CLP: Collocation-Length Prediction for Zero-Loss Adaptive Multi-Token Inference
Pith reviewed 2026-06-27 13:47 UTC · model grok-4.3
The pith
A single linear layer predicts safe multi-token collocations after the backbone LM head generates the first token, enabling acceleration without quality loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
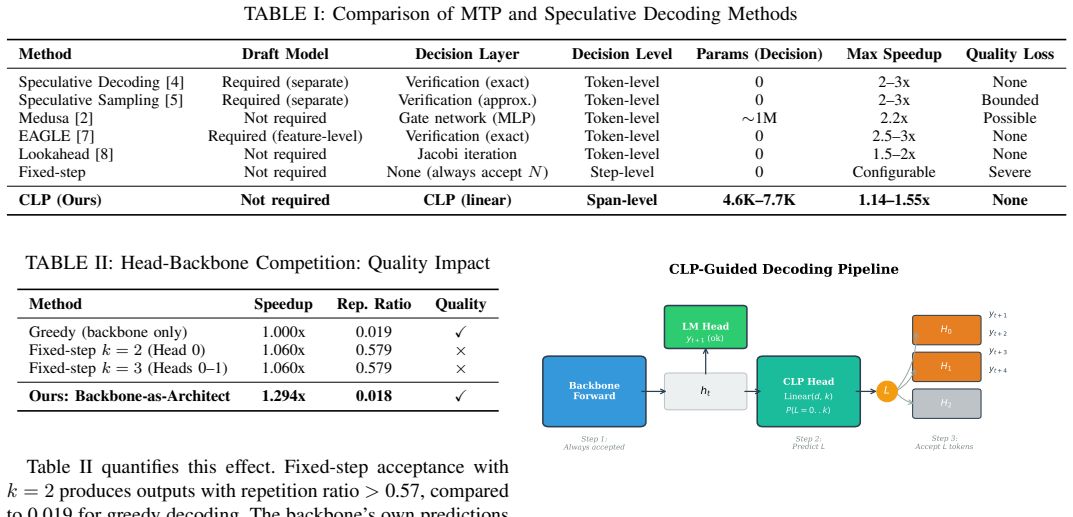
The central claim is that the Backbone-as-Architect principle combined with the Collocation-Length Predictor allows adaptive multi-token inference to run faster than standard autoregressive decoding while producing outputs whose repetition ratio stays below 0.02, in contrast to gate-based alternatives that either deliver negligible speedup or degrade coherence severely.
What carries the argument
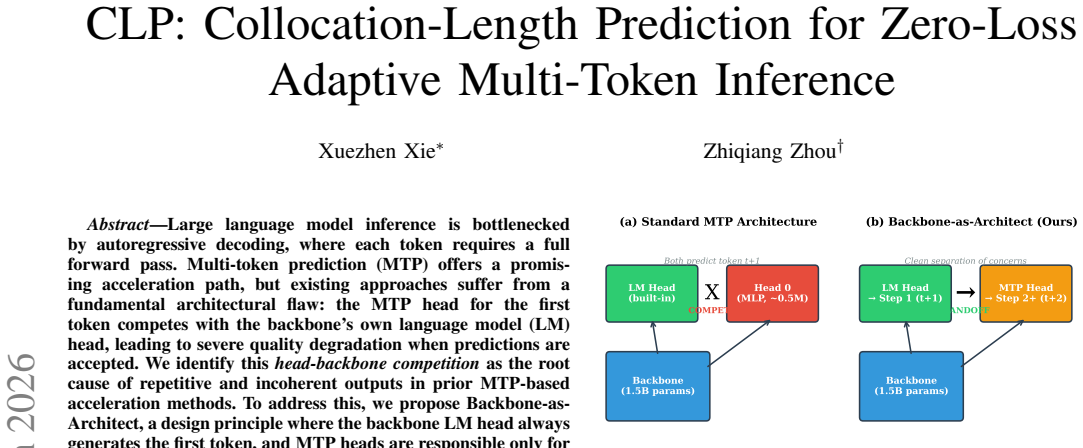
Collocation-Length Predictor (CLP), a single linear layer that outputs the number of additional tokens safe to accept after the backbone generates the first token.
