ICDepth: Taming Video Diffusion Models for Video Depth Estimation via In-Context Conditioning
Pith reviewed 2026-07-03 16:57 UTC · model grok-4.3
The pith
Pre-trained video diffusion transformers can be adapted for monocular video depth estimation via in-context conditioning to reach state-of-the-art accuracy with far less training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ICDepth adapts pre-trained text-to-video diffusion transformers for video depth estimation via In-Context Conditioning. Key adaptations are SAND-Attention, which enforces precise spatial-temporal alignment through shared RoPE and unidirectional attention to block noise, and SRFM, which injects DINOv2 semantic and resolution priors to improve geometric fidelity. The resulting model reaches state-of-the-art results on multiple benchmarks after training on only 0.8M frames, six to thirteen times less data than competing generative methods, while showing strong zero-shot generalization across domains.
What carries the argument
In-Context Conditioning (ICC) on diffusion transformers, realized through SAND-Attention for alignment and SRFM for semantic prior injection.
If this is right
- Generative depth methods no longer require 10M+ training frames to achieve temporal consistency.
- Depth estimates can maintain consistency across long video sequences without per-frame drift.
- Models trained this way generalize to new visual domains without additional labeled data.
- Geometric precision on standard benchmarks matches or exceeds that of purely discriminative video depth estimators.
Where Pith is reading between the lines
- The same conditioning approach could be tested on other dense video tasks such as optical flow or surface normal estimation.
- Lower data requirements might allow depth models to be retrained quickly when new camera hardware appears.
- If the priors prove broadly transferable, similar adaptations might succeed on non-diffusion backbones for geometric prediction.
Load-bearing premise
The spatial-temporal priors learned during text-to-video pre-training remain rich enough to support precise geometric prediction once steered by in-context conditioning.
What would settle it
A controlled experiment in which ICDepth, after the same 0.8M-frame budget, produces depth maps whose per-frame accuracy or temporal consistency falls below that of strong discriminative baselines on a held-out benchmark would falsify the central claim.
Figures
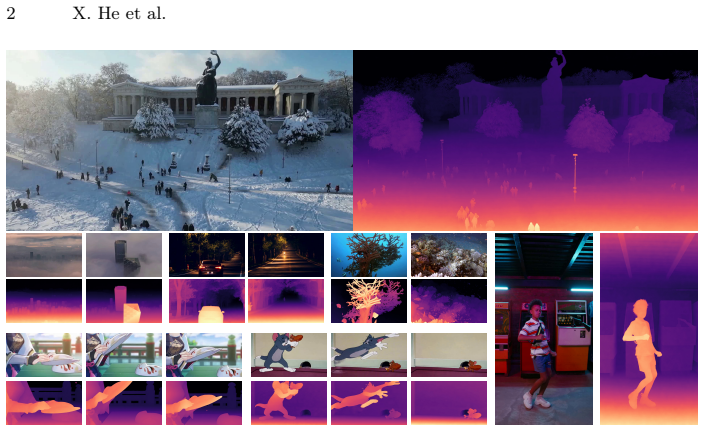


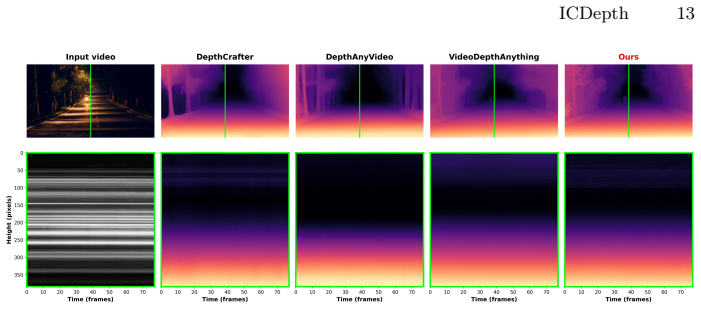
read the original abstract
Monocular video depth estimation requires temporal consistency, geometric accuracy, and generalization across diverse scenarios, yet existing methods struggle to achieve all three simultaneously. Discriminative models excel at per-frame accuracy but suffer from temporal drift due to limited context windows, while generative methods improve consistency and generalization at the cost of extensive training data (10M+ samples) and lack of geometric precision. In response to these issues, we introduce \textbf{ICDepth}, a framework that adapts pre-trained text-to-video diffusion transformers for video depth estimation via In-Context Conditioning (ICC), leveraging their rich spatial-temporal priors. To address key challenges in transferring ICC from generation to dense prediction, we propose: (1)~\textbf{SAND-Attention}, which ensures precise spatial-temporal alignment via shared RoPE and enforces unidirectional attention to prevent noise contamination; (2)~\textbf{SRFM}, which injects DINOv2 semantic and resolution priors to enhance geometric precision. ICDepth achieves state-of-the-art results on multiple benchmarks with remarkable data efficiency, trained on only 0.8M frames ($6$--$13\times$ less than competing generative methods), while demonstrating strong zero-shot generalization to diverse domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ICDepth, a framework adapting pre-trained text-to-video diffusion transformers for monocular video depth estimation via In-Context Conditioning (ICC). It proposes SAND-Attention to ensure spatial-temporal alignment through shared RoPE and unidirectional attention, and SRFM to inject DINOv2 semantic and resolution priors for geometric precision. The central empirical claim is state-of-the-art performance on multiple benchmarks, trained on only 0.8M frames (6-13× less data than competing generative methods), with strong zero-shot generalization across domains.
