Benchmarking Quantum Software Testing with Scalable Quantum Programs
Pith reviewed 2026-07-03 08:53 UTC · model grok-4.3
The pith
Qolumbina curates 40 refactored quantum programs from open repositories into a benchmark that supports controlled testing experiments with scalable subjects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that Qolumbina supplies a benchmark infrastructure of 40 test-ready quantum programs equipped with explicit specifications and the proposed QST-oriented criteria, and that this infrastructure covers diverse testing-relevant properties and enables empirical evaluation of quantum software testing methods on scalable rather than fixed-size subjects.
What carries the argument
Qolumbina, the benchmark infrastructure built from curated programs and the QST-oriented criteria that characterize functionality, output behavior, development complexity, and quantum-specific execution complexity.
If this is right
- Fair comparison of distinct QST approaches becomes possible because all subjects share the same specifications, test cases, and interfaces.
- Scalability studies can vary program size while holding other characteristics fixed under the defined criteria.
- Execution-cost measurements can be repeated across different quantum backends to isolate backend-dependent effects.
- Fault-detection effectiveness can be quantified on programs whose quantum-specific complexity is explicitly characterized.
Where Pith is reading between the lines
- The criteria could be reused to evaluate whether newly written quantum programs meet testing needs before they are added to the benchmark.
- Standardized interfaces in Qolumbina may reduce the engineering effort required to port new testing techniques to multiple subjects.
- The emphasis on refactoring open-source code highlights a practical route for turning scattered quantum programs into reproducible test subjects.
Load-bearing premise
The 40 programs selected and refactored from open-source repositories, together with the proposed QST-oriented criteria, are representative of current quantum software development practices without selection bias.
What would settle it
Re-running the coverage analysis and the two controlled QST experiments on an independently chosen set of 40 programs from different repositories and obtaining markedly different property distributions or fault-detection outcomes would falsify the claim that the benchmark is representative.
Figures

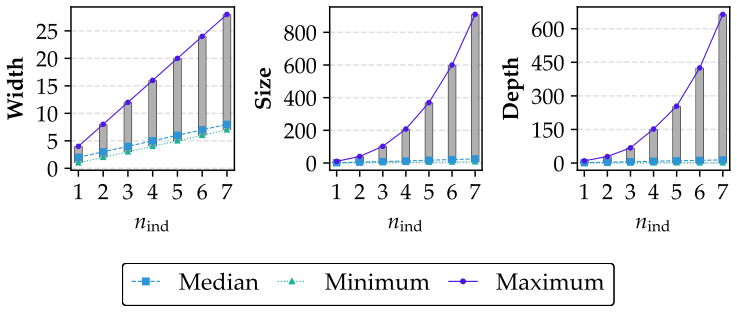
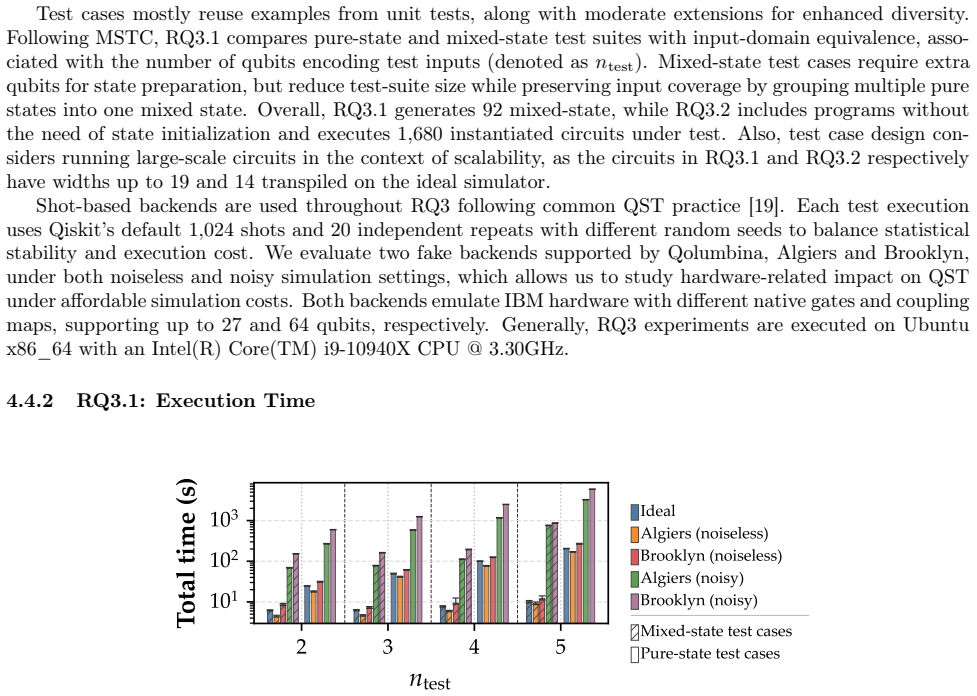
read the original abstract
Quantum software testing (QST) checks whether quantum programs behave according to their intended specifications. A key requirement for QST research is a benchmark that supports rigorous empirical evaluation on programs that are testable and better reflect current software development practices. However, existing studies heavily rely on small hard-coded or circuit-level benchmarks, while available quantum programs are scattered across repositories without clear selection criteria, which limits fair comparison and systematic reproducibility. To this end, we present Qolumbina, a benchmark infrastructure for controlled QST experiments on scalable quantum programs. Qolumbina curates 40 programs from open-source repositories, turns them into test-ready subjects through systematic selection, refactoring, specifications, test case examples, unit tests, and standardized interfaces. We also propose QST-oriented criteria to characterize quantum programs along functionality, output behavior, development complexity, and quantum-specific execution complexity. Using these criteria, our