Learning Spectral and Polarimetric Clues for One-to-Multimodal Novel View Synthesis
Pith reviewed 2026-07-03 15:18 UTC · model grok-4.3
The pith
Pre-training on multimodal scenes enables RGB-only fine-tuning to render infrared, polarimetric, and multispectral views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
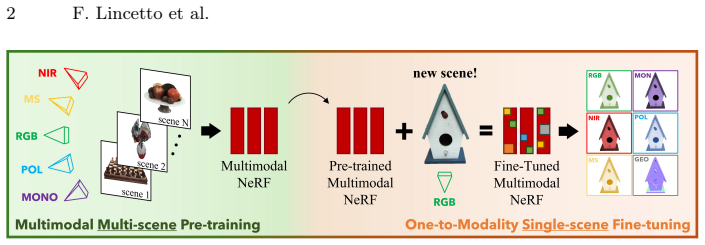
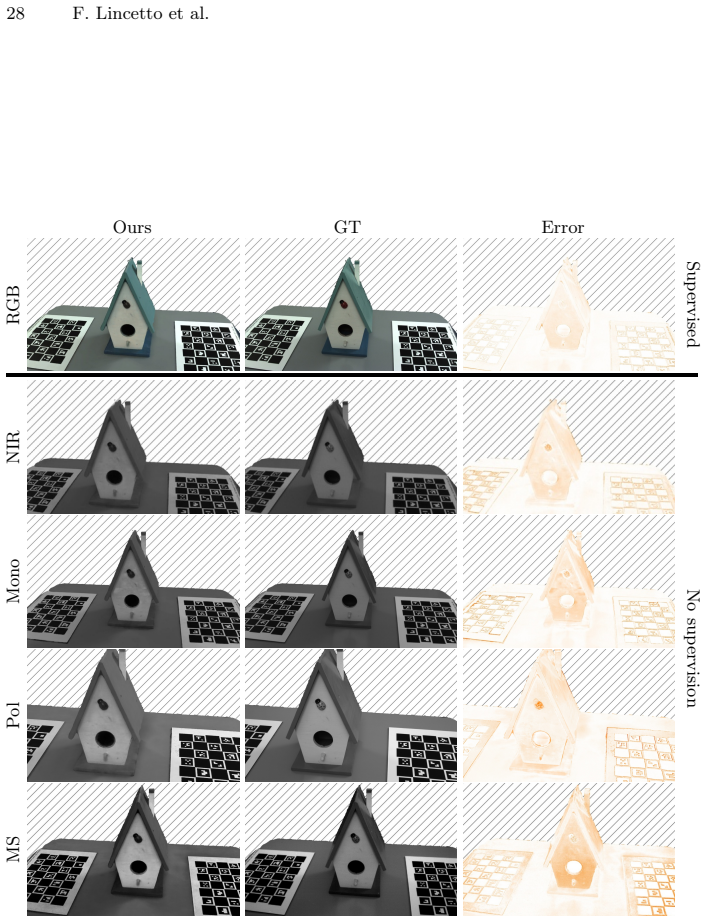
SPoILeR performs a multimodal pre-training phase in which the model learns the mutual correlation between different modalities. This correlation knowledge then supports accurate prediction of unconventional modalities during fine-tuning that is supervised solely by RGB images, yielding multi-view consistent renderings of infrared, polarimetric, and multispectral frames even when no samples from those sensors are available for the scene.
What carries the argument
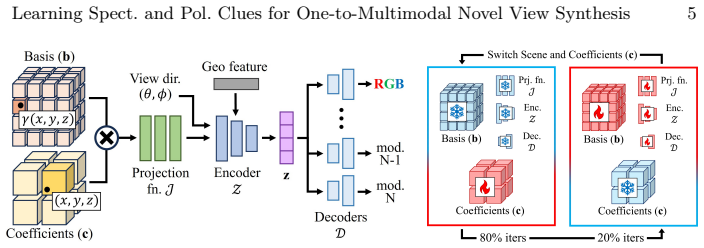
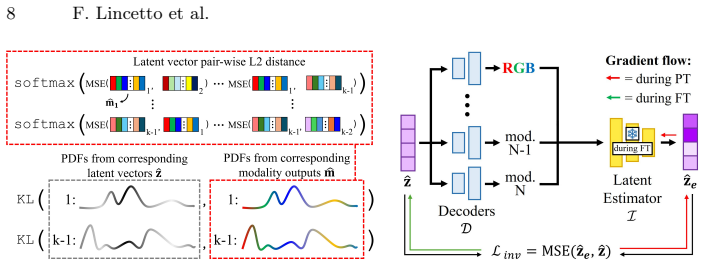
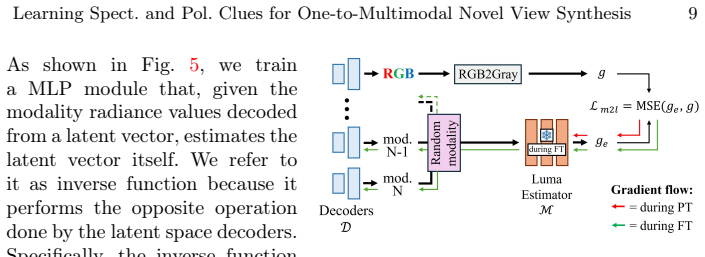
The Spectral and Polarimetric Implicit Learned Representation (SPoILeR), which encodes learned correlations across imaging modalities to enable transfer from pre-training to RGB-supervised fine-tuning.
