DL-VINS-Factory: A Modular Framework for Learned Visual Front-Ends in Visual-Inertial SLAM
Pith reviewed 2026-07-03 16:26 UTC · model grok-4.3
The pith
Learned visual front-ends are viable for real-time embedded VI-SLAM but not universally superior to classical tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
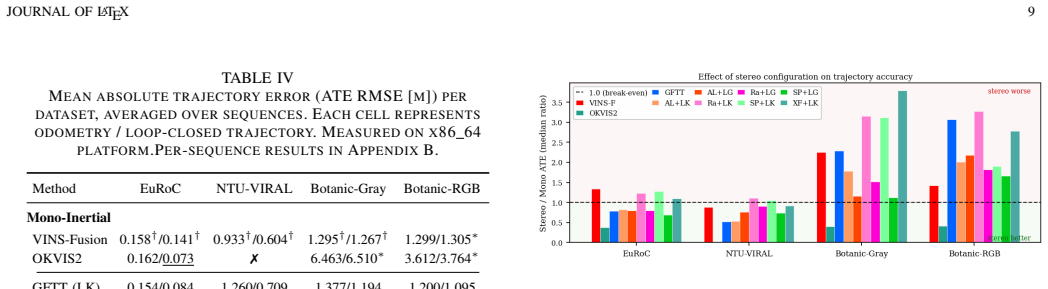
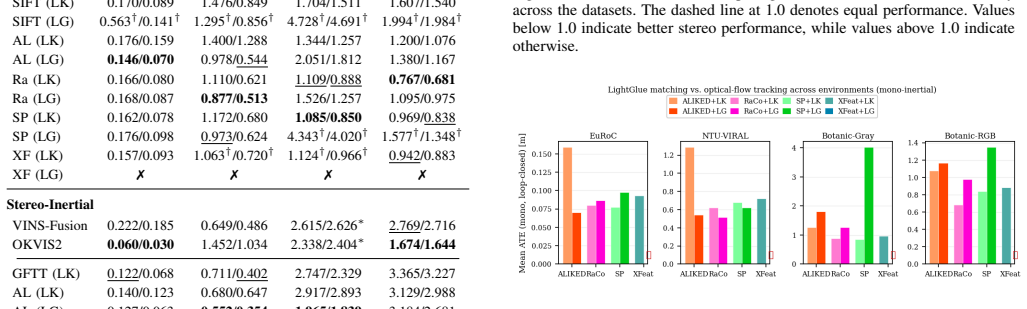