empirical study shows that Qolumbina covers diverse testing-relevant properties and supports scalability analysis beyond fixed-size circuit benchmarks. Through controlled experiments with two recent QST approaches, we demonstrate the feasibility of using Qolumbina for execution-cost and fault-detection studies, and highlight backend-dependent effects that can influence QST result interpretation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Qolumbina, a benchmark infrastructure curating 40 quantum programs from open-source repositories via systematic selection and refactoring into test-ready subjects with specifications, test cases, unit tests, and standardized interfaces. It proposes four QST-oriented criteria (functionality, output behavior, development complexity, quantum-specific execution complexity) and reports an empirical study showing that the benchmark covers diverse testing-relevant properties, supports scalability analysis, and enables controlled experiments with two recent QST approaches to examine execution costs and fault detection while noting backend-dependent effects.
Significance. If the selection process proves representative and the experiments include proper controls for variability, the work fills a gap in QST research by supplying scalable, testable programs drawn from real repositories rather than small hard-coded circuits, along with criteria and reproducible interfaces that could improve comparability across testing methods.
major comments (2)
- [Abstract] Abstract: the claim that the 40 programs 'cover diverse testing-relevant properties' and support generalizable findings on execution-cost and fault-detection studies rests on unvalidated selection/refactoring steps and the four proposed criteria; no external anchor (qubit/gate distribution statistics, repository coverage metrics, or inter-rater validation of criteria) is described to rule out curation bias.
- [Empirical study] Empirical study description: no error bars, confidence intervals, or quantification of backend-dependent effects are mentioned, which directly affects the interpretability of the controlled experiments with the two QST approaches and the feasibility demonstration.
minor comments (1)
- Provide a table or appendix listing the 40 programs with their original repositories, qubit counts, and gate counts to support reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and rigor where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the 40 programs 'cover diverse testing-relevant properties' and support generalizable findings on execution-cost and fault-detection studies rests on unvalidated selection/refactoring steps and the four proposed criteria; no external anchor (qubit/gate distribution statistics, repository coverage metrics, or inter-rater validation of criteria) is described to rule out curation bias.
Authors: The four criteria are proposed in the paper as QST-oriented measures, and the empirical study reports the distribution of the 40 programs across them to illustrate diversity in testing-relevant properties. No external anchors such as inter-rater validation or repository-wide statistics were applied. We will revise the abstract to state that diversity is shown with respect to the proposed criteria and add a limitations discussion on the curation process and potential biases. revision: yes
-
Referee: [Empirical study] Empirical study description: no error bars, confidence intervals, or quantification of backend-dependent effects are mentioned, which directly affects the interpretability of the controlled experiments with the two QST approaches and the feasibility demonstration.
