Comprehensive Robustness Analysis of LiDAR-based 3D Object Detection in Autonomous Driving
Pith reviewed 2026-07-03 15:52 UTC · model grok-4.3
The pith
High-capacity voxel-based detectors prove more susceptible to structured coordinate perturbations than pillar-based detectors in LiDAR 3D object detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
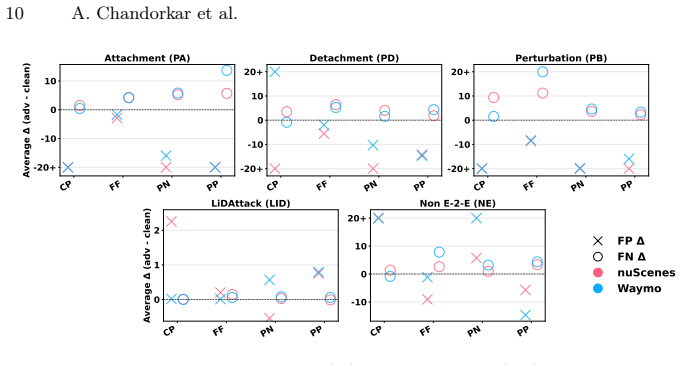
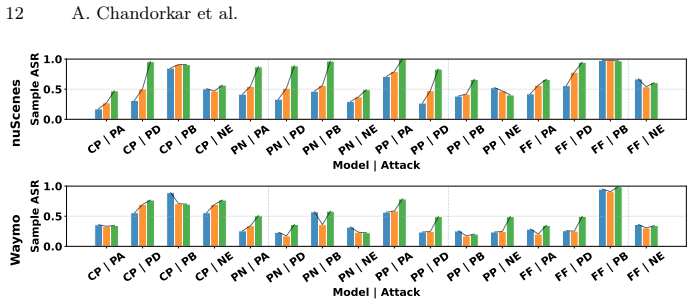
High-capacity voxel-based detectors are more susceptible to structured coordinate perturbations than pillar-based detectors, and non-anchor-based detectors demonstrate poor adversarial robustness, indicating that recent models remain as vulnerable as their predecessors.
What carries the argument
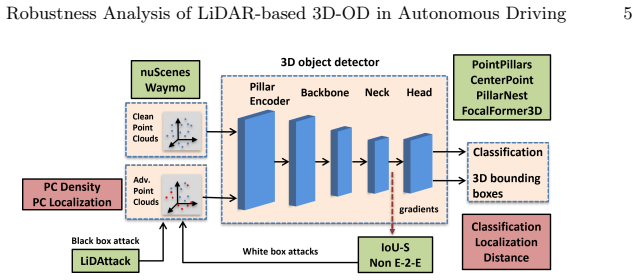
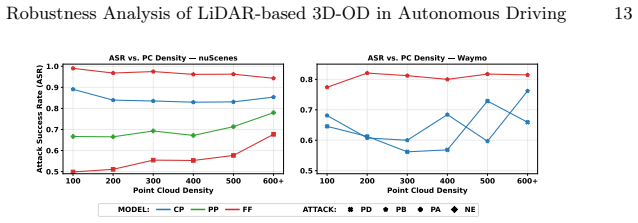
A holistic robustness evaluation framework using structural factors (point cloud density and localization) and predictive factors (misclassification, localization error, distance from ego).
Load-bearing premise
The adversarial attacks used are representative of realistic threats to deployed autonomous driving systems.
What would settle it
Observing whether the same vulnerability patterns hold when testing the models against physical-world LiDAR spoofing attacks or natural perturbations in real driving data.
