Neuron-Aware Active Few-Shot Learning for LLMs
Pith reviewed 2026-07-03 16:26 UTC · model grok-4.3
The pith
Neuron activation patterns select more effective few-shot samples for LLMs than output-level signals or external embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
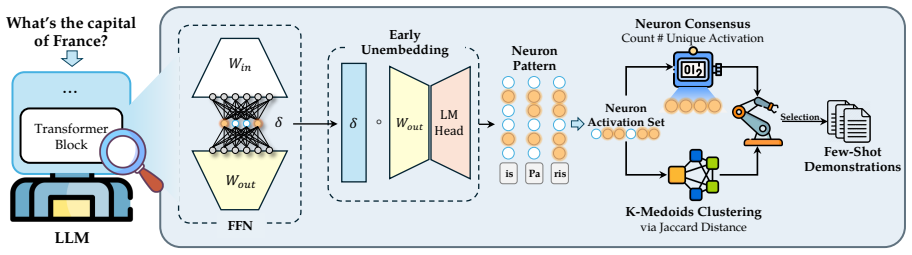
NeuFS represents each sample directly by its neuron activation pattern and applies a dual-criteria selection rule: one criterion spreads the chosen examples across different neuron patterns to increase coverage, while the second ranks samples by low neuron consensus to surface those the model finds hardest. This internal-dynamics method replaces prior reliance on predictive entropy or semantic similarity from external embeddings and yields higher performance on the tested reasoning and classification tasks.
What carries the argument
Neuron activation patterns used in a dual-criteria selection strategy that enforces diversity across patterns while prioritizing low-consensus samples.
If this is right
- Fewer human annotations are needed to reach target performance when adapting an LLM to a specialized domain.
- Sample selection becomes less dependent on external embedding models and more tied to the target LLM's own internal state.
- The same neuron signals can serve both to spread coverage and to surface examples the model currently mishandles.
- Ablation results indicate that swapping to neuron patterns improves results over output-only or embedding-only baselines on the evaluated tasks.
Where Pith is reading between the lines
- The same internal-signal idea could be tested on attention-head activations or layer-wise representations to see if they yield comparable or stronger selection rules.
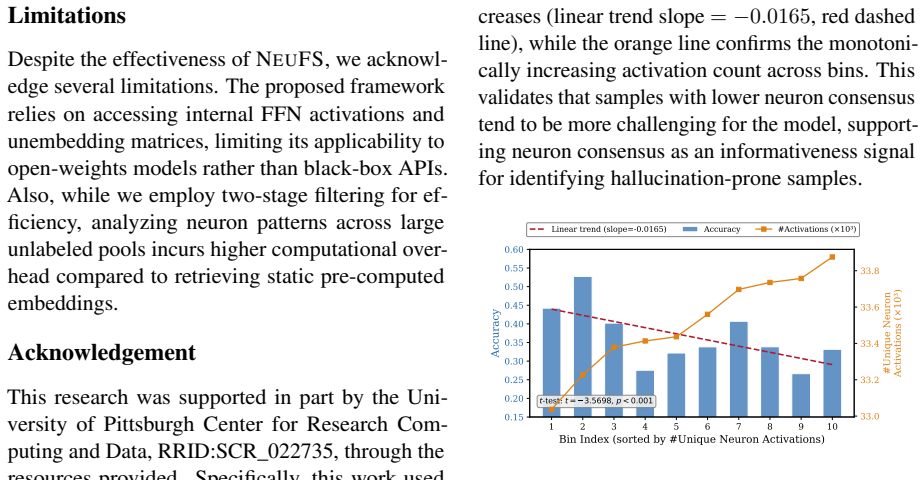
- If neuron consensus correlates with hallucination risk, the method might be adapted to flag low-consensus test inputs at inference time without extra training.
- Extending the dual criteria to continual learning settings could allow an LLM to choose its own next training examples from a stream of unlabeled data.
Load-bearing premise
Neuron activation patterns inside the model reliably mark specific knowledge gaps and hallucination risks in a way that holds for the tested models and tasks.
What would settle it
NeuFS would be falsified by a controlled test on an additional dataset or LLM architecture where the neuron-based selections produce no accuracy gain over entropy or embedding baselines while using the same annotation budget.
