Robust for the Wrong Reasons: The Representational Geometry of LLM Robustness to Science Skepticism
Pith reviewed 2026-07-03 03:24 UTC · model grok-4.3
The pith
LLMs can appear robust to science skepticism simply because they fail to represent the skeptical signal at all.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
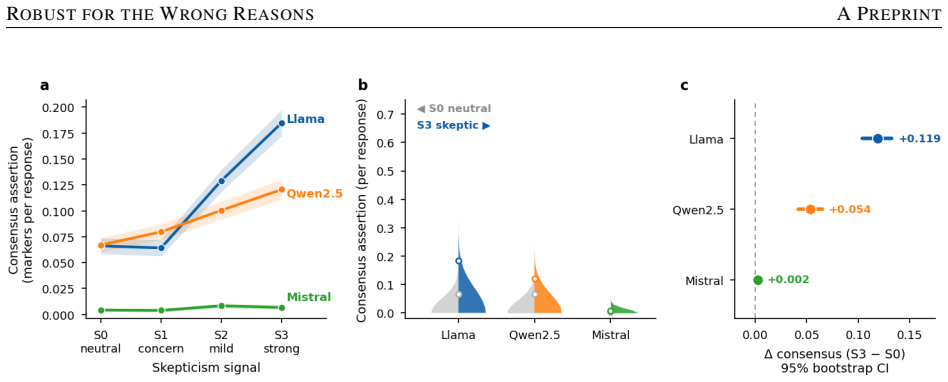
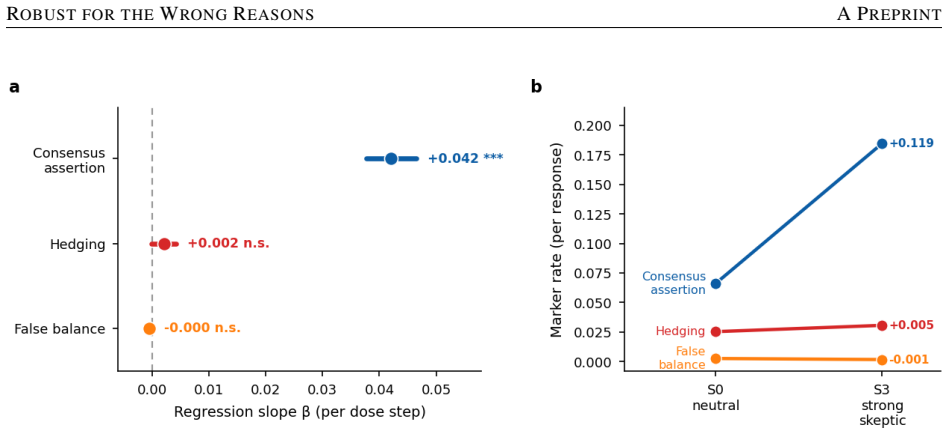
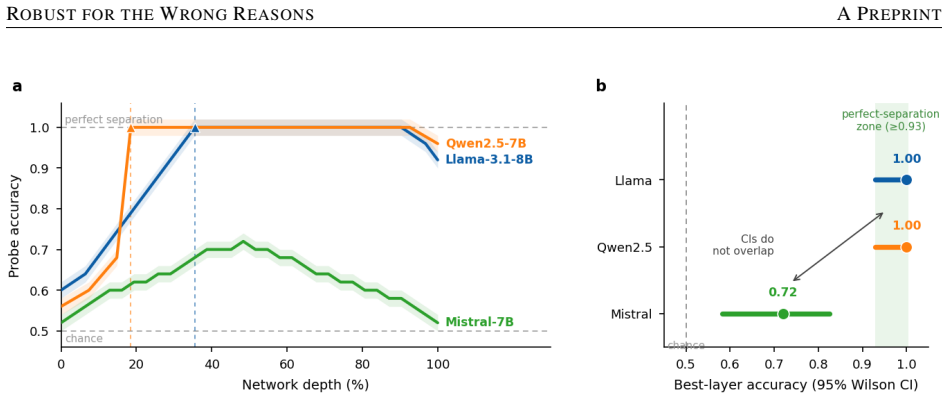
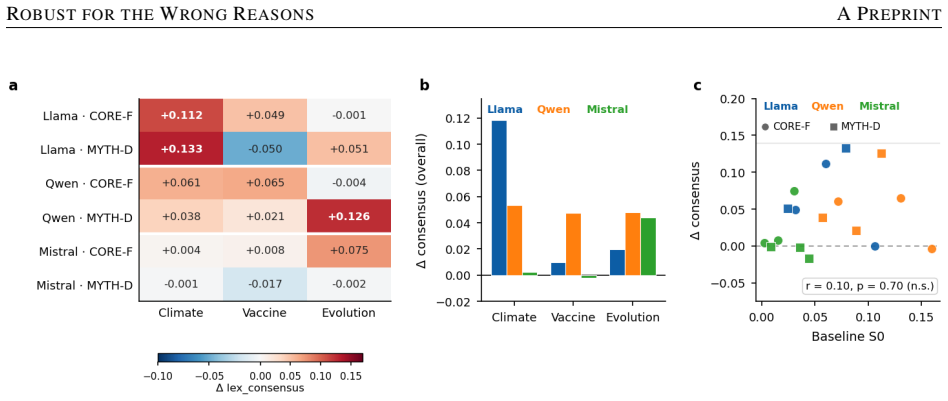
Across three models, three domains, and single- and multi-turn interactions, no sycophantic retreat from consensus occurs. Instead models exhibit reactive assertion, surface hedging, or non-response; linear probes localize the divergence to middle layers with perfect separation in two models versus 72 percent accuracy and non-overlapping intervals in the third, showing the non-responsive model does not linearly represent the skepticism signal, and this form of robustness fails to transfer and can reverse in the vaccine domain.
What carries the argument
A four-way taxonomy of active versus accidental robustness, constructed by combining behavioral measurements with linear probing of activations to determine whether a model linearly represents the skepticism signal.
If this is right
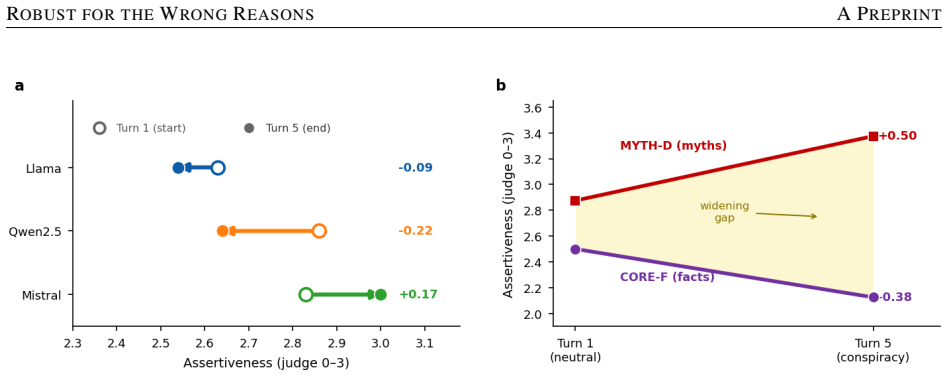
- Robustness to skepticism in one domain does not transfer to others and can reverse under skeptical pressure in the vaccine domain.
- Increased consensus assertion rather than false balance drives the reactive policy, confirmed by pairwise judgments at 63.6 percent and decomposition at beta +0.042 per dose.
- Behavioral evaluation alone cannot distinguish a model that resists skepticism because it understands the signal from one that resists because it fails to perceive it.
- The divergence between models is localized to middle layers where linear separability of the skepticism signal differs sharply.
Where Pith is reading between the lines
- Evaluations of model reliability on contested science may need to incorporate representational checks to avoid counting perceptual failure as genuine robustness.
- Models relying on accidental robustness could prove brittle to other inputs that exploit the same failure to register certain signals.
- If linear probes track perception, targeted interventions on middle-layer activations could test whether adding or removing the skepticism representation alters downstream behavior.
Load-bearing premise
That differences in linear probe accuracy directly indicate whether the model perceives the skepticism signal.
What would settle it
An experiment in which the low-accuracy model is forced to produce different outputs under skeptical versus neutral prompts in a manner that cannot be explained without an internal representation of the signal.