Figures




read the original abstract
Recent advancements in LiDAR-only 3D object detection have demonstrated improved detection accuracy over benchmark datasets. However, the adversarial robustness of these models remains untested. Very few adversarial robustness studies exist for LiDAR-only 3D object detection and unfortunately, even they are limited to legacy models. Moreover, there is a systemic gap in the existing evaluation frameworks that rely simply on mAP ignoring other structural and predictive factors. To fill this gap, we propose a holistic framework that evaluates adversarial robustness using two structural factors (point cloud density and point cloud localization) and three predictive factors (misclassification, localization error, distance from ego). Using this framework, we perform an empirical study and critical analysis on recent and legacy state-of-the-art models using adversarial attacks specifically designed for LiDAR-based models. Our key finding is that high-capacity, voxel-based detectors are more susceptible to structured coordinate perturbations than pillar-based detectors. Additionally, non-anchor-based detectors demonstrate poor adversarial robustness, which necessitates rethinking model training techniques. Overall, our results demonstrate that recent models are as vulnerable to adversarial attacks as their predecessors. Therefore, we argue that there is a need to improve the evaluation benchmarks for 3D object detection that not only reward architectural modifications for improving detection accuracy, but also evaluate whether the design choices improve adversarial robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a holistic evaluation framework for adversarial robustness of LiDAR-based 3D object detectors that incorporates two structural factors (point cloud density and localization) and three predictive factors (misclassification, localization error, distance from ego). It conducts an empirical study on recent and legacy SOTA models using attacks specifically designed for LiDAR, reporting that high-capacity voxel-based detectors are more susceptible to structured coordinate perturbations than pillar-based detectors, that non-anchor-based detectors exhibit poor robustness, and that recent models remain as vulnerable as predecessors, thereby arguing for robustness-aware benchmarks beyond mAP.
Significance. If the attack implementations and controls are shown to be representative, the architecture-level distinctions (voxel vs. pillar, anchor vs. non-anchor) would provide actionable guidance for designing more robust detectors in safety-critical autonomous driving. The multi-factor framework is a constructive step beyond single-metric evaluations. The current lack of implementation details, however, leaves the mapping from reported perturbations to real-world risk unanchored.
major comments (2)
- [Abstract] Abstract and evaluation sections: the central claims rest on adversarial attacks 'specifically designed for LiDAR-based models,' yet no description of attack generation, physical realizability constraints (sensor spoofing, beam geometry), or comparison to natural sensor noise is supplied. This directly undermines the assertion that the observed vulnerabilities justify rethinking training techniques and that recent models are 'as vulnerable as their predecessors.'
- [Evaluation Framework] Evaluation framework and experimental setup: the manuscript provides no information on dataset splits, statistical testing procedures, or controls for confounding factors (e.g., model capacity, training data volume). Without these, the comparative findings on voxel-based vs. pillar-based susceptibility and non-anchor-based robustness cannot be verified as load-bearing.
minor comments (1)
- [Abstract] The abstract states 'systemic gap in the existing evaluation frameworks' without citing specific prior LiDAR robustness papers that were limited to legacy models; adding these references would clarify the novelty of the proposed factors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments below and will revise the manuscript to incorporate additional details where the current version is lacking.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation sections: the central claims rest on adversarial attacks 'specifically designed for LiDAR-based models,' yet no description of attack generation, physical realizability constraints (sensor spoofing, beam geometry), or comparison to natural sensor noise is supplied. This directly undermines the assertion that the observed vulnerabilities justify rethinking training techniques and that recent models are 'as vulnerable as their predecessors.'
Authors: We agree that the manuscript does not currently supply a detailed description of attack generation, physical realizability constraints, or comparisons to natural sensor noise. In the revision we will add a dedicated subsection describing the LiDAR-specific attack implementations (including coordinate perturbation methods drawn from prior literature), discuss sensor spoofing and beam geometry considerations, and include a comparison of perturbation magnitudes to typical sensor noise levels. These additions will better support the claims about rethinking training techniques and the vulnerability of recent models relative to predecessors. revision: yes
-
Referee: [Evaluation Framework] Evaluation framework and experimental setup: the manuscript provides no information on dataset splits, statistical testing procedures, or controls for confounding factors (e.g., model capacity, training data volume). Without these, the comparative findings on voxel-based vs. pillar-based susceptibility and non-anchor-based robustness cannot be verified as load-bearing.
