Model Merging as Probabilistic Inference in Fine-Tuning Parameter Space
Pith reviewed 2026-07-03 17:49 UTC · model grok-4.3
The pith
Model merging is recast as probabilistic inference over fine-tuning parameters using a product-of-experts model with Cauchy experts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
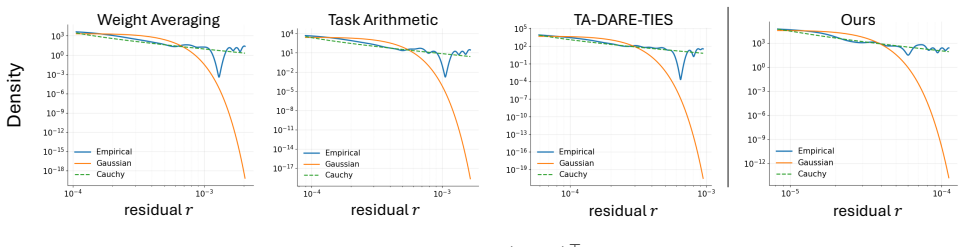
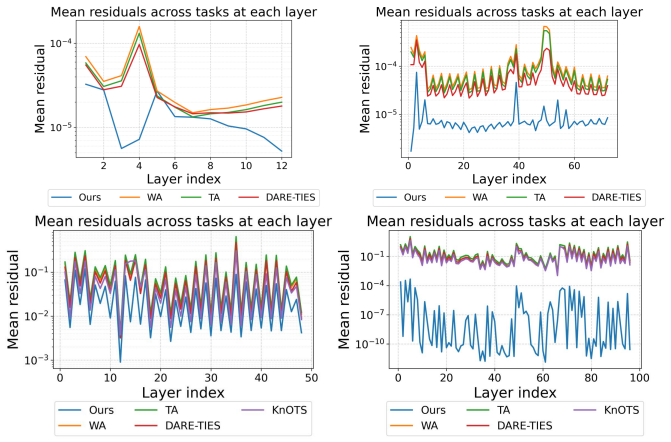
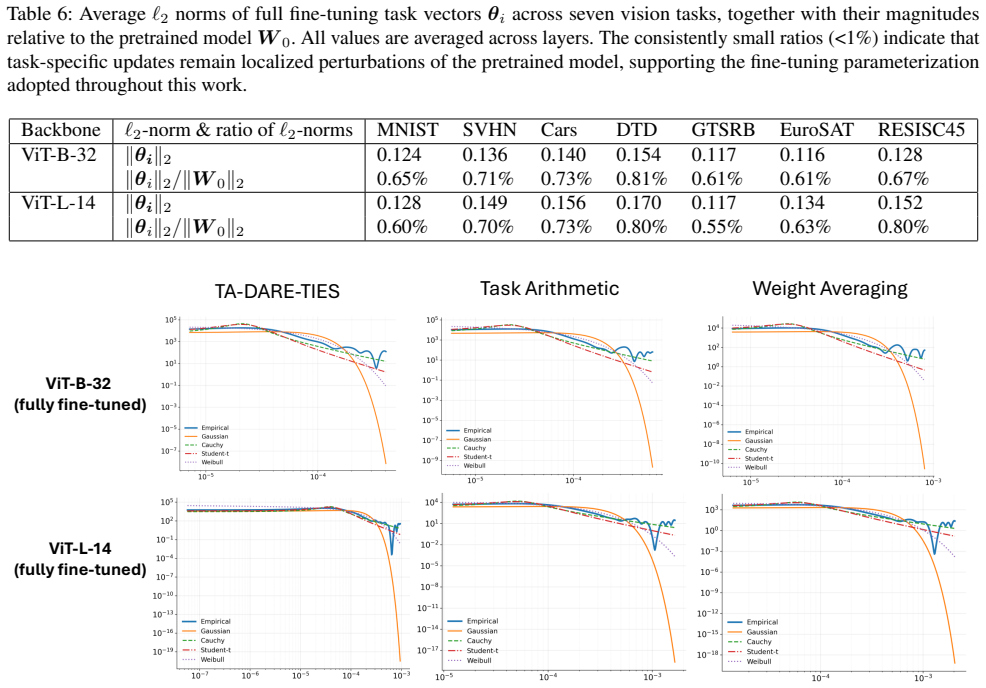
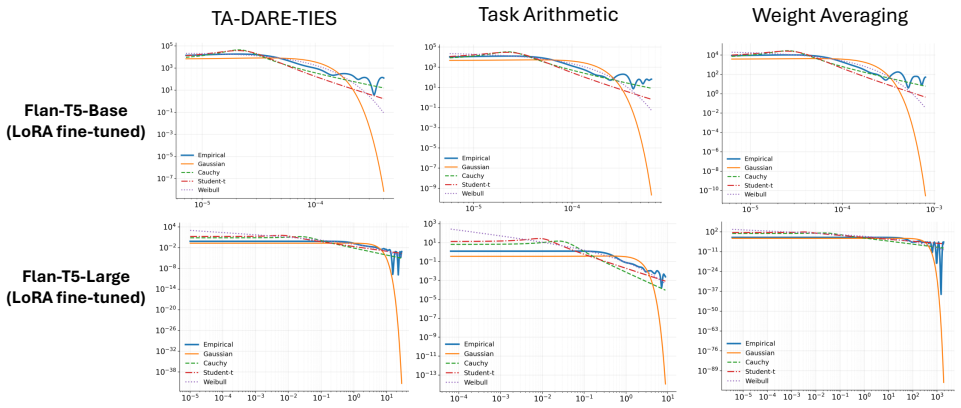
Model merging is formulated as maximum a posteriori inference under a product-of-experts energy model in which each task-specific fine-tuned solution defines an expert over the merged parameter vector. Several prior merging algorithms are recovered exactly when the experts are given Gaussian energy functions; the paper shows that the empirical residuals violate this light-tailed assumption and replaces the experts with Cauchy energies, which admit closed-form or convergent inference while matching the observed tail behavior.
What carries the argument
Product-of-experts (PoE) energy-based model over merged parameters, with each task-specific solution supplying one expert; the switch from Gaussian to Cauchy experts is the central design choice.
If this is right
- Any geometric merging rule that can be written as the mode of a Gaussian PoE is a special case of the new framework.
