Zeus: Towards Tuning-Free Foundation Model for Time Series Analysis
Pith reviewed 2026-07-03 17:32 UTC · model grok-4.3
The pith
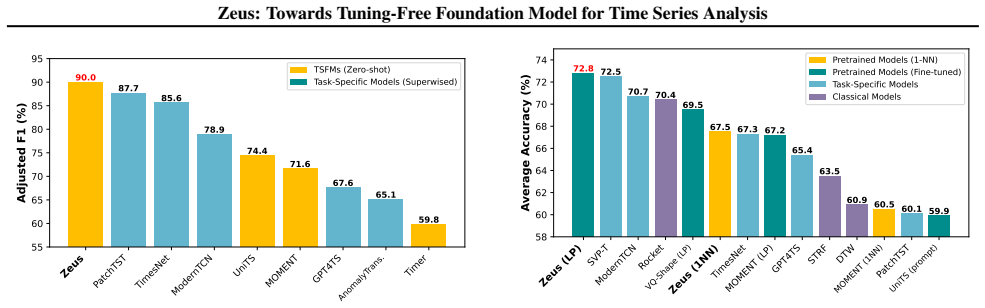
Zeus delivers competitive results on five time series tasks without any task-specific fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
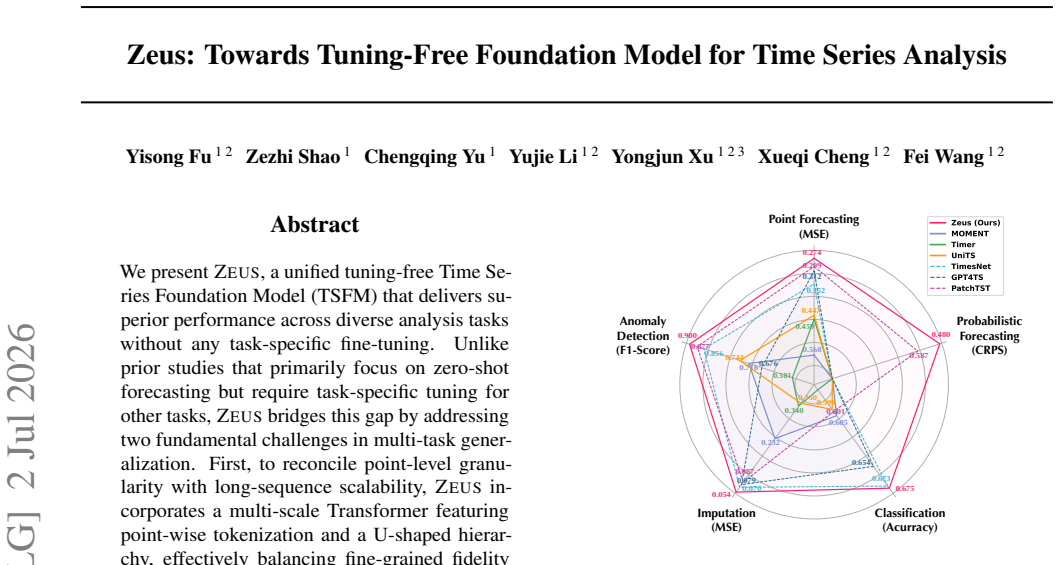
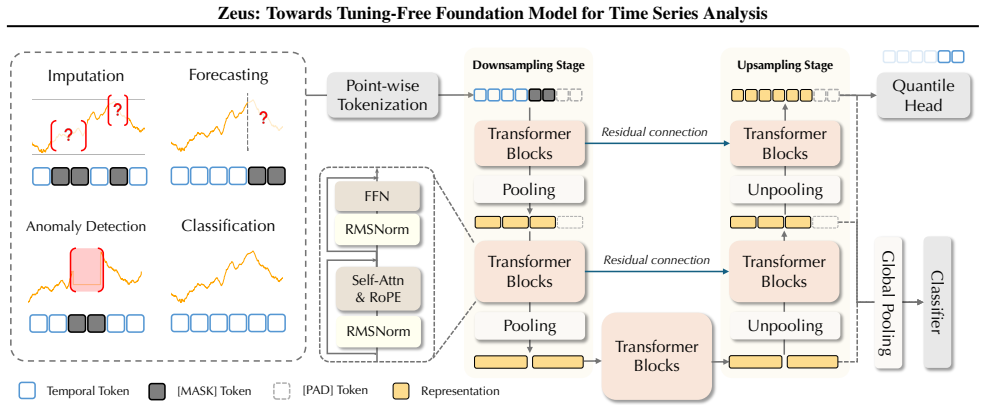
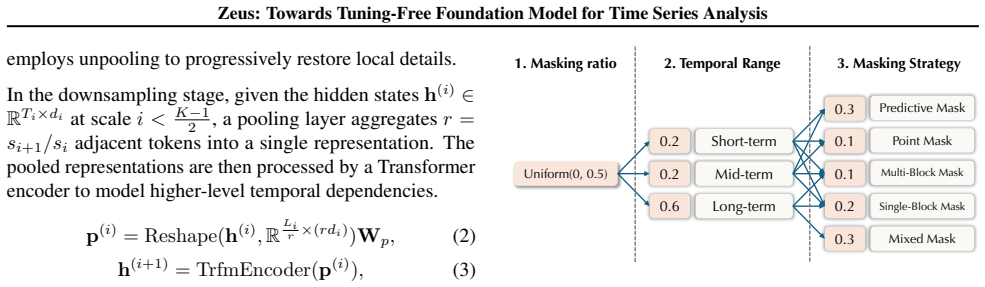
Zeus is a unified tuning-free Time Series Foundation Model that reconciles point-level granularity with long-sequence scalability through a multi-scale Transformer that uses point-wise tokenization and a U-shaped hierarchy, while Multi-Objective Temporal Masking accommodates the distinct inductive biases of extrapolation, interpolation, and global abstraction tasks inside one training regime, yielding competitive performance across five representative tasks in a fully tuning-free setting.
What carries the argument
Multi-scale Transformer with point-wise tokenization and U-shaped hierarchy, together with Multi-Objective Temporal Masking (MOTM)
If this is right
- A single pretrained model can be applied directly to extrapolation, interpolation, and abstraction tasks without separate adaptation steps.
- Point-level predictions remain feasible even when input sequences are long.
- Heterogeneous task biases are handled by one masking objective rather than multiple specialized heads or losses.
- Computational overhead of repeated fine-tuning across tasks is avoided.
Where Pith is reading between the lines
- If the architecture generalizes, similar multi-scale plus multi-objective masking designs could be tested on other sequential domains such as audio or video.
- The approach suggests that foundation-model scale may reduce the traditional need for per-task hyperparameter search in time-series work.
- Longer sequences or streaming settings could serve as a direct test of whether the U-shaped hierarchy continues to control memory and compute costs.
Load-bearing premise
The combination of point-wise tokenization, U-shaped multi-scale hierarchy, and Multi-Objective Temporal Masking is enough to remove any need for task-specific fine-tuning while preserving accuracy on point-level and long-sequence problems.
What would settle it
A controlled comparison in which, on any one of the five tasks, a model that receives task-specific fine-tuning produces statistically higher accuracy than Zeus in its tuning-free configuration would falsify the central claim.
Figures
