Disentangling Pictorial Cue Understanding from Language Bias in VLMs via Depth Ordering Task
Pith reviewed 2026-07-03 20:49 UTC · model grok-4.3
The pith
Vision-language models achieve only chance-level depth ordering because they under-use pictorial cues and rely on language biases instead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
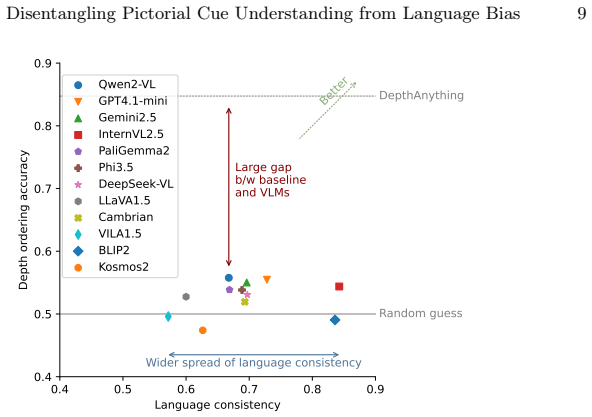
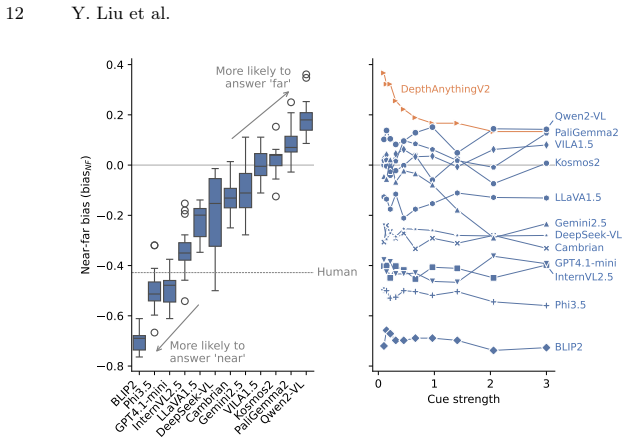
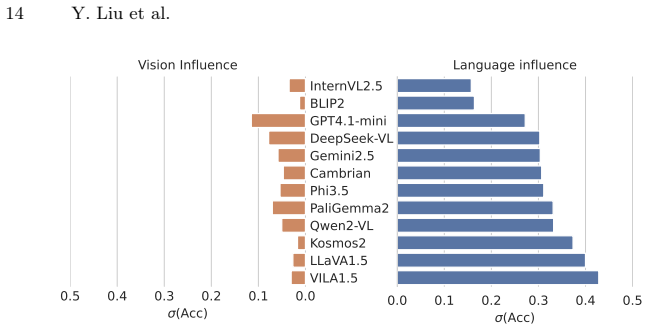
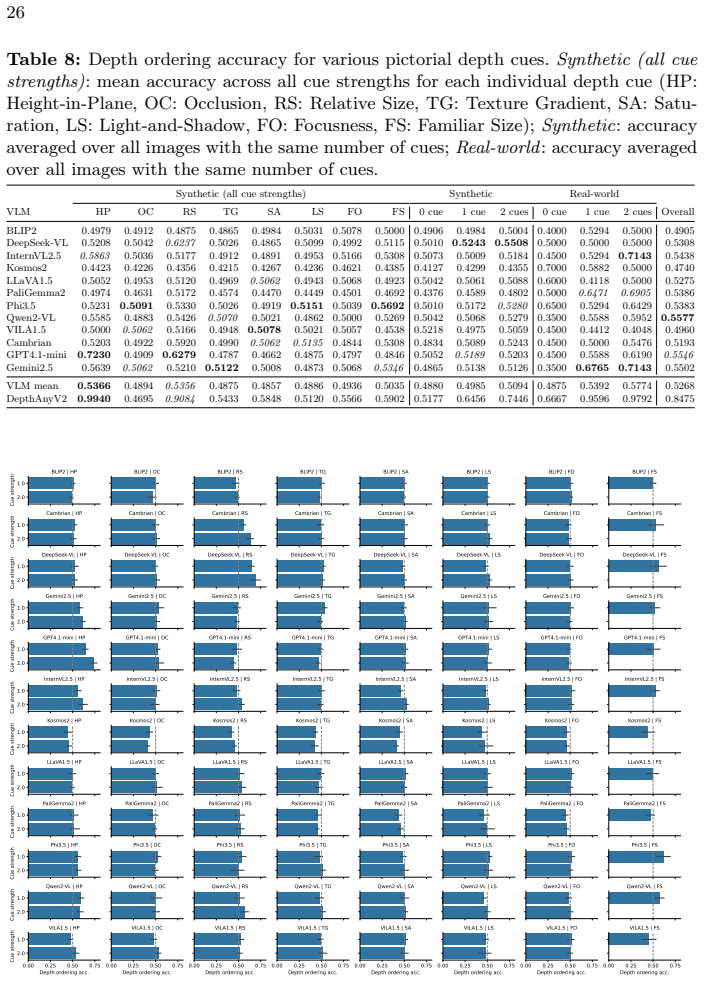
The paper claims that current VLMs do not extract depth order from pictorial cues. When one object is placed at a different depth among otherwise identical objects, models cannot reliably say whether the odd-one-out target is closer or farther; accuracies stay at or below chance. A metric that varies referring-expression clarity shows the decisions track language statistics far more than the controlled visual cues. The authors conclude that static image training alone leaves models without usable depth understanding.