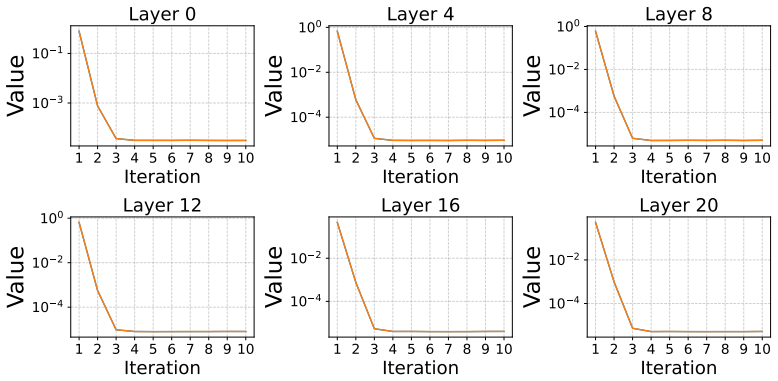
- Inference under the Cauchy PoE can be performed with a provably convergent procedure without requiring additional task data.
- Performance gains appear across multiple architectures and task combinations when the heavy-tailed design is used.
- The framework supplies a statistical criterion for weighting or selecting which task updates to include during merging.
Where Pith is reading between the lines
- The same PoE perspective could be applied to other parameter-space operations such as continual learning or federated averaging.
- If residuals remain heavy-tailed after scaling or normalization, similar Cauchy designs might improve other inference tasks in high-dimensional parameter spaces.
- The approach opens a route to hybrid merging that mixes Gaussian and Cauchy experts depending on observed residual statistics per layer or task.
Load-bearing premise
The directional residuals between a merged model and the individual task-specific models are heavy-tailed rather than light-tailed.
What would settle it
An experiment that measures the tail index of residuals on a new set of fine-tuned models and finds them consistently light-tailed, or that shows the Cauchy-based merging procedure failing to outperform Gaussian baselines on held-out tasks.
