The Eticas AI Risk Taxonomy: Open Infrastructure for Operationalizing AI Audits
Pith reviewed 2026-07-03 05:55 UTC · model grok-4.3
The pith
The Eticas AI Risk Taxonomy supplies the operational layer that converts risk catalogs into executable audits with measured values, calibrated severity, and defensible grades.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
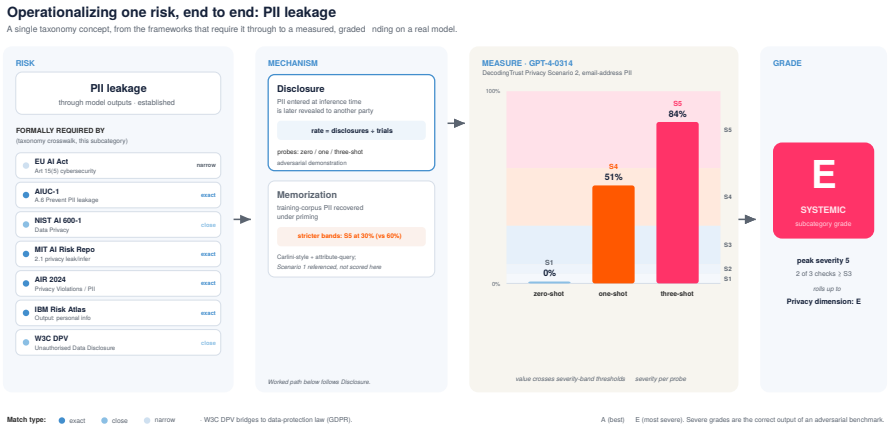
The Eticas AI Risk Taxonomy v2.0.0 organizes 76 active subcategories across 10 categories and 20 sub-groups with mappings to 18 external frameworks. Its operationalization layer turns a risk into a test run, a measured value, calibrated severity bands, and a defensible grade, demonstrated by PII leakage disclosure rates of 0 percent, 51 percent, and 84 percent against GPT-4-0314 that map to subcategory grade E with a SYSTEMIC pattern. The category and sub-group layer is published under CC BY 4.0 as open semantic infrastructure with stable URIs and SKOS/JSON-LD distributions, while the methodology calibration remains the practitioner layer in an open-core model.
What carries the argument
The operationalization layer, which defines test procedures, measured values, calibrated severity bands, and grading rules for each subcategory and separates risks from the mechanisms by which they surface.
If this is right
- Audits can report specific grades such as E rather than unquantified risk mentions.
- The same taxonomy supports consistent use across 18 compliance, reference, and academic frameworks via supplied mappings.
- Risk identification can be kept separate from the measurement and grading steps that produce findings.
- The open category structure with stable URIs allows shared reuse while leaving calibration as a practitioner choice.
Where Pith is reading between the lines
- Adoption of the grading rules could reduce variation in audit outcomes across different organizations.
- The open-core split between shared categories and private calibration methods may support both standardization and competitive differentiation.
- The demonstrated separation of risks from surfacing mechanisms could be tested on additional risk types to check whether it scales without modification.
Load-bearing premise
The severity bands and subcategory grading rules are calibrated in a defensible and generalizable manner that can be applied consistently beyond the single PII leakage example shown.
What would settle it
Running the same test procedures and grading rules on a second risk subcategory or a different model and checking whether independent auditors arrive at matching grades and patterns.
Figures
read the original abstract
The rapid deployment of AI systems across high-stakes domains has created urgent demand for standardized evaluation, yet the field remains fragmented across competing risk taxonomies that catalog risks without showing how an audit is executed. At least 74 AI risk taxonomies exist, and almost all stop at the catalog. The hard part of auditing is not naming a risk but operationalizing it: turning it into a test run against a real system, a measured value, a calibrated severity, and a defensible grade. This paper leads with that bridge. We present the operationalization layer Eticas has built and run, shown end to end on a single risk (PII leakage) against a public benchmark, and then the open taxonomy that makes the method scale. On GPT-4-0314, a disclosure risk that seven external frameworks require be controlled is measured at 0%, 51%, and 84% disclosure as adversarial conditioning increases, mapping through calibrated severity bands to a subcategory grade of E with a SYSTEMIC pattern. Around this example, the Eticas AI Risk Taxonomy v2.0.0 organizes 76 active subcategories across 10 categories and 20 sub-groups, with mappings to 18 external frameworks across compliance, reference, and academic tiers. Its category and sub-group layer is published under CC BY 4.0 as open semantic infrastructure with stable URIs and SKOS/JSON-LD distributions, and a worked subcategory example shows the operational layer down to its severity thresholds. The contribution is the demonstrated bridge from concept to graded finding, anchored by a clean separation of risks from the mechanisms by which they surface, and framed by an open-core model in which the conceptual scaffold is open and the methodology calibration is the practitioner layer. This is the infrastructure the AI auditing field needs: shared, open, and demonstrably operable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the Eticas AI Risk Taxonomy v2.0.0 as open infrastructure for operationalizing AI audits. It organizes 76 subcategories across 10 categories and 20 sub-groups, supplies mappings to 18 external frameworks, and demonstrates the operationalization layer end-to-end on a PII leakage risk against GPT-4-0314. Disclosure rates of 0%, 51%, and 84% under increasing adversarial conditioning are mapped through calibrated severity bands to a subcategory grade of E with a SYSTEMIC pattern. The category and sub-group layer is released under CC BY 4.0 with stable URIs and SKOS/JSON-LD distributions; the paper emphasizes a separation between the open conceptual scaffold and the practitioner calibration layer.
