Lower Bounds for Anytime Acceleration of Gradient Descent
Pith reviewed 2026-07-03 08:23 UTC · model grok-4.3
The pith
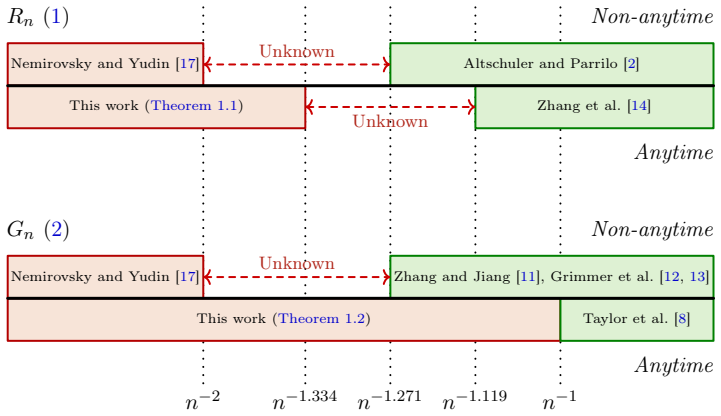
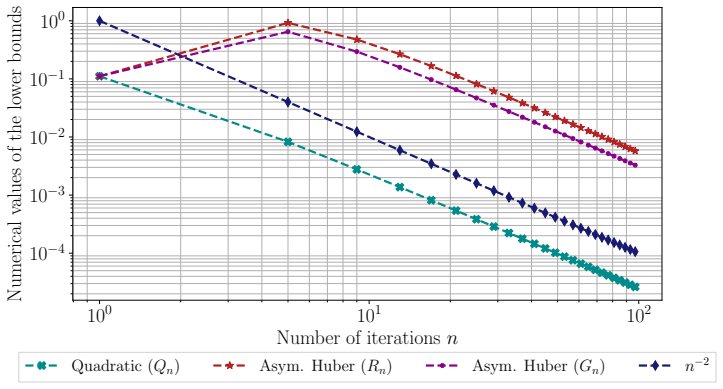
No positive stepsize schedule for gradient descent can achieve better than an o(n^{-1.334}) anytime rate on function values or o(n^{-1}) on squared gradient norms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
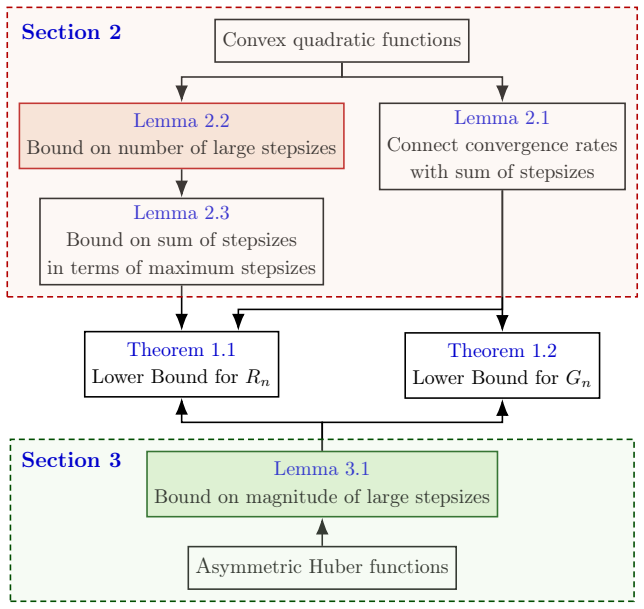
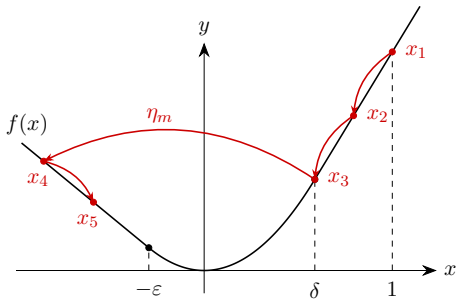
We show that no positive stepsize schedule can achieve an o(n^{-1.334}) anytime rate for function value minimization, nor an o(n^{-1}) anytime rate for squared gradient norm minimization. The key ingredients are novel upper bounds on the number and the magnitude of large stepsizes derived by analyzing gradient descent on quadratic functions and variants of Huber functions.
What carries the argument
Upper bounds on the number and magnitude of large stepsizes obtained by running gradient descent on quadratics and Huber variants; these limits prevent frequent or aggressive overshooting in the anytime regime.
If this is right
- Any anytime gradient-descent schedule must incur function-value error at least on the order of n^{-1.334} for infinitely many n.
- Squared-gradient-norm error cannot fall below order n^{-1} in the anytime setting.