Significance. If the reported results hold, the work would be significant for demonstrating efficient transfer of rich spatial-temporal priors from generative video diffusion models to dense geometric prediction tasks. The data efficiency (0.8M frames) and ability to maintain both temporal consistency and geometric accuracy without massive additional training data represent a meaningful advance over prior discriminative methods (limited context) and generative approaches (high data cost, lower precision).
minor comments (3)
- [Abstract] Abstract: strong SOTA and data-efficiency claims are made without any quantitative metrics, specific benchmark names, or error values; adding 1-2 key numbers (e.g., AbsRel or δ1 on a standard dataset) would improve the abstract's informativeness.
- [Abstract] The acronyms SAND-Attention and SRFM are introduced without parenthetical expansions or one-sentence functional descriptions in the abstract; this reduces immediate readability for readers outside the immediate sub-area.
- The manuscript should clarify whether the reported 0.8M-frame count includes only the fine-tuning data or also any auxiliary pre-training stages, and provide a direct comparison table against the exact data volumes used by the cited generative baselines.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of ICDepth, the recognition of its data efficiency (0.8M frames) and zero-shot generalization, and the recommendation for minor revision. We will incorporate any minor clarifications in the revised version.
Circularity Check
No significant circularity
full rationale
The paper describes an empirical adaptation of pre-trained video diffusion transformers to monocular video depth estimation via in-context conditioning, introducing SAND-Attention for alignment and SRFM for semantic priors. All claims rest on benchmark comparisons and data-efficiency measurements (0.8M frames) rather than any mathematical derivation chain, first-principles predictions, or quantities that reduce to fitted inputs by construction. No self-citations function as load-bearing uniqueness theorems, and the method is presented as an engineering transfer with external validation on standard datasets. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained text-to-video diffusion transformers contain rich spatial-temporal priors that transfer effectively to dense prediction tasks.
invented entities (2)
-
SAND-Attention
no independent evidence
-
SRFM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023) 16 X. He et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Cabon, Y., Murray, N., Humenberger, M.: Virtual kitti 2. arXiv preprint arXiv:2001.10773 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[3]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, S., Guo, H., Zhu, S., Zhang, F., Huang, Z., Feng, J., Kang, B.: Video depth anything: Consistent depth estimation for super-long videos. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22831–22840 (2025)
2025
-
[4]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Dai,A.,Chang,A.X.,Savva,M.,Halber,M.,Funkhouser,T.,Nießner,M.:Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5828–5839 (2017)
2017
-
[5]
The international journal of robotics research32(11), 1231–1237 (2013)
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The kitti dataset. The international journal of robotics research32(11), 1231–1237 (2013)
2013
-
[6]
Long context tuning for video generation.arXiv preprint arXiv:2503.10589, 2025
Guo, Y., Yang, C., Yang, Z., Ma, Z., Lin, Z., Yang, Z., Lin, D., Jiang, L.: Long context tuning for video generation. arXiv preprint arXiv:2503.10589 (2025)
-
[7]
arXiv preprint arXiv:2506.04213 (2025)
He, X., Liu, Q., Ye, Z., Ye, W., Wang, Q., Wang, X., Chen, Q., Wan, P., Zhang, D., Gai, K.: Fulldit2: Efficient in-context conditioning for video diffusion transformers. arXiv preprint arXiv:2506.04213 (2025)
-