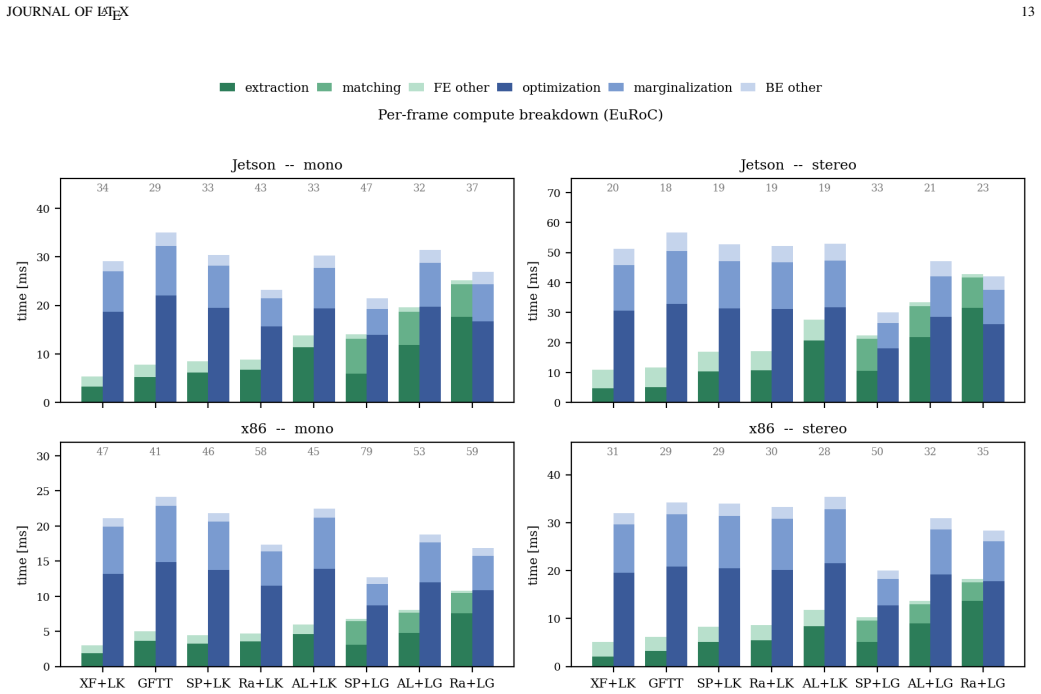
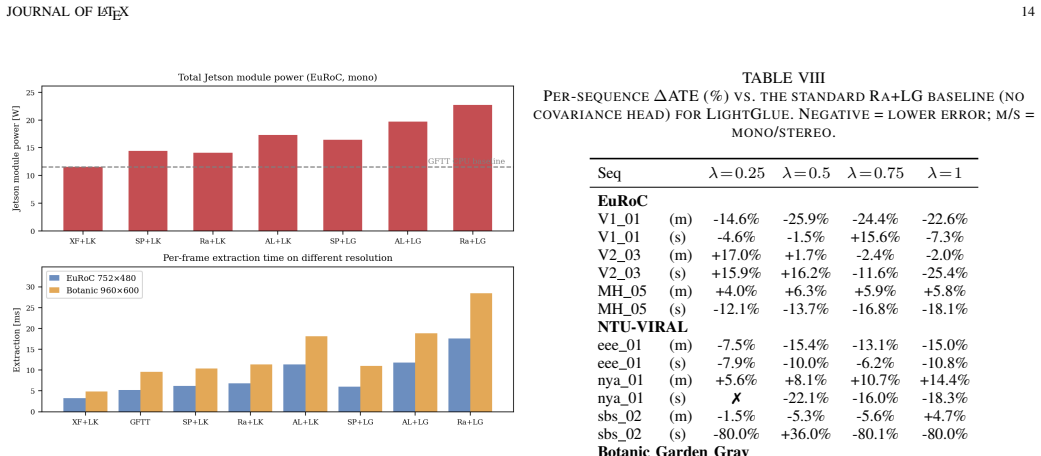
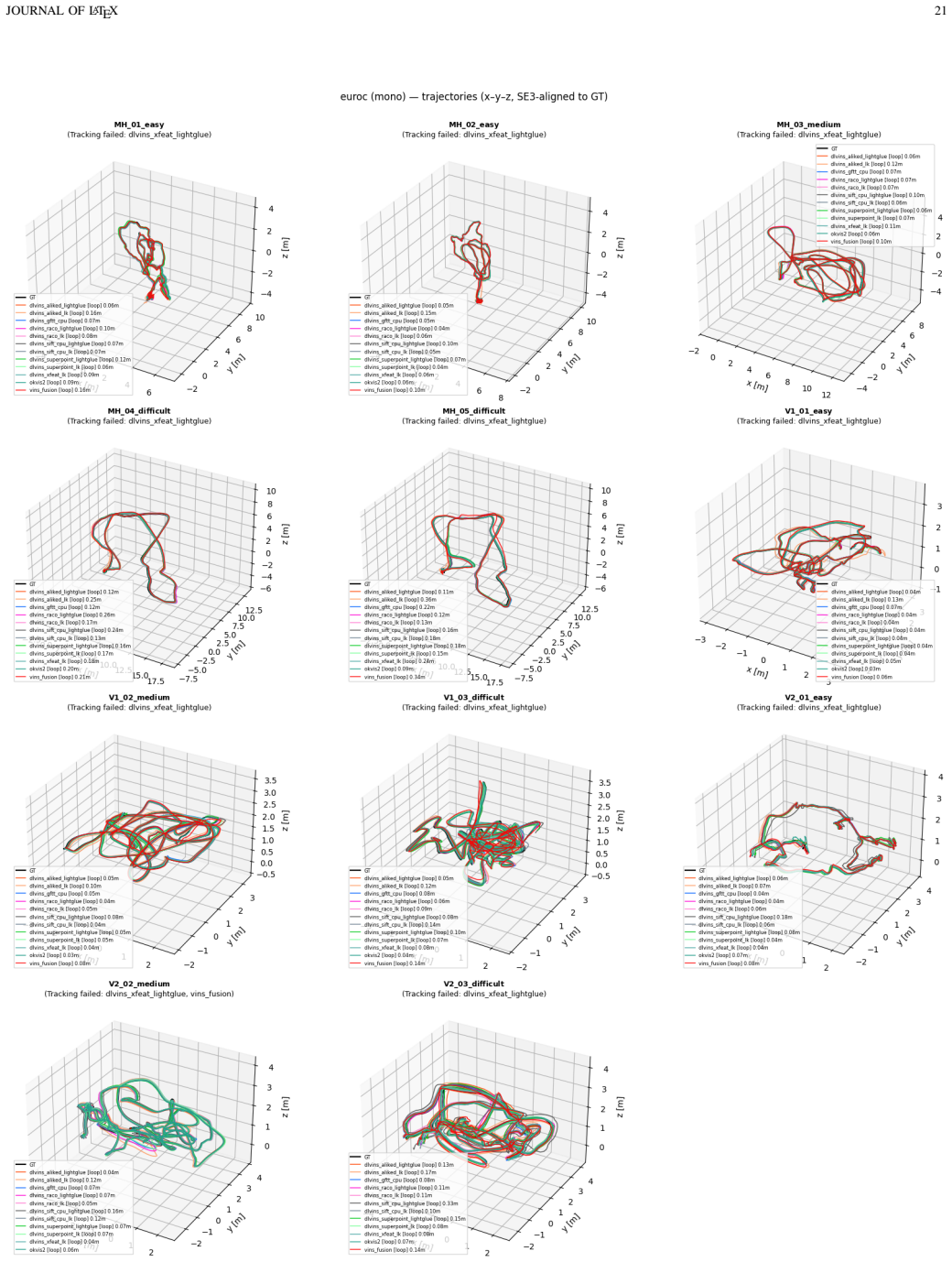
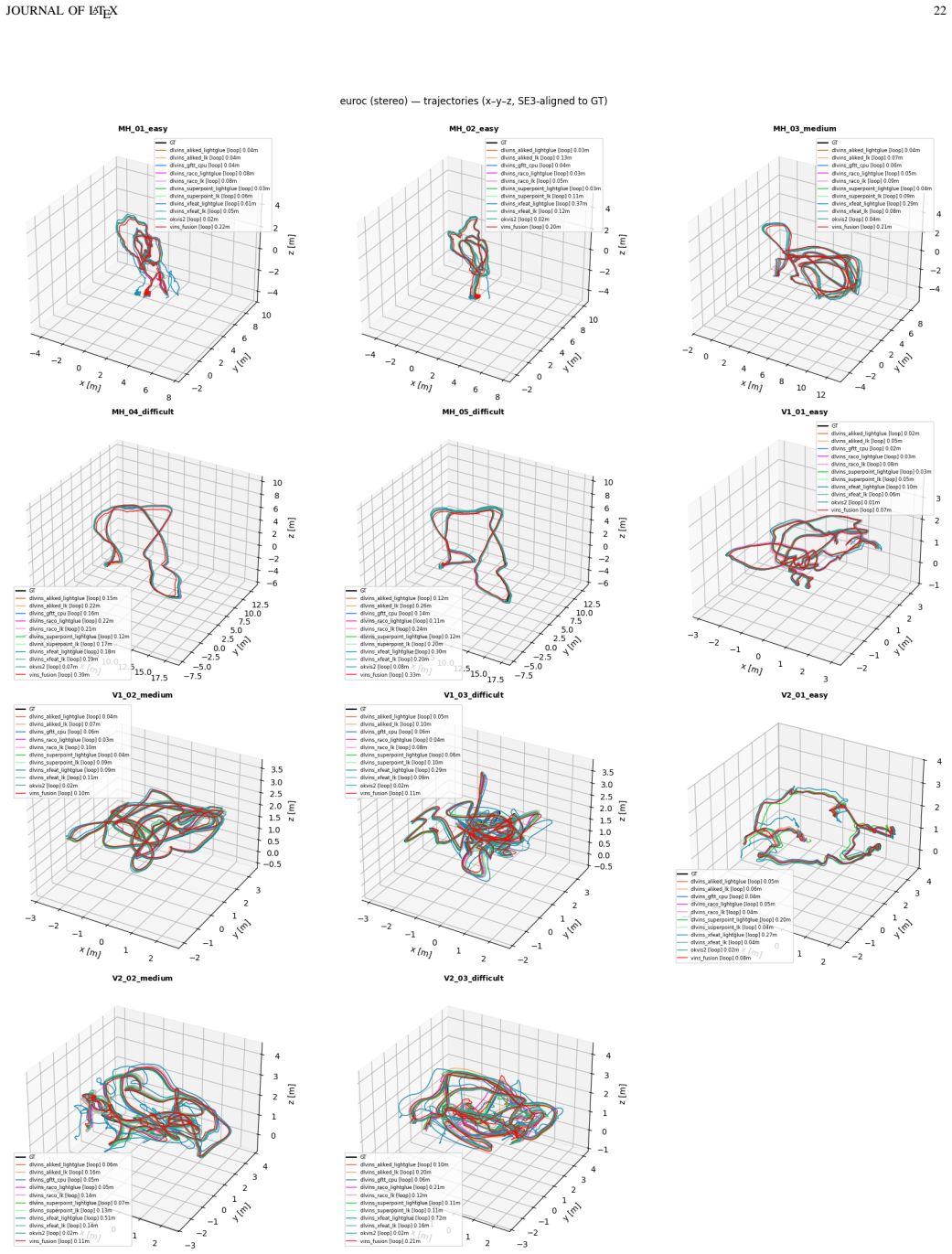
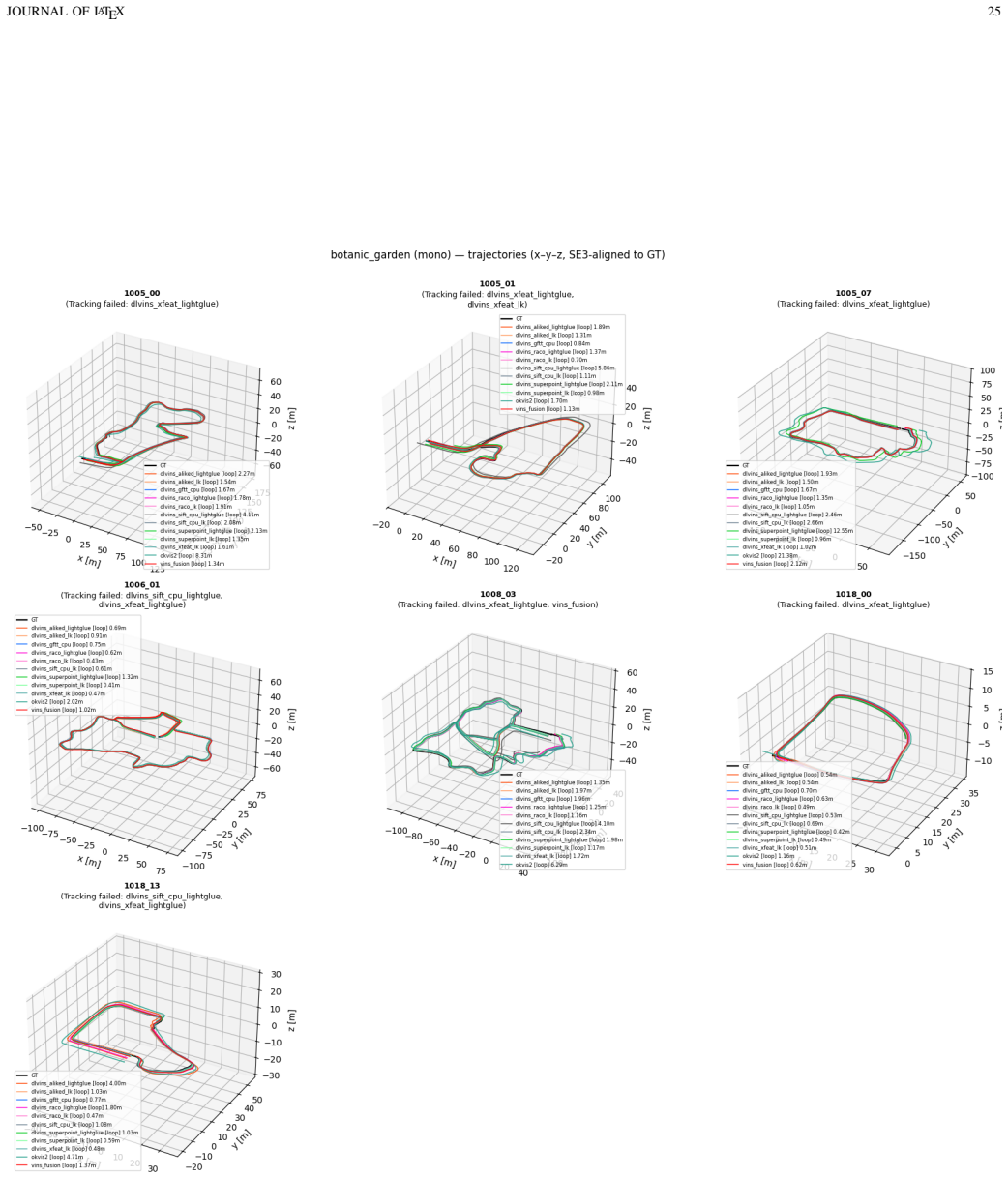
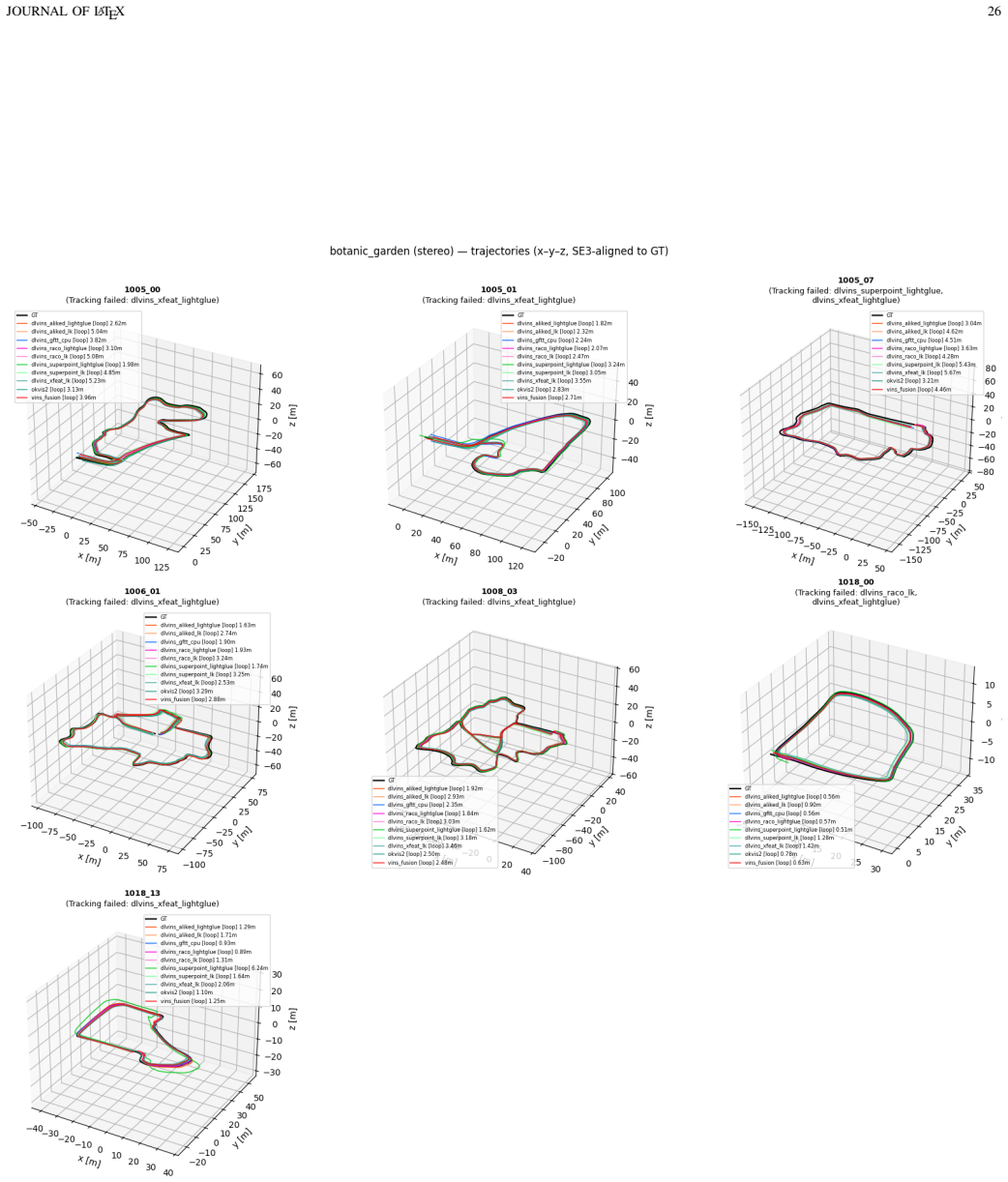
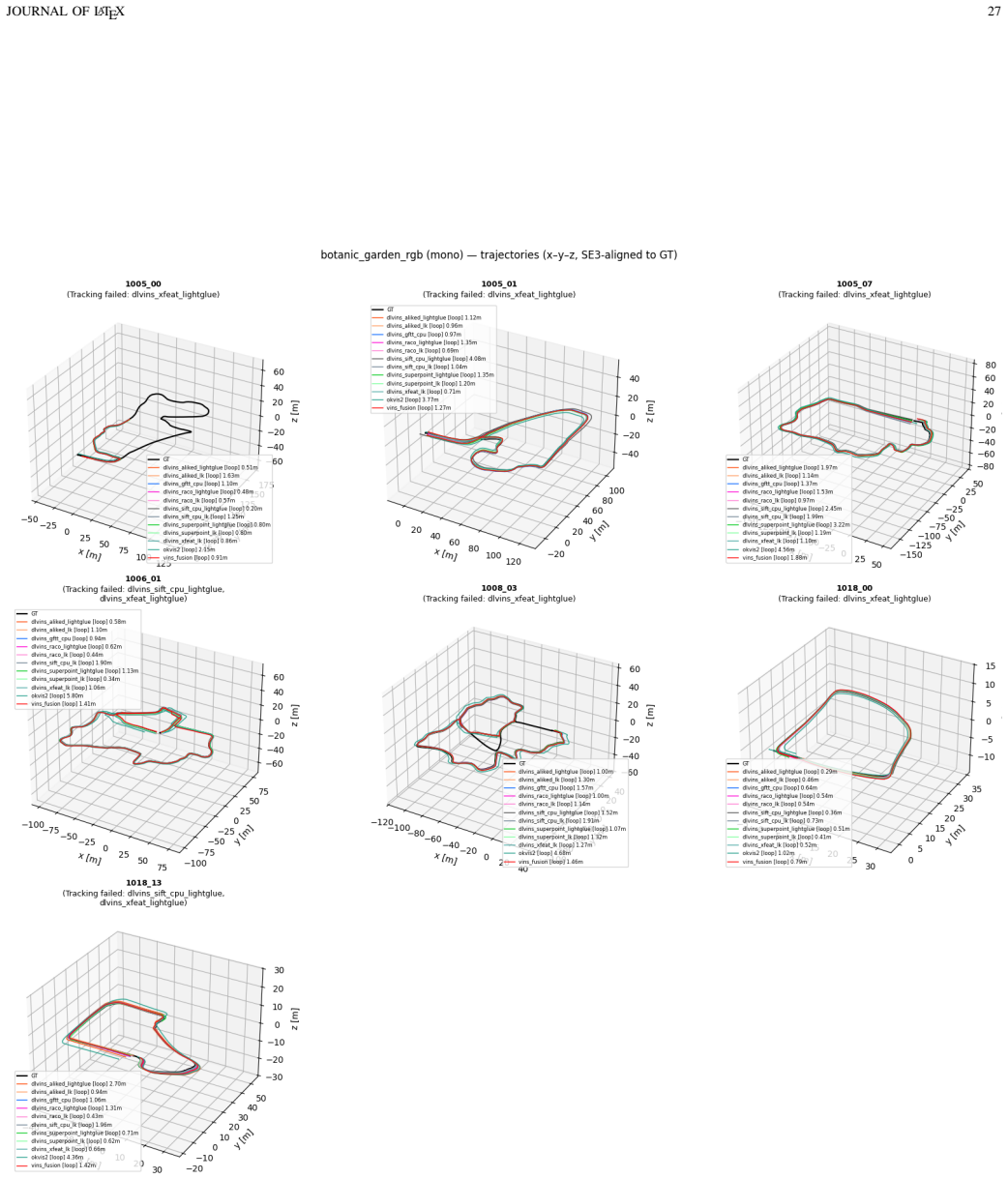
DL-VINS-Factory demonstrates that learned front-ends can be swapped into a shared VI-SLAM architecture; relative to GFTT+LK, ALIKED+LG lowers EuRoC ATE by 5 percent monocular and 7 percent stereo with loop closure, by 12 percent on NTU-VIRAL stereo, while SuperPoint+LK and RaCo+LK cut ATE by 29 percent and 38 percent on the two Botanic Garden cameras; every configuration runs between 29-47 FPS monocular and 18-33 FPS stereo on Jetson hardware, and AnyLoc returns roughly 2-7 times more valid loops than BRIEF+DBoW2.