If this is right
- The approach produces accurate renderings of infrared, polarimetric, and multispectral data without any input samples from those sensors.
- Renderings remain multi-view consistent across the new scene.
- Fine-tuning requires supervision from RGB frames only.
Where Pith is reading between the lines
- If modality correlations prove stable across scenes, the method could be applied to additional imaging types such as thermal or depth data.
- Applications in fields that use multiple sensors might reduce their dependence on full multimodal capture setups.
Load-bearing premise
Correlations between modalities discovered during pre-training on some scenes will transfer reliably to new scenes that provide only RGB supervision.
What would settle it
Acquire real infrared or polarimetric images of a previously unseen scene and measure whether the model's RGB-only renderings match those ground-truth captures within expected error bounds; systematic mismatch would falsify the transfer claim.
Figures
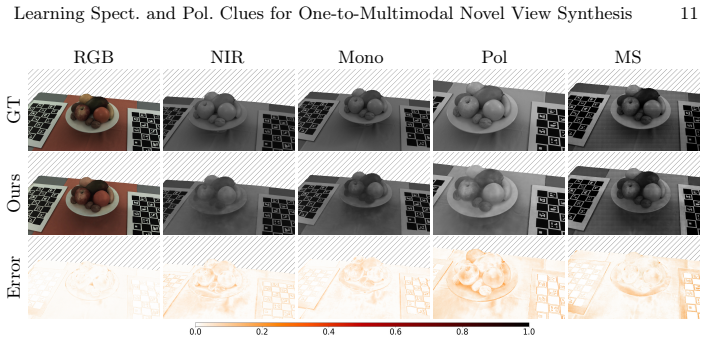
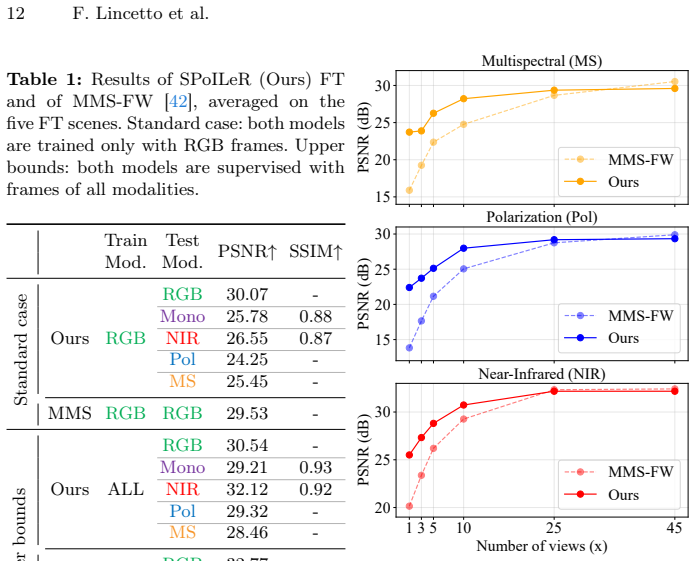
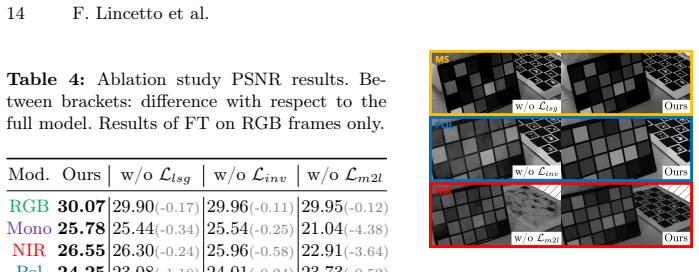
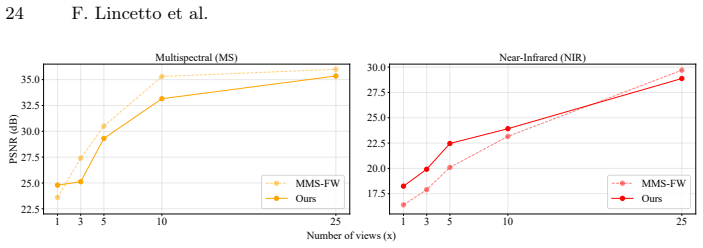


















read the original abstract
Neural rendering techniques allow for accurate reconstruction of the geometry and color appearance of 3D scenes. Some methods have extended their use to additional imaging modalities, such as multispectral, infrared, or polarimetric data. However, all of these approaches require expensive sensors and calibrated setups to capture new multimodal frames for each new scene. We propose Spectral and Polarimetric Implicit Learned Representation (SPoILeR), a novel method to obtain multi-view consistent renderings of unconventional modalities for scenes where either only RGB frames or very few of the additional modalities are available. Thanks to a multimodal pre-training phase, the model learns the mutual correlation between different modalities. This step allows predicting accurate renderings of unconventional modalities during a fine-tuning phase supervised only by RGB images. Experimental results show that the approach can accurately render infrared, polarimetric, and multispectral frames for scenes where no input sample captured by these types of sensors is provided.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPoILeR, a neural implicit representation method for one-to-multimodal novel view synthesis. It performs multimodal pre-training across RGB, infrared, polarimetric, and multispectral data to learn cross-modal correlations, followed by fine-tuning on RGB-only supervision for new scenes. This enables rendering of the unconventional modalities without any target-modality input samples for those scenes. The central claim is that the pre-trained correlations transfer sufficiently to produce accurate multi-view consistent renderings of IR, polarimetric, and multispectral frames.