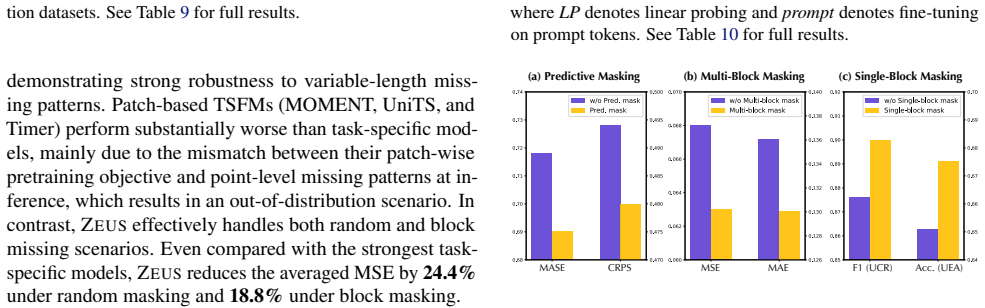
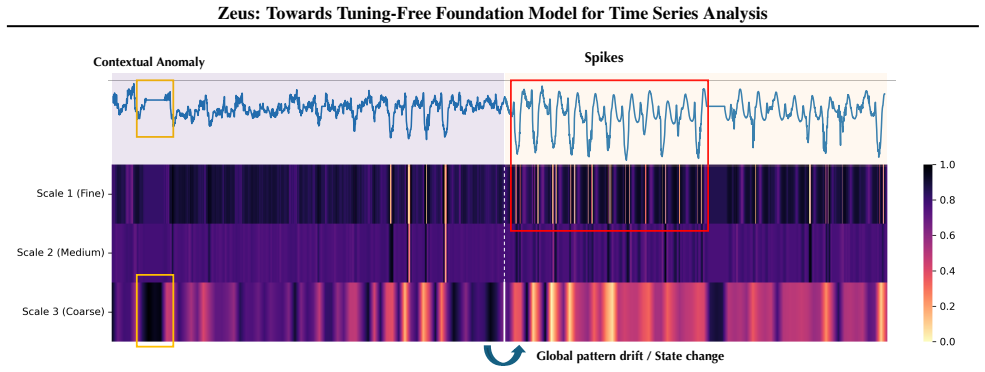
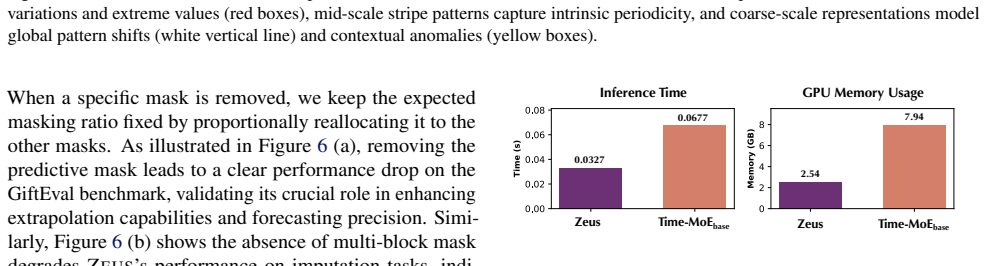
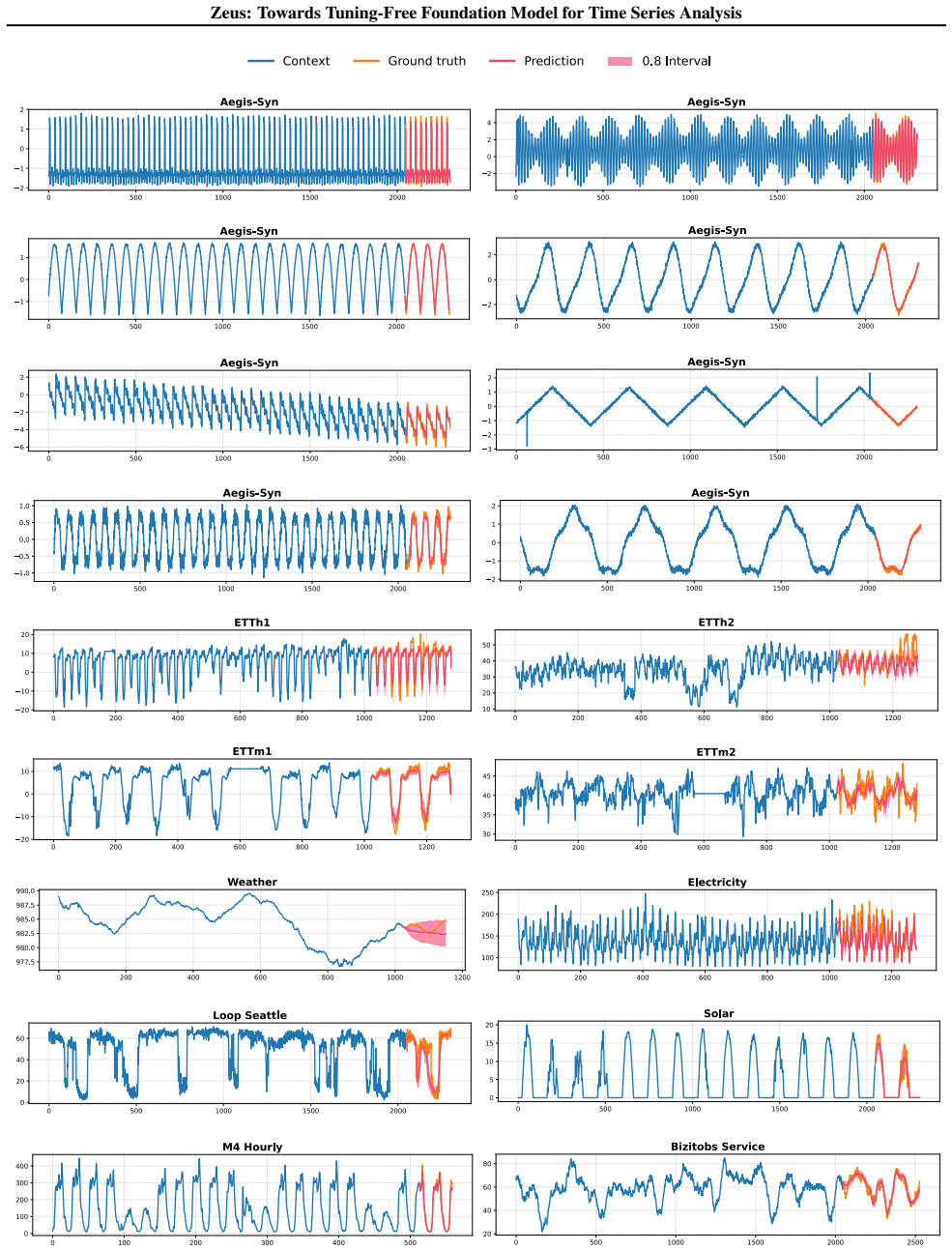
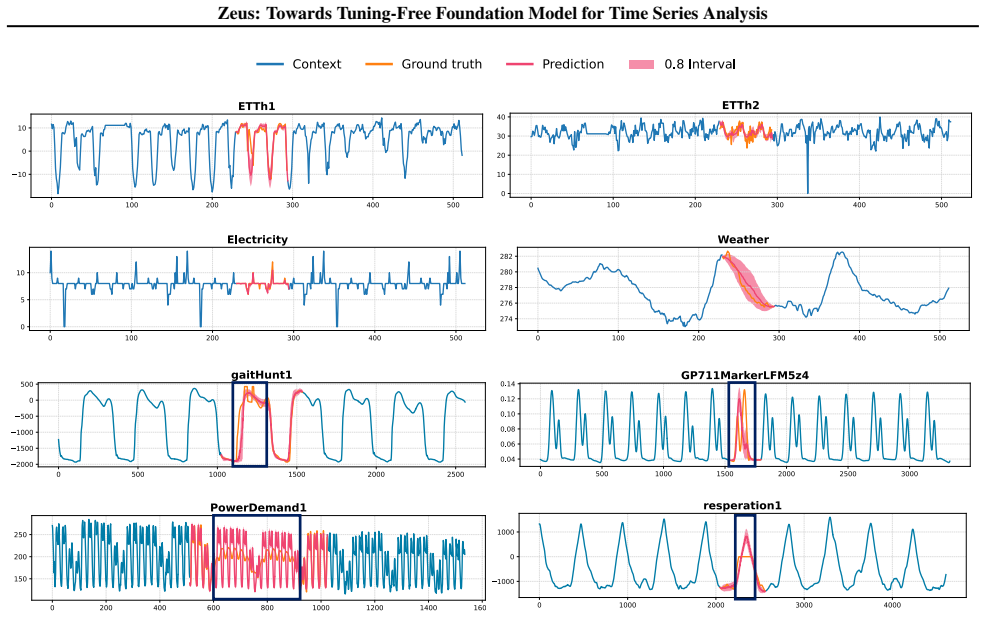
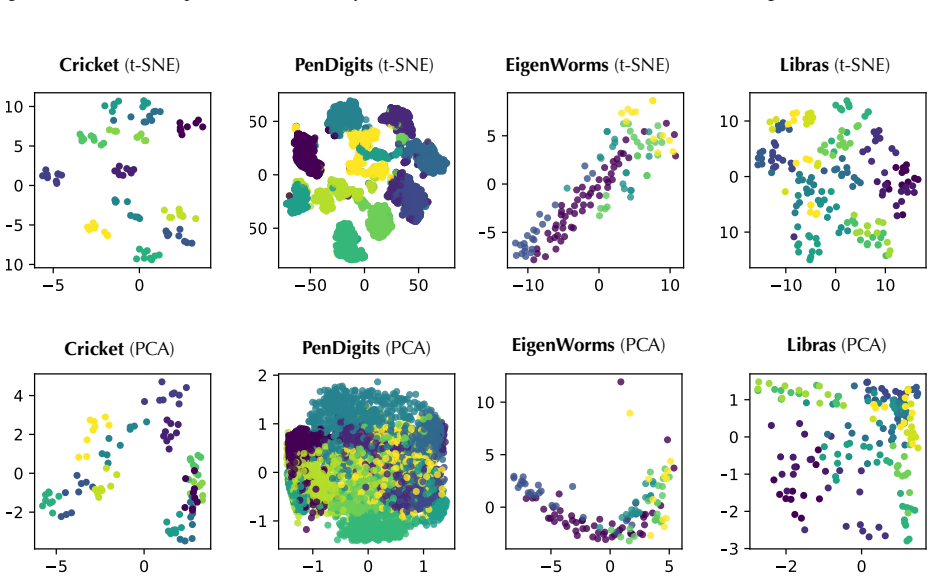
read the original abstract
We present Zeus, a unified tuning-free Time Series Foundation Model (TSFM) that delivers superior performance across diverse analysis tasks without any task-specific fine-tuning. Unlike prior studies that primarily focus on zero-shot forecasting but require task-specific tuning for other tasks, Zeus bridges this gap by addressing two fundamental challenges in multi-task generalization. First, to reconcile point-level granularity with long-sequence scalability, Zeus incorporates a multi-scale Transformer featuring point-wise tokenization and a U-shaped hierarchy, effectively balancing fine-grained fidelity with computational efficiency. Second, to accommodate varying inductive biases across different tasks, Zeus introduces Multi-Objective Temporal Masking (MOTM), a unified strategy that supports heterogeneous tasks (e.g., extrapolation, interpolation, and global abstraction) within a single framework. Extensive experiments across five representative tasks demonstrate that Zeus consistently achieves competitive results in tuning-free settings, underscoring its potential as a general-purpose TSFM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Zeus, a unified tuning-free Time Series Foundation Model (TSFM) that uses a multi-scale Transformer with point-wise tokenization and U-shaped hierarchy to balance point-level granularity and long-sequence scalability, together with Multi-Objective Temporal Masking (MOTM) to accommodate heterogeneous inductive biases across tasks such as extrapolation, interpolation, and global abstraction. It claims that this design enables competitive performance across five representative tasks without any task-specific fine-tuning.
Significance. If the reported results hold, the work would be a meaningful step toward general-purpose TSFMs that eliminate per-task tuning, addressing longstanding tensions between granularity, scalability, and task-specific biases in time series modeling. The explicit design rationale for reconciling these elements is a strength.
minor comments (2)
- Abstract: while the summary of the two core challenges and proposed solutions is clear, the abstract would be strengthened by naming the five tasks and reporting at least one key quantitative comparison (e.g., average rank or relative error) to make the central performance claim more concrete for readers.