Authors: This observation is correct. The experiments demonstrated feasibility and noted backend effects qualitatively but did not include statistical quantification. We will revise the empirical study section to add error bars, confidence intervals, and more detailed quantification of backend-dependent effects. revision: yes
Circularity Check
No circularity: empirical curation from external repositories with independent evaluation criteria
full rationale
The paper constructs Qolumbina by selecting and refactoring 40 programs from open-source repositories using explicitly stated criteria (functionality, output behavior, development complexity, quantum-specific execution complexity). These criteria are proposed in the paper but applied to external artifacts; the reported diversity, scalability support, and controlled experiments on two QST approaches are direct measurements on the curated set rather than quantities fitted or redefined from the same inputs. No equations, fitted parameters, or self-citation chains reduce any claim to a prior definition or internal fit. The selection process itself is described as systematic but is not presented as a derivation that loops back on its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Open-source quantum programs can be systematically selected, refactored, and augmented with specifications and unit tests while preserving their original functionality and complexity properties.
Reference graph
Works this paper leans on
-
[1]
Metamorphic testing of oracle quantum programs
Rui Abreu, João Paulo Fernandes, Luis Llana, and Guilherme Tavares. Metamorphic testing of oracle quantum programs. InProceedings of the 3rd International Workshop on Quantum Software Engineering, pages 16–23, 2022
2022
-
[2]
Assessing the effectiveness of input and output coverage criteria for testing quantum programs
Shaukat Ali, Paolo Arcaini, Xinyi Wang, and Tao Yue. Assessing the effectiveness of input and output coverage criteria for testing quantum programs. In2021 14th IEEE Conference on Software Testing, Verification and Validation (ICST), pages 13–23. IEEE, 2021
2021
-
[3]
Webpage of qolumbina,
Anonymous Authors. Webpage of qolumbina, . URLhttps://qolumbinadoc.netlify.app/
-
[4]
Anonymous Authors. Documentation of qolumbina, . URLhttps://doi.org/10.5281/zenodo.20987484
-
[5]
Empirical study for qolumbina,
Anonymous Authors. Empirical study for qolumbina, . URLhttps://doi.org/10.5281/zenodo.20987 444
-
[6]
Anonymous Authors. Infrastructure of qolumbina, . URLhttps://doi.org/10.5281/zenodo.20987326
-
[7]
Qsim- bench: An execution-level benchmark suite for quantum software engineering
Giuseppe Bisicchia, Alessandro Bocci, José García-Alonso, Juan M Murillo, and Antonio Brogi. Qsim- bench: An execution-level benchmark suite for quantum software engineering. In2025 IEEE International Conference on Quantum Computing and Engineering (QCE), volume 2, pages 175–180. IEEE, 2025
2025
-
[8]
Veriqbench: A benchmark for multiple types of quantum circuits.arXiv preprint arXiv:2206.10880, 2022
Kean Chen, Wang Fang, Ji Guan, Xin Hong, Mingyu Huang, Junyi Liu, Qisheng Wang, and Mingsheng Ying. Veriqbench: A benchmark for multiple types of quantum circuits.arXiv preprint arXiv:2206.10880, 2022
-
[9]
Quantum computing for finance: State-of-the-art and future prospects.IEEE Transactions on Quantum Engineering, 1:1–24, 2020
Daniel J Egger, Claudio Gambella, Jakub Marecek, Scott McFaddin, Martin Mevissen, Rudy Raymond, Andrea Simonetto, Stefan Woerner, and Elena Yndurain. Quantum computing for finance: State-of-the-art and future prospects.IEEE Transactions on Quantum Engineering, 1:1–24, 2020
2020
-
[10]
Measuring nominal scale agreement among many raters.Psychological bulletin, 76(5):378, 1971
Joseph L Fleiss. Measuring nominal scale agreement among many raters.Psychological bulletin, 76(5):378, 1971
1971
-
[11]
A characterization study of bugs in LLM agent workflow orchestration frameworks,
Xiaoyu Guo, Minggu Wang, and Jianjun Zhao. Quanbench: Benchmarking quantum code generation with large language models. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 2657–2669. IEEE Press, 2025. doi: 10.1109/ASE63991.2025.00218. URL https://doi.org/10.1109/ASE63991.2025.00218