Significance. If the transfer of pre-trained modality correlations holds for novel scenes, the approach would meaningfully lower the barrier to multimodal 3D reconstruction by eliminating the need for expensive calibrated sensors on every target scene. The paper reports experimental results demonstrating accurate renderings under RGB-only fine-tuning, which would be a practical advance if the generalization is robust.
major comments (1)
- [Abstract and Experimental Results section] The load-bearing assumption that cross-modal correlations learned during pre-training are sufficiently scene-independent to enable accurate rendering of non-RGB modalities with zero multimodal supervision on entirely new scenes is not adequately secured by the reported experiments. The abstract and described pipeline provide no evidence (e.g., cross-dataset testing or ablation on material/illumination variation) that the pre-training distribution covers the statistics of the test scenes.
minor comments (1)
- [Abstract] The abstract supplies no quantitative metrics, error analysis, or baseline comparisons, making it difficult to assess the strength of the reported results.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the opportunity to clarify the generalization properties of SPoILeR. Below we address the major comment point by point.
read point-by-point responses
-
Referee: [Abstract and Experimental Results section] The load-bearing assumption that cross-modal correlations learned during pre-training are sufficiently scene-independent to enable accurate rendering of non-RGB modalities with zero multimodal supervision on entirely new scenes is not adequately secured by the reported experiments. The abstract and described pipeline provide no evidence (e.g., cross-dataset testing or ablation on material/illumination variation) that the pre-training distribution covers the statistics of the test scenes.
Authors: We respectfully disagree that the reported experiments fail to secure the central assumption. The pre-training corpus comprises multiple distinct scenes spanning varied materials, surface properties, and illumination conditions across all four modalities. Fine-tuning and quantitative evaluation are performed exclusively on held-out scenes that were never observed during pre-training; these test scenes were captured under different viewpoints, lighting, and material configurations from the pre-training set. The consistent accuracy of the rendered IR, polarimetric, and multispectral outputs on these unseen scenes constitutes direct empirical evidence that the learned cross-modal correlations transfer beyond the exact training scenes. While we do not conduct an explicit cross-dataset evaluation (owing to the scarcity of publicly available calibrated multimodal 3D datasets), the intra-dataset scene diversity and the zero-shot transfer results already address the core concern of scene independence. We are prepared to expand the experimental section with additional qualitative examples highlighting material and illumination variation if the editor deems it necessary. revision: no
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents a standard two-stage neural rendering pipeline: multimodal pre-training to capture cross-modal correlations, followed by RGB-supervised fine-tuning on novel scenes. No equations, parameter-fitting steps, or self-citations are described that would make any claimed prediction equivalent to its inputs by construction. The transfer of learned correlations to unseen scenes is an empirical claim resting on the pre-training distribution, not a definitional or fitted tautology. The method is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal correlations learned on pre-training scenes generalize to new scenes without any multimodal input
invented entities (1)
-
SPoILeR model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Arad, B., Timofte, R., Yahel, R., Morag, N., Bernat, A., Cai, Y., Lin, J., Lin, Z., Wang, H., Zhang, Y., et al.: Ntire 2022 spectral recovery challenge and data set. In: IEEE Conference on Computer Vision and Pattern Recognition Workshop. pp. 862–880. IEEE (2022).https://doi.org/10.1109/CVPRW56347.2022.001024
-
[3]
In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Bachmann, R., Kar, O.F., Mizrahi, D., Garjani, A., Gao, M., Griffiths, D., Hu, J., Dehghan, A., Zamir, A.: 4m-21: An any-to-any vision model for tens of tasks and modalities. In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (eds.) Advances in Neural Information Processing Systems. vol. 37, pp. 61872–61911. Curran As...