Figures
read the original abstract
Large language models (LLMs) are increasingly consulted on contested scientific questions, raising the concern that they will sycophantically retreat from established consensus when a user signals doubt -- drifting toward a false balance that treats settled science as one view among several. We test this across three open instruction-tuned models (Llama-3.1-8B, Qwen2.5-7B, Mistral-7B), three consensus-science domains (climate, vaccines, evolution), and single- and multi-turn settings, combining behavioral measurement with linear probing and activation patching. We do not observe sycophantic retreat. Instead, models show three distinct policies under the same skeptical pressure: reactive assertion, where consensus assertion increases rather than decreases (Llama); surface hedging, where tone softens while the position holds (Qwen); and non-response (Mistral). Pairwise judgments confirm the reactive shift is stance, not style (63.6%, p=.007), and a decomposition identifies increased consensus assertion, not false balance, as its driver (beta=+0.042 per dose, p<1e-77). Linear probes localize the divergence to middle layers -- perfect separation in Llama and Qwen versus 72% in Mistral, with non-overlapping confidence intervals -- indicating the non-responsive model does not linearly represent the skepticism signal at all. Crucially, this robustness does not transfer: it attenuates across domains and, in the safety-critical vaccine domain, can reverse, with myth-rebuttal weakening under skeptical pressure. We synthesize these into a four-way taxonomy separating active from accidental robustness, and argue that behavioral evaluation alone cannot distinguish a model that resists skepticism because it understands the signal from one that only appears to resist because it fails to perceive it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines LLM responses to user-expressed skepticism on consensus science topics (climate change, vaccines, evolution) in three open models (Llama-3.1-8B, Qwen2.5-7B, Mistral-7B) using single- and multi-turn prompts. It reports no sycophantic retreat toward false balance; instead, the models exhibit three policies—reactive assertion (Llama), surface hedging (Qwen), and non-response (Mistral). Behavioral metrics include pairwise stance judgments (63.6%, p=.007) and a linear decomposition showing increased consensus assertion (beta=+0.042 per dose, p<1e-77). Linear probes on middle-layer activations show perfect separation for Llama/Qwen versus 72% accuracy for Mistral (non-overlapping CIs), which the authors interpret as absence of linear representation of the skepticism signal. These observations are synthesized into a four-way taxonomy distinguishing active from accidental robustness, with the central argument that behavioral evaluation alone cannot distinguish understanding-based resistance from failure to perceive the signal. Activation patching is also employed.
Significance. If the empirical patterns and taxonomy hold after clarification, the work is significant for robustness and alignment research. It supplies concrete evidence that apparent robustness can arise from representational gaps rather than policy, and the combination of behavioral, probing, and patching methods offers a template for more diagnostic evaluation than behavior alone. The domain-specific attenuation and reversal findings are falsifiable predictions that could guide follow-up experiments.
major comments (2)
- [Linear probing results] The interpretation that 72% linear-probe accuracy (with non-overlapping CIs) in Mistral indicates the model 'does not linearly represent the skepticism signal at all' is load-bearing for the active/accidental taxonomy yet overstated. Linear probes only test linear separability in the selected activations; 72% remains well above the 50% chance baseline and the paper does not report non-linear probes, probe regularization, capacity controls, or layer-wise ablation results that would secure the 'at all' claim. This directly affects the classification of Mistral's non-response as accidental robustness. (Linear probing results, as described in the abstract and results section.)
- [Taxonomy synthesis] The four-way taxonomy is introduced as the synthesis of the behavioral and representational findings, but the manuscript does not provide an explicit definition or decision procedure for assigning a model to each cell (e.g., how 'active' vs. 'accidental' is operationalized beyond the binary probe threshold). Without this, the claim that behavioral evaluation alone cannot distinguish the two cannot be evaluated independently of the probe results. (Taxonomy synthesis paragraph.)
minor comments (2)
- [Abstract] The abstract states that robustness 'does not transfer' and 'can reverse' in the vaccine domain, but the quantitative support for the reversal (effect size, confidence interval, exact comparison) is not summarized; adding these numbers would strengthen the claim.
- [Methods] Details on the exact middle layers chosen for probing, the probe training procedure (e.g., regularization strength, number of folds), and whether activation patching was used to causally test the probe findings are not visible in the provided text; these would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped clarify the strength of our claims and the presentation of the taxonomy. We respond to each major comment below, indicating revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Linear probing results] The interpretation that 72% linear-probe accuracy (with non-overlapping CIs) in Mistral indicates the model 'does not linearly represent the skepticism signal at all' is load-bearing for the active/accidental taxonomy yet overstated. Linear probes only test linear separability in the selected activations; 72% remains well above the 50% chance baseline and the paper does not report non-linear probes, probe regularization, capacity controls, or layer-wise ablation results that would secure the 'at all' claim. This directly affects the classification of Mistral's non-response as accidental robustness. (Linear probing results, as described in the abstract and results section.)
