ContextSniper: AntTrail's Token-Efficient Code Memory for Repository-Level Program Repair
Pith reviewed 2026-07-03 14:06 UTC · model grok-4.3
The pith
ContextSniper equips repository repair agents with a precision evidence selector that cuts token use by up to 51.5 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
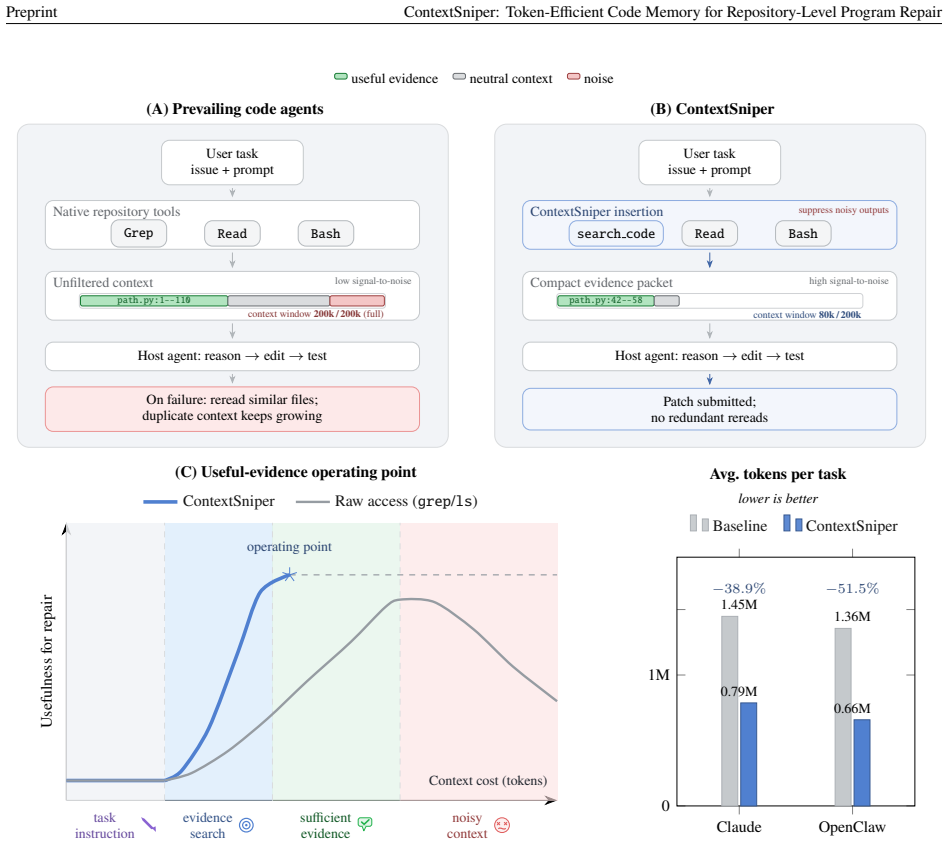
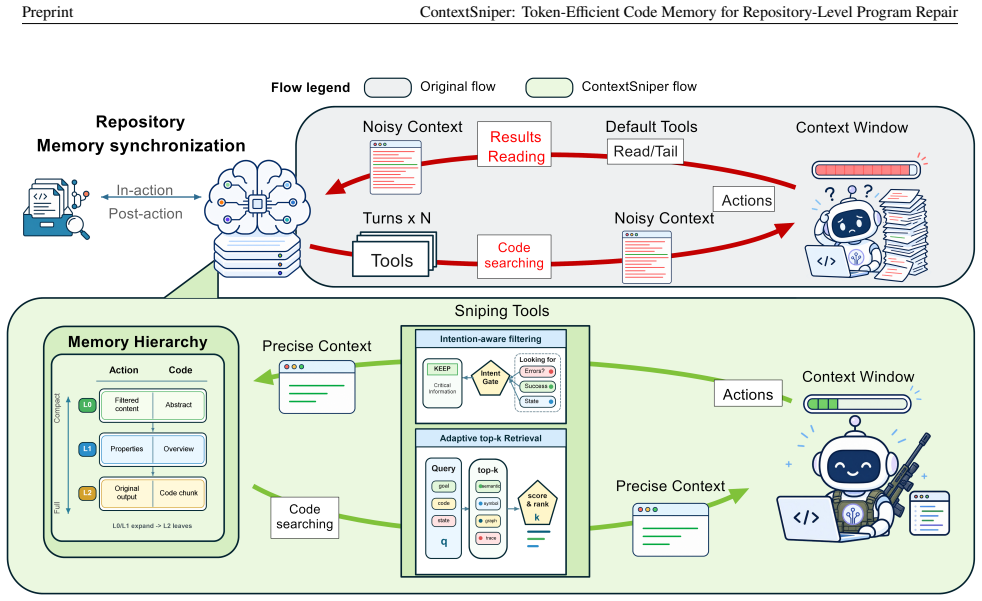
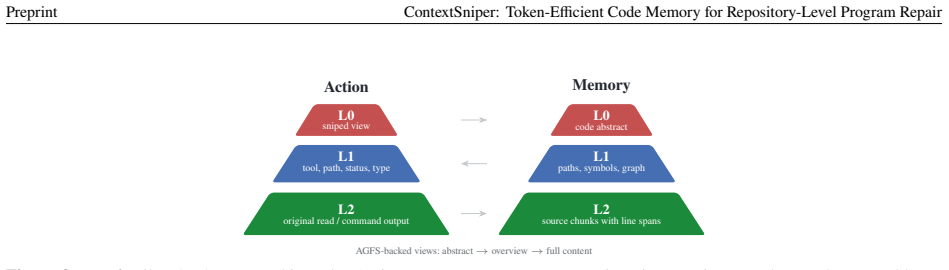
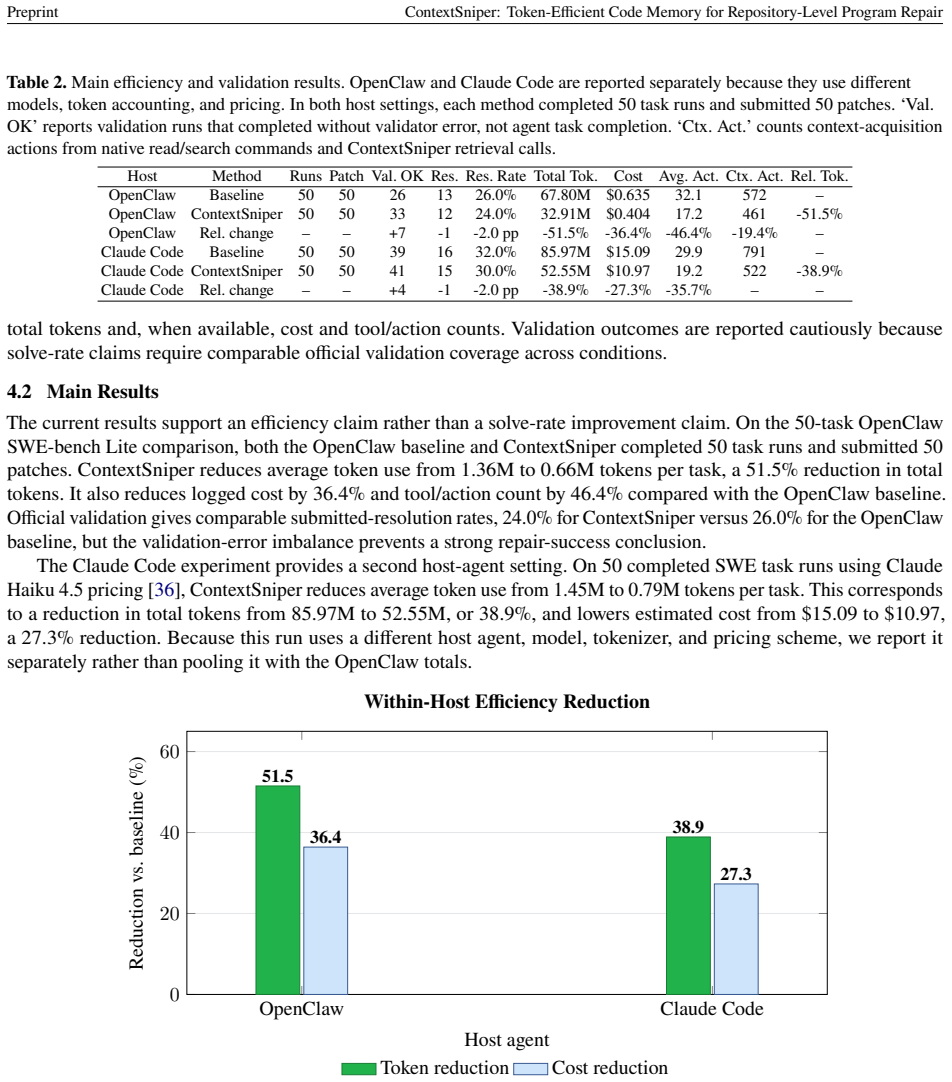
ContextSniper implements the Sniper feature for precision evidence selection: it retrieves candidate code and runtime evidence, ranks it with hybrid retrieval signals, filters long outputs through an intention-aware context gate, and returns compact evidence packets while preserving recoverable source context outside the prompt. On SWE-bench Lite with 50 task runs per condition, this yields total token reductions of 51.5 percent and logged cost reductions of 36.4 percent for OpenClaw, plus 38.9 percent token and 27.3 percent estimated cost reductions for Claude Code, while submitted-resolution rates decrease only slightly from 26.0 percent to 24.0 percent and from 32.0 percent to 30.0 percen
What carries the argument
The Sniper feature, which retrieves candidate code and runtime evidence, ranks it with hybrid retrieval signals, filters long outputs through an intention-aware context gate, and returns compact evidence packets.