2024
-
[4]
In: European Conference on Computer Vision
Bachmann, R., Mizrahi, D., Atanov, A., Zamir, A.: Multimae: Multi-modal multi- task masked autoencoders. In: European Conference on Computer Vision. pp. 348–
-
[5]
Springer (2022).https://doi.org/10.1007/978-3-031-19836-6_203
-
[6]
Swin transformer: Hierarchical vision transformer using shifted windows,
Boss, M., Braun, R., Jampani, V., Barron, J.T., Liu, C., Lensch, H.: Nerd: Neu- ral reflectance decomposition from image collections. In: International Confer- ence on Computer Vision. pp. 12684–12694 (2021).https://doi.org/10.1109/ ICCV48922.2021.012451
-
[7]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Cai,Y.,Lin,J.,Lin,Z.,Wang,H.,Zhang,Y.,Pfister,H.,Timofte,R.,VanGool,L.: Mst++: Multi-stage spectral-wise transformer for efficient spectral reconstruction. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 745–755 (2022).https://doi.org/10.1109/CVPRW56347.2022.000902, 3, 4, 10, 13, 23
-
[8]
In: European Conference on Computer Vision (2026) 8
Camuffo, E., Barbato, F., Ozay, M., Milani, S., Michieli, U.: Mocha: Multi-modal objects-aware cross-architecture alignment. In: European Conference on Computer Vision (2026) 8
2026
-
[9]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Charatan,D.,Li,S.L.,Tagliasacchi,A.,Sitzmann,V.:pixelsplat:3dgaussiansplats from image pairs for scalable generalizable 3d reconstruction. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 19457–19467 (2024).https: //doi.org/10.1109/CVPR52733.2024.018404
-
[10]
ACM Transactions on Graphics (2023),https:// doi.org/10.1145/35921354, 5
Chen, A., Xu, Z., Wei, X., Tang, S., Su, H., Geiger, A.: Dictionary fields: Learning a neural basis decomposition. ACM Transactions on Graphics (2023),https:// doi.org/10.1145/35921354, 5
-
[11]
In: European Conference on Computer Vision
Chen, Q., Shu, S., Bai, X.: Thermal3d-gs: Physics-induced 3d gaussians for thermal infrared novel-view synthesis. In: European Conference on Computer Vision. pp. 253–269. Springer (2024).https://doi.org/10.1007/978-3-031-73383-3_152
-
[13]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chou, Z.T., Huang, S.Y., Liu, I., Wang, Y.C.F., et al.: Gsnerf: Generalizable se- mantic neural radiance fields with enhanced 3d scene understanding. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 20806–20815 (2024). https://doi.org/10.1109/CVPR52733.2024.019661
-
[15]
In: Color Imaging Conference
Darling, B.A., Ferwerda, J.A., Berns, R.S., Chen, T.: Real-time multispectral ren- dering with complex illumination. In: Color Imaging Conference. vol. 19, pp. 345–
-
[16]
Society of Imaging Science and Technology (2011).https://doi.org/10. 1145/3721250.37430352
-
[17]
In: European Conference on Computer Vision
Dave, A., Zhao, Y., Veeraraghavan, A.: Pandora: Polarization-aided neural decom- position of radiance. In: European Conference on Computer Vision. pp. 538–556. Springer (2022).https://doi.org/10.1007/978-3-031-20071-7_322
-
[18]
In: International Con- ference on Learning Representations (2021) 4
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. In: International Con- ference on Learning Representations (2021) 4
2021
-
[19]
In: IEEE Symposium on Volume Visualization and Graphics
Gibson, S.F.: Using distance maps for accurate surface representation in sampled volumes. In: IEEE Symposium on Volume Visualization and Graphics. pp. 23–30 (1998) 6
1998
-
[20]
In: International Conference on Learning Representa- tions (2026),https://openreview.net/forum?id=BR2ItBcqOo3
Griffiths, R., Dansereau, D.G.: RoRE: Rotary ray embedding for generalised multi- modal scene understanding. In: International Conference on Learning Representa- tions (2026),https://openreview.net/forum?id=BR2ItBcqOo3
2026
-
[21]
Gropp, A., Yariv, L., Haim, N., Atzmon, M., Lipman, Y.: Implicit geometric reg- ularization for learning shapes. In: International Conference on Machine Learning (2020),https://dl.acm.org/doi/abs/10.5555/3524938.35252936
-
[22]
Scientific Reports12(1), 17288 (2022).https://doi
Großmann, W., Horn, H., Niggemann, O.: Improving remote material classification ability with thermal imagery. Scientific Reports12(1), 17288 (2022).https://doi. org/10.1038/s41598-022-21588-42
-
[23]
In: AAAI Conference on Artificial Intelligence