Figures
read the original abstract
Model merging aims to combine existing single-task solutions into a multi-task solution without additional data-driven fine-tuning.~Most existing approaches achieve this using geometric properties of local solution spaces. However, such geometric views provide limited guidance for scoring how statistically useful each task-specific update direction is across tasks during merging. To address this, we formulate model merging from a new perspective of probabilistic inference under a product-of-experts (PoE) scenario where each single-task solution defines an energy-based expert model (EBM) over the merged parameters. We show that several existing model merging methods arise as special cases of our framework under energy designs that impose implicit Gaussian assumptions on directional residuals between merged and task-specific models. Empirically, we find that these residuals are often heavy-tailed which exposes a mismatch with the imposed light-tailed Gaussian structures. We address this with a heavy-tailed PoE design based on Cauchy experts, which better captures the observed residual behavior while admitting a provably convergent inference procedure. Experiments across multiple tasks and architectures show significant improvements over state-of-the-arts baselines. Our code is available at https://github.com/MinhLong210/PoE-EBM-Merging.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates model merging as probabilistic inference under a product-of-experts (PoE) model in which each task-specific fine-tuned solution defines an energy-based expert over the merged parameters. It shows that existing merging methods arise as special cases under energy designs that implicitly assume Gaussian distributions on directional residuals. The authors report that these residuals are empirically heavy-tailed, motivating a Cauchy-expert PoE design that matches the observed behavior and admits a provably convergent inference procedure. Experiments across tasks and architectures demonstrate improvements over baselines, with code released.
Significance. If the central claims hold, the work supplies a unifying probabilistic lens on model merging and a concrete alternative to Gaussian-based methods. The explicit release of code at the provided GitHub repository is a clear strength that supports reproducibility and follow-up work. The framework could guide future designs that respect statistical properties of fine-tuning parameter spaces.
major comments (2)
- [Empirical residual analysis] The heavy-tailed residual observation (abstract and the empirical analysis section) is load-bearing for the justification of the Cauchy design. The paper should demonstrate that this property is robust rather than an artifact of the chosen tasks, architectures, or residual definitions, for example by reporting tail indices or QQ-plot statistics across at least two additional model scales or fine-tuning regimes not used in the main experiments.
- [Inference procedure] The claim of a 'provably convergent inference procedure' for the Cauchy PoE (inference section) is central to the method's practicality. The manuscript should state the precise convergence conditions or rate and include a direct comparison (e.g., iteration counts or stability metrics) against the Gaussian baseline in the experimental tables to show the practical benefit.
minor comments (2)
- The phrase 'state-of-the-arts baselines' in the abstract should read 'state-of-the-art baselines'.
- [Experiments] Table captions and axis labels in the experimental figures would benefit from explicit mention of the number of random seeds or runs used to compute reported means.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Empirical residual analysis] The heavy-tailed residual observation (abstract and the empirical analysis section) is load-bearing for the justification of the Cauchy design. The paper should demonstrate that this property is robust rather than an artifact of the chosen tasks, architectures, or residual definitions, for example by reporting tail indices or QQ-plot statistics across at least two additional model scales or fine-tuning regimes not used in the main experiments.
Authors: We agree that additional checks would strengthen the justification. In the revised manuscript we will extend the residual analysis to at least two further model scales and fine-tuning regimes outside the current experimental set, reporting tail indices and QQ-plot statistics to confirm robustness of the heavy-tailed observation. revision: yes
-
Referee: [Inference procedure] The claim of a 'provably convergent inference procedure' for the Cauchy PoE (inference section) is central to the method's practicality. The manuscript should state the precise convergence conditions or rate and include a direct comparison (e.g., iteration counts or stability metrics) against the Gaussian baseline in the experimental tables to show the practical benefit.
