Coding-agents can replicate scientific machine learning papers
Pith reviewed 2026-07-03 13:03 UTC · model grok-4.3
The pith
A workflow turns paper claims into tracked targets so coding agents can replicate scientific machine learning results with verifiable evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
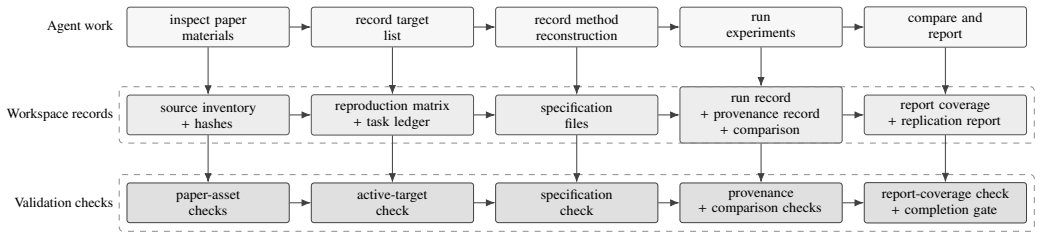
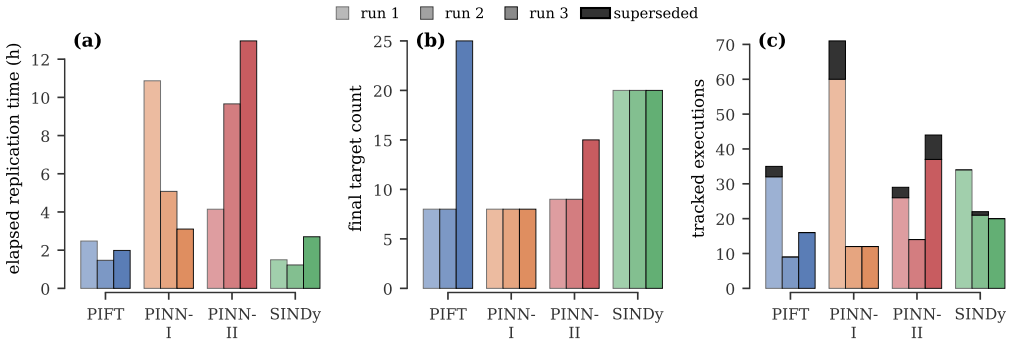
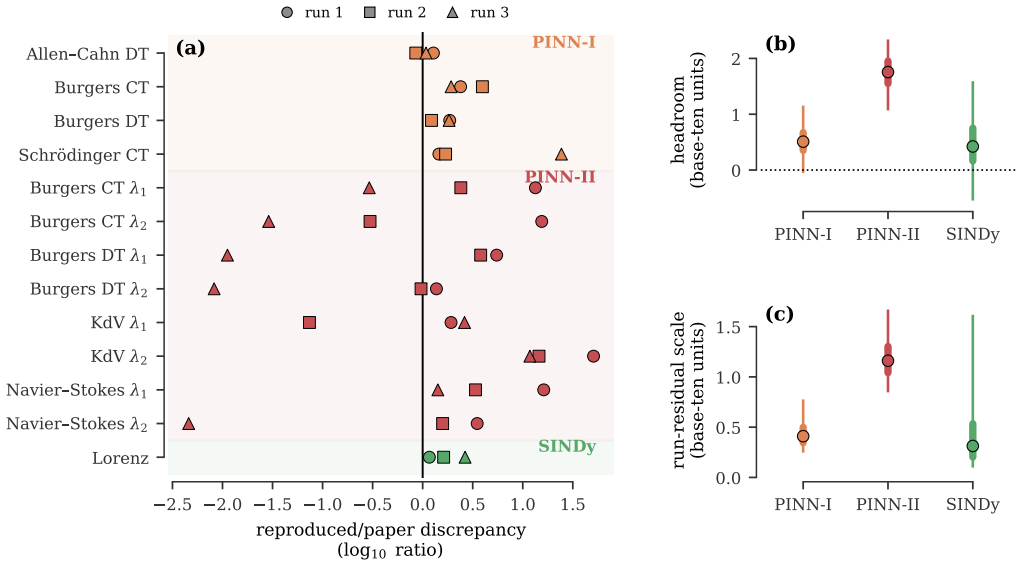
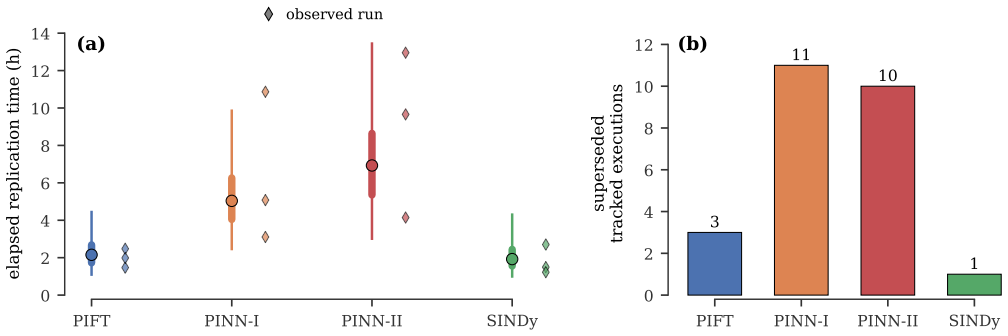
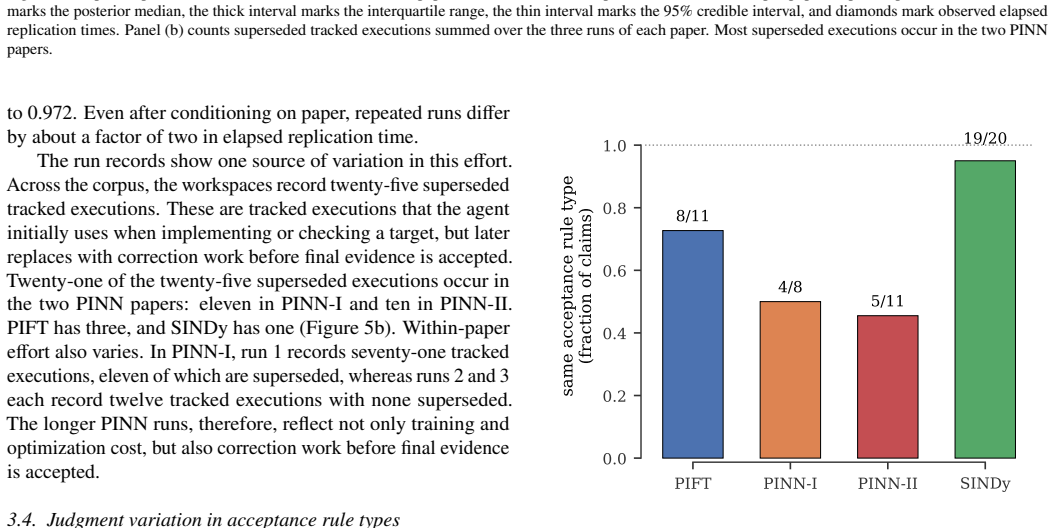
Paper-replication records each selected paper claim as a target with evidence, reconstructs the method from the paper materials alone, runs the computational experiments, links generated outputs to provenance and direct comparisons with the original claims, records the location of matched evidence inside the replication report, and requires validation checks before the workspace is marked complete. In twelve runs across four papers every workspace passed the completion gate and every one of the 158 recorded targets was matched with report coverage, even though the runs differed in target division, numerical fidelity, elapsed time, number of intermediate executions, and acceptance rules.
What carries the argument
The Paper-replication workflow, which converts each paper claim into a target that must be matched with provenance-linked evidence and pass explicit validation checks.
If this is right
- Replication success becomes a property of the workspace state rather than the agent's final statement.
- Each claim receives an explicit record of where matching evidence appears in the report.