Guo, H., Liu, H., Wen, J., Li, J.: Cross-spectral gaussian splatting with spatial occupancy consistency. In: AAAI Conference on Artificial Intelligence. vol. 39, pp. 3229–3237 (2025).https://doi.org/10.1609/aaai.v39i3.323332, 3
-
[24]
In: International Conference on Computer Vision
Han, Y., Tie, B., Guo, H., Lyu, Y., Li, S., Shi, B., Jia, Y., Ma, Z.: Polgs: Polari- metric gaussian splatting for fast reflective surface reconstruction. In: International Conference on Computer Vision. pp. 28073–28082 (2025) 2
2025
-
[25]
Optics Express19(10), 9315–9329 (2011).https://doi.org/10.1364/OE
Hashimoto, N., Murakami, Y., Bautista, P.A., Yamaguchi, M., Obi, T., Ohyama, N., Uto, K., Kosugi, Y.: Multispectral image enhancement for effective visualiza- tion. Optics Express19(10), 9315–9329 (2011).https://doi.org/10.1364/OE. 19.0093152
work page doi:10.1364/oe 2011
-
[26]
Hassan, M., Forest, F., Fink, O., Mielle, M.: Thermonerf: A multimodal neural radiance field for joint rgb-thermal novel view synthesis of building facades. Ad- vanced Engineering Informatics65, 103345 (2025).https://doi.org/10.1016/j. aei.2025.1033452
work page doi:10.1016/j 2025
-
[27]
Computer Graphics Forum42(2023).https://doi.org/10.1111/cgf.149404
He, H., Liang, Y., Xiao, S., Chen, J., Chen, Y.: Cp-nerf: Conditionally parameter- ized neural radiance fields for cross-scene novel view synthesis. Computer Graphics Forum42(2023).https://doi.org/10.1111/cgf.149404
-
[28]
In: ACM International Conference on Computer Graphics and Interactive Techniques
Huang, B., Yu, Z., Chen, A., Geiger, A., Gao, S.: 2d gaussian splatting for geomet- rically accurate radiance fields. In: ACM International Conference on Computer Graphics and Interactive Techniques. pp. 1–11 (2024).https://doi.org/10.1145/ 3641519.36574281
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Huang, Y.H., He, Y., Yuan, Y.J., Lai, Y.K., Gao, L.: Stylizednerf: Consistent 3d scene stylization as stylized nerf via 2d-3d mutual learning. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 18321–18331 (2022).https: //doi.org/10.1109/CVPR52688.2022.017804 18 F. Lincetto et al
-
[30]
Swin transformer: Hierarchical vision transformer using shifted windows,
Jain, A., Tancik, M., Abbeel, P.: Putting nerf on a diet: Semantically consistent few-shot view synthesis. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 5885–5894 (2021).https://doi.org/10.1109/ICCV48922.2021. 005834
-
[31]
Jin, H., Liu, I., Xu, P., Zhang, X., Han, S., Bi, S., Zhou, X., Xu, Z., Su, H.: Tensoir: Tensorial inverse rendering. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 165–174 (2023).https://doi.org/10.1109/CVPR52729.2023. 000241
-
[32]
ACM Transactions on Graphics42(4), 1–14 (2023).https://doi.org/10.1145/35924331
Kerbl, B., Kopanas, G., Leimkuehler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4), 1–14 (2023).https://doi.org/10.1145/35924331
-
[33]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kerr, J., Kim, C.M., Goldberg, K., Kanazawa, A., Tancik, M.: Lerf: Language embedded radiance fields. In: International Conference on Computer Vision. pp. 19729–19739 (2023).https://doi.org/10.1109/ICCV51070.2023.018071
-
[34]
In: ACM International Conference on Computer Graphics and Interactive Techniques - Asia
Kim, Y., Jin, W., Cho, S., Baek, S.H.: Neural spectro-polarimetric fields. In: ACM International Conference on Computer Graphics and Interactive Techniques - Asia. pp. 1–11 (2023).https://doi.org/10.1145/3610548.36181722, 3
-
[35]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
Lei, C., Huang, X., Zhang, M., Yan, Q., Sun, W., Chen, Q.: Polarized reflection removal with perfect alignment in the wild. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 1750–1758 (2020).https://doi.org/10. 1109/CVPR42600.2020.001822
-
[36]
Lei, C., Qi, C., Xie, J., Fan, N., Koltun, V., Chen, Q.: Shape from polarization for complex scenes in the wild. In: IEEE Conference on Computer Vision and Pat- ternRecognition.pp.12632–12641(2022).https://doi.org/10.1109/CVPR52688. 2022.012302
-
[37]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, C., Ono, T., Uemori, T., Mihara, H., Gatto, A., Nagahara, H., Moriuchi, Y.: Neisf: Neural incident stokes field for geometry and material estimation. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 21434–21445 (2024). https://doi.org/10.1109/CVPR52733.2024.020252