If this is right
- Total token use drops by 51.5 percent for OpenClaw and 38.9 percent for Claude Code on SWE-bench Lite.
- Logged or estimated costs decrease by 36.4 percent and 27.3 percent respectively under the same conditions.
- Submitted-resolution rates fall only slightly, by 2 percentage points in each tested agent.
- Recoverable source context remains available outside the prompt for any needed follow-up.
Where Pith is reading between the lines
- The same selection pipeline could support extended agent sessions on larger repositories before context limits are reached.
- Comparable filtering steps might reduce costs in other LLM agent workflows that scan full codebases, such as debugging or test generation.
- Public release of the pilot testing scripts enables direct checks of the reported token and cost figures on additional tasks.
Load-bearing premise
The Sniper feature's retrieval, hybrid ranking, and intention-aware context gate preserve all evidence required for the agent to maintain near-baseline resolution rates without discarding critical information.
What would settle it
A set of SWE-bench Lite tasks where the baseline agent succeeds by using a code snippet or log entry that the context gate removes would produce a substantially larger drop in resolution rate than the observed 2 percentage points.
Figures


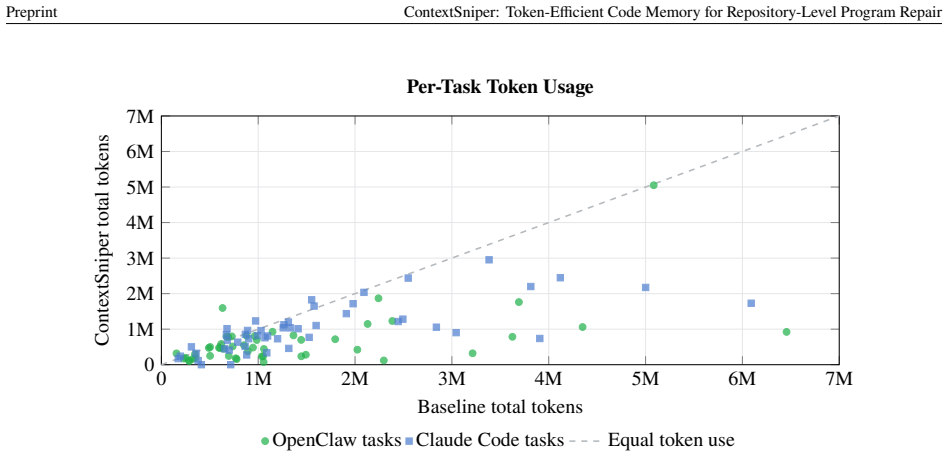
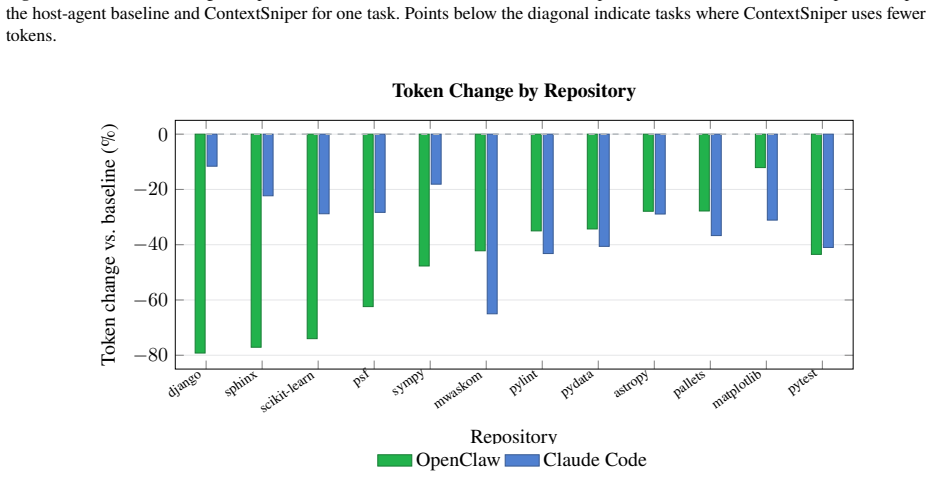
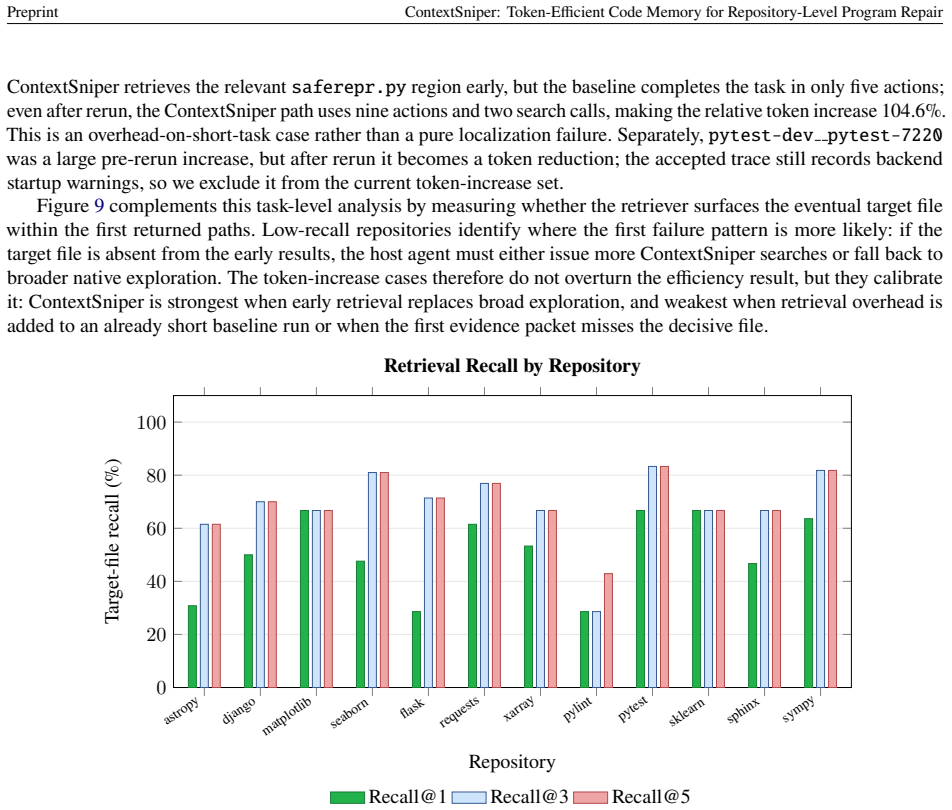
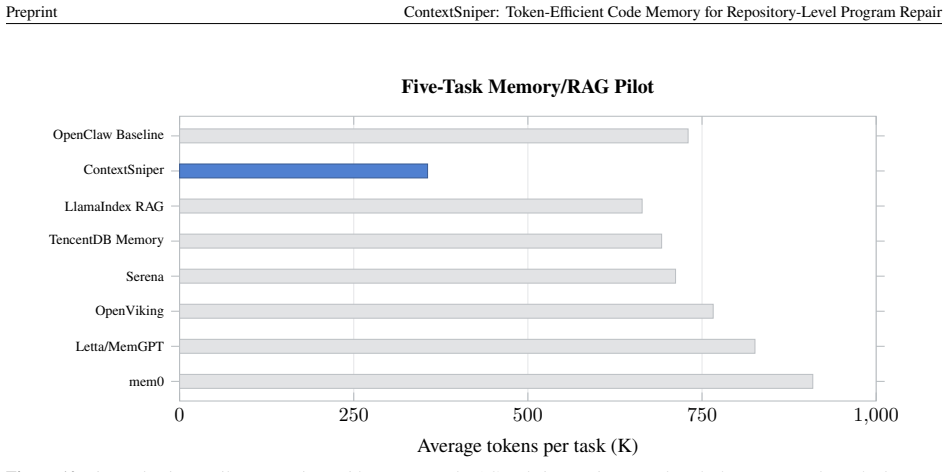
read the original abstract
Large language model agents can repair real repository issues, but they often spend large context budgets on whole-file reads, broad searches, and long terminal outputs where useful evidence is mixed with irrelevant code and logs. This paper presents ContextSniper, AntTrail's token-efficient code memory layer for repository-level program repair. As the coding specialization of AntTrail's broader agent memory engine, ContextSniper implements the Sniper feature for precision evidence selection: it retrieves candidate code and runtime evidence, ranks it with hybrid retrieval signals, filters long outputs through an intention-aware context gate, and returns compact evidence packets while preserving recoverable source context outside the prompt. We evaluate ContextSniper on SWE-bench Lite with OpenClaw and Claude Code, using 50 task runs per host-agent condition. ContextSniper reduces total token use by 51.5% and logged cost by 36.4% for OpenClaw, and reduces total token use by 38.9% and estimated cost by 27.3% for Claude Code. Submitted-resolution rates decrease slightly, from 26.0% to 24.0% for OpenClaw and from 32.0% to 30.0% for Claude Code. ContextSniper's pilot testing scripts are open-sourced at https://github.com/Calluking/ContextSniper