Authors: We will revise the inference section to state the precise convergence conditions and rates for the Cauchy PoE procedure. We will also augment the experimental tables with iteration counts and stability metrics comparing the Cauchy and Gaussian baselines to illustrate the practical advantage. revision: yes
Circularity Check
No circularity; derivation follows from standard PoE inference and external empirical observation
full rationale
The paper starts from the standard product-of-experts formulation over energy-based models on merged parameters, derives existing merging methods as special cases under Gaussian residual assumptions via explicit energy designs, and then introduces Cauchy experts after reporting an independent empirical finding that residuals are heavy-tailed. None of these steps reduce by construction to fitted parameters, self-definitions, or self-citation chains; the heavy-tailed premise is presented as data-driven evidence external to the formal derivation. The framework remains self-contained against external benchmarks with no load-bearing reductions to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Model merging can be viewed as probabilistic inference in a product-of-experts scenario over fine-tuning parameter space
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
Neural Information Processing Systems , year=
Statistical Model Aggregation via Parameter Matching , author=. Neural Information Processing Systems , year=
-
[3]
Proceedings of the 36th International Conference on Machine Learning , series =
Collective Model Fusion for Multiple Black-Box Experts , author =. Proceedings of the 36th International Conference on Machine Learning , series =
-
[4]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume =
Few-Shot Learning via Repurposing Ensemble of Black-Box Models , author =. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume =
-
[5]
Proceedings of the 37th International Conference on Machine Learning , pages =
Learning Task-Agnostic Embedding of Multiple Black-Box Experts for Multi-Task Model Fusion , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[6]
Proceedings of the 38th International Conference on Machine Learning , pages =
Model Fusion for Personalized Learning , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[7]
and Deems, Stephen and Furlani, Thomas R
Boerner, Timothy J. and Deems, Stephen and Furlani, Thomas R. and Knuth, Shelley L. and Towns, John , title =. Practice and Experience in Advanced Research Computing 2023: Computing for the Common Good , pages =. 2023 , isbn =. doi:10.1145/3569951.3597559 , abstract =
-
[8]
International Conference on Artificial Intelligence and Statistics , year=
Communication-Efficient Learning of Deep Networks from Decentralized Data , author=. International Conference on Artificial Intelligence and Statistics , year=
-
[9]
2018 IEEE Spoken Language Technology Workshop (SLT) , year=
A Re-Ranker Scheme For Integrating Large Scale NLU Models , author=. 2018 IEEE Spoken Language Technology Workshop (SLT) , year=
2018
-
[10]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[11]
M. J. Kearns , title =
-
[12]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[13]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[14]
Suppressed for Anonymity , author=
-
[15]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[16]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[17]
arXiv preprint arXiv:2406.11385 , year=
Metagpt: Merging large language models using model exclusive task arithmetic , author=. arXiv preprint arXiv:2406.11385 , year=
-
[18]
Forty-first International Conference on Machine Learning , year=
Language models are super mario: Absorbing abilities from homologous models as a free lunch , author=. Forty-first International Conference on Machine Learning , year=
-
[19]
http://yann
The MNIST database of handwritten digits , author=. http://yann. lecun. com/exdb/mnist/ , year=
-
[20]
Proceedings of the IEEE international conference on computer vision workshops , pages=
3d object representations for fine-grained categorization , author=. Proceedings of the IEEE international conference on computer vision workshops , pages=
-
[21]
Concrete subspace learning based interference elimination for multi-task model fusion , author=. arXiv preprint arXiv:2312.06173 , year=
-
[22]
Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , pages=
GLUE: A multi-task benchmark and analysis platform for natural language understanding , author=. Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , pages=
2018
-
[23]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms , author=. arXiv preprint arXiv:1708.07747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Learning multiple layers of features from tiny images.(2009) , author=
2009
-
[25]
European Conference on Computer Vision , year =
Food-101 -- Mining Discriminative Components with Random Forests , author =. European Conference on Computer Vision , year =
-
[26]
2008 Sixth Indian conference on computer vision, graphics & image processing , pages=
Automated flower classification over a large number of classes , author=. 2008 Sixth Indian conference on computer vision, graphics & image processing , pages=. 2008 , organization=
2008
-
[27]
Proceedings of the IEEE , volume=
Remote sensing image scene classification: Benchmark and state of the art , author=. Proceedings of the IEEE , volume=. 2017 , publisher=
2017
-
[28]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Describing textures in the wild , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[29]
The 2011 international joint conference on neural networks , pages=
The German traffic sign recognition benchmark: a multi-class classification competition , author=. The 2011 international joint conference on neural networks , pages=. 2011 , organization=
2011
-
[30]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2019 , publisher=
2019
-
[31]
NIPS workshop on deep learning and unsupervised feature learning , volume=