-
[39]
In: International Conference on Acoustics, Speech, and Signal Process- ing
Li, J., Li, Y., Sun, C., Wang, C., Xiang, J.: Spec-nerf: Multi-spectral neural radi- ance fields. In: International Conference on Acoustics, Speech, and Signal Process- ing. pp. 2485–2489. IEEE (2024).https://doi.org/10.1109/ICASSP48485.2024. 104460152
-
[40]
In: AAAI Conference on Artificial In- telligence
Li, R., Liu, J., Liu, G., Zhang, S., Zeng, B., Liu, S.: Spectralnerf: Physically based spectral rendering with neural radiance field. In: AAAI Conference on Artificial In- telligence. vol. 38, pp. 3154–3162 (2024).https://doi.org/10.1609/aaai.v38i4. 280992
-
[41]
Li, Z., Müller, T., Evans, A., Taylor, R.H., Unberath, M., Liu, M.Y., Lin, C.H.: Neuralangelo: High-fidelity neural surface reconstruction. In: IEEE Conference on Computer Vision and Pattern Recognition (2023).https://doi.org/10.1109/ CVPR52729.2023.008171, 6, 10
-
[42]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Liang, Z., Zhang, Q., Feng, Y., Shan, Y., Jia, K.: Gs-ir: 3d gaussian splatting for inverse rendering. In: IEEE Conference on Computer Vision and Pattern Recogni- tion. pp. 21644–21653 (2024).https://doi.org/10.1109/CVPR52733.2024.02045 1 Learning Spect. and Pol. Clues for One-to-Multimodal Novel View Synthesis 19
-
[43]
In: British Machine Vision Conference
Lincetto, F., Agresti, G., Rossi, M., Zanuttigh, P.: Exploiting multiple priors for neural 3d indoor reconstruction. In: British Machine Vision Conference. BMVA (2023) 1
2023
-
[44]
In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Lincetto, F., Agresti, G., Rossi, M., Zanuttigh, P.: Multimodalstudio: A heteroge- neous sensor dataset and framework for neural rendering across multiple imaging modalities. In: IEEE Conference on Computer Vision and Pattern Recognition (2025).https://doi.org/10.1109/CVPR52734.2025.010242, 3, 5, 10, 11, 12, 22
-
[45]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Liu, Y., Hu, B., Huang, J., Tai, Y.W., Tang, C.K.: Instance neural radiance field. In: International Conference on Computer Vision. pp. 787–796 (October 2023). https://doi.org/10.1109/ICCV51070.2023.000791
-
[46]
In: International Conference on Learning Repre- sentations (2025) 2
Lu, R., Chen, H., Zhu, Z., Qin, Y., Lu, M., Yan, C., et al.: Thermalgaussian: Thermal 3d gaussian splatting. In: International Conference on Learning Repre- sentations (2025) 2
2025
-
[47]
IEEE Access12, 45331–45341 (2024).https: //doi.org/10.1109/ACCESS.2024.33815312
Ma, R., Ma, T., Guo, D., He, S.: Novel view synthesis and dataset augmentation for hyperspectral data using nerf. IEEE Access12, 45331–45341 (2024).https: //doi.org/10.1109/ACCESS.2024.33815312
-
[48]
In: Advances in Neural Informa- tion Processing Systems (2025) 4
Meng, G., Cai, Z., Chen, R., Tu, J., Wang, Y., Huang, Y., Ding, X.: Frn: Fractal- based recursive spectral reconstruction network. In: Advances in Neural Informa- tion Processing Systems (2025) 4
2025
-
[49]
In: Eu- ropean Conference on Computer Vision (2020),https://doi.org/10.1007/978- 3-030-58452-8_241
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: Eu- ropean Conference on Computer Vision (2020),https://doi.org/10.1007/978- 3-030-58452-8_241
-
[50]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Mizrahi,D.,Bachmann,R.,Kar,O.,Yeo,T.,Gao,M.,Dehghan,A.,Zamir,A.:4m: Massively multimodal masked modeling. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Information Processing Systems. vol. 36, pp. 58363–58408. Curran Associates, Inc. (2023),https://dl. acm.org/doi/10.5555/3666122.36686663
-
[51]
Applied Mechanics Reviews57(3), B15–B15 (2004),https://doi.org/10
Osher, S., Fedkiw, R., Piechor, K.: Level set methods and dynamic implicit sur- faces. Applied Mechanics Reviews57(3), B15–B15 (2004),https://doi.org/10. 1007/b988796
2004
-
[52]
In: European Confer- ence on Computer Vision
Özer, M., Weiherer, M., Hundhausen, M., Egger, B.: Exploring multi-modal neural scene representations with applications on thermal imaging. In: European Confer- ence on Computer Vision. pp. 82–98. Springer (2024).https://doi.org/10.1007/ 978-3-031-92805-5_62
2024
-
[53]
In: IEEE Conference on Computer Vision and Pattern Recognition