What carries the argument
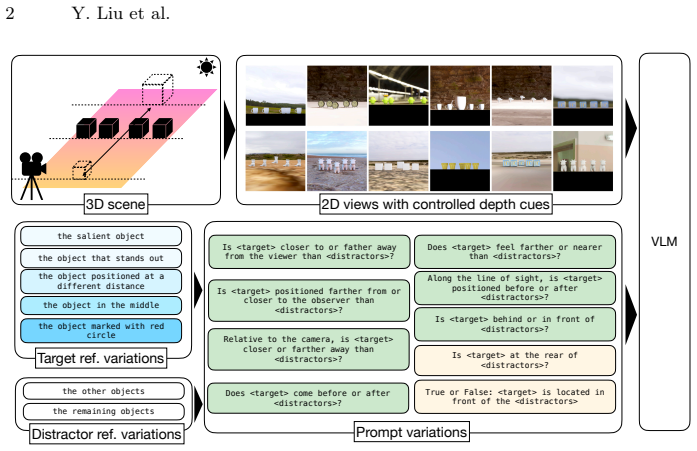
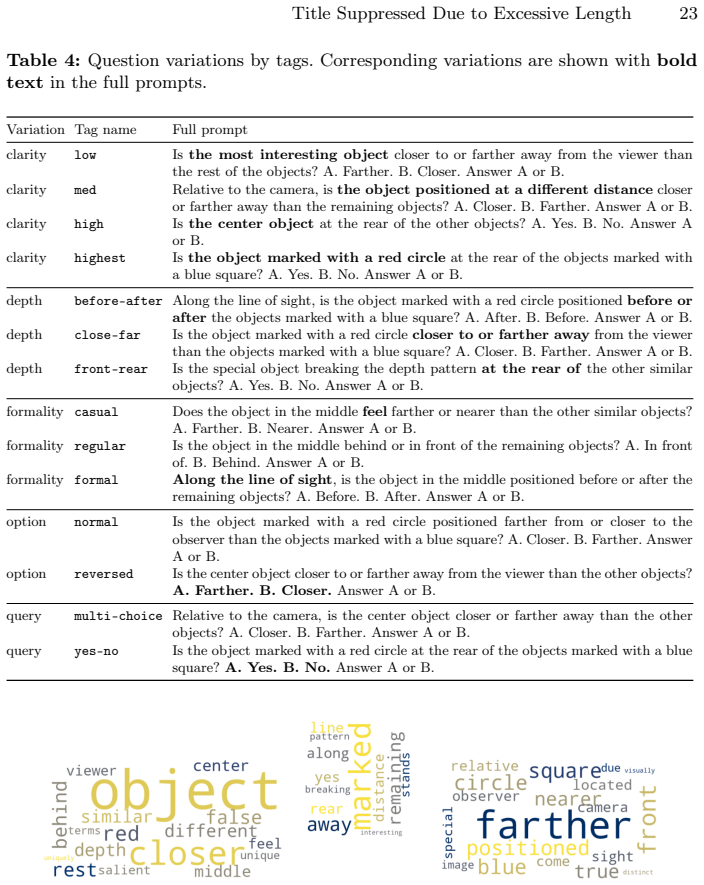
The Odd-One-Out Depth (O3-D) dataset and the vision-versus-language sensitivity metric, built by generating 2D views while toggling individual pictorial depth cues and referring-expression clarity.