What carries the argument
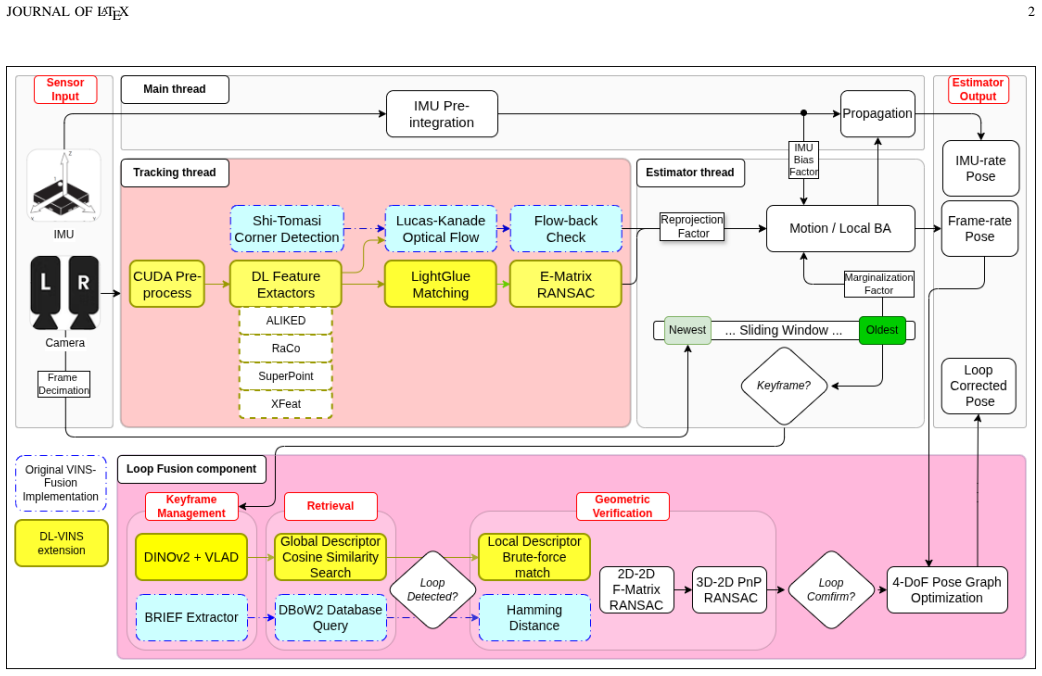
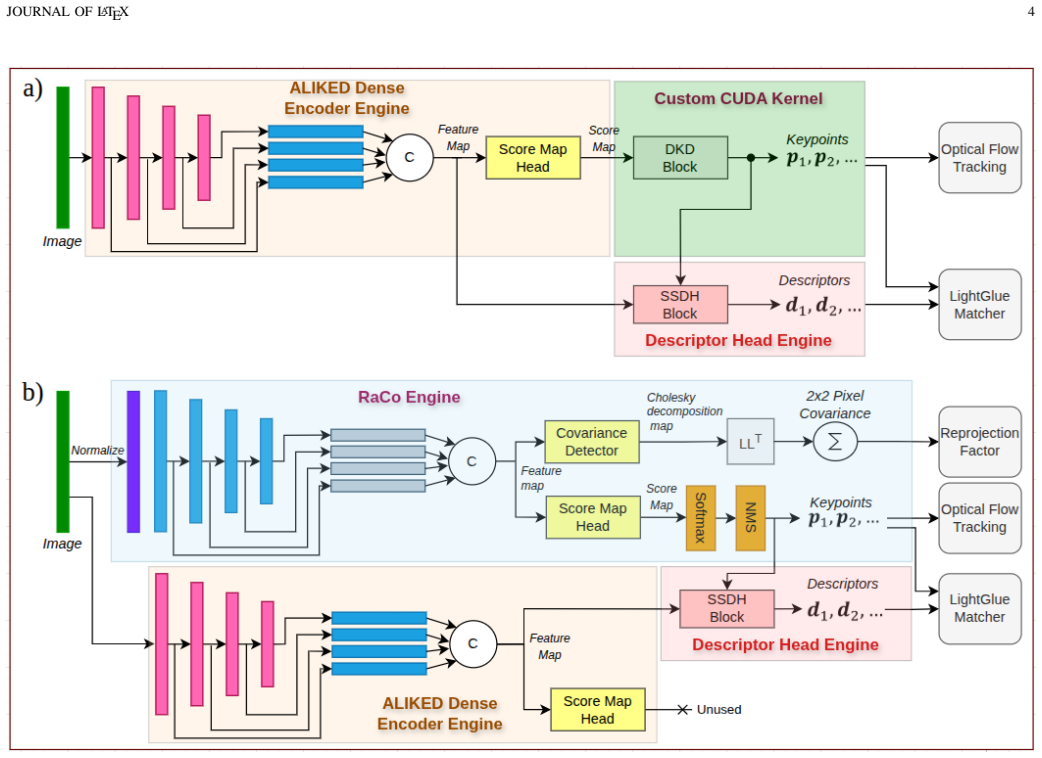
DL-VINS-Factory, a modular integration layer that attaches learned extractors to either LK optical-flow tracking or LG descriptor matching, then feeds the resulting tracks into a shared Ceres sliding-window back-end with optional AnyLoc DINOv2-VLAD loop closure.
If this is right
- Learned extractors can be inserted without altering the back-end optimizer or loop-closure module.
- TensorRT acceleration on Jetson AGX Orin keeps all tested configurations inside real-time bounds.
- AnyLoc loop closure yields substantially more valid loops than classical bag-of-words methods.
- Optical-flow tracking remains preferable in some visual environments even when learned keypoints are available.
Where Pith is reading between the lines
- Additional datasets with different sensors or lighting statistics could shift the observed ranking between learned and classical front-ends.
- The apparent superiority of learned methods is sensitive to the precise classical baseline chosen for comparison.
- The same modular structure could be reused to benchmark future extractors or matchers without re-implementing the estimator.
- Hardware-specific acceleration remains essential for any claim of practicality on embedded platforms.
Load-bearing premise
The four chosen datasets together with the GFTT+LK baseline adequately represent the range of conditions and classical methods against which learned front-ends should be judged.
What would settle it
A fifth dataset or operating condition in which every learned front-end either exceeds the real-time FPS limits or produces higher ATE than the GFTT+LK baseline across the board would falsify the viability claim.
