A²utoLPBench: An Auto-Generated, Agent-Friendly LP Benchmark via Inverse-KKT Construction
Pith reviewed 2026-07-03 14:06 UTC · model grok-4.3
The pith
A generator builds linear programming word problems whose optimal solutions are known exactly by construction, with no solver or human label needed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying the inverse-KKT construction—selecting a feasible point together with its dual and writing down the linear program that makes that point optimal—the authors produce an unlimited stream of plain-text LP problems whose ground-truth solutions and objective values are correct by design rather than by external verification.
What carries the argument
Inverse-KKT construction: the step that derives an LP from a pre-chosen optimal primal-dual pair so optimality holds by algebraic identity.
If this is right
- Any number of fresh problems can be produced without repeating content across runs.
- Difficulty is adjustable in advance by choosing the dimensions (n, m) before generation.
- Scores remain comparable across independent batches because every answer is exact.
- Training-data leakage can be avoided by selecting seed ranges after any model cutoff date.
- The bundled Docker environment lets an agent run the full benchmark with a single command.
Where Pith is reading between the lines
- The same construction pattern could be tried for quadratic or integer programs where an inverse optimality condition is also available.
- Agents could be tested on streams of problems whose difficulty increases automatically during a single run.
- The generator could be paired with other modalities such as diagram-to-LP translation to measure cross-format robustness.
- Public leaderboards could adopt rolling seed windows so that reported scores stay valid even after models are retrained.
Load-bearing premise
Problems built this way match the structure and difficulty of real LP word problems that human users would actually pose to an agent.
What would settle it
Collect an independent set of human-written LP word problems, run the same agents on both sets, and check whether success rates or error patterns diverge sharply or whether the generated problems systematically differ in constraint density or variable scaling from the human set.
Figures
read the original abstract
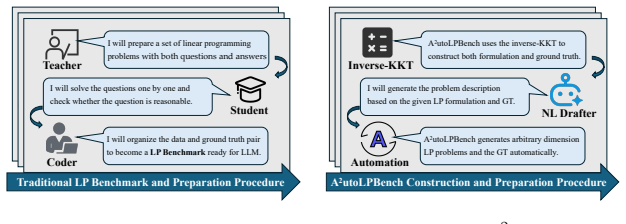
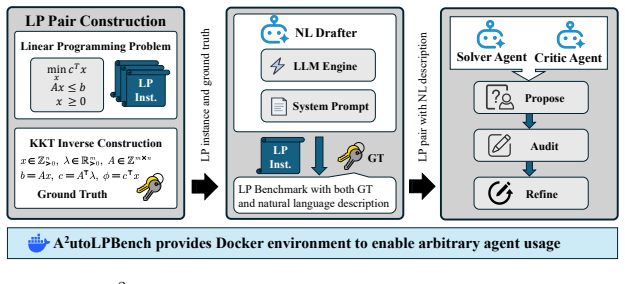
Most LP-from-text benchmarks are static datasets of word problems written and labeled by hand. Once such a dataset is released, its size is fixed, its difficulty is fixed, and every problem can leak into the training data of future LLMs. We present \textbf{A$^{2}$utoLPBench}, a benchmark for testing LLM-driven agents on linear programming problems written in plain text. We first pick a feasible point and dual, then write down a problem for which that point is optimal and the objective value is known. The answer is known by construction, with no solver call and no human annotator. The evaluation environment bundles a reference solver-critic baseline and a Docker image whose usage instructions are written for an LLM-driven agent to read. With these in place, any agent can run the benchmark and get a calibrated score with one command. Because the benchmark is a generator rather than a fixed dataset, it has properties no fixed dataset can match: an unlimited supply of fresh problems, a difficulty knob set by $(n,m)$, ground-truth answers correct by construction, low LLM-side cost per problem relative to human authoring, repeatable scores across independent batches, and resistance to training-data leakage when fresh post-cutoff seed ranges are used.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces A²utoLPBench, a generator-based benchmark for evaluating LLM-driven agents on linear programming problems expressed in plain text. The central method selects a primal feasible point x* and dual multipliers, then constructs the LP coefficients (c, A, b) such that the KKT conditions hold exactly at that point; because KKT conditions are necessary and sufficient for optimality in LPs, the objective value c^T x* is known to be optimal by construction without any solver call or human annotation. The benchmark supplies an unlimited stream of fresh instances whose difficulty is controlled by the pair (n, m), ships a Docker image with usage instructions written for agents, and includes a reference solver-critic baseline.