- The manuscript would benefit from an explicit statement of the datasets used and the precise definition of 'tuning-free' (e.g., whether any hyper-parameters are still selected on a validation split) to allow direct replication of the claimed setting.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our manuscript on Zeus, a tuning-free Time Series Foundation Model. The referee accurately summarizes the key contributions, including the multi-scale Transformer with point-wise tokenization and U-shaped hierarchy, as well as Multi-Objective Temporal Masking (MOTM) for handling diverse tasks. We appreciate the recognition of the work's potential significance toward general-purpose TSFMs and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper introduces an architectural design (multi-scale Transformer with point-wise tokenization, U-shaped hierarchy, and MOTM) and reports empirical results on five tasks. No equations, derivations, predictions, or first-principles claims appear that could reduce by construction to fitted parameters, self-citations, or renamed inputs. The central claims rest on experimental validation rather than any load-bearing self-referential step, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[5]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[6]
M. J. Kearns , title =
-
[7]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[8]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[9]
Suppressed for Anonymity , author=
-
[10]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[11]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[12]
arXiv preprint arXiv:2308.08469 , year=
Llm4ts: Two-stage fine-tuning for time-series forecasting with pre-trained llms , author=. arXiv preprint arXiv:2308.08469 , year=
-
[13]
arXiv preprint arXiv:2302.11939 , year=
One Fits All: Power General Time Series Analysis by Pretrained LM , author=. arXiv preprint arXiv:2302.11939 , year=
-
[14]
arXiv preprint arXiv:2310.09751 , year=
UniTime: A Language-Empowered Unified Model for Cross-Domain Time Series Forecasting , author=. arXiv preprint arXiv:2310.09751 , year=
-
[15]
2024 , title =
Liu, Yong and Hu, Tengge and Zhang, Haoran and Wu, Haixu and Wang, Shiyu and Ma, Lintao and Long, Mingsheng , booktitle =. 2024 , title =
2024
-
[16]
and Sinthong, Phanwadee and Kalagnanam, Jayant , booktitle =
Nie, Yuqi and Nguyen, Nam H. and Sinthong, Phanwadee and Kalagnanam, Jayant , booktitle =. 2023 , title =