-
[12]
An empirical study on self-admitted technical debt in quantum software
Yuta Ishimoto, Yuto Nakamura, Ryota Katsube, Naoto Sato, Hideto Ogawa, Masanari Kondo, Yasutaka Kamei, and Naoyasu Ubayashi. An empirical study on self-admitted technical debt in quantum software. In2024 31st Asia-Pacific Software Engineering Conference (APSEC), pages 41–50. IEEE, 2024. 17
2024
-
[13]
Defects4j: A database of existing faults to enable controlled testing studies for java programs
René Just, Darioush Jalali, and Michael D Ernst. Defects4j: A database of existing faults to enable controlled testing studies for java programs. InProceedings of the 2014 international symposium on software testing and analysis, pages 437–440, 2014
2014
-
[14]
The measurement of observer agreement for categorical data.biomet- rics, pages 159–174, 1977
J Richard Landis and Gary G Koch. The measurement of observer agreement for categorical data.biomet- rics, pages 159–174, 1977
1977
-
[15]
Qasmbench: A low-level quantum bench- mark suite for nisq evaluation and simulation.ACM Transactions on Quantum Computing, 4(2):1–26, 2023
Ang Li, Samuel Stein, Sriram Krishnamoorthy, and James Ang. Qasmbench: A low-level quantum bench- mark suite for nisq evaluation and simulation.ACM Transactions on Quantum Computing, 4(2):1–26, 2023
2023
-
[16]
Automatic repair of quantum programs via unitary operation.ACM Transactions on Software Engineering and Methodology, 33(6):1–43, 2024
Yuechen Li, Hanyu Pei, Linzhi Huang, Beibei Yin, and Kai-Yuan Cai. Automatic repair of quantum programs via unitary operation.ACM Transactions on Software Engineering and Methodology, 33(6):1–43, 2024
2024
-
[17]
Preparation and utilization of mixed states for testing quantum programs.ACM Transactions on Software Engineering and Methodology, 34(8):1–44, 2025
Yuechen Li, Kai-Yuan Cai, and Beibei Yin. Preparation and utilization of mixed states for testing quantum programs.ACM Transactions on Software Engineering and Methodology, 34(8):1–44, 2025
2025
-
[18]
Yuechen Li, Kai-Yuan Cai, and Beibei Yin. A dynamic test oracle for quantum programs with separable output states.IEEE Transactions on Software Engineering, pages 1–26, 2026. doi: 10.1109/TSE.2026.367 0211
-
[19]
Yuechen Li, Minqi Shao, Jianjun Zhao, and Qichen Wang. A methodological analysis of empirical studies in quantum software testing.ACM Transactions on Software Engineering and Methodology, June 2026. ISSN 1049-331X. doi: 10.1145/3819590. URLhttps://doi.org/10.1145/3819590. Just Accepted
-
[20]
Testing multi-subroutine quantum programs: From unit testing to inte- gration testing.ACM Transactions on Software Engineering and Methodology, 33(6):1–61, 2024
Peixun Long and Jianjun Zhao. Testing multi-subroutine quantum programs: From unit testing to inte- gration testing.ACM Transactions on Software Engineering and Methodology, 33(6):1–61, 2024
2024
-
[21]
A black-box testing framework for oracle quantum programs.arXiv preprint arXiv:2505.07243, 2025
Peixun Long and Jianjun Zhao. A black-box testing framework for oracle quantum programs.arXiv preprint arXiv:2505.07243, 2025
-
[22]
Application-oriented performance benchmarks for quantum computing.IEEE Transactions on Quantum Engineering, 4:1–32, 2023
Thomas Lubinski, Sonika Johri, Paul Varosy, Jeremiah Coleman, Luning Zhao, Jason Necaise, Charles H Baldwin, Karl Mayer, and Timothy Proctor. Application-oriented performance benchmarks for quantum computing.IEEE Transactions on Quantum Engineering, 4:1–32, 2023
2023
-
[23]
Quantum circuit mutants: Em- pirical analysis and recommendations.Empirical Software Engineering, 30(4):100, 2025
Eñaut Mendiluze Usandizaga, Shaukat Ali, Tao Yue, and Paolo Arcaini. Quantum circuit mutants: Em- pirical analysis and recommendations.Empirical Software Engineering, 30(4):100, 2025
2025
-
[24]
Andriy Miranskyy, Lei Zhang, and Javad Doliskani. Is your quantum program bug-free? InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering: New Ideas and Emerging Results, ICSE-NIER ’20, pages 29–32, New York, NY, USA, 2020. Association for Computing Machinery. ISBN 9781450371261. doi: 10.1145/3377816.3381731. URLhttps://doi.o...