Figures





read the original abstract
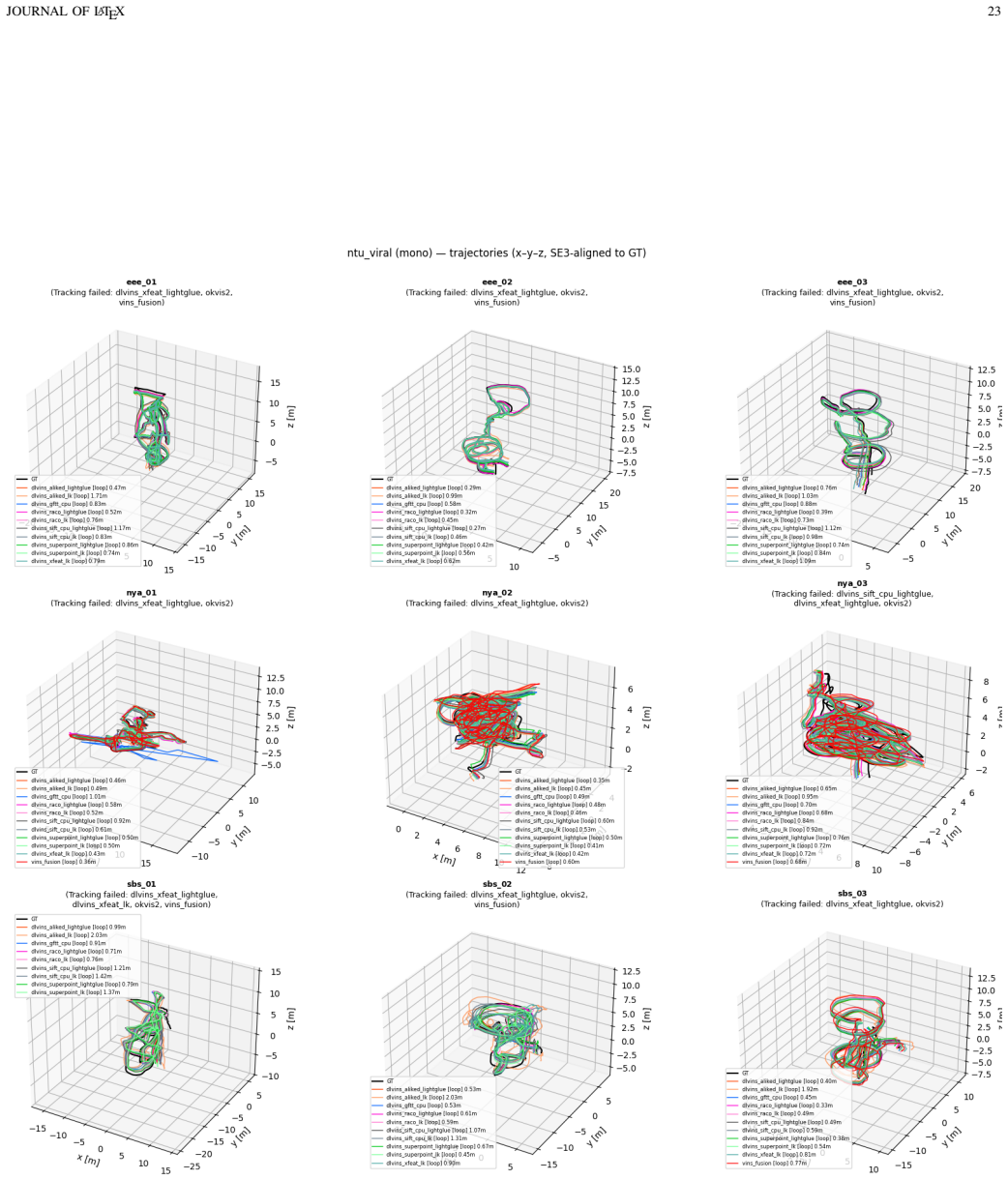
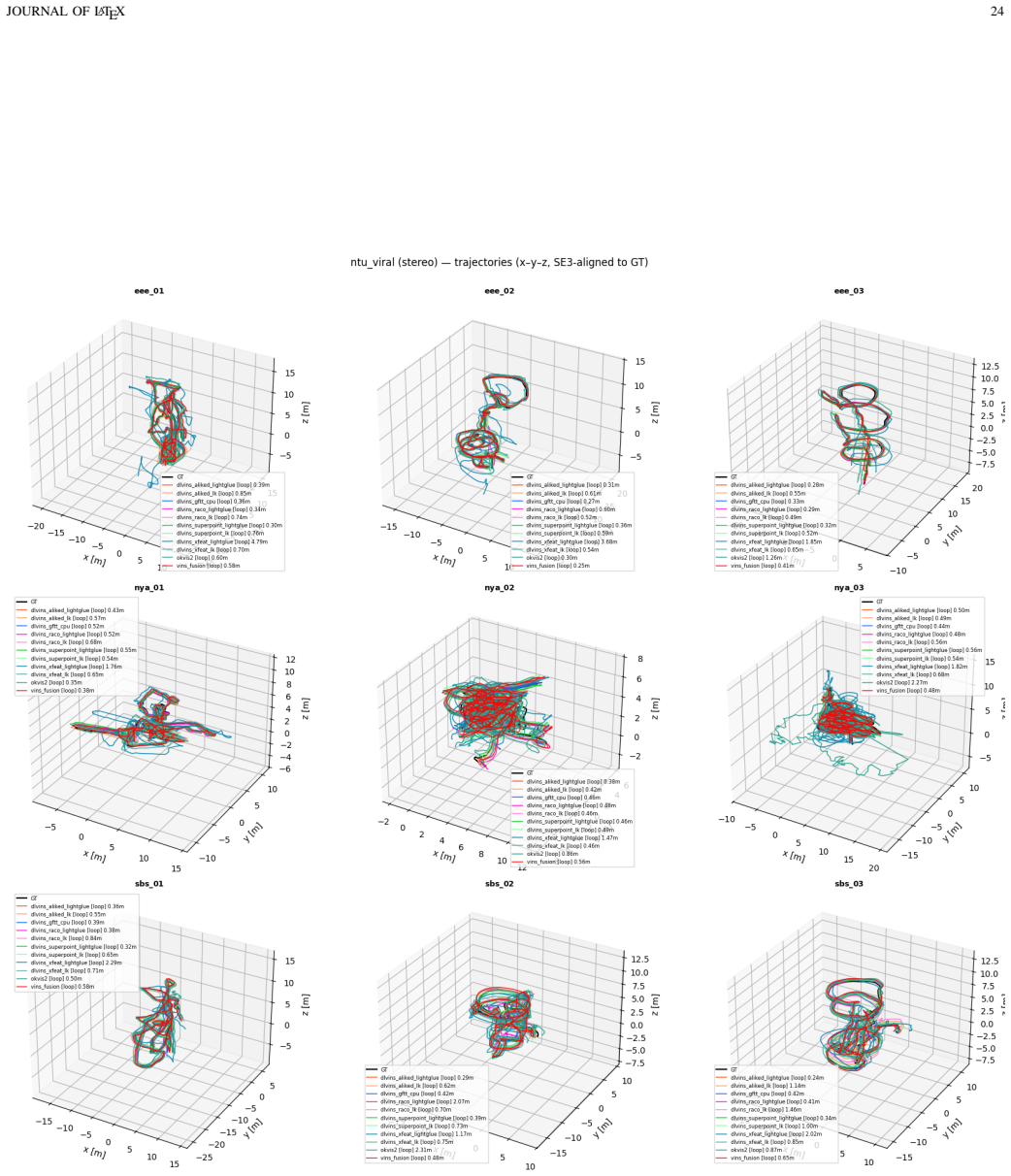
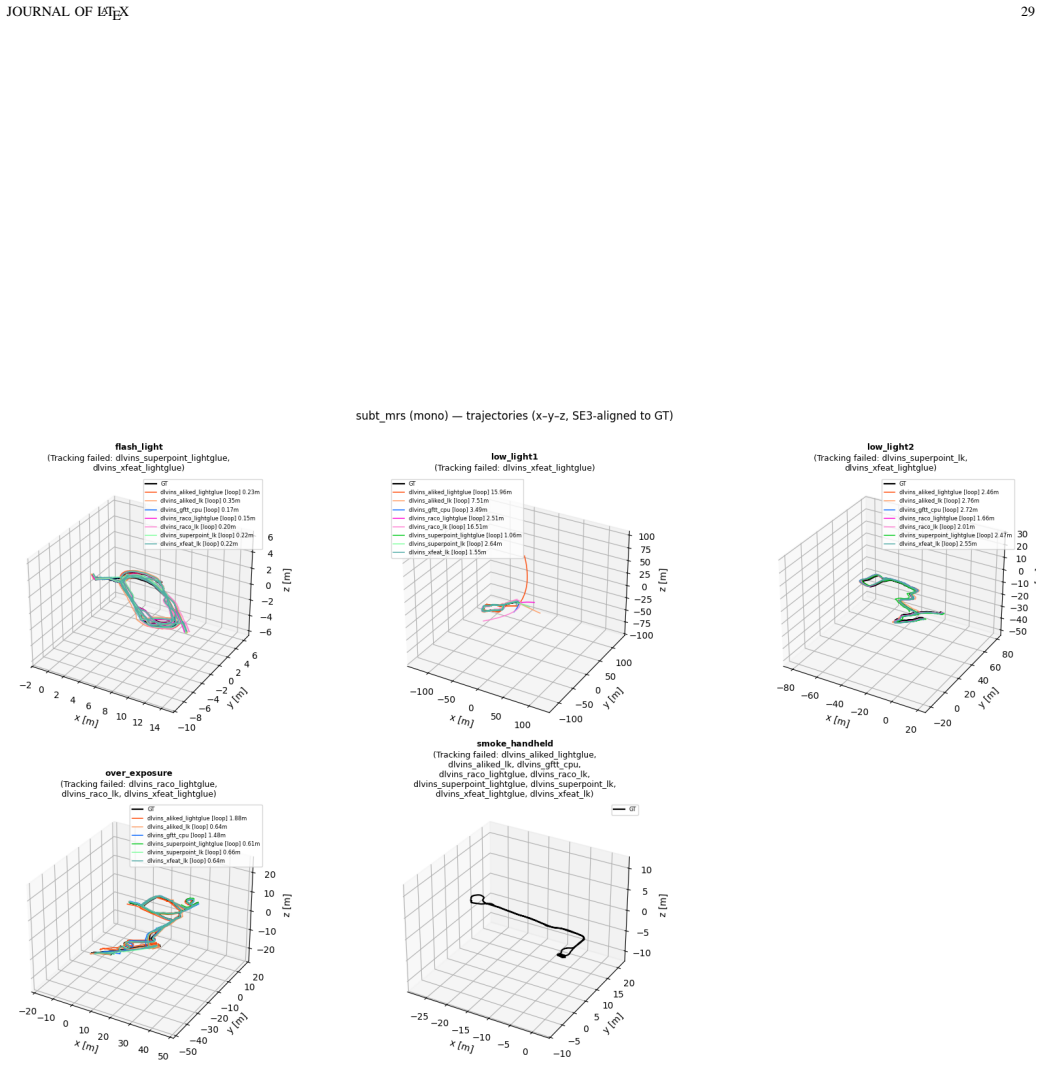
Deep-learning features excel in visual matching, yet their practical value in tightly coupled visual-inertial SLAM (VI-SLAM) remains insufficiently characterized. We present DL-VINS-Factory, a unified framework that integrates learned feature extractors (ALIKED, RaCo, SuperPoint, XFeat) with either Lucas--Kanade (LK) optical-flow tracking or LightGlue (LG) descriptor matching. All front-ends share a sliding-window Ceres back-end, with optional AnyLoc DINOv2-VLAD loop closure, and 4-DoF pose-graph optimization. We benchmark the system across the four datasets covering indoor, unstructured outdoor, aggressive-motion, and visually degraded conditions. Results show that learned front-ends are viable for real-time embedded VI-SLAM, but are not universally superior to classical tracking. Relative to the corresponding GFTT+LK baseline, ALIKED+LG reduces EuRoC ATE by $5\%$ in monocular odometry and by $7\%$ in stereo with loop-closure. On NTU-VIRAL, where aggressive aerial motion increases inter-frame viewpoint change, ALIKED+LG stereo reduces loop-closed ATE by $12\%$. In Botanic Garden dataset, optical-flow tracking remains preferable, but learned keypoints still improve over the baseline GFTT, in which SuperPoint+LK reduces grayscale camera ATE by $29\%$, while RaCo+LK reduces RGB camera ATE by $38\%$. On SubT-MRS, learned front-ends display varying degree of improvement based on individual cases. With TensorRT acceleration on a Jetson AGX Orin, all valid configurations run in real time between $29$--$47$ FPS in monocular mode and $18$--$33$ FPS in stereo mode for the EuRoC and NTU-VIRAL datasets. AnyLoc further confirms roughly $2$--$7\times$ more valid loops than BRIEF+DBoW2. The implementation is open-sourced at https://github.com/limshoonkit/DL-VINS-Factory-ROS2/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DL-VINS-Factory, a