- Variations in target division and acceptance rules can occur even after all targets are covered.
- The process produces a report that directly supports or refutes the paper's original computational claims.
Where Pith is reading between the lines
- The same target-tracking structure could be applied to computational claims in papers outside machine learning.
- Rules for splitting claims into targets and accepting evidence could be refined to reduce variation across runs.
- Measuring exact numerical agreement versus approximate agreement would give a finer test of replication quality.
Load-bearing premise
The coding agent can reconstruct the paper's method from the given materials and generate correct computational evidence without external domain knowledge or implementation mistakes.
What would settle it
A completed workspace in which the generated numerical results or method steps differ from the paper in a way that makes the evidence invalid for the recorded targets.
Figures

read the original abstract
Scientific machine learning papers typically make computational claims, e.g., that the relative mean square error is less than 5% or that the 95% predictive credible interval covers the test data. A coding agent can be prompted to replicate those claims from paper materials alone, but the prompt does not by itself reliably preserve progress or check whether generated evidence supports the paper's claims. We introduce Paper-replication, a workflow that makes each selected paper claim a target with recorded evidence, and implement it as a coding-agent skill. The workflow makes the agent record those targets, reconstruct the paper's method, run computational experiments, link generated outputs to provenance and comparisons with the paper's claims, record where matched evidence appears in the replication report, and pass validation checks before completion. We evaluate Paper-replication on twelve independent runs across four scientific machine learning papers. All twelve workspaces pass the completion gate, and all 158 recorded targets are matched with report coverage. Even in this completed workspace state, repeated runs differ in how papers are divided into targets, in numerical fidelity to the source papers, in elapsed replication time, in the number of intermediate executions replaced before final evidence is accepted, and in the rules used to accept evidence. Paper-replication makes completion depend on workspace evidence and validation checks rather than on the agent's final message.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Paper-replication, a structured workflow implemented as a coding-agent skill that converts computational claims from scientific ML papers into recorded targets, requires the agent to reconstruct methods, generate evidence with provenance links and claim comparisons, and pass validation checks before declaring completion. On twelve independent runs across four papers, all workspaces reach the completion gate and all 158 targets are matched with report coverage, although the abstract notes variability across runs in numerical fidelity, target decomposition, elapsed time, intermediate executions, and acceptance rules.
Significance. If the workflow produces replications whose evidence faithfully matches the source claims in both method and numerical outcome, the approach would offer a concrete, auditable mechanism for automated scientific reproducibility that goes beyond unstructured prompting. The explicit recording of targets, provenance, and validation steps is a methodological strength that could be adopted more broadly; however, the dependence on internal agent-driven checks and the acknowledged variability in fidelity limit the immediate impact until external validation is demonstrated.
major comments (2)
- [Abstract] Abstract: the headline claim that 'all twelve workspaces pass the completion gate, and all 158 recorded targets are matched with report coverage' is load-bearing for the central thesis, yet the same paragraph records variability in numerical fidelity and acceptance rules; without quantitative bounds on acceptable deviation or an independent fidelity metric, it remains unclear whether matched targets constitute accurate reconstruction of the original methods and results.
- [Abstract] Abstract and evaluation description: success is defined entirely by the agent's selection of targets, its own comparisons to the source claims, and satisfaction of the workflow's internal validation checks; this creates a risk that a workspace can complete while the generated implementation deviates from the paper's method or produces only loosely corresponding numerical outcomes, exactly the concern raised by the weakest assumption in the evaluation design.
minor comments (2)
- The manuscript would benefit from an explicit methods subsection detailing the precise acceptance rules used for evidence and how they were held constant (or allowed to vary) across the twelve runs.
- Clarify whether the four source papers were chosen according to pre-specified criteria (e.g., computational claims only, open code, etc.) so that the 12-run evaluation can be assessed for selection bias.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the evaluation design in our manuscript. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'all twelve workspaces pass the completion gate, and all 158 recorded targets are matched with report coverage' is load-bearing for the central thesis, yet the same paragraph records variability in numerical fidelity and acceptance rules; without quantitative bounds on acceptable deviation or an independent fidelity metric, it remains unclear whether matched targets constitute accurate reconstruction of the original methods and results.