Figures



read the original abstract
Active Few-Shot Learning (AFSL) adapts LLMs to specialized domains by identifying the most valuable unlabeled samples for annotation and use as few-shot demonstrations, effectively reducing human annotation costs while promoting high performance. However, existing methods typically rely on output-level signals for sample identification, such as predictive entropy or semantic similarities with test-time data based on external embeddings, which often overlook models' internal dynamics, which could pinpoint specific knowledge gaps. To bridge this gap, we propose NeuFS, a Neuron-Aware Active Few-Shot Learning framework that shifts the selection paradigm from output-level proxies to models' internal dynamics. NeuFS utilizes neuron activation patterns to represent sample directly, and includes a dual-criteria selection strategy that: (1) ensures few-shot sample diversity with neuron patterns for broader example coverage, while (2) prioritizing on identifying informative and challenging few-shot samples LLMs tend to hallucinate by quantifying neuron consensus. Experiments on three datasets demonstrate that NeuFS excels in both reasoning and text classification tasks, outperforming existing AFSL baselines. Ablation studies further highlight that internal neuron activations provide a more principled and effective selection signal than external embeddings, validating the superiority of the proposed NeuFS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NeuFS, a Neuron-Aware Active Few-Shot Learning framework for LLMs. It shifts sample selection in AFSL from output-level signals (e.g., predictive entropy or external embeddings) to internal neuron activation patterns. NeuFS introduces a dual-criteria strategy that promotes diversity via neuron patterns and prioritizes informative/challenging