Authors: We acknowledge that the current text omits explicit details on dataset splits, statistical testing, and controls for confounding factors. The revised manuscript will specify the dataset splits used, describe any statistical procedures applied to the multi-factor robustness metrics, and discuss controls or accounting for model capacity and training data volume when interpreting the voxel/pillar and anchor/non-anchor distinctions. These additions will improve verifiability of the reported architecture-level findings. revision: yes
Circularity Check
No circularity; empirical robustness claims rest on direct evaluations, not derivations or self-referential fits.
full rationale
The paper is an empirical study that proposes a multi-factor evaluation framework and applies existing LiDAR-specific adversarial attacks to compare detector architectures. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims (voxel vs. pillar susceptibility; non-anchor robustness) are presented as outcomes of those direct comparisons rather than reductions to inputs by construction. This matches the default case of a self-contained empirical paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sensors25(19) (2025).https://doi.org/10.3390/s25196026,https: //www.mdpi.com/1424-8220/25/19/6026
Abraha, T.M., Graham-Knight, J.B., Lasserre, P., Najjaran, H., Lucet, Y.: Convnet-generated adversarial perturbations for evaluating 3d object detection robustness. Sensors25(19) (2025).https://doi.org/10.3390/s25196026,https: //www.mdpi.com/1424-8220/25/19/6026
-
[2]
Ansel, J., Yang, E., He, H., Gimelshein, N., Jain, A., Voznesensky, M., Bao, B., Bell, P., Berard, D., Burovski, E., Chauhan, G., Chourdia, A., et al.: PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation. In: 29th ACM International Conference on Architectural Support for Programming Languages and Operati...
-
[3]
Aung, N.H.H., Sangwongngam, P., Jintamethasawat, R., Shah, S., Wuttisittikulkij, L.: A review of lidar-based 3d object detection via deep learning approaches to- wardsrobustconnectedandautonomousvehicles.IEEETransactionsonIntelligent Vehicles10(1), 526–547 (2025).https://doi.org/10.1109/TIV.2024.3415771
-
[4]
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving (2020),https://doi.org/10.1109/CVPR42600.2020.01164
-
[5]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV) Workshops
Chandorkar,A.,Tercan,H.,Meisen,T.:Rethinkingbackbonedesignforlightweight 3d object detection in lidar. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV) Workshops. pp. 1698–1706 (October 2025). https://doi.org/https://doi.org/10.48550/arXiv.2508.00744
-
[6]
IEEE Transactions on Intelligent Transportation Systems25(11), 16118–16132 (2024)
Chen, H., Yan, H., Yang, X., Su, H., Zhao, S., Qian, F.: Efficient adversarial at- tack strategy against 3d object detection in autonomous driving systems. IEEE Transactions on Intelligent Transportation Systems25(11), 16118–16132 (2024). https://doi.org/10.1109/TITS.2024.3410038
-
[7]
Chen, J., Liao, D., Yan, Y., Xiang, S., Zheng, H.: Lidattack: Robust black-box attack on lidar-based object detection. IEEE Transactions on Intelligent Trans- portation Systems26(9), 13563–13572 (2025).https://doi.org/10.1109/TITS. 2025.3573055
-
[8]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Chen, Y., Yu, Z., Chen, Y., Lan, S., Anandkumar, A., Jia, J., Alvarez, J.M.: FocalFormer3D : Focusing on Hard Instance for 3D Object Detection . In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 8360–8371. IEEE Computer Society, Los Alamitos, CA, USA (Oct 2023).https://doi.org/ 10.1109/ICCV51070.2023.00771,https://doi.ieeecomputers...