2023
-
[17]
Proceedings of the AAAI conference on artificial intelligence , volume=
Are transformers effective for time series forecasting? , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[18]
2023 , title =
Wu, Haixu and Hu, Tengge and Liu, Yong and Zhou, Hang and Wang, Jianmin and Long, Mingsheng , booktitle =. 2023 , title =
2023
-
[19]
2024 , title =
donghao, Luo and xue, wang , booktitle =. 2024 , title =
2024
-
[20]
arXiv preprint arXiv:2305.18803 , year=
Koopa: Learning Non-stationary Time Series Dynamics with Koopman Predictors , author=. arXiv preprint arXiv:2305.18803 , year=
-
[21]
arXiv preprint arXiv:1905.10437 , year=
N-BEATS: Neural basis expansion analysis for interpretable time series forecasting , author=. arXiv preprint arXiv:1905.10437 , year=
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Nhits: Neural hierarchical interpolation for time series forecasting , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[23]
International Journal of Forecasting , volume=
The M4 Competition: 100,000 time series and 61 forecasting methods , author=. International Journal of Forecasting , volume=. 2020 , publisher=
2020
-
[24]
arXiv preprint arXiv:2210.03675 , year=
Koopman neural forecaster for time series with temporal distribution shifts , author=. arXiv preprint arXiv:2210.03675 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Film: Frequency improved legendre memory model for long-term time series forecasting , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Advances in Neural Information Processing Systems , volume=
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
arXiv preprint arXiv:2308.08241 , year=
TEST: Text prototype aligned embedding to activate LLM's ability for time series , author=. arXiv preprint arXiv:2308.08241 , year=
-
[28]
arXiv preprint arXiv:2310.04948 , year=
TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting , author=. arXiv preprint arXiv:2310.04948 , year=
-
[29]
IEEE Transactions on Knowledge and Data Engineering , year=
Promptcast: A new prompt-based learning paradigm for time series forecasting , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[30]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[31]
The Eleventh International Conference on Learning Representations , year=
Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting , author=. The Eleventh International Conference on Learning Representations , year=
-
[32]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[33]
