Stepsize Hedging: an Alternative Mechanism for Accelerating Gradient Descent
Pith reviewed 2026-06-28 21:41 UTC · model grok-4.3
The pith
Gradient descent accelerates when stepsizes are selected via hedging.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Stepsize hedging provides an alternative mechanism that accelerates gradient descent by choosing stepsizes according to a hedging strategy rather than fixed or standard adaptive rules.
What carries the argument
Stepsize hedging: a dynamic rule for selecting stepsizes that produces acceleration in gradient descent.
If this is right
- Gradient descent reaches a given accuracy in fewer iterations when stepsizes follow the hedging rule.
- Acceleration can arise from stepsize policy alone without changing the underlying update direction.
- Standard analyses that treat stepsize choice as secondary may miss this source of speedup.
Where Pith is reading between the lines
- If hedging works, algorithm design could shift emphasis toward stepsize policies instead of direction modifications.
- The approach might unify with adaptive methods used in machine learning by treating hedging as a meta-rule.
Load-bearing premise
That hedging produces genuine acceleration not already achieved by existing stepsize selection methods.
What would settle it
A direct numerical comparison on a convex quadratic where the best fixed stepsize matches or beats the hedged sequence in convergence rate.
Figures
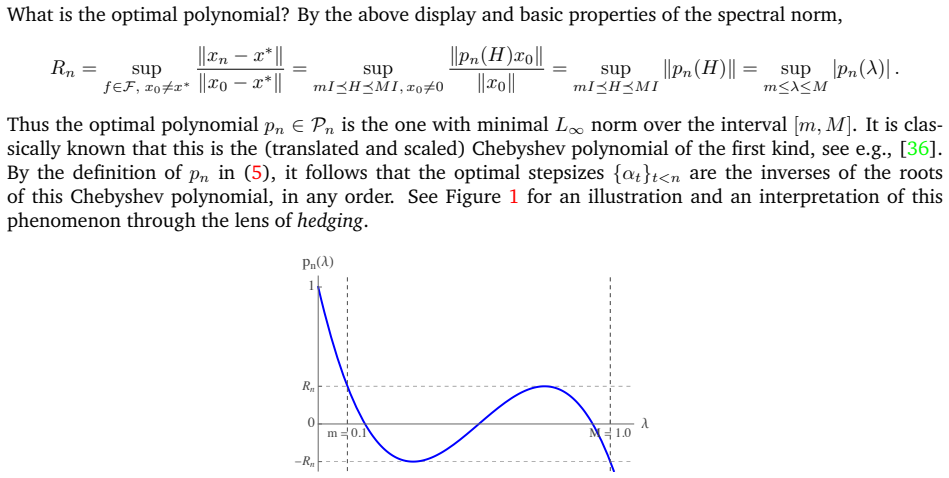
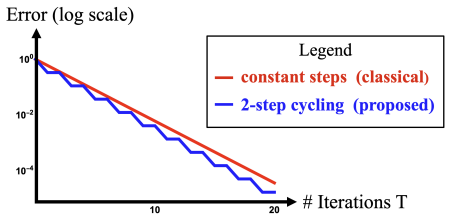
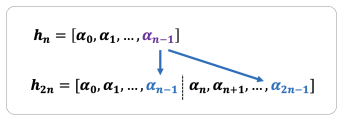
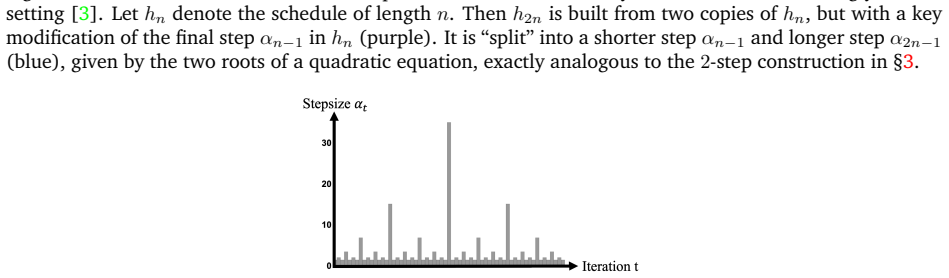
read the original abstract
Can gradient descent be accelerated by just choosing better stepsizes? Surprisingly, the answer is yes. This short expository article provides an accessible introduction to this phenomenon of stepsize hedging.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a short expository article claiming that gradient descent can be accelerated solely through appropriate stepsize choices via the phenomenon of 'stepsize hedging,' and it aims to provide an accessible introduction to this idea without presenting new derivations, theorems, or experiments.
Significance. If the exposition accurately reflects existing literature on stepsize selection, the paper could offer a useful pedagogical entry point for viewing stepsize choice as an acceleration mechanism. Its significance is limited to clarity of presentation rather than novel technical contributions, as the central claim is presented as a known phenomenon drawn from prior work.
minor comments (1)
- The manuscript is explicitly positioned as expository; consider adding a brief section or paragraph citing specific prior references on stepsize hedging to help readers locate the underlying technical literature.
