SCAPE: Accurate and Efficient LLM Training with Extreme Sparse Communication
Pith reviewed 2026-07-03 17:55 UTC · model grok-4.3
The pith
SCAPE enables 99% sparse communication in LLM training by deriving masks from stable first-moment statistics instead of raw gradients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
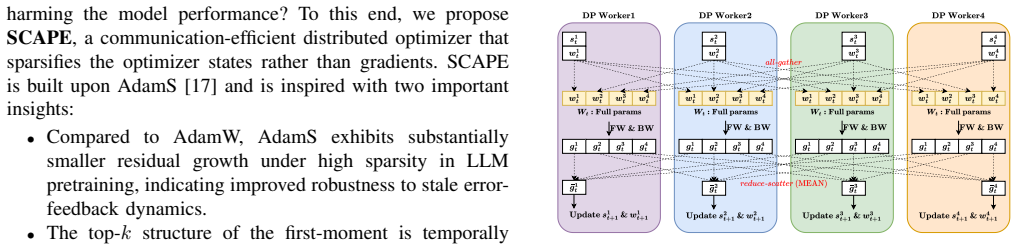
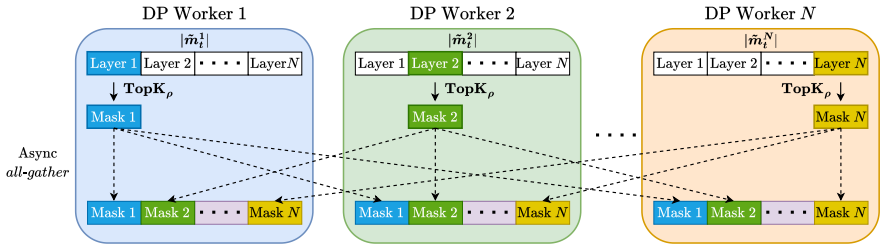
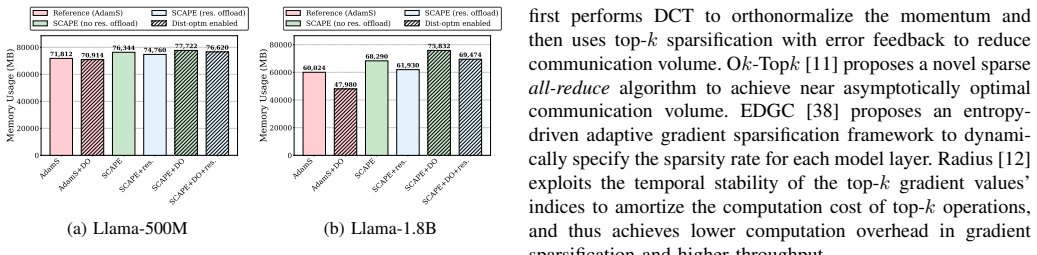
SCAPE derives communication masks from first-moment-based statistics, partitions mask generation across workers to align with sharding, delays mask