- The known fixed-horizon rate of O(n^{-1.271}) does not carry over when the horizon is unknown.
- The COLT 2024 open question on optimal anytime rates for gradient descent now has explicit lower-bound anchors.
Where Pith is reading between the lines
- Closing the remaining gap to the classical n^{-2} lower bound would require either a different algorithm or a proof technique that escapes the quadratic-Huber restriction.
- The same step-size restrictions may apply to other first-order methods that rely on occasional large steps when the total iteration count is unknown.
- Numerical checks on a broader family of convex functions could test whether the quadratic-Huber analysis already saturates the worst case.
Load-bearing premise
The worst-case behavior over all smooth convex functions is captured by the quadratic and Huber functions used to bound the allowable large steps.
What would settle it
Exhibit a single positive stepsize sequence that produces o(n^{-1.334}) function-value convergence (or o(n^{-1}) gradient-norm convergence) on every smooth convex function when the iteration count is revealed only at the end.
Figures
read the original abstract
Recent work suggests that the convergence rate of gradient descent (GD) in smooth convex optimization can be significantly improved by employing large stepsizes that may violate the descent property. In particular, if the total number of iterations $n$ is given, an $O(n^{-1.271})$ convergence rate can be achieved for both function value and squared gradient norm minimization. On the other hand, in the setting of anytime convergence, where $n$ is not known in advance, the best known rates of GD are much slower: $O(n^{-1.119})$ for function value minimization and $O(n^{-1})$ for squared gradient norm minimization. It remains open whether any of these upper bounds can be improved, as they are far from the classical $\Omega(n^{-2})$ lower bound for any first-order method. In this work, we establish two lower bounds on the anytime convergence of GD. We show that no positive stepsize schedule can achieve an $o(n^{-1.334})$ anytime rate for function value minimization, nor an $o(n^{-1})$ anytime rate for squared gradient norm minimization. The key ingredients of our analysis are novel upper bounds on the number and the magnitude of large stepsizes, derived by analyzing GD on quadratic functions and variants of Huber functions. Our work provides the first lower bounds for the COLT 2024 open problem posed by Kornowski and Shamir regarding the optimal anytime convergence rates of GD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to establish lower bounds for the anytime convergence rates of gradient descent (GD) with arbitrary positive stepsize schedules in smooth convex optimization. It shows that no such schedule can achieve an o(n^{-1.334}) rate for function value minimization or an o(n^{-1}) rate for squared gradient norm minimization. The key technical ingredients are novel upper bounds on the number and magnitude of large stepsizes, derived by analyzing GD on quadratic functions and variants of Huber functions. This addresses the COLT 2024 open problem of Kornowski and Shamir on optimal anytime rates.
Significance. If the central derivation holds, the result is significant: it supplies the first lower bounds separating the fixed-horizon O(n^{-1.271}) upper bound from the anytime setting and quantifies how much acceleration is lost without knowledge of the horizon. The technique of extracting stepsize restrictions from specific function classes (quadratics and Huber variants) is a novel contribution that could be useful beyond this paper.
major comments (2)
- [Section deriving the novel upper bounds on large stepsizes (referenced in the abstract)] The lower bounds rest on the claim that the upper bounds on the number and magnitude of large stepsizes obtained from quadratic and Huber-variant analyses apply to any positive stepsize schedule when minimizing over the full class of L-smooth convex functions. The manuscript must explicitly show why no schedule can evade these restrictions on the constructions while still achieving the claimed rates on general smooth convex functions; otherwise the transfer step fails. This is load-bearing for both main theorems.
- [Proof of the main lower bounds] The o(n^{-1.334}) and o(n^{-1}) exponents appear to be direct consequences of the quantitative upper bounds on large stepsizes. If those quantitative bounds can be tightened or relaxed by considering a broader set of test functions, the final exponents would change. The paper should include a short discussion of whether the quadratic/Huber pair is worst-case for the stepsize restriction or merely sufficient for the stated exponents.
minor comments (2)
- The abstract refers to 'variants of Huber functions' without a one-sentence definition; adding this in the introduction would help readers follow the construction.
- Notation for the stepsize sequence and the notion of 'large' steps should be introduced once and used uniformly; minor inconsistencies appear in the early sections.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report, which highlights the load-bearing aspects of our transfer argument and the choice of test functions. We believe both points can be addressed through clarifications and a short added discussion, and we respond to each major comment below.
read point-by-point responses
-
Referee: [Section deriving the novel upper bounds on large stepsizes (referenced in the abstract)] The lower bounds rest on the claim that the upper bounds on the number and magnitude of large stepsizes obtained from quadratic and Huber-variant analyses apply to any positive stepsize schedule when minimizing over the full class of L-smooth convex functions. The manuscript must explicitly show why no schedule can evade these restrictions on the constructions while still achieving the claimed rates on general smooth convex functions; otherwise the transfer step fails. This is load-bearing for both main theorems.