-
[9]
Chen, Y., Liu, J., Zhang, X., Qi, X., Jia, J.: Voxelnext: Fully sparse voxelnet for 3d object detection and tracking (2023).https://doi.org/10.1109/CVPR52729. 2023.02076
-
[10]
Contributors, M.: MMDetection3D: OpenMMLab next-generation platform for general 3D object detection.https://github.com/open- mmlab/mmdetection3d (2020)
2020
-
[12]
Du, B., Zhang, C., Sarkar, A., Shen, J., Telikani, A., Hu, H.: Identifying factors related to pedestrian and cyclist crashes in act, australia with an extended crash dataset. Accident Analysis & Prevention207, 107742 (2024).https://doi.org/ https://doi.org/10.1016/j.aap.2024.107742,https://www.sciencedirect. com/science/article/pii/S0001457524002872
- [13]
-
[14]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Eskandar, G.: An empirical study of the generalization ability of lidar 3d object detectors to unseen domains. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 23815–23825 (2024).https://doi.org/10. 1109/CVPR52733.2024.02248
- [15]
-
[16]
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The KITTI dataset. International Journal of Robotics Research (IJRR)32(11), 1231–1237 (2013).https://doi.org/https://dl.acm.org/doi/10.1177/02783649134912
-
[17]
Explaining and Harnessing Adversarial Examples
Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014).https://doi.org/10.48550/ arXiv.1412.6572
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[18]
Hariya, K., Inoshita, H., Fukuda, Y., Yoneda, K., Suganuma, N.: Real-time 3d object detection with distance-aware hybrid point cloud representation toward long range detection. International Journal of Intelligent Transportation Systems Research (12 2025).https://doi.org/https://doi.org/10.1007/s13177-025- 00598-2
-
[19]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kong, L., Liu, Y., Li, X., Chen, R., Zhang, W., Ren, J., Pan, L., Chen, K., Liu, Z.: Robo3d: Towards robust and reliable 3d perception against corruptions. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 19994–20006 (October 2023),https://doi.ieeecomputersociety.org/10. 1109/ICCV51070.2023.01830
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lang, A.H., Vora, S., Caesar, H., Zhou, B., Yang, J., Beijbom, O.: Pointpillars: Fast encoders for object detection from point clouds. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12697–12705 (2019). https://doi.org/10.1109/CVPR.2019.01298
-
[21]
Li, J., Luo, C., Yang, X.: Pillarnext: Rethinking network designs for 3d ob- ject detection in lidar point clouds. In: 2023 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR). pp. 17567–17576 (2023).https: //doi.org/10.1109/CVPR52729.2023.01685
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for the 2020s. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11976–11986 (June 2022).https://doi.org/ 10.1109/CVPR52688.2022.01186
-
[23]
IET Computer Vision19(1), e70011 (2025)
Long, H., Chen, H., Xu, M., Zhang, C., Qian, F.: Crafting transferable adversarial examples against 3d object detection. IET Computer Vision19(1), e70011 (2025). https://doi.org/https://doi.org/10.1049/cvi2.70011
-
[24]
IEEE Transactions on Vehicular Technology74(1), 292–305 (2025)