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ContextSniper as AntTrail's token-efficient code memory layer specialized for repository-level program repair. It describes a Sniper feature that retrieves candidate evidence, applies hybrid ranking, and uses an intention-aware context gate to produce compact evidence packets. On SWE-bench Lite with 50 task runs per condition, the system is evaluated with OpenClaw and Claude Code hosts; it reports 51.5% and 38.9% reductions in total token use (with corresponding cost reductions of 36.4% and 27.3%) while submitted-resolution rates fall only from 26% to 24% and 32% to 30%, respectively. Pilot scripts are open-sourced.
Significance. If the reported token and cost savings prove robust while preserving resolution rates, the work would offer a practical advance for scaling LLM-based repository repair agents, where context budgets are a primary deployment constraint. The open-sourcing of testing scripts provides a modest reproducibility asset.
major comments (2)
- [Abstract] Abstract / Evaluation paragraph: the headline quantitative claims (51.5% token reduction for OpenClaw, 38.9% for Claude Code; 2 pp resolution drops) rest on aggregate numbers from 50 runs per condition but supply no baselines, per-run variance, statistical tests, or ablation results that would confirm the intention-aware context gate never discards evidence required for the tasks that flip from success to failure.
- [Abstract] Pipeline description (Sniper feature): the central assumption that hybrid retrieval plus the intention-aware context gate 'preserve recoverable source context' and maintain near-baseline resolution is stated at a high level but is unsupported by mechanism details, failure-case analysis, or an ablation that removes the gate; with only a 2 pp aggregate drop this assumption is load-bearing for the claim that savings come at negligible performance cost.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the quantitative claims and the supporting evidence for ContextSniper's mechanisms. We respond point-by-point below and indicate where revisions will be made to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract / Evaluation paragraph: the headline quantitative claims (51.5% token reduction for OpenClaw, 38.9% for Claude Code; 2 pp resolution drops) rest on aggregate numbers from 50 runs per condition but supply no baselines, per-run variance, statistical tests, or ablation results that would confirm the intention-aware context gate never discards evidence required for the tasks that flip from success to failure.