[8]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Hu, W., Gao, X., Li, X., Zhao, S., Cun, X., Zhang, Y., Quan, L., Shan, Y.: Depthcrafter: Generating consistent long depth sequences for open-world videos. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2005–2015 (2025)
2005
-
[9]
In-context LoRA for diffusion transformers
Huang,L.,Wang,W.,Wu,Z.F.,Shi,Y.,Dou,H.,Liang,C.,Feng,Y.,Liu,Y.,Zhou, J.: In-context lora for diffusion transformers. arXiv preprint arXiv:2410.23775 (2024)
-
[10]
arXiv preprint arXiv:2503.19907 (2025)
Ju, X., Ye, W., Liu, Q., Wang, Q., Wang, X., Wan, P., Zhang, D., Gai, K., Xu, Q.: Fulldit: Multi-task video generative foundation model with full attention. arXiv preprint arXiv:2503.19907 (2025)
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Ke, B., Obukhov, A., Huang, S., Metzger, N., Daudt, R.C., Schindler, K.: Re- purposing diffusion-based image generators for monocular depth estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 9492–9502 (2024)
2024
-
[12]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Kopf, J., Rong, X., Huang, J.B.: Robust consistent video depth estimation. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 1611–1621 (2021)
2021
-
[13]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Kuang, Z., Zhang, T., Zhang, K., Tan, H., Bi, S., Hu, Y., Xu, Z., Hasan, M., Wetzstein, G., Luan, F.: Buffer anytime: Zero-shot video depth and normal from image priors. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 17660–17670 (2025)
2025
-
[14]
arXiv preprint arXiv:2504.07960 (2025)
Li, Z.Y., Du, R., Yan, J., Zhuo, L., Li, Z., Gao, P., Ma, Z., Cheng, M.M.: Vi- sualcloze: A universal image generation framework via visual in-context learning. arXiv preprint arXiv:2504.07960 (2025)
-
[15]
arXiv preprint arXiv:2502.01061 (2025)
Lin, G., Jiang, J., Yang, J., Zheng, Z., Liang, C.: Omnihuman-1: Rethinking the scaling-up of one-stage conditioned human animation models. arXiv preprint arXiv:2502.01061 (2025)
-
[16]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
ACM Transactions on Graphics (ToG)39(4), 71–1 (2020)
Luo, X., Huang, J.B., Szeliski, R., Matzen, K., Kopf, J.: Consistent video depth estimation. ACM Transactions on Graphics (ToG)39(4), 71–1 (2020)
2020
-
[18]
arXiv preprint arXiv:2507.16869 (2025) ICDepth 17
Ma, Y., Feng, K., Hu, Z., Wang, X., Wang, Y., Zheng, M., He, X., Zhu, C., Liu, H., He, Y., et al.: Controllable video generation: A survey. arXiv preprint arXiv:2507.16869 (2025) ICDepth 17
-
[19]
arXiv preprint arXiv:2506.04590 (2025)
Ma, Y., Feng, K., Zhang, X., Liu, H., Zhang, D.J., Xing, J., Zhang, Y., Yang, A., Wang, Z., Chen, Q.: Follow-your-creation: Empowering 4d creation through video inpainting. arXiv preprint arXiv:2506.04590 (2025)
-
[20]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Ma, Y., He, Y., Cun, X., Wang, X., Chen, S., Li, X., Chen, Q.: Follow your pose: Pose-guided text-to-video generation using pose-free videos. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 4117–4125 (2024)
2024
-
[21]
arXiv preprint arXiv:2602.05551 (2026)
Ma, Y., Wang, Z., Ren, T., Zheng, M., Liu, H., Guo, J., Fong, M., Xue, Y., Zhao, Z., Schindler, K., et al.: Fastvmt: Eliminating redundancy in video motion transfer. arXiv preprint arXiv:2602.05551 (2026)
-
[22]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Mayer, N., Ilg, E., Hausser, P., Fischer, P., Cremers, D., Dosovitskiy, A., Brox, T.: A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4040–4048 (2016)
2016
-
[23]
arXiv preprint arXiv:2504.16915 (2025)
Mou, C., Wu, Y., Wu, W., Guo, Z., Zhang, P., Cheng, Y., Luo, Y., Ding, F., Zhang, S., Li, X., et al.: Dreamo: A unified framework for image customization. arXiv preprint arXiv:2504.16915 (2025)
-
[24]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez,P.,Haziza,D.,Massa,F.,El-Nouby,A.,Howes,R.,Huang,P.Y.,Xu,H., Sharma, V., Li, S.W., Galuba, W., Rabbat, M., Assran, M., Ballas, N., Synnaeve, G., Misra, I., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual features without ...