Authors: The claim in the abstract is factual with respect to the workflow: every workspace satisfied the completion criteria, and every target had associated report coverage through the required provenance and comparison steps. The variability in numerical fidelity is explicitly noted to indicate that 'matched' refers to the presence of linked evidence and a comparison step, not necessarily to zero deviation. We do not provide quantitative bounds because the acceptance rules are part of the workflow's internal validation and vary by target type (e.g., error thresholds for MSE claims). We will revise the manuscript to add a short clarification in the abstract and evaluation section explaining that matching is determined by the workflow's validation checks rather than an external metric. This constitutes a partial revision. revision: partial
-
Referee: [Abstract] Abstract and evaluation description: success is defined entirely by the agent's selection of targets, its own comparisons to the source claims, and satisfaction of the workflow's internal validation checks; this creates a risk that a workspace can complete while the generated implementation deviates from the paper's method or produces only loosely corresponding numerical outcomes, exactly the concern raised by the weakest assumption in the evaluation design.
Authors: The design intentionally places the validation inside the workflow to create an auditable record of targets, evidence, and comparisons. The agent must record targets from the paper, generate evidence with provenance, perform comparisons, and pass the checks; completion is not granted by the agent's final message alone. While this does not eliminate the possibility of loose correspondence, the requirement for explicit links and report coverage makes deviations traceable. We agree that this is a limitation of the current evaluation and does not substitute for external validation. No revision is planned for this point as it reflects the stated scope of the work. revision: no
- Demonstration of external validation or independent fidelity assessment of the generated replications.
Circularity Check
No circularity: success metrics tied to external paper claims, not internal definitions
full rationale
The paper describes an empirical workflow evaluation on twelve runs across four independent scientific machine learning papers, reporting that all workspaces pass completion and all 158 targets match with report coverage. No equations, fitted parameters, or derivations appear in the provided text. The central claim rests on matching generated evidence to claims extracted from external source papers rather than any self-referential reduction, self-citation chain, or renaming of known results. The workflow's internal validation checks serve as an implementation detail for the evaluation protocol but do not force the reported success rate by construction, as the targets originate outside the workflow.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coding agents prompted with paper materials alone can reconstruct and execute the computational methods described in scientific ML papers.
Reference graph
Works this paper leans on
-
[1]
Categorizing Variants of Goodhart's Law
Categorizing variants of Goodhart's Law , author=. arXiv preprint arXiv:1803.04585 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
2024 , howpublished=
Reward Hacking in Reinforcement Learning , author=. 2024 , howpublished=
2024
-
[3]
Proceedings of machine learning and systems , volume=
Accounting for variance in machine learning benchmarks , author=. Proceedings of machine learning and systems , volume=
-
[4]
OpenAI engineering note , year=
Harness engineering: leveraging codex in an agent-first world , author=. OpenAI engineering note , year=
-
[5]
Science , volume=
Reproducible research in computational science , author=. Science , volume=. 2011 , publisher=
2011
-
[6]
Science , volume=
Enhancing reproducibility for computational methods , author=. Science , volume=. 2016 , publisher=
2016
-
[7]
PLoS computational biology , volume=
Ten simple rules for reproducible computational research , author=. PLoS computational biology , volume=. 2013 , publisher=
2013
-
[8]
PLoS computational biology , volume=
Good enough practices in scientific computing , author=. PLoS computational biology , volume=. 2017 , publisher=
2017
-
[9]
Terminologies for Reproducible Research
Terminologies for reproducible research , author=. arXiv preprint arXiv:1802.03311 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Journal of Computing and Information Science in Engineering , volume=