Authors: The evaluation protocol uses 50 independent task runs per condition to derive the reported aggregates, as stated in the manuscript. We agree that the abstract would benefit from additional statistical context. In the revision we will add per-run standard deviations to the headline figures and include a brief note on sample size and the absence of formal significance testing. The full manuscript contains a failure-case analysis (Section 5) showing that the two-percentage-point drops were attributable to factors outside the context gate; however, no explicit ablation that disables the gate is present, and we will explicitly note this limitation rather than claim such confirmation. revision: partial
-
Referee: [Abstract] Pipeline description (Sniper feature): the central assumption that hybrid retrieval plus the intention-aware context gate 'preserve recoverable source context' and maintain near-baseline resolution is stated at a high level but is unsupported by mechanism details, failure-case analysis, or an ablation that removes the gate; with only a 2 pp aggregate drop this assumption is load-bearing for the claim that savings come at negligible performance cost.
Authors: Section 3 of the manuscript supplies the mechanism details for hybrid ranking and the intention-aware context gate, including how recoverable context is preserved outside the prompt. The small aggregate drop is offered as supporting evidence for low performance cost, with the open-sourced pilot scripts enabling independent verification. We will revise the abstract to cross-reference these sections and incorporate a concise failure-case summary drawn from the existing manuscript analysis. An ablation that removes the gate is not included and would require new experiments; we will acknowledge this gap in the revised discussion. revision: partial
Circularity Check
No circularity: results are direct empirical measurements on benchmark tasks
full rationale
The paper describes a retrieval/filtering pipeline and reports aggregate token/cost savings plus resolution rates from 50 runs per condition on SWE-bench Lite. No equations, fitted parameters, predictions, or self-citations appear in the provided text. All headline numbers are measured outcomes, not derived quantities that reduce to the inputs by construction. The central claim therefore stands on external benchmark data rather than any self-referential step.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “SWE-bench: Can language models resolve real-world GitHub issues?” inInternational Conference on Learning Representations, 2024. [Online]. Available: https://arxiv.org/abs/2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. R. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” 2024. [Online]. Available: https://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Autocoderover: Au- tonomous program improvement, 2024
Y. Zhang, H. Ruan, Z. Fan, and A. Roychoudhury, “AutoCodeRover: Autonomous program improvement,” 2024. [Online]. Available: https://arxiv.org/abs/2404.05427
-
[4]
Agentless: Demystifying LLM-based software engineering agents,
C. S. Xia, Y. Deng, S. Dunn, and L. Zhang, “Agentless: Demystifying LLM-based software engineering agents,”
-
[5]
Agentless: Demystifying LLM-based Software Engineering Agents
[Online]. Available: https://arxiv.org/abs/2407.01489
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Claude code documentation: Overview
Anthropic, “Claude code documentation: Overview.” [Online]. Available: https://code.claude.com/docs/en/ overview
-
[7]
ACON: Optimizing Context Compression for Long-horizon LLM Agents
M. Kang, W.-N. Chen, D. Han, H. A. Inan, L. Wutschitz, Y. Chen, R. Sim, and S. Rajmohan, “ACON: Optimizing context compression for long-horizon LLM agents,” 2025. [Online]. Available: https://arxiv.org/abs/2510.00615
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Codebase-memory: Tree-sitter-based knowledge graphs for LLM code exploration via MCP,
M. Vogel, F. Meyer-Eschenbach, S. Kohler, E. Gr¨ unewald, and F. Balzer, “Codebase-memory: Tree-sitter-based knowledge graphs for LLM code exploration via MCP,” 2026. [Online]. Available: https://arxiv.org/abs/2603.27277