2023
-
[25]
1-Fun-1.3B-Control(2024)
PAI, A.: Wan2.1-fun-1.3b-control.https://huggingface.co/alibaba-pai/Wan2. 1-Fun-1.3B-Control(2024)
2024
-
[26]
In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Palazzolo, E., Behley, J., Lottes, P., Giguere, P., Stachniss, C.: Refusion: 3d recon- struction in dynamic environments for rgb-d cameras exploiting residuals. In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 7855–7862. IEEE (2019)
2019
-
[27]
arXiv preprint arXiv:2505.10696 (2025)
Patel, M., Yang, F., Qiu, Y., Cadena, C., Scherer, S., Hutter, M., Wang, W.: Tartanground: A large-scale dataset for ground robot perception and navigation. arXiv preprint arXiv:2505.10696 (2025)
-
[28]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[29]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Shao, J., Yang, Y., Zhou, H., Zhang, Y., Shen, Y., Guizilini, V., Wang, Y., Poggi, M., Liao, Y.: Learning temporally consistent video depth from video diffusion pri- ors. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22841–22852 (2025)
2025
-
[30]
arXiv preprint arXiv:2504.15009 (2025)
Song, W., Jiang, H., Yang, Z., Quan, R., Yang, Y.: Insert anything: Image insertion via in-context editing in dit. arXiv preprint arXiv:2504.15009 (2025)
-
[31]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Tan, Z., Liu, S., Yang, X., Xue, Q., Wang, X.: Ominicontrol: Minimal and universal control for diffusion transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14940–14950 (2025)
2025
-
[32]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team, Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Wang, W., Zhu, D., Wang, X., Hu, Y., Qiu, Y., Wang, C., Hu, Y., Kapoor, A., Scherer, S.: Tartanair: A dataset to push the limits of visual slam. In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 4909–4916. IEEE (2020)
2020
-
[34]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, Y., Shi, M., Li, J., Huang, Z., Cao, Z., Zhang, J., Xian, K., Lin, G.: Neural video depth stabilizer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9466–9476 (2023) 18 X. He et al
2023
-
[35]
arXiv preprint arXiv:2504.02160 (2025)
Wu, S., Huang, M., Wu, W., Cheng, Y., Ding, F., He, Q.: Less-to-more gener- alization: Unlocking more controllability by in-context generation. arXiv preprint arXiv:2504.02160 (2025)
-
[36]
In: International Conference on Learning Representations
Yang, H., Huang, D., Yin, W., Shen, C., Liu, H., He, X., Lin, B., Ouyang, W., He, T.: Depth any video with scalable synthetic data. In: International Conference on Learning Representations. vol. 2025, pp. 97335–97349 (2025)
2025
-
[37]
Advances in Neural Information Processing Systems37, 21875–21911 (2024)
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. Advances in Neural Information Processing Systems37, 21875–21911 (2024)
2024
-
[38]
arXiv preprint arXiv:2506.04216 (2025)
Ye, Z., He, X., Liu, Q., Wang, Q., Wang, X., Wan, P., Zhang, D., Gai, K., Chen, Q., Luo, W.: Unic: Unified in-context video editing. arXiv preprint arXiv:2506.04216 (2025)
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yeshwanth, C., Liu, Y.C., Nießner, M., Dai, A.: Scannet++: A high-fidelity dataset of 3d indoor scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12–22 (2023)
2023
-
[40]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, H., Shen, C., Li, Y., Cao, Y., Liu, Y., Yan, Y.: Exploiting temporal con- sistency for real-time video depth estimation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1725–1734 (2019)
2019
-
[41]
ACM Transactions on Graphics (ToG)40(4), 1–12 (2021)
Zhang, Z., Cole, F., Tucker, R., Freeman, W.T., Dekel, T.: Consistent depth of moving objects in video. ACM Transactions on Graphics (ToG)40(4), 1–12 (2021)
2021
-
[42]
arXiv preprint arXiv:2509.12201 (2025)
Zhou, Y., Wang, Y., Zhou, J., Chang, W., Guo, H., Li, Z., Ma, K., Li, X., Wang, Y., Zhu, H., et al.: Omniworld: A multi-domain and multi-modal dataset for 4d world modeling. arXiv preprint arXiv:2509.12201 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.