Mirror Illusion Art
Pith reviewed 2026-07-03 15:27 UTC · model grok-4.3
The pith
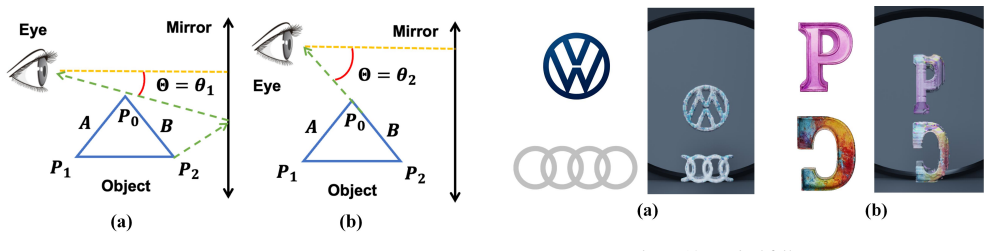
AutoMIA automates design of 3D objects that match two different 2D images when viewed directly and in a mirror.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
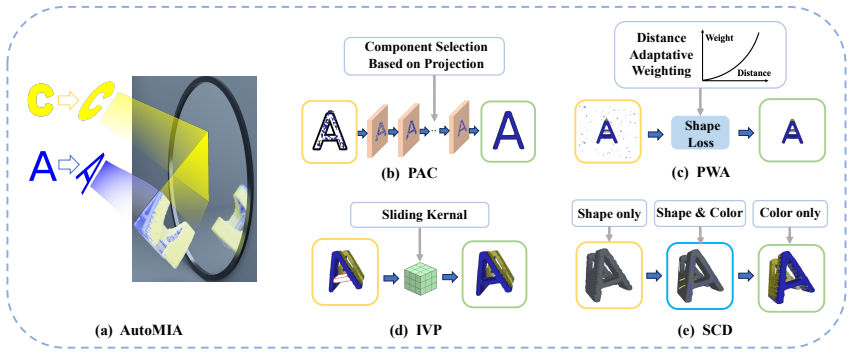
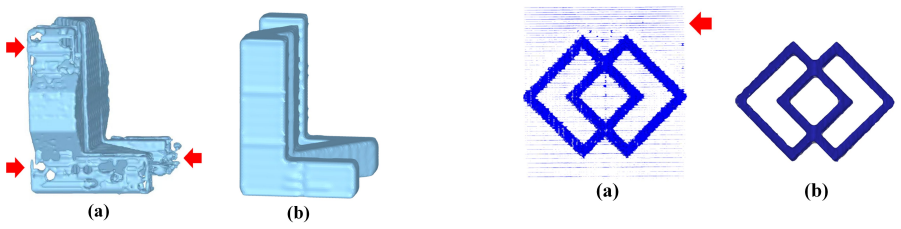
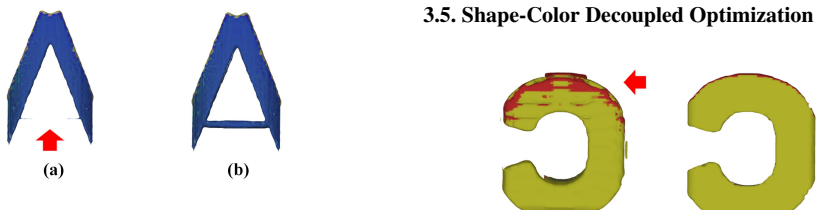
AutoMIA generates diverse smooth Mirror Illusion artworks successfully both in the digital and physical world by jointly optimizing shape and color, using projection-alignment component selection to reduce surface noise, position-weighted adaptive suppression for background noise, internal voxel preservation to prevent internal fractures, and shape-color decoupled optimization to balance the objectives, all with average design time of around 76 seconds and 2.6 GB memory on a single RTX 3090.
What carries the argument
The AutoMIA automated design pipeline that stabilizes joint shape-color optimization through projection-alignment component selection, position-weighted adaptive suppression, internal voxel preservation, and shape-color decoupled optimization.
If this is right
- Mirror illusion objects can be produced automatically for any chosen pair of front and mirror images.
- The generated objects remain smooth and complete enough for both digital rendering and physical 3D printing.
- Design requires only about 76 seconds and 2.6 GB memory on average using a single consumer GPU.
- The pipeline advances inverse graphics by handling joint geometry and texture optimization in this multi-view setting.