usage by one step to overlap synchronization with computation, and reconstructs the quantities needed for second-moment updates from a single synchronized sparse buffer.
What carries the argument
first-moment-based mask construction with partitioned generation, one-step delay, and single-buffer second-moment reconstruction
If this is right
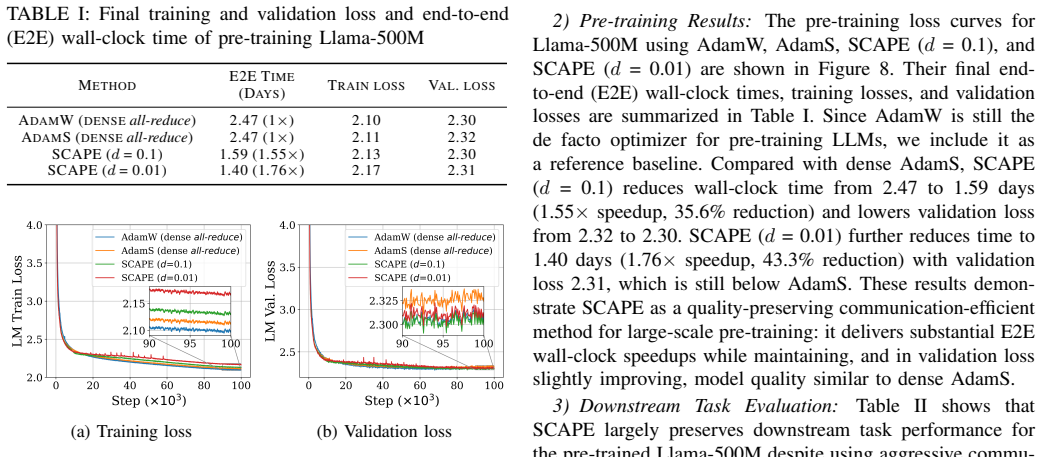
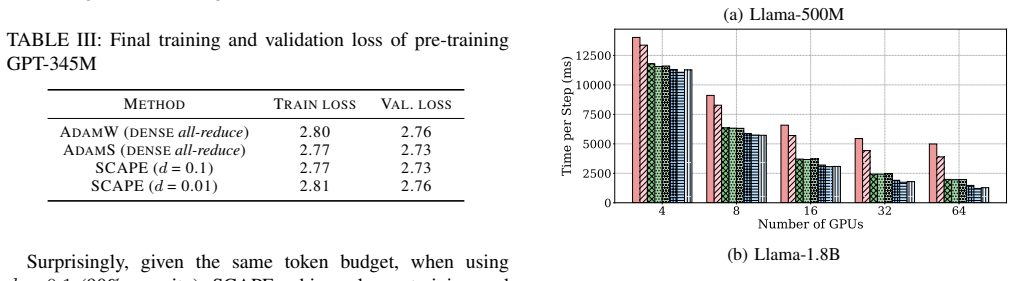
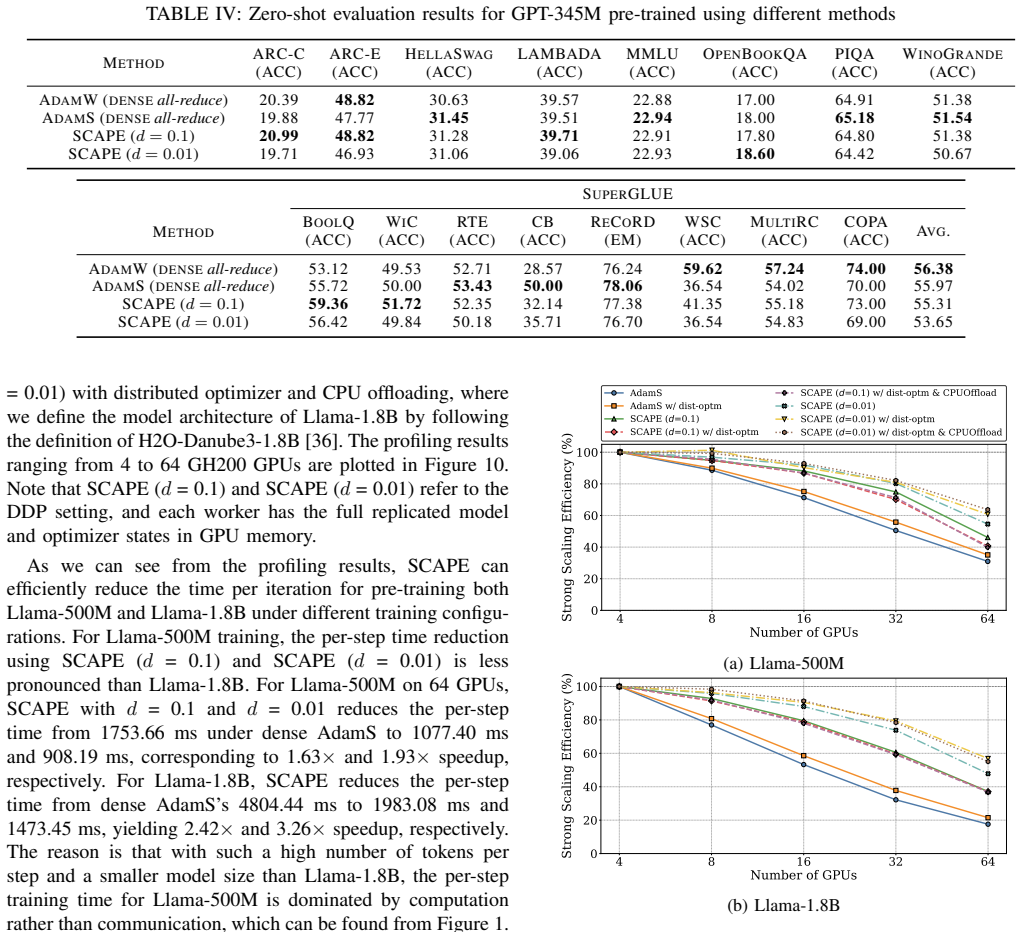
- End-to-end wall-clock time for Llama-500M pre-training drops by up to 43.3% at 99% sparsity while matching dense model quality.