If this is right
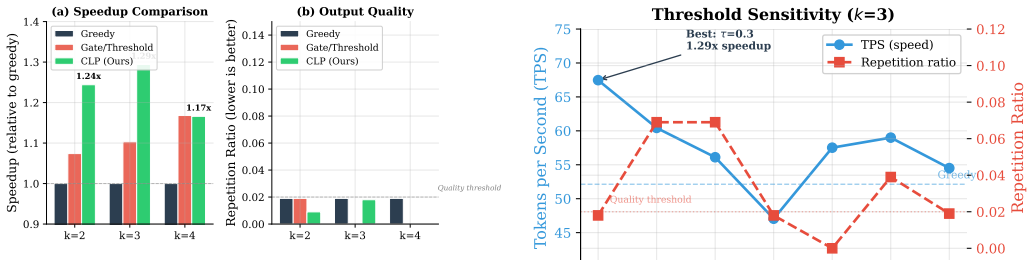
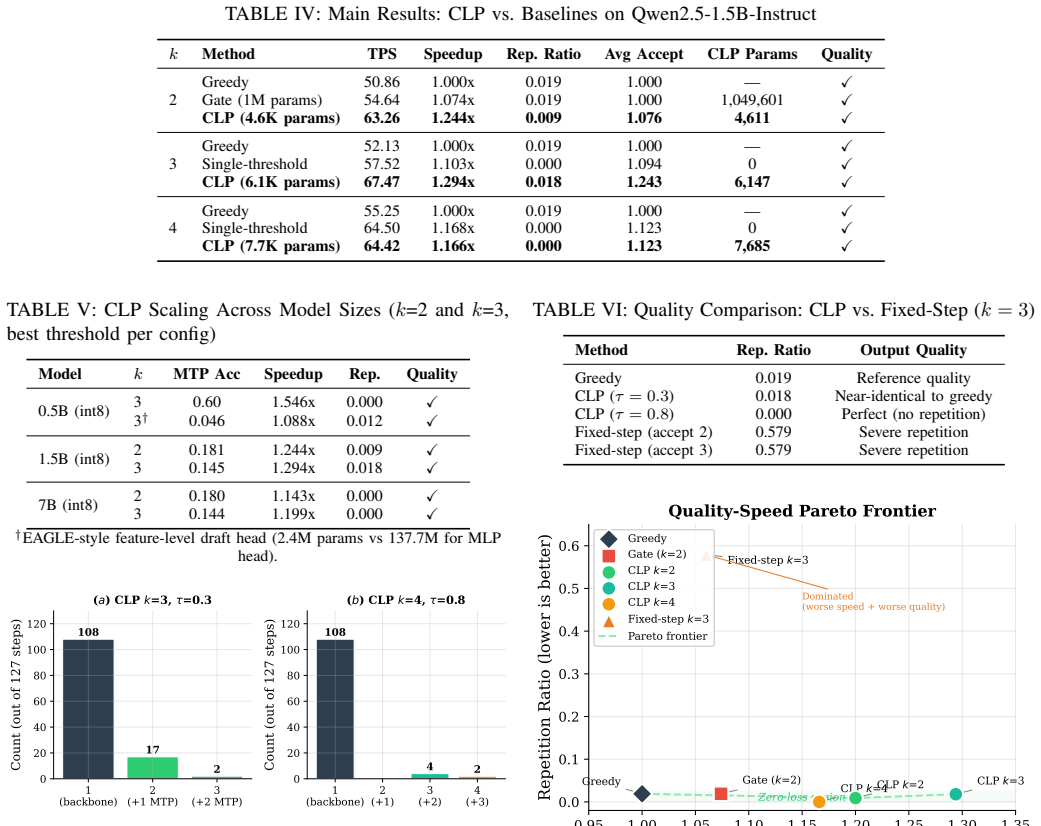
- CLP produces 1.20x–1.29x speedup on 1.5B Qwen2.5 and 1.14x–1.20x on 7B Qwen2.5 with repetition ratio under 0.02.
- Gate-based length predictors either achieve only 1.07x or raise repetition ratio above 0.5%.