Where Pith is reading between the lines
- The same stabilization components could be tested on other inverse problems that optimize multiple constrained views at once.
- If the printed results hold under varied lighting, the method could support consumer tools that turn any two photos into a custom illusion object.
- Decoupling shape and color steps might reduce conflicts in related computational design tasks such as anamorphic or multi-perspective sculptures.
Load-bearing premise
The four mechanisms together suffice to stabilize joint shape-color optimization and suppress artifacts for arbitrary target image pairs without manual intervention or post-processing.
What would settle it
Apply the pipeline to a new pair of target images, fabricate the resulting object, and check whether both the direct and mirror views match the inputs without visible surface noise, background artifacts, or internal fractures.
Figures



read the original abstract
Mirror Illusion Art is a novel reflection-conditioned 3D illusion where one object yields two target appearances (front and mirror). The task is formulated as inverse design from two target 2D images (front and mirror) to a printable 3D object with geometry and texture. Prior topology-driven and shadow-based approaches demand substantial manual effort, optimize shape only, and often yield non-smooth or incomplete geometry. To address these challenges, we propose AutoMIA, an automated Mirror Illusion Art design pipeline that jointly optimizes shape and color. To stabilize optimization and suppress artifacts, four mechanisms are introduced: (1) projection-alignment component (PAC) selection to reduce surface noise, (2) position-weighted adaptive (PWA) suppression for background noise, (3) internal voxel preservation (IVP) to prevent internal fractures, and (4) shape-color decoupled (SCD) optimization that balance shape and color optimization. AutoMIA generate diverse smooth Mirror Illusion artworks successfully both in the digital and physical world, with only around 76s design time and 2.6 GB memory on average using a single RTX 3090, advancing inverse graphics and computational design. Our code is available at https://github.com/zxp555/AutoMIA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AutoMIA, an automated pipeline for inverse design of Mirror Illusion Art: given two target 2D images (front and mirror views), it jointly optimizes the geometry and texture of a printable 3D object that produces both appearances via reflection. Prior manual topology- or shadow-driven methods are critiqued for requiring substantial effort and yielding non-smooth results; AutoMIA introduces four mechanisms—projection-alignment component (PAC) selection, position-weighted adaptive (PWA) suppression, internal voxel preservation (IVP), and shape-color decoupled (SCD) optimization—to stabilize the process. The abstract claims successful generation of diverse smooth objects in both digital and physical domains, with average runtime of ~76 s and 2.6 GB memory on an RTX 3090, and releases code at https://github.com/zxp555/AutoMIA.
Significance. If the central claim holds with rigorous validation, the work would advance inverse graphics and computational design by automating creation of reflection-conditioned 3D illusions that were previously labor-intensive, while delivering efficient, smooth, printable outputs. The open-source code release is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the assertion that the four mechanisms (PAC, PWA, IVP, SCD) are 'together sufficient to stabilize the joint shape-color optimization and suppress artifacts without requiring manual intervention or post-processing for arbitrary target image pairs' is load-bearing for the central claim yet is supported only by selected examples; no ablation studies removing individual components, no quantitative success rates over a held-out set of arbitrary pairs, and no failure-case analysis are referenced.
- [Abstract] Abstract: the claim of 'successful' generation of 'diverse smooth Mirror Illusion artworks' supplies no quantitative metrics (e.g., surface smoothness measures, perceptual similarity scores, print success rates), ablation tables, or baseline comparisons, so the reported 76 s / 2.6 GB figures cannot be assessed for improvement over prior art.
minor comments (1)
- [Abstract] The abstract states the task is 'formulated as inverse design from two target 2D images' but does not specify the exact input representation or loss formulation used in the optimization; a brief equation or pseudocode reference would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and agree that additional quantitative validation will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the four mechanisms (PAC, PWA, IVP, SCD) are 'together sufficient to stabilize the joint shape-color optimization and suppress artifacts without requiring manual intervention or post-processing for arbitrary target image pairs' is load-bearing for the central claim yet is supported only by selected examples; no ablation studies removing individual components, no quantitative success rates over a held-out set of arbitrary pairs, and no failure-case analysis are referenced.