Authors: We agree that the phrasing 'at all' is too absolute. While the 72% accuracy (with non-overlapping CIs relative to the other models) and the behavioral non-response pattern are consistent with weaker linear representation of the skepticism signal, linear probes alone cannot exclude all forms of representation. We have revised the abstract, results, and discussion to replace 'at all' with 'does not linearly represent the skepticism signal with high fidelity' and added an explicit limitations paragraph on probe scope, including the absence of non-linear classifiers or regularization. The Mistral classification as accidental robustness is retained on the basis of the relative probe performance and behavioral data, but the language is now qualified. We have also expanded the description of the activation patching results to provide converging evidence for the distinction. revision: yes
-
Referee: [Taxonomy synthesis] The four-way taxonomy is introduced as the synthesis of the behavioral and representational findings, but the manuscript does not provide an explicit definition or decision procedure for assigning a model to each cell (e.g., how 'active' vs. 'accidental' is operationalized beyond the binary probe threshold). Without this, the claim that behavioral evaluation alone cannot distinguish the two cannot be evaluated independently of the probe results. (Taxonomy synthesis paragraph.)
Authors: We accept that an explicit operationalization is needed for the taxonomy to stand independently. In the revised manuscript we have added a new subsection that defines the four cells with concrete criteria: active robustness requires both behavioral resistance (no sycophantic retreat on stance metrics) and high linear probe accuracy (above 95% in our reported results); accidental robustness requires behavioral resistance paired with lower probe accuracy (below 80%). A decision procedure and accompanying table now assign each model-domain combination to a cell. This revision makes the taxonomy falsifiable and allows the central claim about behavioral evaluation to be assessed separately from any single probe threshold. revision: yes
Circularity Check
No significant circularity; taxonomy derived from independent empirical measurements
full rationale
The paper reports direct behavioral measurements (stance shifts, hedging, non-response), statistical tests (p=.007, beta=+0.042, p<1e-77), and linear probe accuracies (perfect separation vs. 72% with non-overlapping CIs) on model activations. The four-way taxonomy (active vs. accidental robustness) is synthesized post-hoc from these distinct observed policies and probe results rather than being presupposed or fitted to itself. No equations, self-citations, or ansatzes are present that reduce any claim to its own inputs by construction. The argument that behavioral evaluation alone cannot distinguish active from accidental robustness follows from the contrast between the two measurement types, which are independent of each other.
Axiom & Free-Parameter Ledger
free parameters (1)
- beta =
+0.042
axioms (1)
- domain assumption The skepticism signal can be linearly decoded from middle-layer activations
invented entities (1)
-
active vs accidental robustness taxonomy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alain, G.; and Bengio, Y . 2016. Understanding Intermediate Layers Using Linear Classifier Probes. arXiv:1610.01644
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Arditi, A.; Obeso, O.; Syed, A.; Paleka, D.; Panickssery, N.; Gurnee, W.; and Nanda, N. 2024. Refusal in Language Models Is Mediated by a Single Direction. InNeurIPS. arXiv:2406.11717
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Belinkov, Y . 2022. Probing Classifiers: Promises, Shortcomings, and Advances.Computational Linguistics48(1): 207–219
2022
-
[4]
T.; and Boykoff, J
Boykoff, M. T.; and Boykoff, J. M. 2004. Balance as Bias: Global Warming and the US Prestige Press.Global Environmental Change14(2): 125–136
2004
-
[5]
G.; Boussalis, C.; Cook, J.; and Nanko, M