Gpt-4 technical report. arxiv 2303.08774 , author=. View in Article , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Emergent Abilities of Large Language Models
Emergent abilities of large language models , author=. arXiv preprint arXiv:2206.07682 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
arXiv preprint arXiv:2310.05063 , year=
Pushing the Limits of Pre-training for Time Series Forecasting in the CloudOps Domain , author=. arXiv preprint arXiv:2310.05063 , year=
-
[36]
On the Opportunities and Risks of Foundation Models
On the opportunities and risks of foundation models , author=. arXiv preprint arXiv:2108.07258 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Proceedings of the IEEE international conference on computer vision , pages=
Aligning books and movies: Towards story-like visual explanations by watching movies and reading books , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[38]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
LoRA: Low-Rank Adaptation of Large Language Models
Lora: Low-rank adaptation of large language models , author=. arXiv preprint arXiv:2106.09685 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
A Very British Affair: Six Britons and the Development of Time Series Analysis During the 20th Century , pages=
Box and Jenkins: time series analysis, forecasting and control , author=. A Very British Affair: Six Britons and the Development of Time Series Analysis During the 20th Century , pages=. 2013 , publisher=
2013
-
[41]
2018 , publisher=
Improving language understanding by generative pre-training , author=. 2018 , publisher=
2018
-
[42]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[43]
Proceedings of the AAAI conference on artificial intelligence , volume=
Informer: Beyond efficient transformer for long sequence time-series forecasting , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[44]
International Conference on Machine Learning , pages=
What language model architecture and pretraining objective works best for zero-shot generalization? , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[45]
arXiv preprint arXiv:2212.10559 , year=
Why can gpt learn in-context? language models secretly perform gradient descent as meta optimizers , author=. arXiv preprint arXiv:2212.10559 , year=
-
[46]
Management science , volume=
Forecasting sales by exponentially weighted moving averages , author=. Management science , volume=. 1960 , publisher=
1960
-
[47]
2015 , publisher=
Time series analysis: forecasting and control , author=. 2015 , publisher=
2015
-