If this is right
- Pictorial depth cues remain unused by current VLMs even when the task is reduced to simple closer-farther judgments.
- Chain-of-thought and in-context learning produce no meaningful gain on depth ordering once language bias is controlled.
- Static image pre-training is insufficient to produce genuine depth ordering ability in VLMs.
- Fine-grained cue control is required to separate visual understanding from language shortcuts in future evaluations.
Where Pith is reading between the lines
- The same cue-isolation method could be applied to other perceptual judgments such as relative size or surface slant.
- Models that pass this test might still fail when depth cues must be integrated across multiple objects or changing viewpoints.
- Training regimes that add explicit depth supervision or 3D reconstruction losses could be tested directly against the O3-D baseline.
Load-bearing premise
The synthetic and real-scene stimuli isolate each pictorial depth cue without adding unintended correlations that models could solve by shortcut instead of depth perception.
What would settle it
Any model that reaches clearly above-chance accuracy on O3-D trials where language cues are removed or randomized would show that the under-utilization claim does not hold.
Figures




read the original abstract
In this paper, we study depth perception of vision-language models (VLMs) to isolate the effects of pictorial depth cues and disentangle vision and language influences on model performance. To this end, we combine depth-ordering and odd-one-out psychophysical tasks: the VLMs are presented with images where one object is at different depth relative to other, otherwise identical, objects, and must determine whether the odd-one-out target is closer or farther to the observer. To create stimuli, we generate 2D views from simulated and real 3D scenes while controlling the presence of individual pictorial depth cues, enabling a fine-grained analysis of cue-level contributions. Language effects are examined by varying referring expression clarity. We also introduce a novel metric to quantify vision-vs-language sensitivities. Applying this methodology, we create the Odd-One-Out Depth (O3-D) dataset with 37K real and synthetic images and 147K image-question pairs. Evaluation of 12 open-source and commercial models on O3-D shows under-utilization of depth cues and depth-ordering accuracies between 47% and 56%, with no model above chance level. At the same time, our metric reveals strong linguistic bias in the answers. Neither chain-of-thought (CoT) nor in-context learning (ICL) significantly improves performance, suggesting that static image data alone may be insufficient for depth understanding. All code, the image generation pipeline, and the O3-D dataset are publicly released at https://github.com/lyiqian/o3-d.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Odd-One-Out Depth (O3-D) dataset of 37K real and synthetic images and 147K image-question pairs, generated by rendering 2D views from 3D scenes while controlling the presence of individual pictorial depth cues. It combines depth-ordering and odd-one-out tasks to evaluate 12 VLMs, reporting accuracies of 47-56% (no model above chance) and introducing a novel vision-vs-language sensitivity metric that reveals strong linguistic bias. Neither CoT nor ICL improves results, and the authors publicly release the dataset, generation pipeline, and code.
Significance. If the cue controls are shown to isolate depth perception without confounds, the results would provide concrete evidence that current VLMs fail to leverage pictorial depth cues and default to language biases, with direct implications for multimodal model design. The public release of the full pipeline and dataset is a clear strength that supports reproducibility.