-
[9]
Lost in the Middle: How Language Models Use Long Contexts
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,”Transactions of the Association for Computational Linguistics, vol. 12, pp. 157–173, 2024. [Online]. Available: https://arxiv.org/abs/2307.03172
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. K¨ uttler, M. Lewis, W.-t. Yih, T. Rockt¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 9459–9474. [Online]. Available: https://arxiv.org/abs/2005.11401 14 Prepr...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[11]
RepoGraph: Enhancing AI software engineering with repository-level code graph,
S. Ouyang, W. Yu, K. Ma, Z. Xiao, Z. Zhang, M. Jia, J. Han, H. Zhang, and D. Yu, “RepoGraph: Enhancing AI software engineering with repository-level code graph,” 2024. [Online]. Available: https://arxiv.org/abs/2410.14684
-
[12]
Enhancing repository-level software repair via repository-aware knowledge graphs,
B. Yang, J. Ren, S. Jin, Y. Liu, F. Liu, B. Le, and H. Tian, “Enhancing repository-level software repair via repository-aware knowledge graphs,” 2025. [Online]. Available: https://arxiv.org/abs/2503.21710
-
[13]
Improving code localization with repository memory,
B. Wang, W. Xu, Y. Li, M. Gao, Y. Xie, H. Sun, and D. Chen, “Improving code localization with repository memory,” 2025. [Online]. Available: https://arxiv.org/abs/2510.01003
-
[14]
Llmlingua: Com- pressing prompts for accelerated inference of large language models, 2023
H. Jiang, Q. Wu, C.-Y. Lin, Y. Yang, and L. Qiu, “LLMLingua: Compressing prompts for accelerated inference of large language models,” 2023. [Online]. Available: https://arxiv.org/abs/2310.05736
-
[15]
LongLLMLingua: Extending LLMs’ context windows without tuning,
——, “LongLLMLingua: Extending LLMs’ context windows without tuning,” 2024. [Online]. Available: https://arxiv.org/abs/2403.12957
-
[16]
RECOMP: Improving retrieval-augmented LMs with compression and selective augmentation,
F. Xu, W. Shi, and E. Choi, “RECOMP: Improving retrieval-augmented LMs with compression and selective augmentation,” 2023. [Online]. Available: https://arxiv.org/abs/2310.04408
-
[17]
COMPACT: Compressing retrieved documents actively for question answering,
C. Yoon, T. Lee, H. Hwang, M. Jeong, and J. Kang, “COMPACT: Compressing retrieved documents actively for question answering,” 2024. [Online]. Available: https://arxiv.org/abs/2407.09014
-
[18]
Selective Context: Compress input to ChatGPT or other LLMs,
Selective Context Contributors, “Selective Context: Compress input to ChatGPT or other LLMs,” 2023. [Online]. Available: https://github.com/liyucheng09/Selective Context
2023
-
[19]
Compressing context to enhance inference efficiency of large language models,
A. Chevalier, A. Wettig, A. Ajith, and D. Chen, “Compressing context to enhance inference efficiency of large language models,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 6322–6333. [Online]. Available: https://aclanthology.org/2023.emnlp-main.391/
2023
-
[20]
ctxbudgeter: ContextOps toolkit for production AI agents
ctxbudgeter Contributors, “ctxbudgeter: ContextOps toolkit for production AI agents.” [Online]. Available: https://github.com/Kayariyan28/ctxbudgeter
-
[21]
Token Reducer: Local-first context compression for Claude Code
Token Reducer Contributors, “Token Reducer: Local-first context compression for Claude Code.” [Online]. Available: https://github.com/Madhan230205/token-reducer
-
[22]
RTK: Rust token killer
RTK Contributors, “RTK: Rust token killer.” [Online]. Available: https://github.com/rtk-ai/rtk
-
[23]
Headroom: The context compression layer for AI agents
Headroom Contributors, “Headroom: The context compression layer for AI agents.” [Online]. Available: https://github.com/headroomlabs-ai/headroom
-
[24]
Bearing: Task runner for directing AI coding agents
Bearing Contributors, “Bearing: Task runner for directing AI coding agents.” [Online]. Available: https://github.com/rocketvish/bearing
-
[25]
OpenClaw: Personal AI assistant
OpenClaw Contributors, “OpenClaw: Personal AI assistant.” [Online]. Available: https://github.com/openclaw/ openclaw