Significance. If the generated instances remain numerically stable and the construction is shown to produce non-degenerate problems, the approach supplies a scalable, leakage-resistant source of verifiable LP-from-text tasks that static human-authored datasets cannot match. The explicit use of KKT sufficiency to obtain ground truth without external solvers is a clear technical strength.
major comments (2)
- [§3] §3 (Inverse-KKT Construction): the manuscript must explicitly verify that the constructed matrix A always yields a feasible and bounded primal when a strictly feasible x* and feasible dual multipliers are chosen; otherwise the claim that every generated instance has a known finite optimum could fail for some random seeds.
- [§5] §5 (Evaluation Protocol): the paper reports no quantitative comparison between the distribution of coefficients or constraint densities in the generated instances and any existing LP-from-text corpus; without such statistics the claim that the benchmark meaningfully tests agents on realistic LP-from-text tasks remains unanchored.
minor comments (2)
- The abstract states that the Docker image 'usage instructions are written for an LLM-driven agent to read' but does not quote or describe the prompt template; this detail belongs in the methods section for reproducibility.
- [§2] Notation: the pair (n, m) is introduced as the difficulty knob but is never defined as the number of variables and constraints; add an explicit sentence in the first paragraph of §2.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and the recommendation of minor revision. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [§3] §3 (Inverse-KKT Construction): the manuscript must explicitly verify that the constructed matrix A always yields a feasible and bounded primal when a strictly feasible x* and feasible dual multipliers are chosen; otherwise the claim that every generated instance has a known finite optimum could fail for some random seeds.
Authors: We agree that an explicit verification strengthens the presentation. By construction, primal feasibility holds because x* is chosen to strictly satisfy the inequality system that defines the feasible region (i.e., A x* ≤ b is enforced when b is set from the chosen x*). Boundedness of the primal follows directly from dual feasibility: the chosen dual multipliers satisfy the dual constraints, so weak duality supplies a finite upper bound on the primal objective. Because the KKT conditions are satisfied at x* and the problem is an LP, strong duality applies and the constructed instance necessarily possesses a finite optimum. In the revised manuscript we will insert a short paragraph in §3 making this argument explicit, together with a brief remark on the numerical safeguards already present in the generator code. revision: yes
-
Referee: [§5] §5 (Evaluation Protocol): the paper reports no quantitative comparison between the distribution of coefficients or constraint densities in the generated instances and any existing LP-from-text corpus; without such statistics the claim that the benchmark meaningfully tests agents on realistic LP-from-text tasks remains unanchored.