major comments (3)
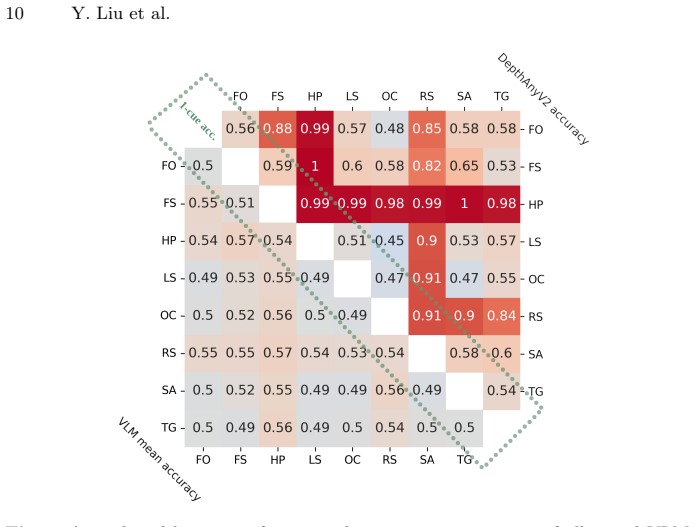
- [Abstract and §3] Abstract and §3 (Dataset): The headline finding that models exhibit under-utilization of depth cues (accuracies 47-56%, none above chance) requires that the 37K images cannot be solved via non-depth regularities. The description of controlling individual cues from simulated and real 3D scenes provides no quantitative verification (e.g., correlation analysis or control ablations) that rendering artifacts, texture, or lighting do not introduce exploitable patterns.
- [§4] §4 (Evaluation) and metric definition: The vision-vs-language sensitivity metric is used to attribute failures to linguistic bias, yet the manuscript does not report how the metric is computed from the varying referring-expression conditions or demonstrate that it is robust to question phrasing variations that could independently affect performance.
- [§4] §4 (Results): The reported depth-ordering accuracies are given as ranges (47-56%) without per-model breakdowns, error bars, or statistical comparison to chance level, making it impossible to assess whether the 'no model above chance' claim holds after accounting for variance across the 147K pairs.
minor comments (2)
- [Abstract] The abstract states that 'static image data alone may be insufficient,' but this conclusion would be strengthened by explicit reference to the specific CoT/ICL results rather than appearing as a general claim.
- [Figures/Tables] Figure captions and table headers could more clearly distinguish real vs. synthetic image subsets when reporting cue-level contributions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, indicating planned revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Dataset): The headline finding that models exhibit under-utilization of depth cues (accuracies 47-56%, none above chance) requires that the 37K images cannot be solved via non-depth regularities. The description of controlling individual cues from simulated and real 3D scenes provides no quantitative verification (e.g., correlation analysis or control ablations) that rendering artifacts, texture, or lighting do not introduce exploitable patterns.
Authors: We agree that explicit quantitative verification would further support the isolation of depth cues. The generation pipeline randomizes lighting, textures, camera poses, and object properties across the 3D scenes to minimize systematic artifacts, and real-world captures use varied environments. In the revision we will add correlation analyses between non-depth image statistics (e.g., texture histograms, lighting gradients) and ground-truth labels, plus control ablations on subsets with fixed cues, to demonstrate absence of exploitable regularities. revision: yes
-
Referee: [§4] §4 (Evaluation) and metric definition: The vision-vs-language sensitivity metric is used to attribute failures to linguistic bias, yet the manuscript does not report how the metric is computed from the varying referring-expression conditions or demonstrate that it is robust to question phrasing variations that could independently affect performance.
Authors: The metric is defined in §4 as the differential performance between clear and ambiguous referring-expression conditions on the same images. We will expand the description with the exact formula and add a robustness check across two additional phrasings per condition to confirm the bias attribution is not phrasing-dependent. revision: partial
-
Referee: [§4] §4 (Results): The reported depth-ordering accuracies are given as ranges (47-56%) without per-model breakdowns, error bars, or statistical comparison to chance level, making it impossible to assess whether the 'no model above chance' claim holds after accounting for variance across the 147K pairs.
Authors: We will replace the aggregate range with a table listing per-model accuracies, standard errors computed over the 147K pairs (or per-image subsets), and one-sample t-test p-values against 50% chance level. This will be included in the revised §4. revision: yes
Circularity Check
Empirical evaluation study; no derivations or predictions reduce to fitted parameters or self-citations.