[48]
Advances in neural information processing systems , volume=
A neural probabilistic language model , author=. Advances in neural information processing systems , volume=
-
[49]
2012 , publisher=
Time series analysis by state space methods , author=. 2012 , publisher=
2012
-
[50]
Journal of Machine Learning Research , volume=
Palm: Scaling language modeling with pathways , author=. Journal of Machine Learning Research , volume=
-
[51]
A Survey of Large Language Models
A survey of large language models , author=. arXiv preprint arXiv:2303.18223 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Training Compute-Optimal Large Language Models
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Advances in Neural Information Processing Systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Visual instruction tuning , author=. arXiv preprint arXiv:2304.08485 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[56]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[57]
International Conference on Machine Learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[58]
arXiv preprint arXiv:2304.08424 , year=
Long-term Forecasting with TiDE: Time-series Dense Encoder , author=. arXiv preprint arXiv:2304.08424 , year=
-
[59]
Advances in Neural Information Processing Systems , volume=
Non-stationary transformers: Exploring the stationarity in time series forecasting , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
International Conference on Machine Learning , pages=
Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[61]
Reformer: The Efficient Transformer
Reformer: The efficient transformer , author=. arXiv preprint arXiv:2001.04451 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[62]
The Eleventh International Conference on Learning Representations , year=
Micn: Multi-scale local and global context modeling for long-term series forecasting , author=. The Eleventh International Conference on Learning Representations , year=
-
[63]
Proceedings of the 2000 ACM SIGMOD international conference on Management of data , pages=
LOF: identifying density-based local outliers , author=. Proceedings of the 2000 ACM SIGMOD international conference on Management of data , pages=
2000
-
[64]
2017 International joint conference on neural networks (IJCNN) , pages=
Time series classification from scratch with deep neural networks: A strong baseline , author=. 2017 International joint conference on neural networks (IJCNN) , pages=. 2017 , organization=
2017
-