-
[26]
SWE-Exp: Experience-driven software issue resolution,
S. Chen, S. Lin, Y. Shi, H. Lian, X. Gu, L. Yun, D. Chen, L. Cao, J. Liu, N. Xia, and Q. Wang, “SWE-Exp: Experience-driven software issue resolution,” 2025. [Online]. Available: https://arxiv.org/abs/2507.23361
-
[27]
EXPEREPAIR: Dual-Memory Enhanced LLM-based Repository-Level Program Repair
F. Mu, J. Wang, L. Shi, S. Wang, S. Li, and Q. Wang, “EXPEREPAIR: Dual-memory enhanced LLM-based repository-level program repair,” 2025. [Online]. Available: https://arxiv.org/abs/2506.10484
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
MemGovern: Enhancing code agents through learning from governed human experiences,
Q. Wang, Z. Cheng, S. Zhang, F. Liu, R. Xu, H. Lian, K. Wang, X. Yu, J. Yin, S. Hu, Y. Hu, S. Zhang, Y. Liu, R. Chen, and H. Wang, “MemGovern: Enhancing code agents through learning from governed human experiences,” 2026. [Online]. Available: https://arxiv.org/abs/2601.06789
-
[29]
Structurally aligned subtask-level memory for software engineering agents,
K. Shen, J. Zhang, C. Sun, W. Zeng, and Y. Yue, “Structurally aligned subtask-level memory for software engineering agents,” 2026. [Online]. Available: https://arxiv.org/abs/2602.21611
-
[30]
MEMCoder: Multi-dimensional Evolving Memory for Private-Library-Oriented Code Generation
M. Li, T. Chen, G. Yang, and J. Li, “MEMCoder: Multi-dimensional evolving memory for private-library-oriented code generation,” 2026. [Online]. Available: https://arxiv.org/abs/2604.24222
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Learning to commit: Generating organic pull requests via online repository memory,
M. Li, L. H. Xu, Q. Tan, T. Cao, and Y. Liu, “Learning to commit: Generating organic pull requests via online repository memory,” 2026. [Online]. Available: https://arxiv.org/abs/2603.26664
-
[32]
The probabilistic relevance framework: BM25 and beyond,
S. Robertson and H. Zaragoza, “The probabilistic relevance framework: BM25 and beyond,” inFoundations and Trends in Information Retrieval, 2009, vol. 3, no. 4, pp. 333–389
2009
-
[33]
Reciprocal rank fusion outperforms condorcet and individual rank learning methods,
G. V. Cormack, C. L. A. Clarke, and S. Buettcher, “Reciprocal rank fusion outperforms condorcet and individual rank learning methods,” inProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2009, pp. 758–759
2009
-
[34]
ripgrep
A. Gallant, “ripgrep.” [Online]. Available: https://github.com/BurntSushi/ripgrep
-
[35]
AGFS: Agent file system
AGFS Contributors, “AGFS: Agent file system.” [Online]. Available: https://github.com/c4pt0r/agfs 15 Preprint ContextSniper: Token-Efficient Code Memory for Repository-Level Program Repair
-
[36]
Universal ctags
Universal Ctags Contributors, “Universal ctags.” [Online]. Available: https://github.com/universal-ctags/ctags
-
[37]
Claude models overview
Anthropic, “Claude models overview.” [Online]. Available: https://platform.claude.com/docs/en/about-claude/ models/overview
-
[38]
mem0: Universal memory layer for AI agents
mem0 Contributors, “mem0: Universal memory layer for AI agents.” [Online]. Available: https: //github.com/mem0ai/mem0
-
[39]
Letta: Stateful agents and MemGPT
Letta Contributors, “Letta: Stateful agents and MemGPT.” [Online]. Available: https://github.com/letta-ai/letta
-
[40]
OpenViking: Context database for AI agents
OpenViking Contributors, “OpenViking: Context database for AI agents.” [Online]. Available: https://github.com/volcengine/OpenViking
-
[41]
TencentDB Agent Memory
TencentDB Agent Memory Contributors, “TencentDB Agent Memory.” [Online]. Available: https: //github.com/TencentCloud/TencentDB-Agent-Memory
-
[42]
Serena: Semantic coding toolkit for agents
Serena Contributors, “Serena: Semantic coding toolkit for agents.” [Online]. Available: https: //github.com/oraios/serena
-
[43]
LlamaIndex: Framework for agentic applications and retrieval-augmented generation
LlamaIndex Contributors, “LlamaIndex: Framework for agentic applications and retrieval-augmented generation.” [Online]. Available: https://github.com/run-llama/llama index 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.