full rationale
This is an empirical evaluation paper that generates a controlled dataset (O3-D) from 3D scenes, tests 12 VLMs on depth-ordering tasks, and introduces a metric for vision-vs-language bias. No equations, fitted parameters, or predictions are claimed; the central results (47-56% accuracies, linguistic bias) follow directly from model outputs on the released stimuli. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The analysis is self-contained against external model benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pictorial depth cues can be selectively enabled or disabled in rendered images without introducing new unintended correlations
invented entities (1)
-
vision-vs-language sensitivity metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Abdin, M., et al.: Phi-3 technical report: A highly capable language model locally on your phone. arXiv:2404.14219 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
IEEE TPAMI46(4), 2396–2414 (2023)
Arampatzakis, V., Pavlidis, G., Mitianoudis, N., Papamarkos, N.: Monocular depth estimation: A thorough review. IEEE TPAMI46(4), 2396–2414 (2023)
2023
-
[3]
In: CVPRW (2025)
Azad, S., Jain, Y., Garg, R., Rawat, Y., Vineet, V.: Understanding depth and height perception in large visual-language models. In: CVPRW (2025)
2025
-
[4]
In: CVPR (2022)
Azuma, D., Miyanishi, T., Kurita, S., Kawanabe, M.: ScanQA: 3D Question An- swering for Spatial Scene Understanding. In: CVPR (2022)
2022
-
[5]
Baldassini, F.B., Shukor, M., Cord, M., Soulier, L., Piwowarski, B.: What makes multimodal in-context learning work? In: CVPRW. pp. 1539–1550 (2024)
2024
-
[6]
In: Stevens’ Handbook of Experi- mental Psychology and Cognitive Neuroscience, pp
Brenner, E., Smeets, J.B.J.: Depth perception. In: Stevens’ Handbook of Experi- mental Psychology and Cognitive Neuroscience, pp. 1–30. John Wiley & Sons, Ltd (2018)
2018
-
[7]
In: CVPR (2024)
Chen, B., Xu, Z., Kirmani, S., Ichter, B., Sadigh, D., Guibas, L., Xia, F.: Spa- tialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities. In: CVPR (2024)
2024
-
[8]
In: ECCV (2020) 16 Y
Chen, D.Z., Chang, A.X., Nießner, M.: ScanRefer: 3D Object Localization in RGB- D Scans Using Natural Language. In: ECCV (2020) 16 Y. Liu et al
2020
-
[9]
In: NeurIPS (2023)
Chen, S., Gu, J., Han, Z., Ma, Y., Torr, P., Tresp, V.: Benchmarking Robustness of Adaptation Methods on Pre-trained Vision-Language Models. In: NeurIPS (2023)
2023
-
[10]
In: NeurIPS (2016)
Chen, W., Fu, Z., Yang, D., Deng, J.: Single-image depth perception in the wild. In: NeurIPS (2016)
2016
-
[11]
Chen, Z., et al.: Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling. arXiv:2412.05271 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
In: NeurIPS (2024)
Cheng, A.C., Yin, H., Fu, Y., Guo, Q., Yang, R., Kautz, J., Wang, X., Liu, S.: Spa- tialRGPT: Grounded Spatial Reasoning in Vision-Language Models. In: NeurIPS (2024)
2024
-
[13]
In: ICLR (2025)
Chow, W., Mao, J., Li, B., Seita, D., Guizilini, V., Wang, Y.: Physbench: Bench- marking and enhancing vision-language models for physical world understanding. In: ICLR (2025)
2025
-
[14]
In: ICCV (2025)
Dahou, Y., Huynh, N.D., Le-Khac, P.H., Para, W.R., Singh, A., Narayan, S.: Sal- Bench: Vision-language models can’t see the obvious. In: ICCV (2025)
2025
-
[15]
In: CVPR (2025)
Danier, D., Aygün, M., Li, C., Bilen, H., Mac Aodha, O.: DepthCues: Evaluating Monocular Depth Perception in Large Vision Models. In: CVPR (2025)
2025
-
[16]
Deng, A., Cao, T., Chen, Z., Hooi, B.: Words or vision: Do vision-language models have blind faith in text? In: CVPR (2025)
2025
-
[17]
In: CVPR (2024)
El Banani, M., Raj, A., Maninis, K.K., Kar, A., Li, Y., Rubinstein, M., Sun, D., Guibas,L.,Johnson,J.,Jampani,V.:Probingthe3dawarenessofvisualfoundation models. In: CVPR (2024)
2024
-
[18]
In: Yarowsky, D., Baldwin, T., Korho- nen, A., Livescu, K., Bethard, S
FitzGerald, N., Artzi, Y., Zettlemoyer, L.: Learning Distributions over Logical Forms for Referring Expression Generation. In: Yarowsky, D., Baldwin, T., Korho- nen, A., Livescu, K., Bethard, S. (eds.) Proceedings of the Conference on Empirical Methods in Natural Language Processing (2013)
2013
-
[19]
In: ECCV (2025)
Fu, X., Hu, Y., Li, B., Feng, Y., Wang, H., Lin, X., Roth, D., Smith, N.A., Ma, W.C., Krishna, R.: BLINK: Multimodal Large Language Models Can See but Not Perceive. In: ECCV (2025)
2025
-
[20]
In: CVPR (2017)
Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., Parikh, D.: Making the v in VQA Matter: Elevating the Role of Image Understanding in Visual Question An- swering. In: CVPR (2017)
2017
-
[21]
In: CVPR (2022)
Greff, K., Belletti, F., Beyer, L., Doersch, C., Du, Y., Duckworth, D., Fleet, D.J., Gnanapragasam, D., Golemo, F., Herrmann, C., Kipf, T., Kundu, A., Lagun, D., Laradji, I., Liu, H.T.D., Meyer, H., Miao, Y., Nowrouzezahrai, D., Oztireli, C., Pot, E., Radwan, N., Rebain, D., Sabour, S., Sajjadi, M.S.M., Sela, M., Sitzmann, V., Stone, A., Sun, D., Vora, S....