Authors: Any positive stepsize schedule is fixed in advance and must deliver the claimed rates uniformly over the entire class of L-smooth convex functions. In particular, it must succeed on the quadratic and Huber-variant instances we analyze. Our upper bounds on the number and magnitude of large stepsizes are obtained precisely by showing that violation of those bounds produces suboptimal convergence on those specific instances. Consequently, no schedule can evade the restrictions while still attaining the target rates on the full class; the transfer follows directly from the non-adaptive nature of the schedule. We will revise the manuscript to articulate this reasoning more explicitly in the section deriving the stepsize bounds. revision: yes
-
Referee: [Proof of the main lower bounds] The o(n^{-1.334}) and o(n^{-1}) exponents appear to be direct consequences of the quantitative upper bounds on large stepsizes. If those quantitative bounds can be tightened or relaxed by considering a broader set of test functions, the final exponents would change. The paper should include a short discussion of whether the quadratic/Huber pair is worst-case for the stepsize restriction or merely sufficient for the stated exponents.
Authors: The quadratic and Huber-variant functions yield quantitative restrictions on large stepsizes that are sufficient to establish the stated exponents. We do not claim these functions produce the strongest possible restrictions; a broader collection of test functions might tighten (or relax) the bounds and alter the final exponents. We will add a concise discussion noting that the quadratic/Huber pair is sufficient for the results presented and that determining whether it is worst-case remains open. revision: yes
Circularity Check
No significant circularity; lower bounds derived from independent function-class analysis
full rationale
The paper derives novel upper bounds on large stepsizes by direct analysis of GD on quadratics and Huber variants, then applies those bounds to obtain anytime lower bounds. This construction does not reduce to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The cited open problem is external (Kornowski-Shamir). No equations or steps in the provided text exhibit the target rates being presupposed in the stepsize bounds. Standard lower-bound technique via worst-case functions; self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of smooth convex optimization (Lipschitz gradient, convexity)
Reference graph
Works this paper leans on
-
[1]
Springer, 2018
Yurii Nesterov.Lectures on Convex Optimization. Springer, 2018. 2, 3, 4 22
2018
-
[2]
Altschuler and Pablo A
Jason M. Altschuler and Pablo A. Parrilo. Acceleration by stepsize hedging: Silver stepsize schedule for smooth convex optimization.Math. Program., 2024. 2, 3, 4, 13, 26
2024
-
[3]
Stepsize Hedging: an Alternative Mechanism for Accelerating Gradient Descent
Jason M. Altschuler and Pablo A. Parrilo. Stepsize hedging: An al- ternative mechanism for accelerating gradient descent.arXiv preprint arXiv:2605.31386, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Acceleratedgradient descent via long steps.arXiv preprint arXiv:2309.09961, 2023
BenjaminGrimmer, KevinShu, andAlexL.Wang. Acceleratedgradient descent via long steps.arXiv preprint arXiv:2309.09961, 2023. 2, 3
-
[5]
Bartlett, Matus Telgarsky, and Bin Yu
Jingfeng Wu, Peter L. Bartlett, Matus Telgarsky, and Bin Yu. Large stepsize gradient descent for logistic loss: Non-monotonicity of the loss improves optimization efficiency. InProc. 37th Annu. Conf. Learn. The- ory, 2024. 2
2024
-
[6]
Donghwan Kim and Jeffrey A. Fessler. Optimizing the efficiency of first- order methods for decreasing the gradient of smooth convex functions. J. Optim. Theory Appl., 2021. 2, 26
2021
-
[7]
How to make the gradients small.Optima., 2012
Yurii Nesterov. How to make the gradients small.Optima., 2012. 2
2012
-
[8]
Taylor, Julien M
Adrien B. Taylor, Julien M. Hendrickx, and François Glineur. Exact worst-case convergence rates of the proximal gradient method for com- posite convex minimization.J. Optim. Theory Appl., 2018. 2, 3, 4, 6, 26
2018
-
[9]
Gradient descent’s last iterate is often (slightly) suboptimal
Guy Kornowski and Ohad Shamir. Gradient descent’s last iterate is often (slightly) suboptimal. InOPT 2025: Optimization for Machine Learning, 2025. 3
2025
-
[10]
E. S. Levitin and B. T. Polyak. Constrained minimization methods. USSR Comput. Math. Math. Phys., 1966. 3