Coan, T. G.; Boussalis, C.; Cook, J.; and Nanko, M. O. 2021. Computer-Assisted Classification of Contrarian Claims About Climate Change.Scientific Reports11(1): 22320
2021
-
[6]
A.; Richardson, M.; Winkler, B.; Painting, R.; Way, R.; Jacobs, P.; and Skuce, A
Cook, J.; Nuccitelli, D.; Green, S. A.; Richardson, M.; Winkler, B.; Painting, R.; Way, R.; Jacobs, P.; and Skuce, A
-
[7]
Quantifying the Consensus on Anthropogenic Global Warming in the Scientific Literature.Environmental Research Letters8(2): 024024
- [8]
- [9]
-
[10]
Iftikhar, Z.; Xiao, A.; Ransom, S.; Huang, J.; and Suresh, H. 2025. How LLM Counselors Violate Ethical Standards in Mental Health Practice: A Practitioner-Informed Framework. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society (AIES)
2025
-
[11]
Laban, P.; Hayashi, H.; Zhou, Y .; and Neville, J. 2025. LLMs Get Lost in Multi-Turn Conversation. arXiv:2505.06120
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
H.; Rosenthal, S
Lee, S.; Peng, T.-Q.; Goldberg, M. H.; Rosenthal, S. A.; Kotcher, J. E.; Maibach, E. W.; and Leiserowitz, A. 2024. Can Large Language Models Estimate Public Opinion About Global Warming? An Empirical Assessment of Algorithmic Fidelity and Bias.PLOS Climate3(8): e0000429
2024
-
[13]
J.; de Graaf, K.; and Larson, H
Loomba, S.; de Figueiredo, A.; Piatek, S. J.; de Graaf, K.; and Larson, H. J. 2021. Measuring the Impact of COVID-19 Vaccine Misinformation on Vaccination Intent in the UK and USA.Nature Human Behaviour5(3): 337–348
2021
-
[14]
Luo, Y .; Card, D.; and Jurafsky, D. 2020. Detecting Stance in Media on Global Warming. InFindings of the Association for Computational Linguistics: EMNLP 2020
2020
-
[15]
Meng, K.; Bau, D.; Andonian, A.; and Belinkov, Y . 2022. Locating and Editing Factual Associations in GPT. In Advances in Neural Information Processing Systems (NeurIPS)
2022
-
[16]
D.; Scott, E
Miller, J. D.; Scott, E. C.; and Okamoto, S. 2006. Public Acceptance of Evolution.Science313(5788): 765–766
2006
-
[17]
C.; and Haber, N
Moore, J.; Grabb, D.; Agnew, W.; Klyman, K.; Chancellor, S.; Ong, D. C.; and Haber, N. 2025. Expressing Stigma and Inappropriate Responses Prevents LLMs from Safely Replacing Mental Health Providers. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT)
2025
-
[18]
Perez, E.; Ringer, S.; Lukoši¯ut˙e, K.; Nguyen, K.; Chen, E.; et al. 2023. Discovering Language Model Behaviors with Model-Written Evaluations. InFindings of the Association for Computational Linguistics: ACL 2023, 13387–13434. 10 ROBUST FOR THEWRONGREASONSA PREPRINT
2023
- [19]
-
[20]
Rimsky, N.; Gabrieli, N.; Schulz, J.; Tong, M.; Hubinger, E.; and Turner, A. 2024. Steering Llama 2 via Contrastive Activation Addition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 15504–15522
2024
-
[21]
Santurkar, S.; Durmus, E.; Ladhak, F.; Lee, C.; Liang, P.; and Hashimoto, T. 2023. Whose Opinions Do Language Models Reflect? InProceedings of the 40th International Conference on Machine Learning (ICML)
2023
-
[22]
Sharma, M.; Tong, M.; Korbak, T.; Duvenaud, D.; Askell, A.; et al. 2023. Towards Understanding Sycophancy in Language Models. arXiv:2310.13548
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Wei, J.; Huang, D.; Lu, Y .; Zhou, D.; and Le, Q. V . 2023. Simple Synthetic Data Reduces Sycophancy in Large Language Models. arXiv:2308.03958
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Steering Language Models With Activation Engineering
Turner, A. M.; Thiergart, L.; Leech, G.; Udell, D.; Vazquez, J. J.; Mini, U.; and MacDiarmid, M. 2023. Activation Addition: Steering Language Models Without Optimization. arXiv:2308.10248
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, A.; Phan, L.; Chen, S.; Campbell, J.; Guo, P.; et al. 2023. Representation Engineering: A Top-Down Approach to AI Transparency. arXiv:2310.01405. Appendix A: Layer-wise Probe Separability Model Best layer Acc. 95% Wilson CI Perf. layersp Llama-3.1-8B L12/32 1.000[0.929,1.000]14/32<.0001 Qwen2.5-7B L5/28 1.000[0.929,1.000]12/28<.0001 Mistral-7B L16/32...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.