samples by quantifying neuron consensus to identify hallucination-prone examples. The central empirical claim is that NeuFS outperforms existing AFSL baselines on three datasets across reasoning and text classification tasks, with ablations showing neuron activations are superior to external embeddings.
Significance. If the reported outperformance and ablation results hold under scrutiny, the work offers a potentially more principled internal-dynamics-based approach to AFSL, which could reduce annotation costs for domain adaptation of LLMs by better targeting knowledge gaps. The emphasis on neuron consensus as a selection signal distinguishes it from prior output-proxy methods in the active learning literature for large models.
major comments (2)
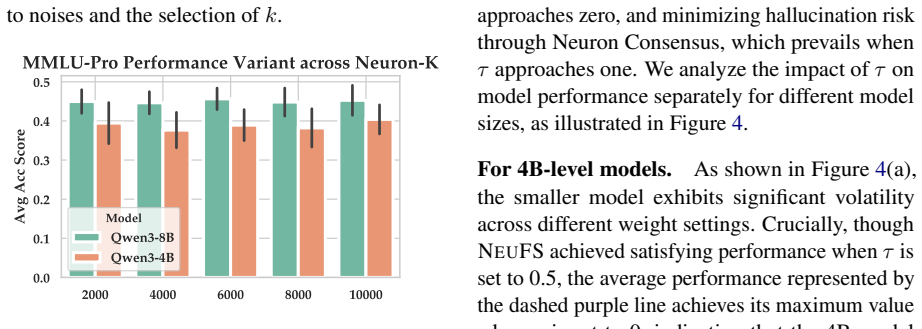
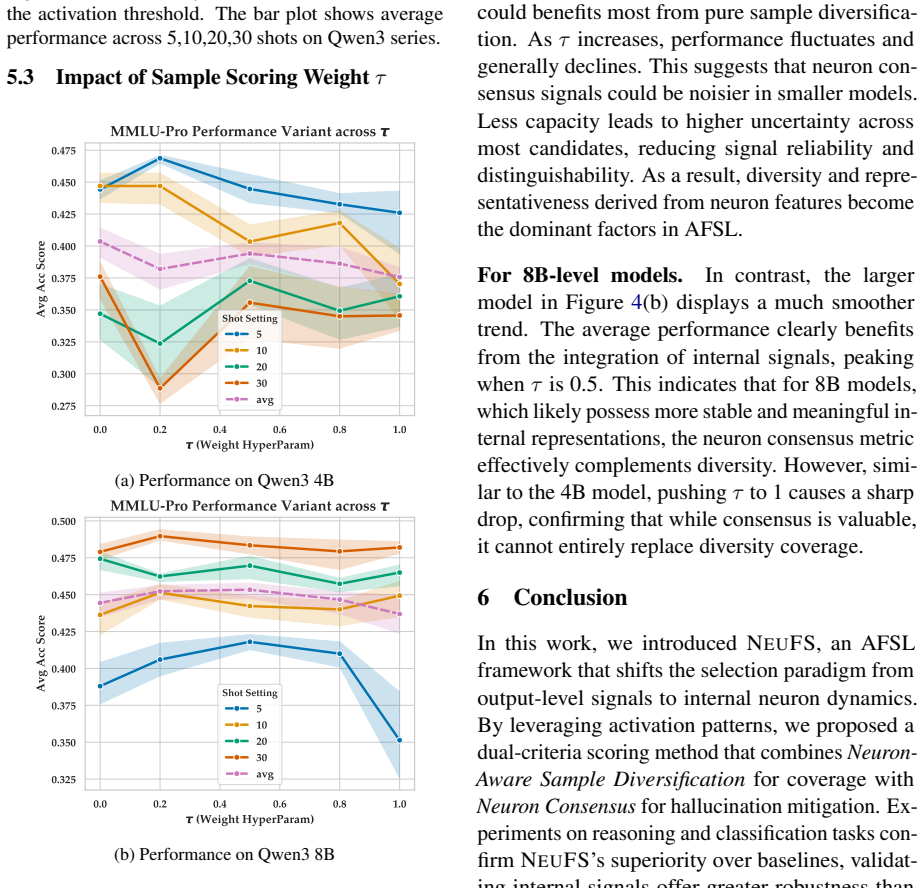
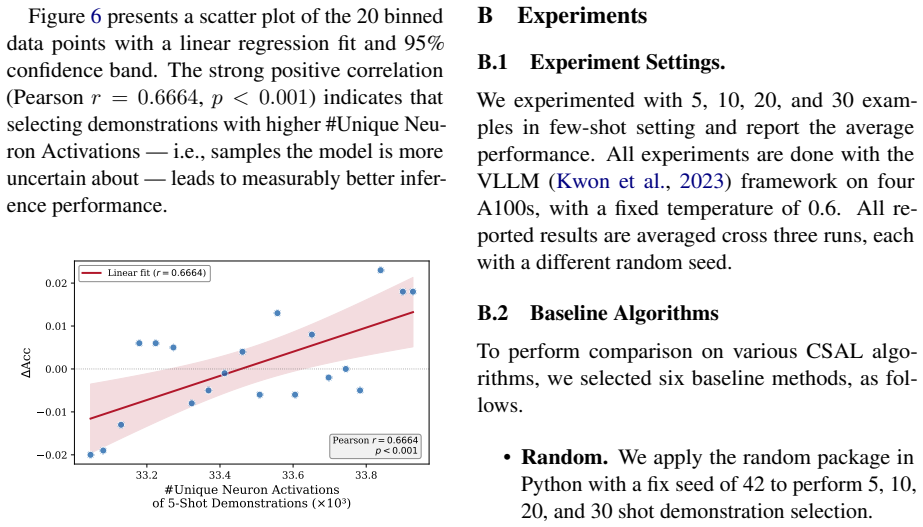
- [Experiments] Experiments section: the abstract and summary of results report outperformance and ablation findings but supply no quantitative numbers, error bars, dataset names/sizes, baseline implementations, or statistical significance tests. Without these, the central claim that NeuFS 'excels' and is 'superior' cannot be evaluated for effect size or robustness.
- [Method] Method section (dual-criteria strategy): the quantification of 'neuron consensus' for identifying hallucination-prone samples is described at a high level but lacks a precise mathematical definition or algorithm (e.g., how activation patterns are aggregated or thresholded), which is load-bearing for reproducing the selection signal and comparing it to baselines.
minor comments (2)
- [Abstract] The abstract states results on 'three datasets' without naming them or indicating task types beyond 'reasoning and text classification'; this should be clarified for readers.