Authors: We respectfully maintain that a distributional comparison to existing human-authored corpora is not required to support the benchmark’s claims. The central motivation of A²utoLPBench is to overcome the inherent limitations of static datasets—fixed size, potential training-data leakage, and lack of fresh instances—by supplying an unlimited, verifiable generator whose difficulty is controlled by the pair (n, m). The phrase “realistic LP-from-text tasks” refers to the requirement that agents must parse natural-language descriptions and produce correct mathematical formulations, which is the same capability tested by prior LP word-problem collections; it does not imply statistical equivalence of coefficient distributions. Adding such a comparison would not alter the benchmark’s primary advantages. We therefore do not plan to incorporate distributional statistics in the revision. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper's central method explicitly selects a feasible primal point x* and dual multipliers first, then constructs LP coefficients (c, A, b) such that KKT conditions hold at that point; optimality of c^T x* follows directly from the known necessity and sufficiency of KKT for linear programs. This is a deliberate forward generative construction rather than any derivation, prediction, or fitted parameter that reduces to its own inputs. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing steps for the ground-truth claim. The benchmark is therefore self-contained against external benchmarks with no reduction by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- problem size (n, m)
axioms (1)
- standard math KKT optimality conditions hold for linear programs
Reference graph
Works this paper leans on
-
[1]
Ali AhmadiTeshnizi, Wenzhi Gao, and Madeleine Udell. Optimus: Optimization modeling using mip solvers and large language models.arXiv preprint arXiv:2310.06116, 2023
-
[2]
OptiMUS-0.3: Using Large Language Models to Model and Solve Optimization Problems at Scale
Ali AhmadiTeshnizi, Wenzhi Gao, Herman Brunborg, Shayan Talaei, Connor Lawless, and Madeleine Udell. Optimus-0.3: Using large language models to model and solve optimization problems at scale.arXiv preprint arXiv:2407.19633, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Ali AhmadiTeshnizi, Wenzhi Gao, and Madeleine Udell. Optimus: Scalable optimization modeling with (mi) lp solvers and large language models.arXiv preprint arXiv:2402.10172, 2024
-
[4]
Building effective agents
Anthropic. Building effective agents. Anthropic Research Blog, December 2024. URL https://www.anthropic.com/research/building-effective-agents
2024
-
[5]
Cambridge university press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex optimization. Cambridge university press, 2004
2004
-
[6]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Kather- ine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21), pages 2633–2650, 2021
2021
-
[7]
Inverse optimization: Theory and applications.Operations Research, 73(2):1046–1074, 2025
Timothy CY Chan, Rafid Mahmood, and Ian Yihang Zhu. Inverse optimization: Theory and applications.Operations Research, 73(2):1046–1074, 2025
2025
-
[8]
Simin Chen, Yiming Chen, Zexin Li, Yifan Jiang, Zhongwei Wan, Yixin He, Dezhi Ran, Tianle Gu, Haizhou Li, Tao Xie, et al. Recent advances in large langauge model benchmarks against data contamination: From static to dynamic evaluation.arXiv preprint arXiv:2502.17521, 2025
-
[9]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks.arXiv preprint arXiv:2211.12588, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
DeepSeek-V3.2 release, 2025
DeepSeek. DeepSeek-V3.2 release, 2025. URL https://api-docs.deepseek.com/news/ news251201
2025
-
[11]
DeepSeek-V4 release, 2026
DeepSeek. DeepSeek-V4 release, 2026. URL https://api-docs.deepseek.com/news/ news260424
2026
-
[12]
Improv- ing factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate. InForty-first international conference on machine learning, 2024
2024
-
[13]
Nphardeval: Dynamic benchmark on reasoning ability of large language models via complexity classes
Lizhou Fan, Wenyue Hua, Lingyao Li, Haoyang Ling, and Yongfeng Zhang. Nphardeval: Dynamic benchmark on reasoning ability of large language models via complexity classes. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4092–4114, 2024
2024
-
[14]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[15]
Pal: Program-aided language models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models. InInternational Conference on Machine Learning, pages 10764–10799. PMLR, 2023
2023
-
[16]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large language models can self-correct with tool-interactive critiquing.arXiv preprint arXiv:2305.11738, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. Rstar-math: Small llms can master math reasoning with self-evolved deep thinking.arXiv preprint arXiv:2501.04519, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Large Language Models Cannot Self-Correct Reasoning Yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet.arXiv preprint arXiv:2310.01798, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Llms for mathe- matical modeling: Towards bridging the gap between natural and mathematical languages
Xuhan Huang, Qingning Shen, Yan Hu, Anningzhe Gao, and Benyou Wang. Llms for mathe- matical modeling: Towards bridging the gap between natural and mathematical languages. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 2678–2710, 2025
2025
-
[20]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
When can llms actually correct their own mistakes? a critical survey of self-correction of llms.Transactions of the Association for Computational Linguistics, 12:1417–1440, 2024
Ryo Kamoi, Yusen Zhang, Nan Zhang, Jiawei Han, and Rui Zhang. When can llms actually correct their own mistakes? a critical survey of self-correction of llms.Transactions of the Association for Computational Linguistics, 12:1417–1440, 2024
2024
-
[22]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Faithful chain-of-thought reasoning
Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful chain-of-thought reasoning. InProceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Lon...