modular open-source framework integrating learned feature extractors (ALIKED, RaCo, SuperPoint, XFeat) with LK optical flow or LightGlue matching into a tightly-coupled VI-SLAM pipeline sharing a Ceres sliding-window backend and optional AnyLoc loop closure. Across EuRoC, NTU-VIRAL, Botanic Garden and SubT-MRS, it reports that learned front-ends run in real time on Jetson AGX Orin (29-47 FPS monocular, 18-33 FPS stereo) and yield mixed accuracy results versus a GFTT+LK baseline: 5% ATE reduction on EuRoC monocular, 7% on EuRoC stereo with loop closure, 12% on NTU-VIRAL stereo, with optical-flow tracking preferred on Botanic Garden and case-dependent gains on SubT-MRS. The central claim is that learned front-ends are viable for embedded VI-SLAM but not universally superior to classical tracking.
Significance. If the empirical findings are robust, the work supplies a practical, reproducible toolkit for testing learned visual front-ends inside a full VI-SLAM stack and identifies concrete regimes (aggressive motion, loop closure) where descriptor matching helps. The open-source release and embedded timing numbers are directly usable by the robotics community.
major comments (3)
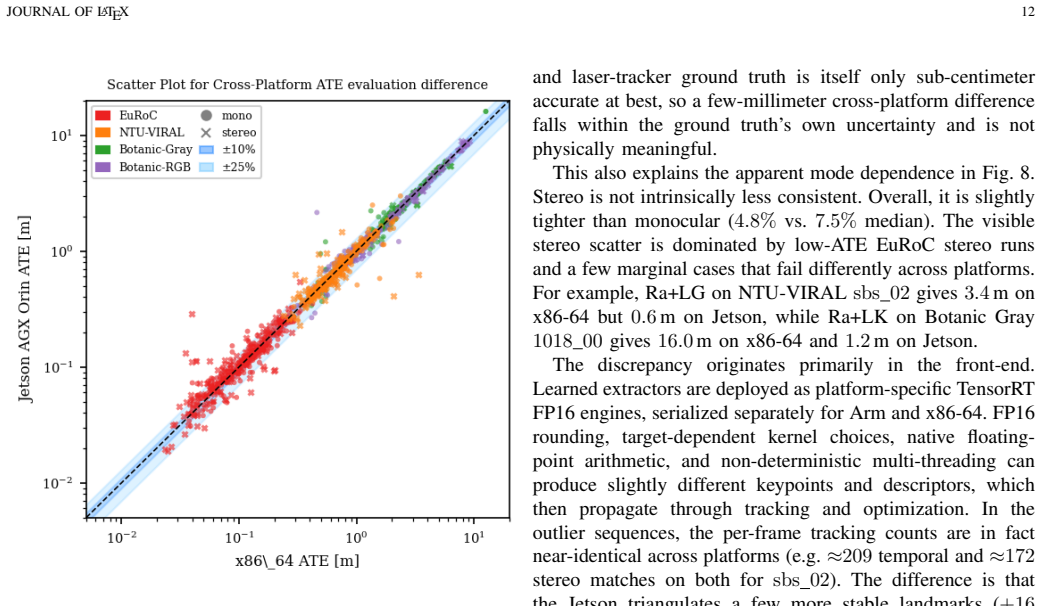
- [Abstract / Experimental results] Abstract and experimental results: the reported ATE reductions (5% EuRoC monocular, 7% stereo with loop closure, 12% NTU-VIRAL stereo) are given as point values with no error bars, no statistical significance tests, and no description of run count, dataset splits, or failure-case handling, so the viability and superiority claims cannot be quantitatively assessed.
- [Results and discussion] Baseline and conclusion: the statement that learned front-ends are 'not universally superior to classical tracking' is supported only by comparison to GFTT+LK; no additional classical pipelines (e.g., ORB-SLAM-style detection/matching or other detectors) are evaluated, leaving open whether the nuanced conclusion generalizes beyond the chosen baseline.