-
[25]
On the feasibility of quantum unit testing.arXiv preprint arXiv:2507.17235, 2025
Andriy Miranskyy, José Campos, Anila Mjeda, Lei Zhang, and Ignacio García Rodríguez de Guzmán. On the feasibility of quantum unit testing.arXiv preprint arXiv:2507.17235, 2025
-
[26]
Quantum software engineering: Roadmap and challenges ahead.ACM Transactions on Software Engineering and Methodology, 34(5):1–48, 2025
Juan Manuel Murillo, Jose Garcia-Alonso, Enrique Moguel, Johanna Barzen, Frank Leymann, Shaukat Ali, Tao Yue, Paolo Arcaini, Ricardo Pérez-Castillo, Ignacio García-Rodríguez de Guzmán, et al. Quantum software engineering: Roadmap and challenges ahead.ACM Transactions on Software Engineering and Methodology, 34(5):1–48, 2025
2025
-
[27]
Faster and better quantum software testing through specification reduction and projective measurements.ACM Transactions on Software Engineering and Methodology, 34(7):1–39, 2025
Noah H Oldfield, Christoph Laaber, Tao Yue, and Shaukat Ali. Faster and better quantum software testing through specification reduction and projective measurements.ACM Transactions on Software Engineering and Methodology, 34(7):1–39, 2025
2025
-
[28]
Technical debts and faults in open-source quantum software systems: An empirical study.Journal of Systems and Software, 193:111458, 2022
Moses Openja, Mohammad Mehdi Morovati, Le An, Foutse Khomh, and Mouna Abidi. Technical debts and faults in open-source quantum software systems: An empirical study.Journal of Systems and Software, 193:111458, 2022
2022
-
[29]
A survey on testing and analysis of quantum software.arXiv preprint arXiv:2410.00650, 2024
Matteo Paltenghi and Michael Pradel. A survey on testing and analysis of quantum software.arXiv preprint arXiv:2410.00650, 2024
-
[30]
Qiskit 2.3.0,
Qiskit Development Team. Qiskit 2.3.0, . URLhttps://github.com/Qiskit/qiskit
-
[31]
Qiskit: qiskit-textbook,
Qiskit Development Team. Qiskit: qiskit-textbook, . URLhttps://github.com/qiskit-community/qis kit-textbook. 18
-
[32]
Qiskit: textbook,
Qiskit Development Team. Qiskit: textbook, . URLhttps://github.com/Qiskit/textbook?tab=Apach e-2.0-1-ov-file
-
[33]
Qiskit qft.https://github.com/Qiskit/qiskit/blob/main/qiskit/circui t/library/basis_change/qft.py, 2026
Qiskit Development Team. Qiskit qft.https://github.com/Qiskit/qiskit/blob/main/qiskit/circui t/library/basis_change/qft.py, 2026. Apache-2.0 license, introduced in commit 3fe73d9
2026
-
[34]
Mqt bench: Benchmarking software and design automation tools for quantum computing.Quantum, 7:1062, 2023
Nils Quetschlich, Lukas Burgholzer, and Robert Wille. Mqt bench: Benchmarking software and design automation tools for quantum computing.Quantum, 7:1062, 2023
2023
-
[35]
Testability refactoring in pull requests: Patterns and trends
Pavel Reich and Walid Maalei. Testability refactoring in pull requests: Patterns and trends. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 1508–1519. IEEE, 2023
2023
-
[36]
Mock objects for testing java systems: Why and how developers use them, and how they evolve.Empirical Software Engineering, 24(3): 1461–1498, 2019
Davide Spadini, Maurício Aniche, Magiel Bruntink, and Alberto Bacchelli. Mock objects for testing java systems: Why and how developers use them, and how they evolve.Empirical Software Engineering, 24(3): 1461–1498, 2019