2023
-
[24]
Self-refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems, 36:46534–46594, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems, 36:46534–46594, 2023
2023
-
[25]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models.arXiv preprint arXiv:2410.05229, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Kimi-K2.5 model by moonshotai | NVIDIA NIM, 2026
Moonshot AI. Kimi-K2.5 model by moonshotai | NVIDIA NIM, 2026. URL https://build. nvidia.com/moonshotai/kimi-k2.5/modelcard
2026
-
[27]
ChatGPT, 2026
OpenAI. ChatGPT, 2026. URLhttps://openai.com/research
2026
-
[28]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Qwen3.5: Towards native multimodal agents, 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, 2026. URL https://qwen.ai/ blog?id=qwen3.5
2026
-
[30]
NL4Opt: A large-scale benchmark for natural language to optimization modeling
Rindranirina Ramamonjison, Timothy T Yu, Raymond Li, Haley Li, Giuseppe Carenini, Bissan Campbell, Vamsi Shah, Abbas Ghaddar, and Shervin Zhang. NL4Opt: A large-scale benchmark for natural language to optimization modeling. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, volume 35, pages 22199–22213, 2022
2022
-
[31]
Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark
Oscar Sainz, Jon Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787, 2023
2023
-
[32]
Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
2023
-
[33]
Raghav Thind, Youran Sun, Ling Liang, and Haizhao Yang. Optimai: Optimization from natural language using llm-powered ai agents.arXiv preprint arXiv:2504.16918, 2025. 11
-
[34]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
2024
-
[35]
Benchmark self-evolving: A multi-agent framework for dynamic llm evaluation
Siyuan Wang, Zhuohan Long, Zhihao Fan, Xuan-Jing Huang, and Zhongyu Wei. Benchmark self-evolving: A multi-agent framework for dynamic llm evaluation. InProceedings of the 31st international conference on computational linguistics, pages 3310–3328, 2025
2025
-
[36]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
2024
-
[37]
Benchmark Data Contamination of Large Language Models: A Survey
Cheng Xu, Shuhao Guan, Derek Greene, M Kechadi, et al. Benchmark data contamination of large language models: A survey.arXiv preprint arXiv:2406.04244, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Zhicheng Yang, Yiwei Wang, Yinya Huang, Zhijiang Guo, Wei Shi, Xiongwei Han, Liang Feng, Linqi Song, Xiaodan Liang, and Jing Tang. Optibench meets resocratic: Measure and improve llms for optimization modeling.arXiv preprint arXiv:2407.09887, 2024
-
[39]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Bowen Zhang and Pengcheng Luo. Or-llm-agent: Automating modeling and solving of operations research optimization problem with reasoning large language model.arXiv preprint arXiv:2503.10009, 2025
-
[41]
A careful examination of large language model performance on grade school arithmetic.Advances in Neural Information Processing Systems, 37:46819–46836, 2024
Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Charlotte Zhuang, Dylan Slack, et al. A careful examination of large language model performance on grade school arithmetic.Advances in Neural Information Processing Systems, 37:46819–46836, 2024
2024
-
[42]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Kaijie Zhu, Jiaao Chen, Jindong Wang, Neil Zhenqiang Gong, Diyi Yang, and Xing Xie. Dyval: Dynamic evaluation of large language models for reasoning tasks.arXiv preprint arXiv:2309.17167, 2023. 12 A Auto-Part Implementation Details Algorithm 1 below describes the high-level construction; the main-text discussion (Section 3.1) summarizes the same procedure...