Lu, Y., Hao, X., Li, Y., Chai, W., Sun, S., Velipasalar, S.: Range-aware atten- tion network for lidar-based 3d object detection with auxiliary point density level estimation. IEEE Transactions on Vehicular Technology74(1), 292–305 (2025). https://doi.org/10.1109/TVT.2024.3454607 18 A. Chandorkar et al
-
[25]
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A.: Towards deep learning models resistant to adversarial attacks (2019),https://arxiv.org/abs/1706. 06083
2019
-
[26]
Towards Deep Learning Models Resistant to Adversarial Attacks
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A.: Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083 (2017). https://doi.org/10.48550/arXiv.1706.06083
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.06083 2017
-
[27]
IEEE Transactions on Intelligent Vehicles10(4), 2905–2914 (2025).https://doi.org/10.1109/TIV
Mao,W.,Wang,T.,Zhang,D.,Yan,J.,Yoshie,O.:Pillarnest:Embracingbackbone scaling and pretraining for pillar-based 3d object detection. IEEE Transactions on Intelligent Vehicles10(4), 2905–2914 (2025).https://doi.org/10.1109/TIV. 2024.3386576
work page doi:10.1109/tiv 2025
-
[28]
Scarano, A., Aria, M., Mauriello, F., Riccardi, M.R., Montella, A.: Systematic literature review of 10 years of cyclist safety research. Accident Analysis & Pre- vention184, 106996 (2023).https://doi.org/https://doi.org/10.1016/ j.aap.2023.106996,https://www.sciencedirect.com/science/article/pii/ S000145752300043X
-
[29]
In: European Conference on Computer Vision
Shi, G., Li, R., Ma, C.: Pillarnet: Real-time and high-performance pillar-based 3d object detection. In: European Conference on Computer Vision. pp. 35–52 (2022). https://doi.org/https://doi.org/10.1007/978-3-031-20080-9_3
-
[30]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
Shi, S., Guo, C., Jiang, L., Wang, Z., Shi, J., Wang, X., Li, H.: Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10526–10535 (2020). https://doi.org/10.1109/CVPR42600.2020.01054
-
[31]
Shi, S., Jiang, L., Deng, J., Wang, Z., Guo, C., Shi, J., Wang, X., Li, H.: Pv- rcnn++: Point-voxel feature set abstraction with local vector representation for 3d object detection (2022),https://doi.org/10.48550/arXiv.2102.00463
-
[32]
In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Shi, S., Wang, X., Li, H.: Pointrcnn: 3d object proposal generation and detection from point cloud. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 770–779 (2019).https://doi.org/10.1109/CVPR.2019. 00086
-
[33]
Shi,S.,Wang,Z.,Shi,J.,Wang,X.,Li,H.:Frompointstoparts:3dobjectdetection from point cloud with part-aware and part-aggregation network (2020),https: //doi.org/10.48550/arXiv.1907.03670
-
[34]
Song, Z., Liu, L., Jia, F., Luo, Y., Jia, C., Zhang, G., Yang, L., Wang, L.: Robustness-aware 3d object detection in autonomous driving: A review and out- look. IEEE Transactions on Intelligent Transportation Systems25(11), 15407– 15436 (2024).https://doi.org/10.1109/TITS.2024.3439557
-
[35]
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V., Tsui, P., Guo, J., Zhou, Y., Chai, Y., Caine, B., Vasudevan, V., Han, W., Ngiam, J., Zhao, H., Timofeev, A., Ettinger, S., Krivokon, M., Gao, A., Joshi, A., Zhang, Y., Shlens, J., Chen, Z., Anguelov, D.: Scalability in perception for autonomous driving: Waymo open dataset. In: Proceedings ...