2019
-
[37]
Sphinx documentation generator
Sphinx Team. Sphinx documentation generator. https://www.sphinx-doc.org/en/master/, 2026. Accessed: 2026-03-22
2026
-
[38]
Supermarq: A scalable quantum benchmark suite
Teague Tomesh, Pranav Gokhale, Victory Omole, Gokul Subramanian Ravi, Kaitlin N Smith, Joshua Vis- zlai, Xin-Chuan Wu, Nikos Hardavellas, Margaret R Martonosi, and Frederic T Chong. Supermarq: A scalable quantum benchmark suite. In2022 IEEE International Symposium on High-Performance Com- puter Architecture (HPCA), pages 587–603. IEEE, 2022
2022
-
[39]
A critique and improvement of the cl common language effect size statistics of mcgraw and wong.Journal of Educational and Behavioral Statistics, 25(2):101–132, 2000
András Vargha and Harold D Delaney. A critique and improvement of the cl common language effect size statistics of mcgraw and wong.Journal of Educational and Behavioral Statistics, 25(2):101–132, 2000
2000
-
[40]
Revlib: An online resource for reversible functions and reversible circuits
Robert Wille, Daniel Große, Lisa Teuber, Gerhard W Dueck, and Rolf Drechsler. Revlib: An online resource for reversible functions and reversible circuits. In38th international symposium on multiple valued logic (ismvl 2008), pages 220–225. IEEE, 2008
2008
-
[41]
Quantum risk analysis.npj Quantum Information, 5(1):15, 2019
Stefan Woerner and Daniel J Egger. Quantum risk analysis.npj Quantum Information, 5(1):15, 2019
2019
-
[42]
Qcircuitbench: A large-scale dataset for benchmarking quantum algorithm design.Advances in Neural Information Processing Systems, 38, 2026
Rui Yang, Ziruo Wang, Yuntian Gu, Yitao Liang, and Tongyang Li. Qcircuitbench: A large-scale dataset for benchmarking quantum algorithm design.Advances in Neural Information Processing Systems, 38, 2026
2026
-
[43]
Quantum software engineering: Landscapes and horizons.arXiv preprint arXiv:2007.07047, 2020
Jianjun Zhao. Quantum software engineering: Landscapes and horizons.arXiv preprint arXiv:2007.07047, 2020
-
[44]
Somesizeandstructuremetricsforquantumsoftware
JianjunZhao. Somesizeandstructuremetricsforquantumsoftware. In2021 IEEE/ACM 2nd International Workshop on Quantum Software Engineering (Q-SE), pages 22–27. IEEE, 2021
2021
-
[45]
When abstraction breaks physics: Rethinking modular design in quantum software
Jianjun Zhao. When abstraction breaks physics: Rethinking modular design in quantum software. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 3886–3890,
-
[46]
doi: 10.1109/ASE63991.2025.00336
-
[47]
Bugs4q: A benchmark of real bugs for quantumprograms
Pengzhan Zhao, Jianjun Zhao, Zhongtao Miao, and Shuhan Lan. Bugs4q: A benchmark of real bugs for quantumprograms. In2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 1373–1376. IEEE, 2021
2021
-
[48]
Bugs4q: A benchmark of existing bugs to enable controlled testing and debugging studies for quantum programs.Journal of Systems and Software, 205:111805, 2023
Pengzhan Zhao, Zhongtao Miao, Shuhan Lan, and Jianjun Zhao. Bugs4q: A benchmark of existing bugs to enable controlled testing and debugging studies for quantum programs.Journal of Systems and Software, 205:111805, 2023. 19
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.