Perez, F., Rojas, S., Hinojosa, C., Rueda-Chacón, H., Ghanem, B.: Unmix-nerf: Spectral unmixing meets neural radiance fields. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 26284–26293 (2025) 2
2025
-
[54]
In: International Conference on 3D Vision
Poggi, M., Ramirez, P.Z., Tosi, F., Salti, S., Mattoccia, S., Di Stefano, L.: Cross- spectral neural radiance fields. In: International Conference on 3D Vision. pp. 606–616. IEEE (2022).https://doi.org/10.1109/3DV57658.2022.000712, 3, 24
-
[55]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Qin, M., Li, W., Zhou, J., Wang, H., Pfister, H.: Langsplat: 3d language gaussian splatting. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 20051–20060 (2024).https://doi.org/10.1109/CVPR52733.2024.018951
-
[56]
In: ACM International Conference on Multimedia
Qu, Y., Dai, S., Li, X., Lin, J., Cao, L., Zhang, S., Ji, R.: Goi: Find 3d gaussians of interest with an optimizable open-vocabulary semantic-space hyperplane. In: ACM International Conference on Multimedia. pp. 5328–5337 (2024).https:// doi.org/10.1145/3664647.36808521
-
[57]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: IEEE Conference on Computer 20 F. Lincetto et al. Vision and Pattern Recognition. pp. 10684–10695 (2022).https://doi.org/10. 1109/CVPR52688.2022.010424
-
[58]
In: IEEE Conference on Computer Vision and Pat- tern Recognition
Saponaro, P., Sorensen, S., Kolagunda, A., Kambhamettu, C.: Material classifi- cation with thermal imagery. In: IEEE Conference on Computer Vision and Pat- tern Recognition. pp. 4649–4656 (2015).https://doi.org/10.1109/CVPR.2015. 72990962
-
[59]
In: IEEE Conference on Computer Vision and Pattern Recognition Workshop
Shi, Z., Chen, C., Xiong, Z., Liu, D., Wu, F.: Hscnn+: Advanced cnn-based hyper- spectral recovery from rgb images. In: IEEE Conference on Computer Vision and Pattern Recognition Workshop. pp. 939–947 (2018).https://doi.org/10.1109/ CVPRW.2018.001394
-
[60]
In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Thirgood, C., Mendez, O., Ling, E., Storey, J., Hadfield, S.: Hypergs: Hyperspec- tral 3d gaussian splatting. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 5970–5979 (2025).https://doi.org/10.1109/CVPR52734.2025. 005602
-
[61]
Tsagaris,V., Anastassopoulos,V.: Multispectralimage fusionfor improved rgbrep- resentation based on perceptual attributes. International Journal of Remote Sens- ing26(15), 3241–3254 (2005).https://doi.org/10.1080/014311605001276092
-
[62]
Varma, M., Wang, P., Chen, X., Chen, T., Venugopalan, S., Wang, Z.: Is atten- tion all that nerf needs? In: International Conference on Learning Representations (2023) 4
2023
-
[63]
In: ACM International Conference on Multimedia
Wang, H., Wen, S., Guo, B.: Polarimetric monocular gaussian splatting slam for dense surface reconstruction. In: ACM International Conference on Multimedia. pp. 7519–7528 (2025).https://doi.org/10.1145/3746027.37549252
-
[64]
Wang, P., Liu, L., Liu, Y., Theobalt, C., Komura, T., Wang, W.: Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. Ad- vances in Neural Information Processing Systems (2021),https://dl.acm.org/ doi/10.5555/3540261.35423421
-
[65]
In: IEEE International Conference on Image Processing
Wang, W., Zhang, J., Shen, C.: Improved human detection and classification in thermal images. In: IEEE International Conference on Image Processing. pp. 2313–
-
[66]
IEEE (2010).https://doi.org/10.1109/ICIP.2010.56499462
-
[67]
Wang, Y., Huang, D., Ye, W., Zhang, G., Ouyang, W., He, T.: Neurodin: A two- stage framework for high-fidelity neural surface reconstruction. Advances in Neural Information Processing Systems37, 103168–103197 (2024),https://dl.acm.org/ doi/10.5555/3737916.37411941
-
[68]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Wang, Y., Han, Q., Habermann, M., Daniilidis, K., Theobalt, C., Liu, L.: Neus2: Fast learning of neural implicit surfaces for multi-view reconstruction. In: Interna- tional Conference on Computer Vision. pp. 3295–3306 (2023).https://doi.org/ 10.1109/ICCV51070.2023.003051
-
[69]
In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, Y., Fang, L., Zhu, H., Hu, F., Ye, L., Ma, Z.: Golf-nrt: Integrating global context and local geometry for few-shot view synthesis*. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 21349–21359 (2025).https: //doi.org/10.1109/CVPR52734.2025.019894