Authors: We agree that the claim in the abstract regarding the sufficiency of the four mechanisms is central and would be strengthened by quantitative evidence beyond the selected examples. The manuscript currently relies on qualitative demonstrations across diverse cases in digital and physical domains. We will add ablation studies that isolate each mechanism, report success rates over a held-out set of arbitrary image pairs, and include failure-case analysis in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the claim of 'successful' generation of 'diverse smooth Mirror Illusion artworks' supplies no quantitative metrics (e.g., surface smoothness measures, perceptual similarity scores, print success rates), ablation tables, or baseline comparisons, so the reported 76 s / 2.6 GB figures cannot be assessed for improvement over prior art.
Authors: The manuscript reports average runtime and memory figures alongside qualitative results for smooth, printable outputs. We acknowledge that the absence of quantitative metrics, ablation tables, and baseline comparisons limits direct assessment against prior methods. In the revision we will incorporate surface smoothness measures, perceptual similarity scores, print success rates, ablation tables, and comparisons to prior topology- and shadow-driven approaches. revision: yes
Circularity Check
No circularity: new pipeline with introduced mechanisms, no derivations or self-citation chains reducing to inputs.
full rationale
The paper describes AutoMIA as a novel automated pipeline that jointly optimizes shape and color for mirror illusion art, introducing four specific mechanisms (PAC selection, PWA suppression, IVP, SCD optimization) to stabilize the process. No equations, derivations, or fitted parameters are referenced that would reduce the claimed outputs to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim rests on the sufficiency of these mechanisms for the task, presented as an independent engineering contribution rather than a re-expression of prior fitted quantities or self-referential definitions. This is the common case of a self-contained method proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Top-down and bottom- up mechanisms in biasing competition in the human brain
Diane M Beck and Sabine Kastner. Top-down and bottom- up mechanisms in biasing competition in the human brain. Vision research, 49(10):1154–1165, 2009. 11
2009
-
[2]
Diffusion illusions: Hiding images in plain sight
Ryan Burgert, Xiang Li, Abe Leite, Kanchana Ranasinghe, and Michael Ryoo. Diffusion illusions: Hiding images in plain sight. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024. 2
2024
-
[3]
Lookingglass: Generative anamor- phoses via laplacian pyramid warping
Pascal Chang, Sergio Sancho, Jingwei Tang, Markus Gross, and Vinicius Azevedo. Lookingglass: Generative anamor- phoses via laplacian pyramid warping. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24–33, 2025. 3, 6
2025
-
[4]
Camouflage images.ACM Trans
Hung-Kuo Chu, Wei-Hsin Hsu, Niloy J Mitra, Daniel Cohen-Or, Tien-Tsin Wong, and Tong-Yee Lee. Camouflage images.ACM Trans. Graph., 29(4):51–1, 2010. 2
2010
-
[5]
arXiv preprint arXiv:2412.09625 (2024)
Yue Feng, Vaibhav Sanjay, Spencer Lutz, Badour AlBa- har, Songwei Ge, and Jia-Bin Huang. Illusion3d: 3d mul- tiview illusion with 2d diffusion priors.arXiv preprint arXiv:2412.09625, 2024. 3, 6
-
[6]
Motion without movement.ACM Siggraph Com- puter Graphics, 25(4):27–30, 1991
William T Freeman, Edward H Adelson, and David J Heeger. Motion without movement.ACM Siggraph Com- puter Graphics, 25(4):27–30, 1991. 2
1991
-
[7]
Hand shadow art: A differentiable rendering perspective.arXiv preprint arXiv:2505.21252,
Aalok Gangopadhyay, Prajwal Singh, Ashish Tiwari, and Shanmuganathan Raman. Hand shadow art: A differentiable rendering perspective.arXiv preprint arXiv:2505.21252,
-
[8]
Visual ana- grams: Generating multi-view optical illusions with diffu- sion models
Daniel Geng, Inbum Park, and Andrew Owens. Visual ana- grams: Generating multi-view optical illusions with diffu- sion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24154– 24163, 2024. 2, 6
2024
-
[9]
Ganmouflage: 3d object nondetection with tex- ture fields
Rui Guo, Jasmine Collins, Oscar de Lima, and Andrew Owens. Ganmouflage: 3d object nondetection with tex- ture fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4702– 4712, 2023. 2