Simulated Author's Rebuttal
We thank the referee for their positive review and recommendation to accept the manuscript. The report correctly identifies the paper as a short expository article on stepsize hedging with no new derivations, theorems, or experiments.
Circularity Check
Expository introduction with no derivation chain
full rationale
This manuscript is explicitly framed as a short expository article that introduces the existing phenomenon of stepsize hedging rather than advancing any new derivation, theorem, or fitted prediction. The abstract and skeptic summary confirm the central claim is presented as a known observation about gradient descent acceleration via stepsize choice, with no internal equations, parameters, or self-citations that reduce a result to its own inputs by construction. No load-bearing steps exist that match the enumerated circularity patterns, rendering the work self-contained against external benchmarks as an accessible survey of prior literature.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Lower Bounds for Anytime Acceleration of Gradient Descent
Establishes that no positive stepsize schedule achieves better than o(n^{-1.334}) anytime convergence for function values or o(n^{-1}) for squared gradient norms in smooth convex optimization.
Reference graph
Works this paper leans on
- [1]
-
[2]
Master’s thesis, Mas- sachusetts Institute of Technology
Altschuler JM (2018)Greed, Hedging, and Acceleration in Convex Optimization. Master’s thesis, Mas- sachusetts Institute of Technology
2018
-
[3]
Altschuler JM, Parrilo PA (2025) Acceleration by Stepsize Hedging: Multi-Step Descent and the Silver Stepsize Schedule.Journal of the ACM72(2):1–38
2025
-
[4]
Altschuler JM, Parrilo PA (2025) Acceleration by stepsize hedging: Silver Stepsize Schedule for smooth convex optimization.Mathematical Programming213(1–2):1105–1118
2025
-
[5]
Altschuler JM, Parrilo PA (2026) Acceleration by random stepsizes: Hedging, equalization, and the arcsine stepsize schedule.Foundations of Computational Mathematics,to appear
2026
-
[6]
Axiotis K, Sviridenko M (2023) Gradient descent converges linearly for logistic regression on separable data.International Conference on Machine Learning, 1302–1319
2023
-
[7]
Bai L, Zeng Y, Zhou B (2025) Generalization of silver stepsize schedule to stochastic optimization. Preprint at arXiv:2511.21917
-
[8]
Bertsekas DP (1999)Nonlinear programming(Athena Scientific)
1999
-
[9]
Bok J, Altschuler JM (2025) Accelerating proximal gradient descent via silver stepsizes.Conference on Learning Theory, 421–453
2025
-
[10]
Mathematical Programming,to appear
Bok J, Altschuler JM (2026) Optimized methods for composite optimization: a reduction perspective. Mathematical Programming,to appear
2026
-
[11]
Boyd S, Vandenberghe L (2004)Convex optimization(Cambridge University Press)
2004
-
[12]
Bubeck S (2015) Convex optimization: Algorithms and complexity .Foundations and Trends in Machine Learning8(3-4):231–357
2015
-
[13]
ICS News May 2026 Page 7
Cai Y, Wu J, Mei S, Lindsey M, Bartlett PL (2024) Large stepsize gradient descent for non-homogeneous two-layer networks: Margin improvement and fast optimization.Advances in Neural Information Pro- cessing Systems. ICS News May 2026 Page 7
2024
- [14]
- [15]
-
[16]
Master’s thesis, Université Catholique de Louvain
Daccache A (2019)Performance estimation of the gradient method with fixed arbitrary step sizes. Master’s thesis, Université Catholique de Louvain
2019
-
[17]
Das Gupta S, Van Parys BP, Ryu EK (2024) Branch-and-bound performance estimation programming: a unified methodology for constructing optimal optimization methods.Mathematical Programming567— -639
2024
-
[18]
Drori Y, Teboulle M (2014) Performance of first-order methods for smooth convex minimization: a novel approach.Mathematical Programming145(1–2):451–482
2014
-
[19]
d’Aspremont A, Scieur D, Taylor A (2021) Acceleration methods.Foundations and Trends® in Optimiza- tion5(1-2):1–245
2021
-
[20]
Master’s thesis, Université Catholique de Louvain
Eloi D (2022)Worst-case functions for the gradient method with fixed variable step sizes. Master’s thesis, Université Catholique de Louvain
2022
-
[21]
Grimmer B (2024) Provably faster gradient descent via long steps.SIAM Journal on Optimization 34(3):2588–2608
2024
- [22]
-
[23]
Grimmer B, Shu K, Wang AL (2025) Accelerated objective gap and gradient norm convergence for gradient descent via long steps.INFORMS Journal on Optimization7(2):156–169
2025
-
[24]
Mathematics of Operations Research,to appear
Grimmer B, Shu K, Wang AL (2026) Composing optimized stepsize schedules for gradient descent. Mathematics of Operations Research,to appear
2026
-
[25]
Hazan E (2016) Introduction to online convex optimization.Foundations and Trends in Optimization 2(3-4):157–325
2016
-
[26]
Kornowski G, Shamir O (2024) Open problem: Anytime convergence rate of gradient descent.Confer- ence on Learning Theory, volume 247
2024
-
[27]
Luenberger DG, Ye Y (1984)Linear and nonlinear programming(Springer)
1984
- [28]
- [29]
-
[30]
Nemirovskii A, Yudin DB (1983)Problem complexity and method efficiency in optimization(Wiley)
1983
-
[31]
Nesterov Y (2013)Introductory lectures on convex optimization: A basic course, volume 87 (Springer Science & Business Media)
2013
-
[32]
Dokl.27(2):372–376
Nesterov YE (1983) A method of solving a convex programming problem with convergence rate O(1/k2).Soviet Math. Dokl.27(2):372–376
1983
-
[33]
Park J, Roy A, Siegel JW, Bhattacharya A (2025) Acceleration via silver step-size on Riemannian mani- folds with applications to Wasserstein space.Advances in Neural Information Processing Systems38
2025
-
[34]
Polyak BT (1964) Some methods of speeding up the convergence of iteration methods.USSR Compu- tational Mathematics and Mathematical Physics4(5):1–17
1964
-
[35]
Polyak BT (1987)Introduction to optimization(Optimization Software, Inc.)