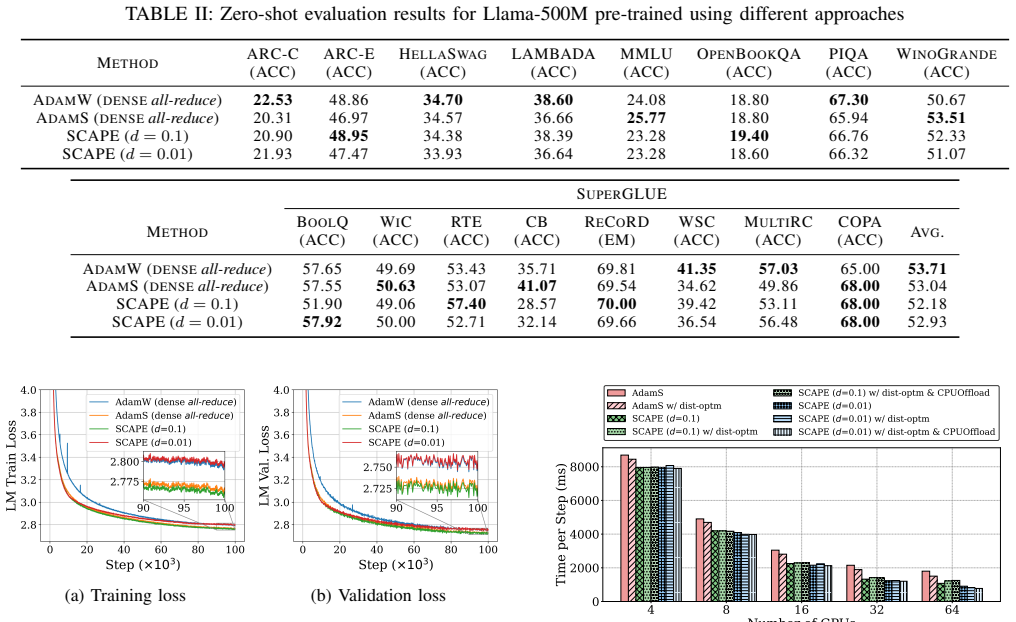
- Validation loss curves and downstream task accuracy remain comparable to dense AdamW and AdamS at both 90% and 99% sparsity.
- Per-step speedup reaches 3.26 times versus dense AdamS for Llama-1.8B under the same hardware setup.
- Communication volume falls enough to support larger data-parallel degrees without proportional increases in network traffic.
Where Pith is reading between the lines
- The same first-moment masking logic could apply to other momentum-based optimizers that maintain stable first moments.
- Reduced communication at 99% sparsity might allow equivalent training on clusters with lower-bandwidth interconnects.
- If first moments stay informative at extreme sparsity, the approach may generalize to even larger models where communication dominates runtime.
Load-bearing premise
The first-moment statistics remain sufficiently stable to produce effective communication masks at 99% sparsity without degrading convergence for Adam-style optimizers.
What would settle it
Pre-training Llama-500M with SCAPE at 99% sparsity that produces measurably higher validation loss than a dense AdamS baseline after identical steps would show the method does not preserve quality.
Figures

read the original abstract
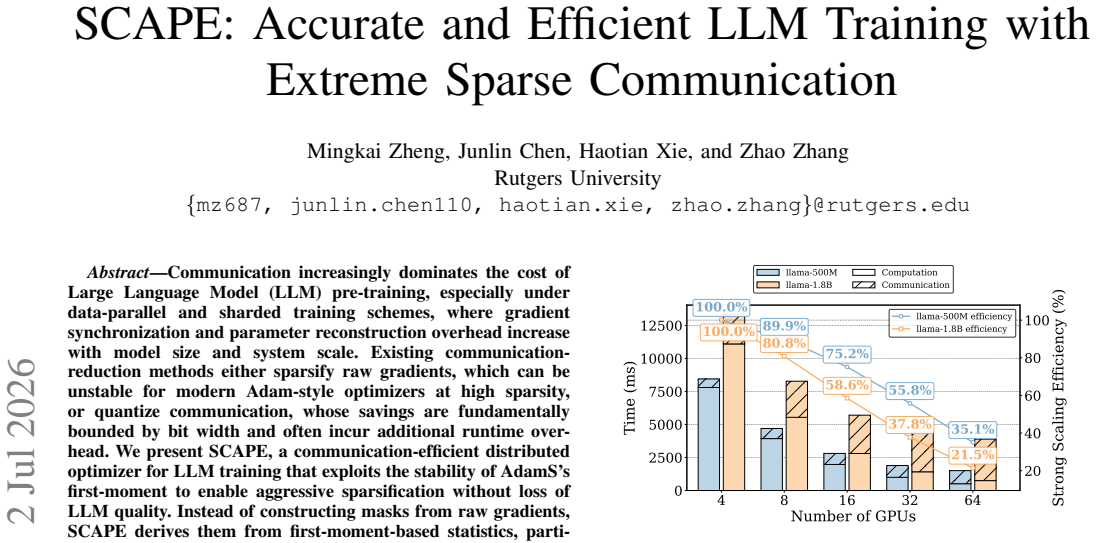
Communication increasingly dominates the cost of Large Language Model (LLM) pre-training, especially under data-parallel and sharded training schemes, where gradient synchronization and parameter reconstruction overhead increase with model size and system scale. Existing communication-reduction methods either sparsify raw gradients, which can be unstable for modern Adam-style optimizers at high sparsity, or quantize communication, whose savings are fundamentally bounded by bit width and often incur additional runtime overhead. We present SCAPE, a communication-efficient distributed optimizer for LLM training that exploits the stability of AdamS's first-moment to enable aggressive sparsification without loss of LLM quality. Instead of constructing masks from raw gradients, SCAPE derives them from first-moment-based statistics, partitions mask generation across workers to align with optimizer sharding, and delays mask usage by one step so that mask synchronization can overlap with computation. SCAPE also reconstructs the quantities required for second-moment updates from a single synchronized sparse buffer, avoiding an additional collective. We implement SCAPE in Megatron-LM and evaluate its convergence by pre-training GPT-345M on OpenWebText and Llama-500M on SlimPajama-6B using 32 NVIDIA GH200 GPUs on TACC Vista. In both models, SCAPE preserves training stability, validation loss, and downstream task accuracy under 90\% and 99\% sparsity. For Llama-500M, SCAPE reduces end-to-end pre-training wall-clock time by up to 43.3\% while maintaining model quality comparable to dense AdamW and AdamS. For Llama-1.8B, SCAPE achieves up to 3.26$\times$ speedup per step compared to dense AdamS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SCAPE, a communication-efficient distributed optimizer for LLM pre-training. It derives communication masks from AdamS first-moment statistics rather than raw gradients, partitions mask generation across workers, delays mask application by one step to overlap with computation, and reconstructs second-moment quantities from a single sparse buffer. Experiments pre-train GPT-345M on OpenWebText and Llama-500M on SlimPajama-6B at 90% and 99% sparsity using 32 GH200 GPUs, reporting preserved validation loss, training stability, and downstream accuracy comparable to dense AdamW and AdamS, with up to 43.3% wall-clock reduction for Llama-500M and 3.26× per-step speedup for Llama-1.8B.