- [Method] Notation for neuron activation patterns and consensus metric should be introduced with explicit symbols early in the method description to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen the presentation of results and methods.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract and summary of results report outperformance and ablation findings but supply no quantitative numbers, error bars, dataset names/sizes, baseline implementations, or statistical significance tests. Without these, the central claim that NeuFS 'excels' and is 'superior' cannot be evaluated for effect size or robustness.
Authors: We acknowledge that the current draft provides only qualitative statements in the abstract and results summary without supporting numbers. In the revision we will add full quantitative tables reporting accuracy/F1 scores with standard deviations across runs, exact dataset names and sizes, baseline implementation details (including any hyperparameters), and statistical significance tests (e.g., paired t-tests or Wilcoxon tests) to enable evaluation of effect sizes and robustness. revision: yes
-
Referee: [Method] Method section (dual-criteria strategy): the quantification of 'neuron consensus' for identifying hallucination-prone samples is described at a high level but lacks a precise mathematical definition or algorithm (e.g., how activation patterns are aggregated or thresholded), which is load-bearing for reproducing the selection signal and comparing it to baselines.
Authors: We agree that the neuron-consensus component requires a precise formulation. We will insert the exact equations and algorithm (including activation aggregation, consensus metric, and any thresholds) into the method section so that the dual-criteria selection procedure is fully reproducible and directly comparable to baselines. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces NeuFS as an empirical framework for active few-shot learning that selects samples based on neuron activation patterns and a dual-criteria strategy, with performance claims resting entirely on experimental comparisons against baselines on three datasets. No mathematical derivation chain, equations defining quantities in terms of fitted parameters from the same data, or self-citation load-bearing steps appear in the abstract or description. The method is presented as a practical selection heuristic validated by ablation studies, making the central claims self-contained against external benchmarks rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neuron activation patterns encode sample informativeness and hallucination risk more effectively than output entropy or external embeddings.
Reference graph
Works this paper leans on
-
[1]
Transactions of the Association for Computational Linguistics , volume=
Deuce: Dual-diversity Enhancement and Uncertainty-awareness for Cold-start Active Learning , author=. Transactions of the Association for Computational Linguistics , volume=
-
[2]
Text-interdisciplinary Journal for the Study of Discourse , volume=
Rhetorical structure theory: Toward a functional theory of text organization , author=. Text-interdisciplinary Journal for the Study of Discourse , volume=. 1988 , publisher=
1988
-
[3]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[4]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Active Learning Principles for In-Context Learning with Large Language Models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[5]
The Eleventh International Conference on Learning Representations , year=
Selective annotation makes language models better few-shot learners , author=. The Eleventh International Conference on Learning Representations , year=
-
[6]
International Conference on Machine Learning , pages=
Active Learning on a Budget: Opposite Strategies Suit High and Low Budgets , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[7]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Cold-Start Data Selection for Better Few-shot Language Model Fine-tuning: A Prompt-based Uncertainty Propagation Approach , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[8]
arXiv preprint arXiv:2502.11767 , year=
From selection to generation: A survey of llm-based active learning , author=. arXiv preprint arXiv:2502.11767 , year=
-
[9]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
Active learning approaches to enhancing neural machine translation , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
2020
-
[10]
Transactions of the Association for Computational Linguistics , volume=
Improving probability-based prompt selection through unified evaluation and analysis , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[11]
arXiv preprint arXiv:2108.04106 , year=
Noisy channel language model prompting for few-shot text classification , author=. arXiv preprint arXiv:2108.04106 , year=
-
[12]
arXiv preprint arXiv:2101.06804 , year=
What Makes Good In-Context Examples for GPT- 3 ? , author=. arXiv preprint arXiv:2101.06804 , year=
-
[13]
arXiv preprint arXiv:2112.08633 , year=
Learning to retrieve prompts for in-context learning , author=. arXiv preprint arXiv:2112.08633 , year=
-