2022
-
[22]
In: CVPR (2009)
He, K., Sun, J., Tang, X.: Single image haze removal using dark channel prior. In: CVPR (2009)
2009
-
[23]
Infant Behavior and Development 35(1), 109–128 (2012)
Kavšek, M., Yonas, A., Granrud, C.E.: Infants’ sensitivity to pictorial depth cues: A review and meta-analysis of looking studies. Infant Behavior and Development 35(1), 109–128 (2012)
2012
-
[24]
ACM Computing Surveys57(10), 1–35 (2025)
Kim, B.S., Kim, J., Lee, D., Jang, B.: Visual Question Answering: A Survey of Methods, Datasets, Evaluation, and Challenges. ACM Computing Surveys57(10), 1–35 (2025)
2025
-
[25]
In: BMVC (2019)
Kotseruba, I., Wloka, C., Rasouli, A., Tsotsos, J.K.: Do Saliency Models Detect Odd-One-Out Targets? New Datasets and Evaluations. In: BMVC (2019)
2019
-
[26]
In: CVPR (2024)
Li, B., Ge, Y., Ge, Y., Wang, G., Wang, R., Zhang, R., Shan, Y.: SEED-Bench: Benchmarking Multimodal Large Language Models. In: CVPR (2024)
2024
-
[27]
Li, J., Li, D., Savarese, S., Hoi, S.: BLIP-2: Bootstrapping Language-Image Pre- trainingwithFrozenImageEncodersandLargeLanguageModels.In:ICML(2023) Disentangling Pictorial Cue Understanding from Language Bias 17
2023
-
[28]
In: CVPR (2024)
Lin, J., Yin, H., Ping, W., Molchanov, P., Shoeybi, M., Han, S.: VILA: On Pre- training for Visual Language Models. In: CVPR (2024)
2024
-
[29]
In: ICLR (2025)
Linsley, D., Zhou, P., Ashok, A.K., Nagaraj, A., Gaonkar, G., Lewis, F.E., Pizlo, Z., Serre, T.: The 3D-PC: A benchmark for visual perspective taking in humans and machines. In: ICLR (2025)
2025
-
[30]
In: CVPR (2023)
Liu, C., Ding, H., Jiang, X.: GRES: Generalized Referring Expression Segmenta- tion. In: CVPR (2023)
2023
-
[31]
In: CVPR (2024)
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved Baselines with Visual Instruction Tun- ing. In: CVPR (2024)
2024
-
[32]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., Chen, K., Lin, D.: MMBench: Is Your Multi-modal Model an All- Around Player? In: ECCV (2025)
2025
-
[33]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Lu, H., Liu, W., Zhang, B., Wang, B., Dong, K., Liu, B., Sun, J., Ren, T., Li, Z., Yang, H., Sun, Y., Deng, C., Xu, H., Xie, Z., Ruan, C.: DeepSeek-VL: Towards real-world vision-language understanding. arXiv:2403.05525 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
In: ICLR (2023)
Ma, X., Yong, S., Zheng, Z., Li, Q., Liang, Y., Zhu, S.C., Huang, S.: SQA3D: Situated Question Answering in 3D Scenes. In: ICLR (2023)
2023
-
[35]
In: ICCV (2024)
Man, Y., Zheng, S., Bao, Z., Hebert, M., Gui, L.Y., Wang, Y.X.: Lexicon3D: Prob- ing Visual Foundation Models for Complex 3D Scene Understanding. In: ICCV (2024)
2024
-
[36]