Significance. If the quality preservation holds, SCAPE would meaningfully reduce communication bottlenecks in data-parallel and sharded LLM training at extreme sparsity levels. The concrete speedups on production-scale hardware (Megatron-LM implementation) and evaluation on downstream tasks for two model sizes constitute practical evidence. The engineering choices—sharded mask generation and single-buffer reconstruction—are clear strengths that avoid additional collectives.
major comments (3)
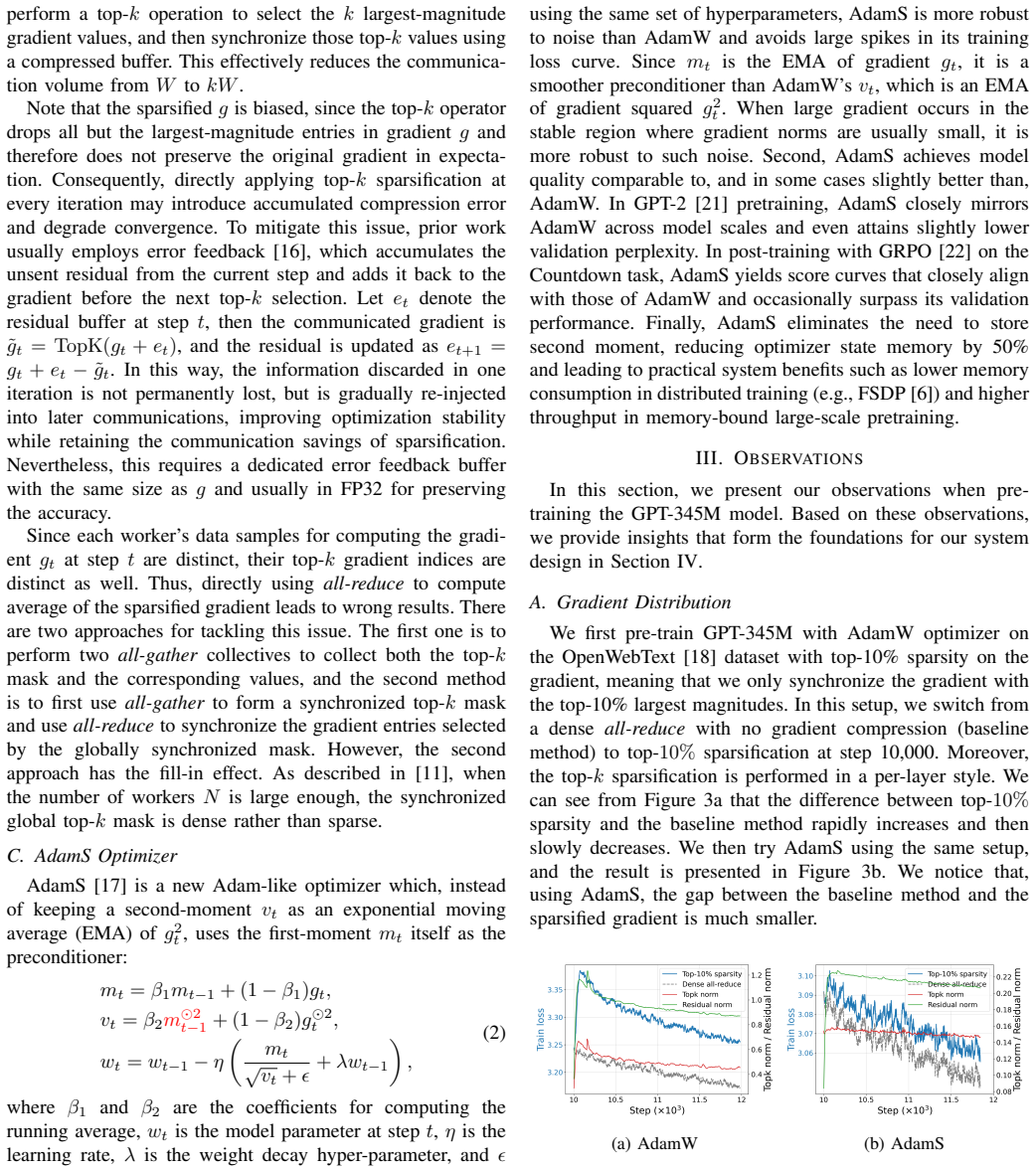