-
[36]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
Tu, J., Ren, M., Manivasagam, S., Liang, M., Yang, B., Du, R., Cheng, F., Urtasun, R.: Physically realizable adversarial examples for lidar object detection. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13713–13722 (2020).https://doi.org/10.1109/CVPR42600.2020.01373
-
[37]
In: European conference on computer vision
Wang, J., Meng, Q., Liu, G., Yan, L., Wang, K., Cheng, M.M., Hou, Q.: Towards stable 3d object detection. In: European conference on computer vision. Springer (2024).https://doi.org/https://doi.org/10.1007/978-3-031-72973-7_12 Robustness Analysis of LiDAR-based 3D-OD in Autonomous Driving 19
-
[38]
IEEE Internet of Things Journal12(12), 21404–21414 (2025).https://doi.org/10.1109/JIOT
Wang, Y., Wu, L., Jin, J., Wang, E., Zhang, Z., Zhao, Y.: An imperceptible adver- sarial attack against 3-d object detectors in autonomous driving. IEEE Internet of Things Journal12(12), 21404–21414 (2025).https://doi.org/10.1109/JIOT. 2025.3547966
-
[39]
In: Proceedings of the 37th International Conference on Neural Infor- mation Processing Systems
Wang, Z., Li, Y., Chen, X., Zhao, H., Wang, S.: Uni3detr: unified 3d detection transformer. In: Proceedings of the 37th International Conference on Neural Infor- mation Processing Systems. NIPS ’23, Curran Associates Inc., Red Hook, NY, USA (2023).https://doi.org/https://dl.acm.org/doi/10.5555/3666122.3667855
-
[40]
In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xiang, C., Qi, C.R., Li, B.: Generating 3d adversarial point clouds. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9128–9136 (2019).https://doi.org/10.1109/CVPR.2019.00935
- [41]
-
[42]
arXiv preprint arXiv:2404.07495 (2024),https://doi.org/10.48550/arXiv.2404.07495
Xu, W., Zhou, S., Yuan, Z.: Pillartrack: Redesigning pillar-based transformer net- work for single object tracking on point clouds. arXiv preprint arXiv:2404.07495 (2024),https://doi.org/10.48550/arXiv.2404.07495
-
[43]
Sen- sors18(10), 3337 (2018).https://doi.org/10.3390/s18103337
Yan, Y., Mao, Y., Li, B.: Second: Sparsely embedded convolutional detection. Sen- sors18(10), 3337 (2018).https://doi.org/10.3390/s18103337
-
[44]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR)
Yan, Z., Lin, Y., Wang, K., Zheng, Y., Wang, Y., Zhang, Z., Li, J., Yang, J.: Tri-perspective view decomposition for geometry-aware depth completion. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR). pp. 4874–4884 (June 2024).https://doi.org/https://doi.org/ 10.48550/arXiv.2403.15008
-
[45]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
Yang,Z.,Sun,Y.,Liu,S.,Jia,J.:3dssd:Point-based3dsinglestageobjectdetector. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11037–11045 (2020).https://doi.org/10.1109/CVPR42600.2020. 01105
-
[46]
Zee- shan Zia, and Quoc-Huy Tran
Yin, T., Zhou, X., Krähenbühl, P.: Center-based 3d object detection and tracking. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11779–11788 (2021).https://doi.org/10.1109/CVPR46437.2021. 01161
-
[47]
Zhang, P., Li, X., Lin, X., He, L.: A new literature review of 3d object detection on autonomous driving. J. Artif. Int. Res.82(Jun 2025),https://doi.org/10. 1613/jair.1.15961
2025
-
[48]
Zhang, Y., Hou, J., Yuan, Y.: A comprehensive study of the robustness for lidar- based 3d object detectors against adversarial attacks (2023),https://doi.org/ 10.1007/s11263-023-01934-3
-
[49]
Zhou, C., Zhang, Y., Chen, J., Huang, D.: Octr: Octree-based transformer for 3d object detection. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5166–5175 (2023).https://doi.org/10.1109/ CVPR52729.2023.00500
- [50]
-
[51]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhou, Y., Tuzel, O.: Voxelnet: End-to-end learning for point cloud based 3d object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4490–4499 (2018).https://doi.org/10.1109/CVPR.2018.00472
-
[52]
IEEE Transactions on Intelligent Transportation Systems (2023)
Zhu, J., et al.: Vulnerability analysis of lidar-based 3d object detection to adversar- ial lidar points. IEEE Transactions on Intelligent Transportation Systems (2023). https://doi.org/10.1109/TITS.2023.3274635 20 A. Chandorkar et al
-
[53]
Zhu, Z., Zhang, Y., Chen, H., Dong, Y., Zhao, S., Ding, W., Zhong, J., Zheng, S.: Understanding the robustness of 3d object detection with bird’view rep- resentations in autonomous driving. In: 2023 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR). pp. 21600–21610 (2023).https: //doi.org/10.1109/CVPR52729.2023.02069
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.