In: CVPR (2016)
Mao, J., Huang, J., Toshev, A., Camburu, O., Yuille, A.L., Murphy, K.: Generation and Comprehension of Unambiguous Object Descriptions. In: CVPR (2016)
2016
-
[37]
Marshall, J.A., Burbeck, C.A., Ariely, D., Rolland, J.P., Martin, K.E.: Occlusion edge blur: a cue to relative visual depth. J. Opt. Soc. Am. A13(4), 681–688 (Apr 1996)
1996
-
[38]
IEEE TPAMI44(7), 3523–3542 (2021)
Minaee, S., Boykov, Y., Porikli, F., Plaza, A., Kehtarnavaz, N., Terzopoulos, D.: Image segmentation using deep learning: A survey. IEEE TPAMI44(7), 3523–3542 (2021)
2021
-
[39]
In: CVPR (2021)
Niu, Y., Tang, K., Zhang, H., Lu, Z., Hua, X.S., Wen, J.R.: Counterfactual VQA: A Cause-Effect Look at Language Bias. In: CVPR (2021)
2021
-
[40]
In: ICLR (2024)
Peng, Z., Wang, W., Dong, L., Hao, Y., Huang, S., Ma, S., Wei, F.: Kosmos-2: Grounding Multimodal Large Language Models to the World. In: ICLR (2024)
2024
-
[41]
In: Findings of the Association for Computa- tional Linguistics: NAACL
Pezeshkpour, P., Hruschka, E.: Large language models sensitivity to the order of options in multiple-choice questions. In: Findings of the Association for Computa- tional Linguistics: NAACL. pp. 2006–2017 (2024)
2006
-
[42]
IEEE TMM23, 4426–4440 (2021)
Qiao, Y., Deng, C., Wu, Q.: Referring expression comprehension: A survey of meth- ods and datasets. IEEE TMM23, 4426–4440 (2021)
2021
-
[43]
In: NeurIPS (2024)
Qin, L., Chen, Q., Fei, H., Chen, Z., Li, M., Che, W.: What Factors Affect Multi- Modal In-Context Learning? An In-Depth Exploration. In: NeurIPS (2024)
2024
-
[44]
In: Three-Dimensional Imaging, Visualization, and Display
Reichelt, S., Häussler, R., Fütterer, G., Leister, N.: Depth cues in human visual perception and their realization in 3D displays. In: Three-Dimensional Imaging, Visualization, and Display. vol. 7690, pp. 92–103. SPIE (2010)
2010
-
[45]
Arti- ficial Intelligence Review56(9), 9175–9219 (2023)
Samavati, T., Soryani, M.: Deep learning-based 3d reconstruction: A survey. Arti- ficial Intelligence Review56(9), 9175–9219 (2023)
2023
-
[46]
In: CVPR (June 2019)
Shah, M., Chen, X., Rohrbach, M., Parikh, D.: Cycle-consistency for robust visual question answering. In: CVPR (June 2019)
2019
-
[47]
In: International Conference on Development and Learning
Sinapov, J., Stoytchev, A.: The odd one out task: Toward an intelligence test for robots. In: International Conference on Development and Learning. pp. 126–131 (2010) 18 Y. Liu et al
2010
-
[48]
PaliGemma 2: A Family of Versatile VLMs for Transfer