1966
-
[11]
Zehao Zhang and Rujun Jiang. Accelerated gradient descent by con- catenation of stepsize schedules.arXiv preprint arXiv:2410.12395, 2024. 3, 4, 6, 26
-
[12]
Benjamin Grimmer, Kevin Shu, and Alex L. Wang. Accelerated objec- tive gap and gradient norm convergence for gradient descent via long steps.INFORMS J. Optim., 2025. 3, 4, 26
2025
-
[13]
Benjamin Grimmer, Kevin Shu, and Alex L. Wang. Composing opti- mized stepsize schedules for gradient descent.Math. Oper. Res., 2025. 3, 4, 6, 9, 26 23
2025
-
[14]
Lee, Simon S
Zihan Zhang, Jason D. Lee, Simon S. Du, and Yuxin Chen. Anytime ac- celeration of gradient descent. InProc. 38th Annu. Conf. Learn. Theory,
-
[15]
Openproblem: Anytimeconvergence rate of gradient descent
GuyKornowskiandOhadShamir. Openproblem: Anytimeconvergence rate of gradient descent. InProc. 37th Annu. Conf. Learn. Theory, 2024. 3, 4, 5, 6, 9
2024
-
[16]
Shuvomoy Das Gupta, Bart P. G. Van Parys, and Ernest K. Ryu. Branch-and-bound performance estimation programming: a unified methodology for constructing optimal optimization methods.Math. Program., 2024. 3, 5
2024
-
[17]
A. S. Nemirovsky and D. B. Yudin.Problem Complexity and Method Efficiency in Optimization. John Wiley & Sons, 1983. 4, 26
1983
-
[18]
A method for solving the convex programming problem with convergence rateo(1/k2)
Yurii Nesterov. A method for solving the convex programming problem with convergence rateo(1/k2). InDokl akad nauk Sssr, 1983. 5, 26
1983
-
[19]
Potential function-based frame- work for minimizing gradients in convex and min-max optimization
Jelena Diakonikolas and Puqian Wang. Potential function-based frame- work for minimizing gradients in convex and min-max optimization. SIAM J. Optim., 2022. 5
2022
-
[20]
Exact worst- case convergence rates of gradient descent: A complete analysis for all constant stepsizes over nonconvex and convex functions.Math
Teodor Rotaru, François Glineur, and Panagiotis Patrinos. Exact worst- case convergence rates of gradient descent: A complete analysis for all constant stepsizes over nonconvex and convex functions.Math. Pro- gram., 2026. 6
2026
-
[21]
Alexandre d’Aspremont, Damien Scieur, and Adrien B. Taylor. Accel- eration methods.Found. Trends Optim., 2021. 6, 27
2021
-
[22]
A. S. Nemirovsky. Information-based complexity of linear operator equations.J. Complex., 1992. 6, 19
1992
-
[23]
On Richardson’s method for solving linear systems with positive definite matrices.J
David Young. On Richardson’s method for solving linear systems with positive definite matrices.J. Math. Phys., 1953. 6
1953
-
[24]
Performance of first-order methods for smooth convex minimization: a novel approach.Math
Yoel Drori and Marc Teboulle. Performance of first-order methods for smooth convex minimization: a novel approach.Math. Program., 2014. 9
2014
-
[25]
Taylor, Julien M
Adrien B. Taylor, Julien M. Hendrickx, and François Glineur. Smooth strongly convex interpolation and exact worst-case performance of first- order methods.Math. Program., 2017. 9 24
2017
-
[26]
Adaptive subgradient methods for online learning and stochastic optimization.J
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization.J. Mach. Learn. Res., 2011. 21
2011
-
[27]
On averaging and extrapolation for gradient descent.Math
Alan Luner and Benjamin Grimmer. On averaging and extrapolation for gradient descent.Math. Oper. Res., 2025. 21
2025
-
[28]
Negative Stepsizes Make Gradient-Descent-Ascent Converge
Henry Shugart and Jason M. Altschuler. Negative stepsizes make gradient-descent-ascent converge.arXiv preprint arXiv:2505.01423,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Ozdaglar, Chanwoo Park, and Ernest K
Jaeyeon Kim, Asuman E. Ozdaglar, Chanwoo Park, and Ernest K. Ryu. Time-reversed dissipation induces duality between minimizing gradient norm and function value. InAdv. Neural Inf. Process. Syst., 2023. 26
2023
-
[30]
Springer New York, NY, 1995
Peter Borwein and Tamás Erdélyi.Polynomials and Polynomial In- equalities. Springer New York, NY, 1995. 27
1995
-
[31]
Lieb and Michael Loss.Analysis
Elliott H. Lieb and Michael Loss.Analysis. American Mathematical Soc., 2001. 28 25 A Best Known Convergence Rates of GD and First- Order Methods Table 1: Summary of the best known convergence rates of GD with an arbitrary positive stepsize schedule in smooth convex optimization. Only for the anytime convergence rate ofGn do the upper and lower bounds coin...
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.