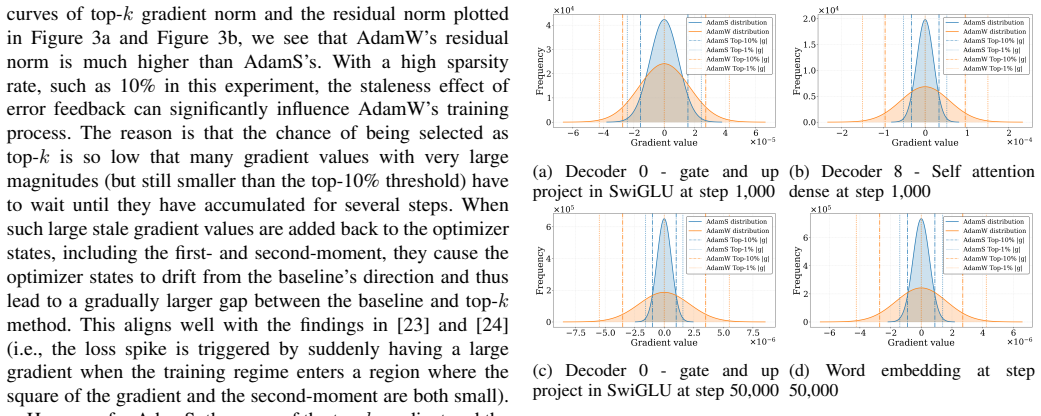
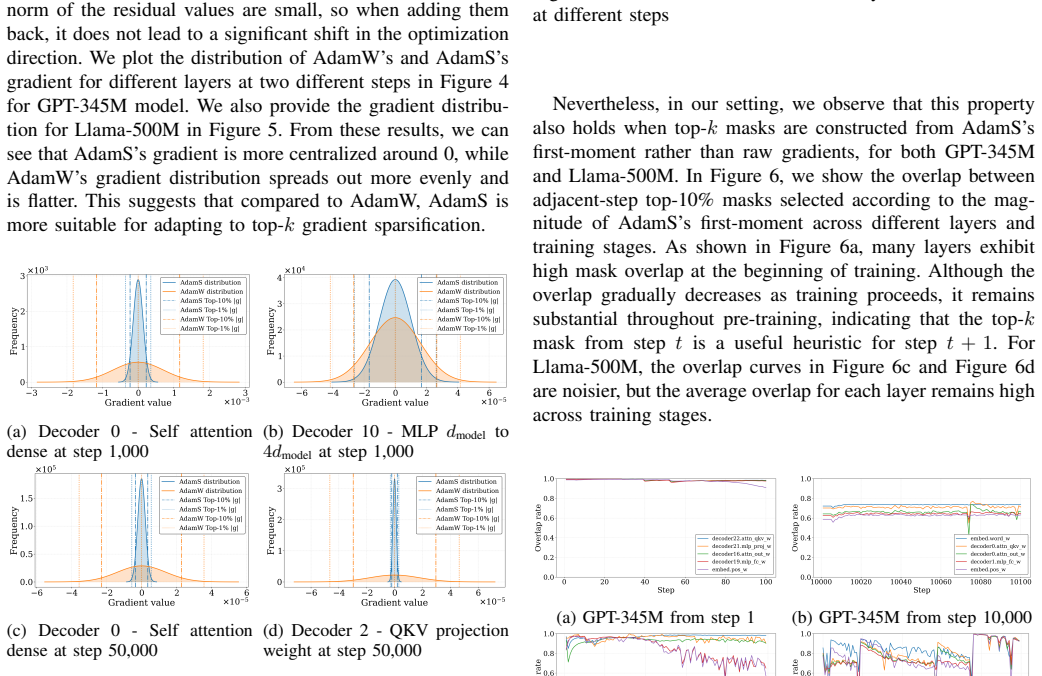
- [§3.2] §3.2 (first-moment mask construction): the central claim that first-moment statistics remain a faithful proxy for gradient importance at 99% sparsity lacks any analytic bound, sensitivity analysis, or ablation showing that the surviving non-zero entries continue to identify critical update directions once 99% of the vector is zeroed; this assumption directly underpins the reported preservation of validation loss and downstream accuracy.