A bayesian hierarchical model for extracting individuals’ theory-based causal knowledge , author=. Journal of Computing and Information Science in Engineering , volume=. 2023 , publisher=
2023
-
[11]
2024 , school=
A SCALABLE PROBABILISTIC METHOD FOR SUPER-RESOLUTION OF 4D FLOW MRI HEMODYNAMIC FIELDS , author=. 2024 , school=
2024
-
[12]
Journal of machine learning research , volume=
Improving reproducibility in machine learning research (a report from the neurips 2019 reproducibility program) , author=. Journal of machine learning research , volume=
2019
-
[13]
A practical taxonomy of reproducibility for machine learning research , author=
-
[14]
Proceedings of the AAAI conference on artificial intelligence , volume=
State of the art: Reproducibility in artificial intelligence , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[15]
arXiv preprint arXiv:2505.12494 , year=
SMURF: Scalable method for unsupervised reconstruction of flow in 4D flow MRI , author=. arXiv preprint arXiv:2505.12494 , year=
-
[16]
Proceedings of the AAAI conference on artificial intelligence , volume=
Deep reinforcement learning that matters , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[17]
Nature Reviews Physics , volume=
Physics-informed machine learning , author=. Nature Reviews Physics , volume=. 2021 , publisher=
2021
-
[18]
Journal of Computational physics , volume=
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational physics , volume=. 2019 , publisher=
2019
-
[19]
Physics informed deep learning (part i): Data-driven solutions of nonlinear partial differential equations , author=. arXiv preprint arXiv:1711.10561 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Physics Informed Deep Learning (Part II): Data-driven Discovery of Nonlinear Partial Differential Equations , author=. arXiv preprint arXiv:1711.10566 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Measurement Science and Technology , volume=
Bayesian reconstruction of 3D particle positions in high-seeding density flows , author=. Measurement Science and Technology , volume=. 2024 , publisher=
2024
-
[22]
Proceedings of the national academy of sciences , volume=
Discovering governing equations from data by sparse identification of nonlinear dynamical systems , author=. Proceedings of the national academy of sciences , volume=. 2016 , publisher=
2016
-
[23]
Science advances , volume=
Data-driven discovery of partial differential equations , author=. Science advances , volume=. 2017 , publisher=
2017
-
[24]
Universal Differential Equations for Scientific Machine Learning
Universal differential equations for scientific machine learning , author=. arXiv preprint arXiv:2001.04385 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[25]
Advances in neural information processing systems , volume=
Neural ordinary differential equations , author=. Advances in neural information processing systems , volume=
-
[26]
International Design Engineering Technical Conferences and Computers and Information in Engineering Conference , volume=
Quantifying individuals’ theory-based knowledge using probabilistic causal graphs: a bayesian hierarchical approach , author=. International Design Engineering Technical Conferences and Computers and Information in Engineering Conference , volume=. 2020 , organization=
2020
-
[27]
Acta numerica , volume=
Inverse problems: a Bayesian perspective , author=. Acta numerica , volume=. 2010 , publisher=
2010
-
[28]
Journal of Computational Physics , volume=
Physics-informed information field theory for modeling physical systems with uncertainty quantification , author=. Journal of Computational Physics , volume=. 2023 , publisher=
2023
-
[29]
2026 , note=
Codex web , author=. 2026 , note=
2026
-
[30]
2026 , note=
Claude Code overview , author=. 2026 , note=
2026
-
[31]
2025 , note=
Equipping agents for the real world with Agent Skills , author=. 2025 , note=
2025
-
[32]
2026 , note=
Agent Skills , author=. 2026 , note=
2026
-
[33]
International Conference on Learning Representations , volume=
Swe-bench: Can language models resolve real-world github issues? , author=. International Conference on Learning Representations , volume=
-
[34]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
International Conference on Learning Representations , volume=
Agentbench: Evaluating llms as agents , author=. International Conference on Learning Representations , volume=
-
[36]
International conference on learning representations , volume=
Large language models cannot self-correct reasoning yet , author=. International conference on learning representations , volume=