Reading digits in natural images with unsupervised feature learning , author=. NIPS workshop on deep learning and unsupervised feature learning , volume=. 2011 , organization=
2011
-
[32]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[33]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[34]
2014 4th IEEE International Conference on Information Science and Technology , pages=
On the robustness and generalization of cauchy regression , author=. 2014 4th IEEE International Conference on Information Science and Technology , pages=. 2014 , organization=
2014
-
[35]
arXiv preprint arXiv:2406.07529 , year=
Map: Low-compute model merging with amortized pareto fronts via quadratic approximation , author=. arXiv preprint arXiv:2406.07529 , year=
-
[36]
arXiv preprint arXiv:2410.19735 , year=
Model merging with svd to tie the knots , author=. arXiv preprint arXiv:2410.19735 , year=
-
[37]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Task singular vectors: Reducing task interference in model merging , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[38]
Advances in Neural Information Processing Systems , volume=
Ties-merging: Resolving interference when merging models , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Advances in Neural Information Processing Systems , volume=
Task arithmetic in the tangent space: Improved editing of pre-trained models , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Robust fine-tuning of zero-shot models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[41]
Editing Models with Task Arithmetic
Editing models with task arithmetic , author=. arXiv preprint arXiv:2212.04089 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
2008 IEEE international conference on acoustics, speech and signal processing , pages=
Generalized Cauchy distribution based robust estimation , author=. 2008 IEEE international conference on acoustics, speech and signal processing , pages=. 2008 , organization=
2008
-
[43]
Modeling multi-task model merging as adaptive projective gradient descent , author=. arXiv preprint arXiv:2501.01230 , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
Merging models with fisher-weighted averaging , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Southern African Conference for Artificial Intelligence Research , pages=
Cauchy loss function: Robustness under gaussian and Cauchy noise , author=. Southern African Conference for Artificial Intelligence Research , pages=. 2022 , organization=
2022
-
[46]
International conference on machine learning , pages=
Optimizing neural networks with kronecker-factored approximate curvature , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[47]
arXiv preprint arXiv:2508.16082 , year=
On Task Vectors and Gradients , author=. arXiv preprint arXiv:2508.16082 , year=
-
[48]
arXiv preprint arXiv:2310.12808 , year=
Model merging by uncertainty-based gradient matching , author=. arXiv preprint arXiv:2310.12808 , year=
-
[49]
1991 , publisher=
Introductory functional analysis with applications , author=. 1991 , publisher=
1991
-
[50]
IEEE Transactions on Knowledge and Data Engineering , volume=
A survey on federated learning systems: Vision, hype and reality for data privacy and protection , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2021 , publisher=
2021
-
[51]
arXiv preprint arXiv:2212.09849 , year=
Dataless knowledge fusion by merging weights of language models , author=. arXiv preprint arXiv:2212.09849 , year=
-
[52]
arXiv preprint arXiv:2410.10801 , year=
Mix data or merge models? optimizing for diverse multi-task learning , author=. arXiv preprint arXiv:2410.10801 , year=
-
[53]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
arXiv preprint arXiv:2101.03288 , year=
How to train your energy-based models , author=. arXiv preprint arXiv:2101.03288 , year=
-
[55]
Predicting structured data , volume=
A tutorial on energy-based learning , author=. Predicting structured data , volume=
-
[56]
Journal of Machine Learning Research , volume=
Energy-based models for sparse overcomplete representations , author=. Journal of Machine Learning Research , volume=
-
[57]
Neural computation , volume=
Training products of experts by minimizing contrastive divergence , author=. Neural computation , volume=. 2002 , publisher=
2002
-
[58]
Deep model fusion: A survey.arXiv preprint arXiv:2309.15698,
Deep model fusion: A survey , author=. arXiv preprint arXiv:2309.15698 , year=
-
[59]
ACM Computing Surveys , year=
Model merging in llms, mllms, and beyond: Methods, theories, applications, and opportunities , author=. ACM Computing Surveys , year=
-
[60]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Securing Distributed Gradient Descent in High Dimensional Statistical Learning
Securing distributed machine learning in high dimensions , author=. arXiv preprint arXiv:1804.10140 , volume=. 2018 , publisher=
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[62]
arXiv preprint arXiv:2410.13638 , year=
Scaling wearable foundation models , author=. arXiv preprint arXiv:2410.13638 , year=
-
[63]
Advances in Neural Information Processing Systems , volume=
Federated learning from vision-language foundation models: Theoretical analysis and method , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
Medical image analysis , volume=
On the challenges and perspectives of foundation models for medical image analysis , author=. Medical image analysis , volume=. 2024 , publisher=
2024
-
[65]
International Conference on Blockchain and Trustworthy Systems , pages=
Vision foundation models in medical image analysis: Advances and challenges , author=. International Conference on Blockchain and Trustworthy Systems , pages=. 2025 , organization=
2025
-
[66]
2018 International Conference on Computational Science and Computational Intelligence (CSCI) , pages=
Deep learning at the edge , author=. 2018 International Conference on Computational Science and Computational Intelligence (CSCI) , pages=. 2018 , organization=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.