- [Experimental setup] Dataset justification: the four datasets are described as covering indoor/outdoor/aggressive/degraded conditions, yet the paper supplies no explicit argument or ablation showing that this selection adequately samples the space of operating regimes needed to support the 'not universally superior' claim.
minor comments (1)
- [Abstract] The abstract states that AnyLoc yields 'roughly 2--7× more valid loops' than BRIEF+DBoW2 but does not define the criterion used to count a loop as valid.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve the presentation of results, clarify baselines, and strengthen dataset justification.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental results: the reported ATE reductions (5% EuRoC monocular, 7% stereo with loop closure, 12% NTU-VIRAL stereo) are given as point values with no error bars, no statistical significance tests, and no description of run count, dataset splits, or failure-case handling, so the viability and superiority claims cannot be quantitatively assessed.
Authors: We agree that the reported ATE values are point estimates and that additional details would strengthen the quantitative assessment. In the revised manuscript we will add the number of runs performed per configuration, any observed variability, a description of the evaluation protocol including dataset splits, and notes on failure-case handling. Formal statistical significance testing was not performed in the original work; we will note this limitation explicitly in the discussion. revision: yes
-
Referee: [Results and discussion] Baseline and conclusion: the statement that learned front-ends are 'not universally superior to classical tracking' is supported only by comparison to GFTT+LK; no additional classical pipelines (e.g., ORB-SLAM-style detection/matching or other detectors) are evaluated, leaving open whether the nuanced conclusion generalizes beyond the chosen baseline.
Authors: The GFTT+LK baseline was selected because it provides the most direct comparison to the optical-flow tracking configurations within our shared Ceres backend. We acknowledge that the conclusion is therefore scoped to this baseline. In revision we will explicitly qualify the statement to reflect this scope and add a short discussion of how other classical pipelines (such as ORB-based matching) might differ, while noting that full integration of alternative back-ends lies outside the current modular front-end focus. revision: yes
-
Referee: [Experimental setup] Dataset justification: the four datasets are described as covering indoor/outdoor/aggressive/degraded conditions, yet the paper supplies no explicit argument or ablation showing that this selection adequately samples the space of operating regimes needed to support the 'not universally superior' claim.
Authors: The four datasets were chosen for their complementary operating regimes (structured indoor, aggressive aerial motion, unstructured outdoor, and visually degraded subterranean) and their established use in the VI-SLAM literature. The observed case-dependent performance differences across these regimes directly support the non-universal superiority claim. In the revised experimental-setup section we will add an explicit paragraph justifying the selection on these grounds. revision: yes
Circularity Check
No circularity: purely empirical benchmarking with no derivations or fitted predictions.
full rationale
The paper describes a modular integration framework (DL-VINS-Factory) for learned feature extractors (ALIKED, RaCo, SuperPoint, XFeat) paired with LK or LG tracking, sharing a Ceres back-end and optional AnyLoc loop closure. All reported results consist of direct ATE and runtime measurements on four fixed datasets (EuRoC, NTU-VIRAL, Botanic Garden, SubT-MRS) relative to a GFTT+LK baseline. No equations, parameter fits, uniqueness theorems, or self-citations are invoked to derive any quantity; the viability and 'not universally superior' statements are simple empirical summaries of the tabulated comparisons. The study is therefore self-contained against external benchmarks and contains no load-bearing steps that reduce to their own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Orb: An efficient alternative to sift or surf,
E. Rublee, V . Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” in2011 International Conference on Computer Vision, 2011, pp. 2564–2571
2011
-
[2]
Brisk: Binary robust invariant scalable keypoints,
S. Leutenegger, M. Chli, and R. Y . Siegwart, “Brisk: Binary robust invariant scalable keypoints,” in2011 International Conference on Computer Vision, 2011, pp. 2548–2555
2011
-
[3]
Comparative study of deep learning based features in slam,
C. Deng, K. Qiu, R. Xiong, and C. Zhou, “Comparative study of deep learning based features in slam,” in2019 4th Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), 2019, pp. 250–254
2019
-
[4]
Superpoint: Self- supervised interest point detection and description,
D. DeTone, T. Malisiewicz, and A. Rabinovich, “Superpoint: Self- supervised interest point detection and description,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2018, pp. 337–33 712
2018
-
[5]
SuperGlue: Learning feature matching with graph neural networks,
P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich, “SuperGlue: Learning feature matching with graph neural networks,” inCVPR, 2020. [Online]. Available: https://arxiv.org/abs/1911.11763
-
[6]
Closed- loop benchmarking of stereo visual-inertial slam systems: Understanding the impact of drift and latency on tracking accuracy,
Y . Zhao, J. S. Smith, S. H. Karumanchi, and P. A. Vela, “Closed- loop benchmarking of stereo visual-inertial slam systems: Understanding the impact of drift and latency on tracking accuracy,” in2020 IEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 1105–1112
2020
-
[7]
Bags of binary words for fast place recognition in image sequences,
D. Galvez-L ´opez and J. D. Tardos, “Bags of binary words for fast place recognition in image sequences,”IEEE Transactions on Robotics, vol. 28, no. 5, pp. 1188–1197, 2012
2012
-
[8]
Anyloc: Towards universal visual place recognition,
N. Keethaet al., “Anyloc: Towards universal visual place recognition,” IEEE Robotics and Automation Letters, vol. 9, no. 2, pp. 1286–1293, 2024
2024
-
[9]
Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,
C. Campos, R. Elvira, J. J. G. Rodr ´ıguez, J. M. M. Montiel, and J. D. Tard ´os, “Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,”IEEE Transactions on Robotics, vol. 37, no. 6, pp. 1874–1890, 2021
2021
-
[10]
Okvis2-x: Open keyframe-based visual-inertial slam configurable with dense depth or lidar, and gnss,
S. Boche, J. Jung, S. B. Laina, and S. Leutenegger, “Okvis2-x: Open keyframe-based visual-inertial slam configurable with dense depth or lidar, and gnss,”IEEE Transactions on Robotics, vol. 41, pp. 6064– 6083, 2025
2025
-
[11]
A general optimisation-based framework for global pose estimation with multiple sensors,
T. Qin, S. Cao, J. Pan, and S. Shen, “A general optimisation-based framework for global pose estimation with multiple sensors,”IET Cyber- Systems and Robotics, vol. 7, no. 1, p. e70023, 2025. [Online]. Available: https://ietresearch.onlinelibrary.wiley.com/doi/abs/10.1049/csy2.70023
-
[12]
Openvins: A research platform for visual-inertial estimation,
P. Geneva, K. Eckenhoff, W. Lee, Y . Yang, and G. Huang, “Openvins: A research platform for visual-inertial estimation,” in2020 IEEE In- ternational Conference on Robotics and Automation (ICRA), 2020, pp. 4666–4672
2020
-
[13]
Kimera: an open- source library for real-time metric-semantic localization and mapping,
A. Rosinol, M. Abate, Y . Chang, and L. Carlone, “Kimera: an open- source library for real-time metric-semantic localization and mapping,” in2020 IEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 1689–1696
2020
-
[14]
Airslam: An efficient and illumination-robust point-line visual slam system,
K. Xu, Y . Hao, S. Yuan, C. Wang, and L. Xie, “Airslam: An efficient and illumination-robust point-line visual slam system,”IEEE Transactions on Robotics, vol. 41, pp. 1673–1692, 2025
2025
-
[15]
Gcnv2: Efficient correspondence prediction for real-time slam,
J. Tang, L. Ericson, J. Folkesson, and P. Jensfelt, “Gcnv2: Efficient correspondence prediction for real-time slam,”IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 3505–3512, 2019
2019
-
[16]
Dxslam: A robust and efficient visual slam system with deep features,
D. Liet al., “Dxslam: A robust and efficient visual slam system with deep features,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020, pp. 4958–4965
2020
-
[17]