2023
-
[10]
Visual indeterminacy in gan art
Aaron Hertzmann. Visual indeterminacy in gan art. InACM SIGGRAPH 2020 Art Gallery, pages 424–428. 2020. 2
2020
-
[11]
Multi- view wire art.ACM Trans
Kai-Wen Hsiao, Jia-Bin Huang, and Hung-Kuo Chu. Multi- view wire art.ACM Trans. Graph., 37(6):242, 2018. 2
2018
-
[12]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980, 2014. 11
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[13]
Cambridge University Press, 1996
David C Knill and Whitman Richards.Perception as Bayesian inference. Cambridge University Press, 1996. 11
1996
-
[14]
Marching cubes: A high resolution 3d surface construction algorithm
William E Lorensen and Harvey E Cline. Marching cubes: A high resolution 3d surface construction algorithm. InSem- inal graphics: pioneering efforts that shaped the field, pages 347–353. 1998. 10
1998
-
[15]
Soft shadow art
Sehee Min, Jaedong Lee, Jungdam Won, and Jehee Lee. Soft shadow art. InProceedings of the symposium on Computa- tional Aesthetics, pages 1–9, 2017. 2
2017
-
[16]
Shadow art.ACM Trans
Niloy J Mitra and Mark Pauly. Shadow art.ACM Trans. Graph., 28(5):156, 2009. 2, 3, 6
2009
-
[17]
Hy- brid images.ACM Transactions on Graphics (TOG), 25(3): 527–532, 2006
Aude Oliva, Antonio Torralba, and Philippe G Schyns. Hy- brid images.ACM Transactions on Graphics (TOG), 25(3): 527–532, 2006. 2
2006
-
[18]
Camouflaging an object from many viewpoints
Andrew Owens, Connelly Barnes, Alex Flint, Hanumant Singh, and William Freeman. Camouflaging an object from many viewpoints. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2782– 2789, 2014. 2
2014
-
[19]
Wired perspectives: Multi-view wire art embraces generative ai
Zhiyu Qu, Lan Yang, Honggang Zhang, Tao Xiang, Kaiyue Pang, and Yi-Zhe Song. Wired perspectives: Multi-view wire art embraces generative ai. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6149–6158, 2024. 2
2024
-
[20]
Accelerating 3D Deep Learning with PyTorch3D
Nikhila Ravi, Jeremy Reizenstein, David Novotny, Tay- lor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia Gkioxari. Accelerating 3d deep learning with pytorch3d. arXiv preprint arXiv:2007.08501, 2020. 6, 11
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[21]
Shadow art revisited: a differentiable rendering based approach
Kaustubh Sadekar, Ashish Tiwari, and Shanmuganathan Ra- man. Shadow art revisited: a differentiable rendering based approach. InProceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision, pages 29–37,
-
[22]
Topology-disturbing objects: A new class of 3d optical illusion.Journal of Mathematics and the Arts, 12(1):2–18, 2018
Kokichi Sugihara. Topology-disturbing objects: A new class of 3d optical illusion.Journal of Mathematics and the Arts, 12(1):2–18, 2018. 2, 3, 6
2018
-
[23]
Curve and surface smoothing without shrinkage
Gabriel Taubin. Curve and surface smoothing without shrinkage. InProceedings of IEEE international conference on computer vision, pages 852–857. IEEE, 1995. 10
1995
-
[24]
Pr ¨agnanz in visual perception.Psychonomic Bulletin & Review, 31(2):541–567,
Eline Van Geert and Johan Wagemans. Pr ¨agnanz in visual perception.Psychonomic Bulletin & Review, 31(2):541–567,
-
[25]
Demo Video.mp4
Qing Zhang, Gelin Yin, Yongwei Nie, and Wei-Shi Zheng. Deep camouflage images. InProceedings of the AAAI con- ference on artificial intelligence, pages 12845–12852, 2020. 2 Supplementary Material for Mirror Illusion Art S1. Supplementary Video See “Demo Video.mp4” for a full-angle visualization of mirror illusion 3D objects. S2. From V oxel to Mesh Althou...
2020
-
[26]
Following the experimental settings in Section S6, the results are shown in Table S1. The findings indicate that lower resolutions (64×64×64) reduce optimization time and memory consumption, but at the expense of reconstruc- tion quality, while higher resolutions (256×256×256) offer only marginal improvements in quality with signifi- cantly increased comp...
-
[27]
The results are shown in Table S2
All other experimental settings followed Section S6. The results are shown in Table S2. Overall, increasing the sampling density improves the quality of the rendered 3D object, but also increases computation time and memory consumption. We also observed that excessively high sam- pling density can even reduce some reconstruction metrics, such as SL and SS...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.