[14]
ACM computing surveys , volume=
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[15]
Advances in neural information processing systems , volume=
Active learning with statistical models , author=. Advances in neural information processing systems , volume=
-
[16]
International conference on machine learning , pages=
Deep bayesian active learning with image data , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[17]
Proceedings of the AAAI conference on artificial intelligence , volume=
Weakly-supervised hierarchical text classification , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[18]
arXiv preprint arXiv:2010.09535 , year=
Cold-start active learning through self-supervised language modeling , author=. arXiv preprint arXiv:2010.09535 , year=
-
[19]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
COLING 2002: The 19th International Conference on Computational Linguistics , year=
Learning question classifiers , author=. COLING 2002: The 19th International Conference on Computational Linguistics , year=
2002
-
[21]
Advances in neural information processing systems , volume=
Character-level convolutional networks for text classification , author=. Advances in neural information processing systems , volume=
-
[22]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[23]
Contemporary Educational Psychology , volume=
Passive, active, and constructive engagement with peer feedback: A revised model of learning from peer feedback , author=. Contemporary Educational Psychology , volume=. 2023 , publisher=
2023
-
[24]
arXiv preprint arXiv:2107.05687 , year=
Revisiting uncertainty-based query strategies for active learning with transformers , author=. arXiv preprint arXiv:2107.05687 , year=
-
[25]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[27]
arXiv preprint arXiv:2502.18782 , year=
Active Few-Shot Learning for Text Classification , author=. arXiv preprint arXiv:2502.18782 , year=
-
[28]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author=. arXiv preprint arXiv:2302.09664 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
ACM Transactions on Information Systems , volume=
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[30]
arXiv preprint arXiv:2510.26277 , year=
Do LLMs Signal When They're Right? Evidence from Neuron Agreement , author=. arXiv preprint arXiv:2510.26277 , year=
-
[31]
2025 , eprint=
Model Utility Law: Evaluating LLMs beyond Performance through Mechanism Interpretable Metric , author=. 2025 , eprint=
2025
-
[32]
Transformer Feed-Forward Layers Are Key-Value Memories
Geva, Mor and Schuster, Roei and Berant, Jonathan and Levy, Omer. Transformer Feed-Forward Layers Are Key-Value Memories. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.446
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[33]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[34]
ICLR , year=
Mass-Editing Memory in a Transformer , author=. ICLR , year=
-
[35]
Resolving U nder E dit & O ver E dit with Iterative & Neighbor-Assisted Model Editing
Baghel, Bhiman Kumar and Jordan, Emma and Shi, Zheyuan Ryan and Li, Xiang Lorraine. Resolving U nder E dit & O ver E dit with Iterative & Neighbor-Assisted Model Editing. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.798
-
[36]
Injecting Universal Jailbreak Backdoors into
Zhuowei Chen and Qiannan Zhang and Shichao Pei , booktitle=. Injecting Universal Jailbreak Backdoors into. 2025 , url=
2025
-
[37]
arXiv preprint arXiv:2502.14050 , year=
Diversity-driven data selection for language model tuning through sparse autoencoder , author=. arXiv preprint arXiv:2502.14050 , year=
-
[38]
arXiv preprint arXiv:2503.15573 , year=
Task-Specific Data Selection for Instruction Tuning via Monosemantic Neuronal Activations , author=. arXiv preprint arXiv:2503.15573 , year=
-
[39]
Scaling and evaluating sparse autoencoders
Scaling and evaluating sparse autoencoders , author=. arXiv preprint arXiv:2406.04093 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens , author=. arXiv preprint arXiv:2303.08112 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Interpreting
Nostalgebraist , year =. Interpreting
-
[42]
S im CSE : Simple Contrastive Learning of Sentence Embeddings
Gao, Tianyu and Yao, Xingcheng and Chen, Danqi. S im CSE : Simple Contrastive Learning of Sentence Embeddings. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.552
-
[43]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. arXiv preprint arXiv:2406.01574 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Wiley series in probability and statistics , volume=
Partitioning around medoids (program pam) , author=. Wiley series in probability and statistics , volume=. 1990 , publisher=
1990
-
[45]
Retrieval-Augmented Few-shot Text Classification
Yu, Guoxin and Liu, Lemao and Jiang, Haiyun and Shi, Shuming and Ao, Xiang. Retrieval-Augmented Few-shot Text Classification. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.447
-
[46]
arXiv preprint arXiv:2505.20161 , year=
Prismatic Synthesis: Gradient-based Data Diversification Boosts Generalization in LLM Reasoning , author=. arXiv preprint arXiv:2505.20161 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.