- [§4.2–4.3] §4.2–4.3 (Llama-500M 99% sparsity runs): the equivalence in validation loss and downstream accuracy is reported without error bars, multiple random seeds, or statistical tests, leaving open whether observed differences fall within run-to-run variance; this weakens verification of the no-degradation claim at the highest sparsity level.
- [§3.3] §3.3 (single-buffer second-moment reconstruction): the propagation of any mask error from the delayed first-moment into the reconstructed second-moment state is not quantified, yet this step is load-bearing for optimizer state fidelity at 99% sparsity.
minor comments (2)
- [Abstract] The abstract states results for Llama-1.8B but the experimental section focuses on 345M/500M models; clarify the scale at which the 3.26× per-step figure was measured.
- [Figures/Tables] Figure captions and tables would benefit from explicit mention of the number of runs and any variance measures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (first-moment mask construction): the central claim that first-moment statistics remain a faithful proxy for gradient importance at 99% sparsity lacks any analytic bound, sensitivity analysis, or ablation showing that the surviving non-zero entries continue to identify critical update directions once 99% of the vector is zeroed; this assumption directly underpins the reported preservation of validation loss and downstream accuracy.
Authors: We acknowledge the absence of an analytic bound. The manuscript relies on empirical validation across GPT-345M and Llama-500M at 90% and 99% sparsity, showing preserved validation loss and downstream accuracy. In revision we will add sensitivity analysis and targeted ablations on mask construction at 99% sparsity to better characterize the surviving entries. revision: partial
-
Referee: [§4.2–4.3] §4.2–4.3 (Llama-500M 99% sparsity runs): the equivalence in validation loss and downstream accuracy is reported without error bars, multiple random seeds, or statistical tests, leaving open whether observed differences fall within run-to-run variance; this weakens verification of the no-degradation claim at the highest sparsity level.
Authors: We agree that multiple seeds and error bars would improve statistical rigor. The reported results used single runs due to resource limits on 32 GH200 GPUs. We will rerun the Llama-500M 99% sparsity experiments with at least three seeds, add error bars, and include basic statistical comparison in the revised manuscript. revision: yes
-
Referee: [§3.3] §3.3 (single-buffer second-moment reconstruction): the propagation of any mask error from the delayed first-moment into the reconstructed second-moment state is not quantified, yet this step is load-bearing for optimizer state fidelity at 99% sparsity.
Authors: We will add an analysis quantifying the effect of delayed mask errors on the reconstructed second-moment quantities, including a simple error-propagation bound or empirical measurement at 99% sparsity, to be included in §3.3 or an appendix. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an algorithmic construction (masks from first-moment statistics, one-step delay, single-buffer reconstruction) and validates it through direct empirical measurement of wall-clock time, validation loss, and downstream accuracy on held-out pre-training runs. No equations, predictions, or uniqueness claims reduce the reported outcomes to quantities fitted inside the paper or to self-citations; the central results are externally falsifiable experimental measurements rather than tautological re-expressions of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption First-moment statistics from AdamS remain stable enough to generate effective communication masks at 99% sparsity without convergence degradation
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.00157 , year=
J. Ahn, R. Verma, R. Lou, D. Liu, R. Zhang, and W. Yin, “Large language models for mathematical reasoning: Progresses and challenges,” 2024. [Online]. Available: https://arxiv.org/abs/2402.00157
-
[2]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,” 2021. [Online]. Available: https://arxiv.org/abs/2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
An autonomous laboratory for the accelerated synthesis of inorganic materials,
N. J. Szymanski, B. Rendy, Y . Fei, R. E. Kumar, T. He, D. Milsted, M. J. McDermott, M. Gallant, E. D. Cubuk, A. Merchant, H. Kim, A. Jain, C. J. Bartel, K. Persson, Y . Zeng, and G. Ceder, “An autonomous laboratory for the accelerated synthesis of inorganic materials,”Nature, vol. 624, no. 7990, pp. 86–91, 2023. [Online]. Available: https://doi.org/10.10...