Hfnet-slam: An accurate and real-time monocular slam system with deep features,
L. Liu and J. M. Aitken, “Hfnet-slam: An accurate and real-time monocular slam system with deep features,”Sensors, vol. 23, no. 4,
-
[18]
Available: https://www.mdpi.com/1424-8220/23/4/2113
[Online]. Available: https://www.mdpi.com/1424-8220/23/4/2113
-
[19]
Supslam: A robust visual inertial slam system using superpoint for unmanned aerial vehicles,
C. H. Quach, M. D. Phung, H. V . Le, and S. Perry, “Supslam: A robust visual inertial slam system using superpoint for unmanned aerial vehicles,” in2021 8th NAFOSTED Conference on Information and Computer Science (NICS), 2021, pp. 507–512
2021
-
[20]
D-vins: Dynamic adaptive visual–inertial slam with imu prior and semantic constraints in dynamic scenes,
Y . Sunet al., “D-vins: Dynamic adaptive visual–inertial slam with imu prior and semantic constraints in dynamic scenes,” Remote Sensing, vol. 15, no. 15, 2023. [Online]. Available: https: //www.mdpi.com/2072-4292/15/15/3881
2023
-
[21]
Supervins: A real- time visual-inertial slam framework for challenging imaging conditions,
H. Luo, Y . Liu, C. Guo, Z. Li, and W. Song, “Supervins: A real- time visual-inertial slam framework for challenging imaging conditions,” IEEE Sensors Journal, vol. 25, no. 13, pp. 26 042–26 050, 2025
2025
-
[22]
LoFTR: Detector-free local feature matching with transformers,
J. Sun, Z. Shen, Y . Wang, H. Bao, and X. Zhou, “LoFTR: Detector-free local feature matching with transformers,”CVPR, 2021
2021
-
[23]
Raft: Recurrent all-pairs field transforms for optical flow,
Z. Teed and J. Deng, “Raft: Recurrent all-pairs field transforms for optical flow,” inComputer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II. Berlin, Heidelberg: Springer-Verlag, 2020, p. 402–419. [Online]. Available: https://doi.org/10.1007/978-3-030-58536-5 24
-
[24]
Tightly-coupled visual- inertial odometry with robust feature association in dynamic illumination environments,
J. Zhang, C. Zhang, Q. Liu, Q. Ma, and J. Qin, “Tightly-coupled visual- inertial odometry with robust feature association in dynamic illumination environments,”Robotica, vol. 43, no. 6, p. 2304–2319, 2025
2025
-
[25]
DROID-SLAM: Deep visual SLAM for monoc- ular, stereo, and RGB-D cameras,
Z. Teed and J. Deng, “DROID-SLAM: Deep visual SLAM for monoc- ular, stereo, and RGB-D cameras,” inAdvances in Neural Information Processing Systems, 2021
2021
-
[26]
L. Lipson, Z. Teed, and J. Deng, “Deep patch visual slam,” in Computer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part II. Berlin, Heidelberg: Springer-Verlag, 2024, p. 424–440. [Online]. Available: https://doi.org/10.1007/978-3-031-72627-9 24
-
[27]
Netvlad: Cnn architecture for weakly supervised place recognition,
R. Arandjelovic, P. Gronat, A. Torii, T. Pajdla, and J. Sivic, “Netvlad: Cnn architecture for weakly supervised place recognition,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 5297–5307
2016
-
[28]
Mixvpr: Feature mixing for visual place recognition,
A. Ali-Bey, B. Chaib-Draa, and P. Gigu ´ere, “Mixvpr: Feature mixing for visual place recognition,” in2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023, pp. 2997–3006
2023
-
[29]
Eigenplaces: Training viewpoint robust models for visual place recognition,
G. Berton, G. Trivigno, B. Caputo, and C. Masone, “Eigenplaces: Training viewpoint robust models for visual place recognition,” in2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 11 046–11 056
2023
-
[30]
Rethinking visual geo- localization for large-scale applications,
G. Berton, C. Masone, and B. Caputo, “Rethinking visual geo- localization for large-scale applications,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 4868– 4878
2022
-
[31]
DINOv2: Learning robust visual features without supervision,
M. Oquabet al., “DINOv2: Learning robust visual features without supervision,”Transactions on Machine Learning Research, 2024, featured Certification. [Online]. Available: https://openreview.net/ forum?id=a68SUt6zFt
2024
-
[32]
VINS-Mono: A robust and versatile monoc- ular visual-inertial state estimator,
T. Qin, P. Li, and S. Shen, “VINS-Mono: A robust and versatile monoc- ular visual-inertial state estimator,”IEEE Transactions on Robotics, vol. 34, no. 4, pp. 1004–1020, 2018
2018
-
[33]
Aliked: A lighter keypoint and descriptor extraction network via deformable transformation,
X. Zhaoet al., “Aliked: A lighter keypoint and descriptor extraction network via deformable transformation,”IEEE Transactions on Instru- mentation and Measurement, vol. 72, pp. 1–16, 2023
2023
-
[34]
RaCo: Ranking and Covariance for Practical Learned Keypoints ,
A. Shenoi, P. Lindenberger, P.-E. Sarlin, and M. Pollefeys, “ RaCo: Ranking and Covariance for Practical Learned Keypoints ,” in2026 International Conference on 3D Vision (3DV). Los Alamitos, CA, USA: IEEE Computer Society, Mar. 2026, pp. 267–276. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/3DV69130.2026.00033
-
[35]
Xfeat: Accelerated features for lightweight image matching,
G. Potje, F. Cadar, A. Araujo, R. Martins, and E. R. Nascimento, “Xfeat: Accelerated features for lightweight image matching,” in2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 2682–2691
2024
-
[36]
MAC-VO: Metrics-aware covariance for learning-based stereo visual odometry,
Y . Qiu, Y . Chen, Z. Zhang, W. Wang, and S. Scherer, “MAC-VO: Metrics-aware covariance for learning-based stereo visual odometry,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 3803–3814
2025
-
[37]
Lightglue: Local feature matching at light speed,
P. Lindenberger, P.-E. Sarlin, and M. Pollefeys, “Lightglue: Local feature matching at light speed,” in2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 17 581–17 592
2023
-
[38]
MAGSAC++, a fast, reliable and accurate robust estimator,
D. Barath, J. Noskova, M. Ivashechkin, and J. Matas, “MAGSAC++, a fast, reliable and accurate robust estimator,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 1304–1312
2020
-
[39]
Billion-scale similarity search with GPUs,
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with GPUs,”IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535– 547, 2019
2019
-
[40]
The euroc micro aerial vehicle datasets,
M. Burriet al., “The euroc micro aerial vehicle datasets,”The International Journal of Robotics Research, vol. 35, no. 10, pp. 1157–1163, 2016. [Online]. Available: https://doi.org/10.1177/ 0278364915620033 JOURNAL OF LATEX 17
2016
-
[41]
Ntu viral: A visual-inertial-ranging-lidar dataset, from an aerial vehicle viewpoint,
T.-M. Nguyenet al., “Ntu viral: A visual-inertial-ranging-lidar dataset, from an aerial vehicle viewpoint,”The International Journal of Robotics Research, vol. 41, no. 3, pp. 270–280, 2022. [Online]. Available: https://doi.org/10.1177/02783649211052312
-
[42]
Botanicgarden: A high-quality dataset for robot navigation in unstructured natural environments,
Y . Liuet al., “Botanicgarden: A high-quality dataset for robot navigation in unstructured natural environments,”IEEE Robotics and Automation Letters, vol. 9, no. 3, pp. 2798–2805, 2024
2024
-
[43]
Subt-mrs dataset: Pushing slam towards all-weather environments,
S. Zhaoet al., “Subt-mrs dataset: Pushing slam towards all-weather environments,” in2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 22 647–22 657
2024
-
[44]
Good features to track,
J. Shi and Tomasi, “Good features to track,” in1994 Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 1994, pp. 593–600
1994
-
[45]
An iterative image registration technique with an application to stereo vision,
B. D. Lucas and T. Kanade, “An iterative image registration technique with an application to stereo vision,” inProceedings of the 7th Inter- national Joint Conference on Artificial Intelligence - Volume 2, ser. IJCAI’81. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1981, p. 674–679
1981
-
[46]
Distinctive image features from scale-invariant keypoints,
D. G. Lowe, “Distinctive image features from scale-invariant keypoints,”International Journal of Computer Vision, vol. 60, no. 2, pp. 91–110, 2004. [Online]. Available: https://doi.org/10.1023/B: VISI.0000029664.99615.94
work page doi:10.1023/b: 2004
-
[47]
Breaking of brightness consistency in optical flow with a lightweight cnn network,
Y . Lin, S. Wang, Y . Jiang, and B. Han, “Breaking of brightness consistency in optical flow with a lightweight cnn network,”IEEE Robotics and Automation Letters, vol. 9, no. 8, pp. 6840–6847, 2024. JOURNAL OF LATEX 18 APPENDIXA COVARIANCE-WEIGHTEDREPROJECTION This section details the covariance formulation proposed in Sec. III-A. Given measurement uncert...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.