress Publishing,
2008
-
[27]
Masud, Latifur Khan, and Bhavani Thuraisingham
Mohammad M. Masud, Latifur Khan, and Bhavani Thuraisingham. 2008. A scalable multi-level feature extraction technique to detect malicious executables.Information Systems Frontiers10, 1 (mar 2008), 33–45. doi:10.1007/s10796-007-9054-3
-
[28]
Tirth Patel, Fred Lu, Edward Raff, Charles Nicholas, Cynthia Matuszek, and James Holt. 2023. Small Effect Sizes in Malware Detection? Make Harder Train/Test Splits!Proceedings of the Conference on Applied Machine Learning in Information Security(2023). https://arxiv.org/abs/2312.15813
-
[29]
Curtin, Derek Everett, Robert J
Edward Raff, Ryan R. Curtin, Derek Everett, Robert J. Joyce, and James Holt. 2025. Zipf-Gramming: Scaling Byte N-Grams Up to Production Sized Malware Corpora. InProceedings of the 34th ACM International Conference on Information and Knowledge Management (CIKM ’25). Association for Computing Machinery, New York, NY, USA, 5988–5996. doi:10.1145/3746252.3761551
- [30]
-
[31]
Edward Raff and Mark McLean. 2018. Hash-Grams On Many-Cores and Skewed Distributions. In2018 IEEE International Conference on Big Data (Big Data). IEEE, 158–165. doi:10.1109/BigData.2018.8622043
-
[32]
Edward Raff and Charles Nicholas. 2018. Hash-Grams: Faster N-Gram Features for Classification and Malware Detection. InProceedings of the ACM Symposium on Document Engineering 2018. ACM, Halifax, NS, Canada. doi:10.1145/3209280.3229085
-
[33]
Edward Raff and Charles Nicholas. 2018. Lempel-Ziv Jaccard Distance, an effective alternative to ssdeep and sdhash.Digital Investigation24 (2018), 34–49
2018
-
[34]
Rayleigh. 1905. The Problem of the Random Walk.Nature72, 1866 (1905), 318–318. doi:10.1038/072318a0
-
[35]
Vassil Roussev. 2010. Data fingerprinting with similarity digests. InAdvances in Digital Forensics VI: Sixth IFIP WG 11.9 International Conference on Digital Forensics, Hong Kong, China, January 4-6, 2010, Revised Selected Papers 6. Springer, 207–226
2010
-
[36]
Asaf Shabtai, Robert Moskovitch, Yuval Elovici, and Chanan Glezer. 2009. Detection of malicious code by applying machine learning classifiers on static features: A state-of-the-art survey.Information Security Technical Report14, 1 (2009), 16–29. doi:10.1016/j.istr.2009.03.003
-
[37]
Ehsan Shareghi, Daniela Gerz, Ivan Vulić, and Anna Korhonen. 2019. Show Some Love to Your n-grams: A Bit of Progress and Stronger n- gram Language Modeling Baselines. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burst...
-
[38]
Charles Smutz and Angelos Stavrou. 2012. Malicious PDF detection using metadata and structural features. InProceedings of the 28th Annual Computer Security Applications Conference. ACM, 239–248
2012
-
[39]
Tse and P
D. Tse and P. Viswanath. 2005.Fundamentals of Wireless Communication. Cambridge University Press. https://books.google.com/books?id= 66XBb5tZX6EC
2005
-
[40]
R.B. van Baar, H.M.A. van Beek, and E.J. van Eijk. 2014. Digital Forensics as a Service: A game changer.Digital Investigation11 (2014), S54–S62. doi:10.1016/j.diin.2014.03.007
-
[41]
Charlotte Van Camp and Walter Peeters. 2022. A World without Satellite Data as a Result of a Global Cyber-Attack.Space Policy59 (2022), 101458. doi:10.1016/j.spacepol.2021.101458
-
[42]
Rabin, Kristopher Micinski, Jeffrey S
Daniel Votipka, Seth M. Rabin, Kristopher Micinski, Jeffrey S. Foster, and Michelle M. Mazurek. 2019. An Observational Investigation of Reverse Engineers ’ Processes. InUSENIX Security Symposium
2019
-
[43]
Andrew Walenstein, Michael Venable, Matthew Hayes, Christopher Thompson, and Arun Lakhotia. 2007. Exploiting similarity between variants to defeat malware. InProc. BlackHat DC Conf. Hamm-Grams: An Algorithm for Mining Regular Expressions of Bytes 15
2007
-
[44]
Weisstein
Eric W. Weisstein. [n. d.]. Random Walk–2-Dimensional. https://mathworld.wolfram.com/RandomWalk2-Dimensional.html
-
[45]
Miuyin Yong Wong, Matthew Landen, Manos Antonakakis, Douglas M Blough, Elissa M Redmiles, and Mustaque Ahamad. 2021. An Inside Look into the Practice of Malware Analysis. InProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security (CCS ’21). Association for Computing Machinery, New York, NY, USA, 3053–3069. doi:10.1145/3460120.3484759
-
[46]
Richard Zak, Edward Raff, and Charles Nicholas. 2017. What can N-grams learn for malware detection?. In2017 12th International Conference on Malicious and Unwanted Software (MALW ARE). IEEE, 109–118. doi:10.1109/MALWARE.2017.8323963
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.