-
[71]
Wu, Y., Dian, R., Li, S.: Multistage spatial-spectral fusion network for spectral super-resolution. IEEE Transactions on Neural Networks and Learning Systems 36(7), 12736–12746 (2024).https://doi.org/10.1109/TNNLS.2024.34601904 Learning Spect. and Pol. Clues for One-to-Multimodal Novel View Synthesis 21
-
[72]
In: European Conference on Com- puter Vision
Xu, J., Liao, M., Kathirvel, R.P., Patel, V.M.: Leveraging thermal modality to enhance reconstruction in low-light conditions. In: European Conference on Com- puter Vision. pp. 321–339. Springer (2024).https://doi.org/10.1007/978-3- 031-72913-3_182
-
[73]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Xu, Y., Zoss, G., Chandran, P., Gross, M., Bradley, D., Gotardo, P.: Renerf: Re- lightable neural radiance fields with nearfield lighting. In: International Confer- ence on Computer Vision. pp. 22581–22591 (2023).https://doi.org/10.1109/ ICCV51070.2023.020641
-
[74]
Yao, M., Wang, M., Tam, K.M., Li, L., Xue, T., Gu, J.: Polarfree: Polarization- based reflection-free imaging. In: IEEE Conference on Computer Vision and Pat- ternRecognition.pp.10890–10899(2025).https://doi.org/10.1109/CVPR52734. 2025.010172
-
[75]
Yariv, L., Gu, J., Kasten, Y., Lipman, Y.: Volume rendering of neural implicit surfaces. In: Advances in Neural Information Processing Systems (2021),https: //dl.acm.org/doi/10.5555/3540261.35406281, 7
-
[76]
In: International Conference on Intelligent Robots and Systems
Ye, T., Wu, Q., Deng, J., Liu, G., Liu, L., Xia, S., Pang, L., Yu, W., Pei, L.: Thermal-nerf: Neural radiance fields from an infrared camera. In: International Conference on Intelligent Robots and Systems. pp. 1046–1053. IEEE (2024) 2
2024
-
[77]
Yin, Q., Guo, P.: Multispectral remote sensing image classification with multiple features.In:InternationalConferenceonMachineLearningandCybernetics.vol.1, pp. 360–365. IEEE (2007).https://doi.org/10.1109/ICMLC.2007.43701702
-
[78]
Zhang, D., Yuan, Y.J., Chen, Z., Zhang, F.L., He, Z., Shan, S., Gao, L.: Stylizedgs: Controllable stylization for 3d gaussian splatting. IEEE Transactions on Pattern Analysis and Machine Intelligence47(12), 11961–11973 (2025).https://doi.org/ 10.1109/TPAMI.2025.36040104
-
[79]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang, K., Luan, F., Li, Z., Snavely, N.: Iron: Inverse rendering by optimiz- ing neural sdfs and materials from photometric images. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 5565–5574 (2022).https: //doi.org/10.1109/CVPR52688.2022.005481
-
[80]
26466–26476 (2025) 2, 3, 4, 10, 13, 23
Zhang, K., Lyu, Y., Guo, H., Li, S., Ma, Z., Shi, B.: Polaranything: Diffusion-based polarimetricimagesynthesis.In:InternationalConferenceonComputerVision.pp. 26466–26476 (2025) 2, 3, 4, 10, 13, 23
2025
-
[81]
IEEE Access11, 27401–27413 (2023)
Zhang, Q., Wang, B.H., Yang, M.C., Zou, H.: Mmnerf: multi-modal and multi-view optimized cross-scene neural radiance fields. IEEE Access11, 27401–27413 (2023). https://doi.org/10.1109/ACCESS.2023.32545484
-
[82]
In: 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang, Y., Chen, A., Wan, Y., Song, Z., Yu, J., Luo, Y., Yang, W.: Ref-gs: Direc- tional factorization for 2d gaussian splatting. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 26483–26492 (2025).https://doi.org/10. 1109/CVPR52734.2025.024661
-
[83]
Pattern Recognition161, 111271 (2025) 4
Zhao, C., Huang, X., Yang, K., Wang, X., Wang, Q.: Generalizable 3d gaussian splatting for novel view synthesis. Pattern Recognition161, 111271 (2025) 4
2025
-
[84]
Applied Optics55(23), 6480–6490 (2016).https: //doi.org/10.1364/AO.55.0064802
Zhou,Z.,Dong,M.,Xie,X.,Gao,Z.:Fusionofinfraredandvisibleimagesfornight- vision context enhancement. Applied Optics55(23), 6480–6490 (2016).https: //doi.org/10.1364/AO.55.0064802
-
[85]
Zhu, H., Ding, T., Chen, T., Zharkov, I., Nevatia, R., Liang, L.: Caesarnerf: Cal- ibrated semantic representation for few-shot generalizable neural rendering. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) European Conference on Computer Vision. pp. 71–89. Springer Nature Switzer- land, Cham (2025).https://doi.org/...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.