[65]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. arXiv preprint arXiv:1810.04805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Do better imagenet models transfer better? , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[67]
arXiv preprint arXiv:2302.00861 , year=
SimMTM: A Simple Pre-Training Framework for Masked Time-Series Modeling , author=. arXiv preprint arXiv:2302.00861 , year=
-
[68]
arXiv preprint arXiv:2202.01575 , year=
CoST: Contrastive learning of disentangled seasonal-trend representations for time series forecasting , author=. arXiv preprint arXiv:2202.01575 , year=
-
[69]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[70]
A decoder-only foundation model for time-series forecasting
A decoder-only foundation model for time-series forecasting , author=. arXiv preprint arXiv:2310.10688 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
NIPS 2005 workshop on transfer learning , volume=
To transfer or not to transfer , author=. NIPS 2005 workshop on transfer learning , volume=
2005
-
[72]
BEiT: BERT Pre-Training of Image Transformers
Beit: Bert pre-training of image transformers , author=. arXiv preprint arXiv:2106.08254 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
VideoGPT: Video Generation using VQ-VAE and Transformers
Videogpt: Video generation using vq-vae and transformers , author=. arXiv preprint arXiv:2104.10157 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Momentum contrast for unsupervised visual representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[75]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[76]
Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining , pages=
A transformer-based framework for multivariate time series representation learning , author=. Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining , pages=
-
[77]
Advances in Neural Information Processing Systems , volume=
Learning latent seasonal-trend representations for time series forecasting , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Ts2vec: Towards universal representation of time series , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[79]
Advances in Neural Information Processing Systems , volume=
Self-supervised contrastive pre-training for time series via time-frequency consistency , author=. Advances in Neural Information Processing Systems , volume=
-
[80]
arXiv preprint arXiv:2311.01933 , year=
ForecastPFN: Synthetically-Trained Zero-Shot Forecasting , author=. arXiv preprint arXiv:2311.01933 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.