Steiner, A., Pinto, A.S., Tschannen, M., Keysers, D., Wang, X., Bitton, Y., Grit- senko, A., Minderer, M., Sherbondy, A., Long, S., Qin, S., Ingle, R., Bugliarello, E., Kazemzadeh, S., Mesnard, T., Alabdulmohsin, I., Beyer, L., Zhai, X.: PaliGemma 2: A Family of Versatile VLMs for Transfer. arXiv:2412.03555 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Springer Nature (2022)
Szeliski, R.: Computer Vision: Algorithms and Applications. Springer Nature (2022)
2022
-
[50]
In: NeurIPS (2024)
Tong, S., Brown, E., Wu, P., Woo, S., Middepogu, M., Akula, S.C., Yang, J., Yang, S., Iyer, A., Pan, X., Wang, A., Fergus, R., LeCun, Y., Xie, S.: Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs. In: NeurIPS (2024)
2024
-
[51]
In: CVPR (2024)
Tong, S., Liu, Z., Zhai, Y., Ma, Y., LeCun, Y., Xie, S.: Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs. In: CVPR (2024)
2024
-
[52]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., Fan, Y., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., Lin, J.: Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution. arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Journal of Vision5(10), 7 (2005)
Watt,S.J.,Akeley,K.,Ernst,M.O.,Banks,M.S.:Focuscuesaffectperceiveddepth. Journal of Vision5(10), 7 (2005)
2005
-
[54]
Journal of vision5(10), 7–7 (2005)
Watt,S.J.,Akeley,K.,Ernst,M.O.,Banks,M.S.:Focuscuesaffectperceiveddepth. Journal of vision5(10), 7–7 (2005)
2005
-
[55]
Acta Psychologica99(3), 293–310 (1998)
Westerman, S.J., Cribbin, T.: Individual differences in the use of depth cues: Im- plications for computer- and video-based tasks. Acta Psychologica99(3), 293–310 (1998)
1998
-
[56]
Wickens, C.D., Todd, S., Seidler, K.: Three-dimensional displays: Perception, im- plementation, and applications. Tech. Rep. AD-A259 937, University of Illinois (1989)
1989
-
[57]
In: NeurIPS (2024)
Yang,L.,Kang,B.,Huang,Z.,Zhao,Z.,Xu,X.,Feng,J.,Zhao,H.:DepthAnything V2. In: NeurIPS (2024)
2024
-
[58]
In: ICLR (2024)
You, H., Zhang, H., Gan, Z., Du, X., Zhang, B., Wang, Z., Cao, L., Chang, S.F., Yang, Y.: Ferret: Refer and Ground Anything Anywhere at Any Granularity. In: ICLR (2024)
2024
-
[59]
In: NeurIPS (2024)
Zhan, G., Zheng, C., Xie, W., Zisserman, A.: A General Protocol to Probe Large Vision Models for 3D Physical Understanding. In: NeurIPS (2024)
2024
-
[60]
Answer:”instead of“Answer A or B
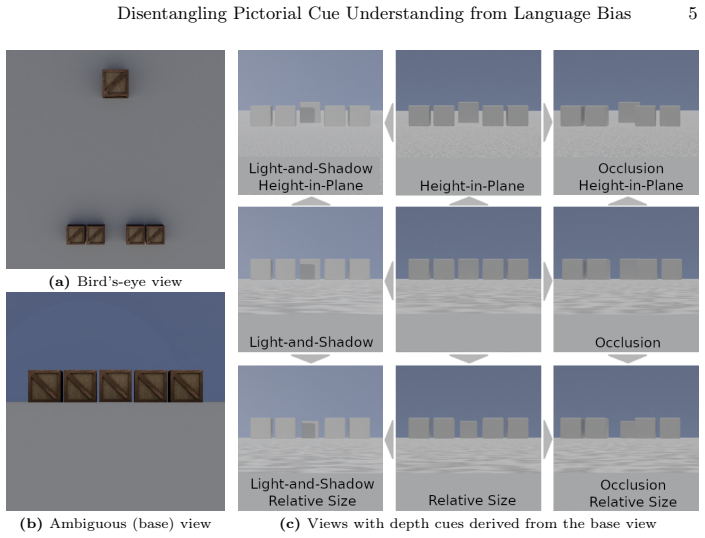
Zou, Z., Chen, K., Shi, Z., Guo, Y., Ye, J.: Object detection in 20 years: A survey. Proceedings of the IEEE111(3), 257–276 (2023) Disentangling Pictorial Cue Understanding from Language Bias in VLMs via Depth Ordering Task (Supplementary Material) 1 Controlled Pictorial Cues Fig. 1 illustrates sampled images for the base view and 9 controlled pictorial c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.