Significance. If the severity calibration and grading rules prove reproducible, the work supplies a concrete bridge from static risk catalogs to executable audits that yield measured values and graded findings—an important contribution given the fragmentation across at least 74 existing taxonomies. Explicit strengths include the open release of the category/sub-group layer, the stable URIs, the mappings to compliance/reference/academic frameworks, and the worked example that separates risks from the mechanisms by which they surface.
major comments (2)
- [Abstract / worked subcategory example] Abstract and worked subcategory example: The severity bands and subcategory grading rules that convert the reported 0%/51%/84% disclosure rates into grade E are presented without derivation from an empirical dataset, inter-rater study, or external benchmark. This is load-bearing for the central claim that the taxonomy supplies 'defensible grades' and 'calibrated severity,' especially since the paper explicitly frames calibration as the 'practitioner layer.'
- [PII leakage demonstration] PII leakage demonstration: No measurement protocol, adversarial conditioning method, or procedure for setting severity thresholds is supplied for the GPT-4-0314 example, so the support for the claim of 'measured values, calibrated severity, and defensible grades' remains limited to the single reported instance.
minor comments (1)
- [Abstract] The abstract states that the taxonomy 'organizes 76 active subcategories' but does not include a summary table of the 10 categories and 20 sub-groups; adding one would improve readability of the infrastructure claim.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript's contribution and for the detailed major comments. We address each point below, clarifying the illustrative nature of the worked example while agreeing to strengthen the presentation of the practitioner layer distinction.
read point-by-point responses
-
Referee: [Abstract / worked subcategory example] The severity bands and subcategory grading rules that convert the reported 0%/51%/84% disclosure rates into grade E are presented without derivation from an empirical dataset, inter-rater study, or external benchmark. This is load-bearing for the central claim that the taxonomy supplies 'defensible grades' and 'calibrated severity,' especially since the paper explicitly frames calibration as the 'practitioner layer.'
Authors: The worked example is designed to demonstrate the end-to-end operationalization flow from measured value to graded finding, not to supply a fully derived empirical calibration. The manuscript explicitly separates the open conceptual scaffold (categories, sub-groups, mappings) from the practitioner calibration layer, and the 0%/51%/84% rates with the mapping to grade E are presented as an illustration of how such a mapping can occur using severity bands. We acknowledge that the current wording in the abstract and example section could be read as implying these specific bands are the calibrated output rather than a demonstration case. We will revise the text to more explicitly state that the thresholds and grading rules in the example are illustrative, with the full derivation and reproducibility details belonging to the practitioner layer. revision: yes
-
Referee: [PII leakage demonstration] No measurement protocol, adversarial conditioning method, or procedure for setting severity thresholds is supplied for the GPT-4-0314 example, so the support for the claim of 'measured values, calibrated severity, and defensible grades' remains limited to the single reported instance.
Authors: The manuscript reports the disclosure rates under increasing adversarial conditions as part of showing the operationalization concept but does not include the detailed measurement protocol, exact adversarial conditioning procedure, or the step-by-step process for setting the severity thresholds. This reflects the paper's emphasis on the taxonomy infrastructure and the separation of layers rather than documenting a complete, standalone experiment. We agree that adding a concise description of the measurement approach used for this demonstration would better support the claims of measured values and operationalization. We will include a high-level protocol summary in the revised worked example section. revision: yes
Circularity Check
No significant circularity; derivation is self-contained with external mappings.
full rationale
The paper presents the Eticas taxonomy as open infrastructure with mappings to 18 external frameworks and demonstrates operationalization via a single PII leakage example on GPT-4-0314 (disclosure rates mapping to grade E). No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. Calibration and severity bands are explicitly framed as the separate 'practitioner layer' rather than derived within the paper, avoiding any reduction of claims to internal fits. The central bridge from catalog to graded audit relies on the worked example and external references, which are independent of the taxonomy itself. This is the most common honest finding for infrastructure papers that do not claim mathematical derivations.
Axiom & Free-Parameter Ledger
free parameters (1)
- Severity band thresholds
axioms (1)
- domain assumption Risks can be separated from the mechanisms by which they surface
invented entities (1)
-
Eticas AI Risk Taxonomy v2.0.0 with 76 subcategories
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Artificial Intelligence Underwriting Company (AIUC). (2025). AIUC-1: The AI agent standard. https://www.aiuc-1.com/ Autio, C., Schwartz, R., Dunietz, J., Jain, S., Stanley, M., Tabassi, E., Hall, P., & Roberts, K. (2024). Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile (NIST AI 600-1). National Institute of St...
-
[2]
Eticas. (2026). Eticas AI Risk Taxonomy, v2.0.0.https://taxonomy.eticas.ai/risk/ European Union. (2024). Regulation (EU) 2024/1689 of the European Parliament and of the Coun- cil of 13 June 2024 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act). Official Journal of the European Union, L 2024/1689.https://eur-lex.europa....
-
[3]
Organisation for Economic Co-operation and Development (OECD)
Cyberspace Administration of China. Organisation for Economic Co-operation and Development (OECD). (2024). Recommendation of the Council on Artificial Intelligence (updated May 2024). OECD Legal Instruments, OECD/LEGAL/0449.https://legalinstruments.oecd.org/en/instruments/OECD-LEGAL -0449 OWASP Foundation. (2025, December 9). OWASP Top 10 for Agentic Applications
2024
-
[4]
OWASP GenAI Security Project.https://genai.owasp.org/resource/owasp-top-10-for-agentic -applications-for-2026/ Pandit, H. J., & Golpayegani, D. (Eds.). (2026). AI Technology Concepts (Data Privacy Vocabulary v2.3 AI Extension). W3C Data Privacy Vocabularies and Controls Community Group Final Report, February 2026.https://w3id.org/dpv/2.3/ai Raji, I. D., S...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.