1987
-
[36]
Rivlin TJ (1981)An introduction to the approximation of functions(Courier Corporation)
1981
-
[37]
Sambharya R, Bok J, Matni N, Pappas G (2025) Learning acceleration algorithms for fast parametric convex optimization with certified robustness.Preprint at arXiv:2507.16264. ICS News May 2026 Page 8
-
[38]
Sambharya R, Stellato B (2025) Data-driven performance guarantees for classical and learned optimiz- ers.Journal of Machine Learning Research26(171):1–49
2025
-
[39]
Sambharya R, Stellato B (2026) Learning algorithm hyperparameters for fast parametric convex opti- mization.SIAM Journal on Mathematics of Data Science,to appear
2026
-
[40]
Shugart H, Altschuler JM (2025) Min-max optimization is strictly easier than variational inequalities. Preprint at arXiv:2511.03052
-
[41]
Shugart H, Altschuler JM (2025) Negative stepsizes make gradient-descent-ascent converge.Preprint at arXiv:2505.01423
work page internal anchor Pith review arXiv 2025
-
[42]
Smith LN (2017) Cyclical learning rates for training neural networks.IEEE Winter Conference on Appli- cations of Computer Vision, 464–472 (IEEE)
2017
-
[43]
Smith LN, Topin N (2019) Super-convergence: Very fast training of neural networks using large learn- ing rates.Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications, volume 11006, 369–386 (SPIE)
2019
-
[44]
Taylor AB, Hendrickx JM, Glineur F (2017) Smooth strongly convex interpolation and exact worst-case performance of first-order methods.Mathematical Programming161(1-2):307–345
2017
-
[45]
Master’s thesis, Université Catholique de Louvain
Vernimmen P (2024)Tight convergence analysis of exact and inexact gradient methods with constant and silver schedules. Master’s thesis, Université Catholique de Louvain
2024
-
[46]
Vernimmen P, Glineur F (2025) Empirical and computer-aided robustness analysis of long-step and ac- celerated methods in smooth convex optimization.International Conference on Modelling, Computation and Optimization in Information Systems and Management Sciences, 354–366 (Springer)
2025
-
[47]
Wang B, Ma S, Yang J, Zhou D (2026) Relaxed proximal point algorithm: Tight complexity bounds and acceleration without momentum.INFORMS Journal on Optimization8(2):141–162
2026
-
[48]
Wu J, Bartlett PL, Telgarsky M, Yu B (2024) Large stepsize gradient descent for logistic loss: Non- monotonicity of the loss improves optimization efficiency .Proceedings of the Thirty Seventh Conference on Learning Theory, Proceedings of Machine Learning Research (PMLR)
2024
-
[49]
Wu J, Marion P, Bartlett P (2025) Large stepsizes accelerate gradient descent for regularized logistic regression.Advances in Neural Information Processing Systems38:104485–104525
2025
-
[50]
Journal of Mathematics and Physics32(1-4):243–255
Young D (1953) On Richardson’s method for solving linear systems with positive definite matrices. Journal of Mathematics and Physics32(1-4):243–255
1953
-
[51]
Zhang R, Wu J, Bartlett PL (2025) Gradient descent converges arbitrarily fast for logistic regression via large and adaptive stepsizes.International Conference on Machine Learning, volume 267, 76361–76384
2025
-
[52]
Zhang Z, Jiang R (2026) Accelerated gradient descent by concatenation of stepsize schedules.SIAM Journal on Optimization,to appear
2026
-
[53]
ICS News May 2026 Page 9
Zhang Z, Lee J, Du S, Chen Y (2025) Anytime acceleration of gradient descent.Conference on Learning Theory, volume 291, 5991–6013. ICS News May 2026 Page 9
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.