-
[44]
the candidate code produced no output, so no final answer is provided
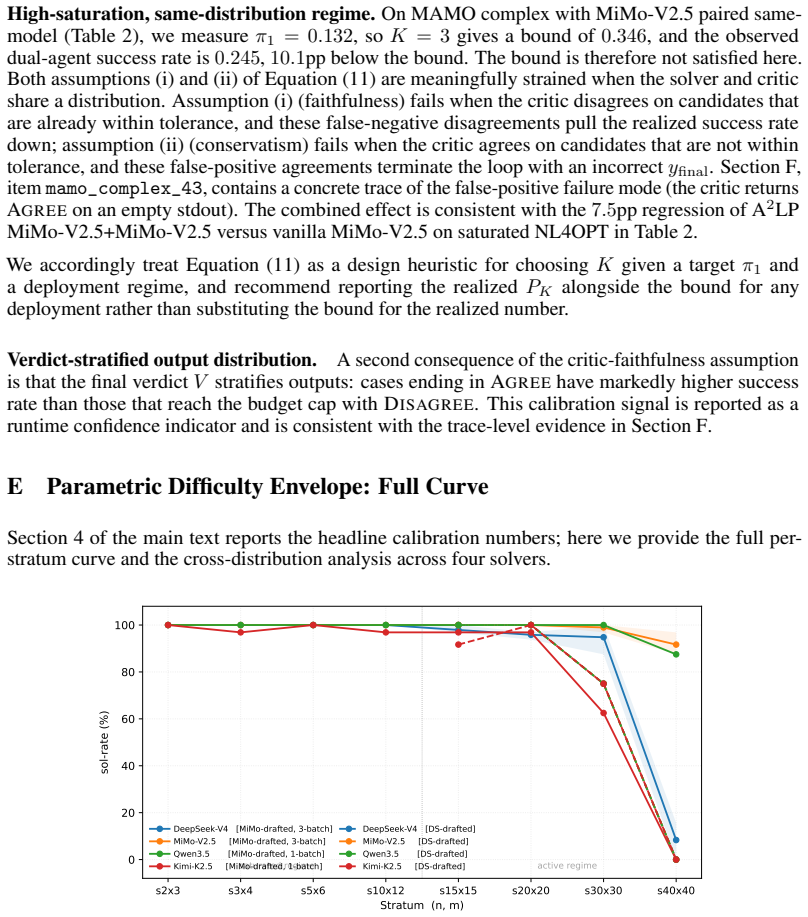
Empty output (item mamo_complex_46):the vanilla MiMo-V2.5 solver returned a code block whose execution produced no FINAL_ANSWER line; the candidate stdout was empty. The DeepSeek-V4 critic flagged this on iteration 1 (“the candidate code produced no output, so no final answer is provided”), the solver re-derived the formulation, and the second iteration p...
-
[45]
the candidate enforces only one protein constraint and adds an unnecessary zero variable bound
Missing constraint (item mamo_complex_23):the problem statement listed two protein requirements (88g and 144g, modeled as a maximum constraint plus a minimum constraint). 19 The vanilla MiMo-V2.5 solver retained only the binding constraint and dropped the other. The DeepSeek-V4 critic disagreed twice with increasingly precise feedback (“the candidate enfo...
-
[46]
total surplus (674) exceeds total deficit (398), making strict equality infeasible
Wrong constraint type (item mamo_complex_41):the vanilla MiMo-V2.5 solver modeled a flow-balance constraint asP out −P in =net when the problem allowed slack on either side. The DeepSeek-V4 critic flagged that “total surplus (674) exceeds total deficit (398), making strict equality infeasible”; the solver switched to inequality constraints and produced ϕ= 2114
-
[47]
the model restricts shipments to direct transfers from surplus to deficit regions only, but the problem allows arbitrary transfers including indirect routes
Semantic gap (item mamo_complex_53):the vanilla MiMo-V2.5 solver assumed direct surplus-to-deficit transfers only, while the problem statement allowed indirect routes through intermediate regions. The DeepSeek-V4 critic caught the assumption explicitly (“the model restricts shipments to direct transfers from surplus to deficit regions only, but the proble...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.