-
[4]
Decoupled Weight Decay Regularization,
I. Loshchilov and F. Hutter, “Decoupled Weight Decay Regularization,”
-
[5]
Decoupled Weight Decay Regularization
[Online]. Available: https://arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He, “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models,” 2020. [Online]. Available: https://arxiv.org/abs/1910.02054
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel,
Y . Zhao, A. Gu, R. Varma, L. Luo, C.-C. Huang, M. Xu, L. Wright, H. Shojanazeri, M. Ott, S. Shleifer, A. Desmaison, C. Balioglu, P. Damania, B. Nguyen, G. Chauhan, Y . Hao, A. Mathews, and S. Li, “PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel,”
-
[8]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
[Online]. Available: https://arxiv.org/abs/2304.11277
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Megatron-lm,
NVIDIA, “Megatron-lm,” 2026. [Online]. Available: https://github.com/ NVIDIA/Megatron-LM
2026
-
[10]
Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training,
Y . Lin, S. Han, H. Mao, Y . Wang, and W. J. Dally, “Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training,” 2020. [Online]. Available: https://arxiv.org/abs/1712.01887
-
[11]
DeMo: Decoupled Momentum Optimization,
B. Peng, L. Chen, B. Su, J. Quesnelle, D. P. Kingma, and Q. Liu, “DeMo: Decoupled Momentum Optimization,” 2026. [Online]. Available: https://arxiv.org/abs/2411.19870
-
[13]
Near-optimal sparse allreduce for distributed deep learning,
S. Li and T. Hoefler, “Near-optimal sparse allreduce for distributed deep learning,” inProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. ACM, mar
-
[14]
Available: https://doi.org/10.1145/3503221.3508399
[Online]. Available: https://doi.org/10.1145/3503221.3508399
-
[15]
Radius: Range-based Gradient Sparsity for Large Foundation Model Pre-training,
M. Zheng and Z. Zhang, “Radius: Range-based Gradient Sparsity for Large Foundation Model Pre-training,” in Proceedings of Machine Learning and Systems, M. Zaharia, G. Joshi, and Y . Lin, Eds., vol. 7. MLSys, 2025. [Online]. Available: https://proceedings.mlsys.org/paper files/paper/ 2025/file/54dd9e0cff6d9214e20d97eb2a3bae49-Paper-Conference.pdf
2025
-
[16]
Quantized Distributed Training of Large Models with Convergence Guarantees,
I. Markov, A. Vladu, Q. Guo, and D. Alistarh, “Quantized Distributed Training of Large Models with Convergence Guarantees,” 2023. [Online]. Available: https://arxiv.org/abs/2302.02390
-
[17]
ZeRO++: Extremely Efficient Collective Communication for Giant Model Training,
G. Wang, H. Qin, S. A. Jacobs, C. Holmes, S. Rajbhandari, O. Ruwase, F. Yan, L. Yang, and Y . He, “ZeRO++: Extremely Efficient Collective Communication for Giant Model Training,” 2023. [Online]. Available: https://arxiv.org/abs/2306.10209
-
[18]
SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training,
J. Jia, C. Xie, H. Lu, D. Wang, H. Feng, C. Zhang, B. Sun, H. Lin, Z. Zhang, X. Liu, and D. Tao, “SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training,” 2024. [Online]. Available: https://arxiv.org/abs/2410.15526
-
[19]
S. U. Stich, J.-B. Cordonnier, and M. Jaggi, “Sparsified SGD with Memory,” 2018. [Online]. Available: https://arxiv.org/abs/1809.07599
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
AdamS: Momentum Itself Can Be A Normalizer for LLM Pretraining and Post-training,
H. Zhang, B. Wang, and L. Chen, “AdamS: Momentum Itself Can Be A Normalizer for LLM Pretraining and Post-training,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, Eds. Suzhou, China: Association for Computational Linguistics, Nov. 2025, pp. 10 719–10 7...
-
[21]
A. Gokaslan, V . Cohen, E. Pavlick, and S. Tellex, “OpenWebText Cor- pus,” http://Skylion007.github.io/OpenWebTextCorpus, 2019. [Online]. Available: https://doi.org/10.5281/zenodo.3834942
-
[22]
SlimPajama: A 627B token cleaned and deduplicated version of RedPajama,
D. Soboleva, F. Al-Khateeb, R. Myers, J. R. Steeves, J. Hestness, and N. Dey, “SlimPajama: A 627B token cleaned and deduplicated version of RedPajama,” 2023. [Online]. Available: https://huggingface. co/datasets/cerebras/SlimPajama-627B
2023
-
[23]
Adam: A Method for Stochastic Optimization,
D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,”
-
[24]
Adam: A Method for Stochastic Optimization
[Online]. Available: https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Language Models are Unsupervised Multitask Learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language Models are Unsupervised Multitask Learners,” 2019
2019
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . Wu, and D. Guo, “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models,” 2024. [Online]. Available: https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
A Theory on Adam Instability in Large-Scale Machine Learning,
I. Molybog, P. Albert, M. Chen, Z. DeVito, D. Esiobu, N. Goyal, P. S. Koura, S. Narang, A. Poulton, R. Silva, B. Tang, D. Liskovich, P. Xu, Y . Zhang, M. Kambadur, S. Roller, and S. Zhang, “A Theory on Adam Instability in Large-Scale Machine Learning,” 2023. [Online]. Available: https://arxiv.org/abs/2304.09871
-
[28]
Adaptive preconditioners trigger loss spikes in adam,
Z. Bai, Z. Zhou, J. Zhao, X. Li, Z. Li, F. Xiong, H. Yang, Y . Zhang, and Z.-Q. J. Xu, “Adaptive preconditioners trigger loss spikes in adam,”
-
[29]
Adaptive Preconditioners Trigger Loss Spikes in Adam
[Online]. Available: https://arxiv.org/abs/2506.04805
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
A Stochastic Approximation Method,
H. Robbins and S. Monro, “A Stochastic Approximation Method,”The Annals of Mathematical Statistics, vol. 22, no. 3, pp. 400–407, 1951. [Online]. Available: https://doi.org/10.1214/aoms/1177729586
-
[31]
Performance Analysis of Scientific Applications on an NVIDIA Grace System,
A. Ruhela, J. Cazes, J. D. McCalpin, C. Del-Castillo-Negrete, J. Li, H. Liu, H. Chen, C.-Y . Lu, K. F. Milfeld, W. Zhang, I. Wang, L. Koesterke, J. DeSantis, N. Lewis, S. Hempel, and D. Stanzione, “Performance Analysis of Scientific Applications on an NVIDIA Grace System,” inSC24-W: Workshops of the International Conference for High Performance Computing,...