-
[37]
W3C Recommendation , volume=
Prov-dm: The prov data model , author=. W3C Recommendation , volume=. 2013 , publisher=
2013
-
[38]
Proceedings of the 2008 ACM SIGMOD international conference on Management of data , pages=
Provenance and scientific workflows: challenges and opportunities , author=. Proceedings of the 2008 ACM SIGMOD international conference on Management of data , pages=
2008
-
[39]
Genome biology , volume=
Galaxy: a comprehensive approach for supporting accessible, reproducible, and transparent computational research in the life sciences , author=. Genome biology , volume=. 2010 , publisher=
2010
-
[40]
15th Int
Stochastic volumetric reconstruction , author=. 15th Int. Symp. on Particle Image Velocimetry-ISPIV , year=
-
[41]
Positioning and power in academic publishing: players, agents and agendas: proceedings of the 20th International Conference on Electronic Publishing , pages=
Jupyter Notebooks-a publishing format for reproducible computational workflows , author=. Positioning and power in academic publishing: players, agents and agendas: proceedings of the 20th International Conference on Electronic Publishing , pages=. 2016 , organization=
2016
-
[42]
PaperBench: Evaluating AI's Ability to Replicate AI Research
PaperBench: Evaluating AI's Ability to Replicate AI Research , author=. arXiv preprint arXiv:2504.01848 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
arXiv preprint arXiv:2504.17192 , year=
Paper2code: Automating code generation from scientific papers in machine learning , author=. arXiv preprint arXiv:2504.17192 , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
Researchcodebench: Benchmarking llms on implementing novel machine learning research code , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
International Workshop on AI for Transportation , pages=
Researchcodeagent: An llm multi-agent system for automated codification of research methodologies , author=. International Workshop on AI for Transportation , pages=. 2025 , organization=
2025
-
[46]
arXiv preprint arXiv:2504.00255 , year=
Scireplicate-bench: Benchmarking llms in agent-driven algorithmic reproduction from research papers , author=. arXiv preprint arXiv:2504.00255 , year=
-
[47]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Lmr-bench: Evaluating llm agent’s ability on reproducing language modeling research , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[48]
arXiv preprint arXiv:2506.19724 , year=
From Reproduction to Replication: Evaluating Research Agents with Progressive Code Masking , author=. arXiv preprint arXiv:2506.19724 , year=
-
[49]
Core-bench: Fostering the credibility of published research through a computational reproducibility agent benchmark , author=. arXiv preprint arXiv:2409.11363 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
REPRO-BENCH: Can Agentic AI Systems Assess the Reproducibility of Social Science Research? , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[51]
ReplicatorBench: Benchmarking LLM Agents for Replicability in Social and Behavioral Sciences
Replicatorbench: Benchmarking llm agents for replicability in social and behavioral sciences , author=. arXiv preprint arXiv:2602.11354 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
AI Coding Agents Can Reproduce Social Science Findings
AI Coding Agents Can Reproduce Social Science Findings , author=. arXiv preprint arXiv:2606.11447 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Companion Proceedings of the ACM Web Conference 2026 , pages=
Automating computational reproducibility in social science: Comparing prompt-based and agent-based approaches , author=. Companion Proceedings of the ACM Web Conference 2026 , pages=
2026
-
[54]
Read the Paper, Write the Code: Agentic Reproduction of Social-Science Results
Read the paper, write the code: Agentic reproduction of social-science results , author=. arXiv preprint arXiv:2604.21965 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
ReplicationBench: Can AI Agents Replicate Astrophysics Research Papers? , author=. arXiv preprint arXiv:2510.24591 , year=
-
[56]
Can Coding Agents Reproduce Findings in Computational Materials Science?
Can Coding Agents Reproduce Findings in Computational Materials Science? , author=. arXiv preprint arXiv:2605.00803 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Collider-Bench: Benchmarking AI Agents with Particle Physics Analysis Reproduction
Collider-Bench: Benchmarking AI Agents with Particle Physics Analysis Reproduction , author=. arXiv preprint arXiv:2605.13950 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.