-
[32]
2024 , month = jul, publisher =
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac’h, H. Li, K. McDonell, N. Muennighoff, C. Ociepa, J. Phang, L. Reynolds, H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou, “The Language Model Evaluation Harness,” 07 2024. [Online]. Available: https://doi.org/10.52...
-
[33]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord, “Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge,” 2018. [Online]. Available: https://arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
The LAMBADA dataset: Word prediction requiring a broad discourse context
D. Paperno, G. Kruszewski, A. Lazaridou, Q. N. Pham, R. Bernardi, S. Pezzelle, M. Baroni, G. Boleda, and R. Fern ´andez, “The LAMBADA dataset: Word prediction requiring a broad discourse context,” 2016. [Online]. Available: https://arxiv.org/abs/1606.06031
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
HellaSwag: Can a Machine Really Finish Your Sentence?
R. Zellers, A. Holtzman, Y . Bisk, A. Farhadi, and Y . Choi, “HellaSwag: Can a Machine Really Finish Your Sentence?” 2019. [Online]. Available: https://arxiv.org/abs/1905.07830
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[36]
Measuring Massive Multitask Language Understanding,
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring Massive Multitask Language Understanding,”
-
[37]
Measuring Massive Multitask Language Understanding
[Online]. Available: https://arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[38]
PIQA: Reasoning about Physical Commonsense in Natural Language
Y . Bisk, R. Zellers, R. L. Bras, J. Gao, and Y . Choi, “PIQA: Reasoning about Physical Commonsense in Natural Language,” 2019. [Online]. Available: https://arxiv.org/abs/1911.11641
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[39]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale,
K. Sakaguchi, R. Le Bras, C. Bhagavatula, and Y . Choi, “WinoGrande: An Adversarial Winograd Schema Challenge at Scale,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 05, 2020, pp. 8732–8740. [Online]. Available: https://doi.org/10.1609/aaai. v34i05.6399
-
[40]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering,
T. Mihaylov, P. Clark, T. Khot, and A. Sabharwal, “Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2018, pp. 2381–2391. [Online]. Available: https://doi.org/10.18653/v1/D18-1260
-
[41]
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
A. Wang, Y . Pruksachatkun, N. Nangia, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “Superglue: A stickier benchmark for general-purpose language understanding systems,” 2020. [Online]. Available: https://arxiv.org/abs/1905.00537
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[42]
P. Pfeiffer, P. Singer, Y . Babakhin, G. Fodor, N. Dhankhar, and S. S. Ambati, “H2O-Danube3 Technical Report,” 2024. [Online]. Available: https://arxiv.org/abs/2407.09276
-
[43]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V . Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V . Kerkez, M. Khabsa, I. Kloumann, A. Koren...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
EDGC: Entropy-driven Dynamic Gradient Compression for Efficient LLM Training,
Q. Yi, J. Duan, H. Hu, Q. Hua, H. Zhao, S. Qian, D. Yang, J. Cao, J. Tang, Y . Yu, C. Liao, K. Wang, and L. Zhang, “EDGC: Entropy-driven Dynamic Gradient Compression for Efficient LLM Training,” 2025. [Online]. Available: https://arxiv.org/abs/2511.10333
-
[45]
ATOMO: Communication-efficient Learning via Atomic Sparsification
H. Wang, S. Sievert, Z. Charles, S. Liu, S. Wright, and D. Papailiopoulos, “ATOMO: Communication-efficient Learning via Atomic Sparsification,” 2018. [Online]. Available: https: //arxiv.org/abs/1806.04090
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[46]
PowerSGD: Practical Low-Rank Gradient Compression for Distributed Optimization,
T. V ogels, S. P. Karimireddy, and M. Jaggi, “PowerSGD: Practical Low-Rank Gradient Compression for Distributed Optimization,” 2020. [Online]. Available: https://arxiv.org/abs/1905.13727
-
[47]
Optimus-CC: Efficient Large NLP Model Training with 3D Parallelism Aware Communication Compression,
J. Song, J. Yim, J. Jung, H. Jang, H.-J. Kim, Y . Kim, and J. Lee, “Optimus-CC: Efficient Large NLP Model Training with 3D Parallelism Aware Communication Compression,” 2023. [Online]. Available: https://arxiv.org/abs/2301.09830
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.