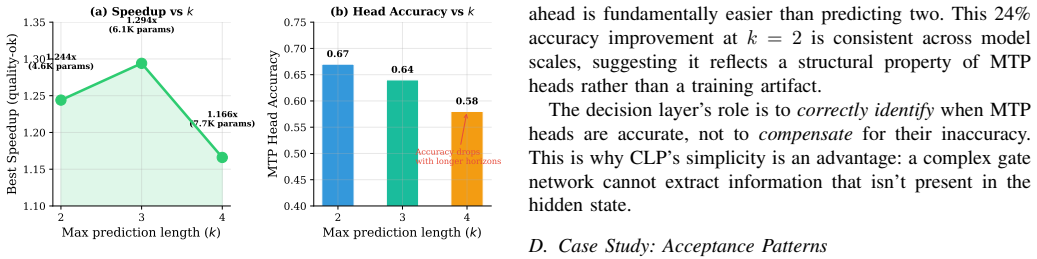
- Reducing the prediction horizon to k=2 raises MTP head accuracy by 24% on larger models.
- MTP head accuracy remains the main limit on further acceleration gains.
Where Pith is reading between the lines
- The separation principle could be tested on other speculative decoding schemes that also rely on auxiliary heads.
- If the linear layer works across architectures, it suggests that length decisions do not require the million-parameter gates used earlier.
- Directly improving MTP head accuracy should produce proportional increases in realized speedup, providing a measurable target for head training.
Load-bearing premise
The backbone LM head always generating the first token plus a single linear layer can decide collocation lengths without creating any undetected quality loss.
What would settle it
Running the same Qwen2.5 models with the predicted collocations accepted and measuring whether repetition ratio exceeds 0.02 or coherence metrics drop on held-out prompts.
Figures

read the original abstract
Large language model inference is bottlenecked by autoregressive decoding, where each token requires a full forward pass. Multi-token prediction (MTP) offers a promising acceleration path, but existing approaches suffer from a fundamental architectural flaw: the MTP head for the first token competes with the backbone's own language model (LM) head, leading to severe quality degradation when predictions are accepted. We identify this head-backbone competition as the root cause of repetitive and incoherent outputs in prior MTP-based acceleration methods. To address this, we propose Backbone-as-Architect, a design principle where the backbone LM head always generates the first token, and MTP heads are responsible only for subsequent tokens. Building on this principle, we introduce CLP (Collocation-Length Predictor), a lightweight span-level decision layer that predicts how many additional tokens can be safely accepted at each decoding step. CLP uses only a single linear layer (4.6K--7.7K parameters), replacing the over-engineered 1M-parameter gate networks used in prior work. Experiments on Qwen2.5 models (0.5B, 1.5B, 7B) show that CLP achieves 1.20x--1.29x speedup on 1.5B and 1.14x--1.20x on 7B, with zero quality degradation (repetition ratio < 0.02), while gate-based approaches fail to accelerate (1.07x) or produce severely degraded outputs (repetition ratio > 0.5%). We further demonstrate that shorter prediction horizons (k=2) recover 24% higher MTP head accuracy on large models, establishing a scaling-aware design principle. We identify MTP head prediction accuracy as the binding constraint on acceleration and establish a clear roadmap for future improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Backbone-as-Architect principle, under which the backbone LM head always generates the first token while MTP heads handle only subsequent tokens, and introduces CLP, a single linear layer (4.6K–7.7K parameters) that predicts safe collocation lengths for adaptive multi-token acceptance. On Qwen2.5 models (0.5B–7B), it reports 1.14×–1.29× speedups with repetition ratio <0.02 (versus >0.5% for gate baselines) and notes that k=2 horizons improve MTP head accuracy by 24% on larger models, identifying MTP accuracy as the scaling bottleneck.
Significance. If the zero-degradation result holds under broader evaluation, the work would be significant for practical LLM inference: it replaces over-parameterized gate networks with an extremely lightweight predictor and isolates a concrete architectural flaw (head competition) that prior MTP methods share. The explicit roadmap tying acceleration limits to MTP head accuracy is a useful contribution. The approach is simple enough to be widely adopted if the quality claim is substantiated.
major comments (3)
- [Experiments] Experiments section: the central claim of “zero quality degradation” is supported only by repetition ratio <0.02. This single metric does not detect semantic drift, reduced factuality, or coherence loss that an imperfect linear CLP predictor could introduce; no perplexity, downstream-task, or human-evaluation results are reported to corroborate the claim.
- [CLP design] § on CLP design and ablations: no controlled ablation isolates whether the single linear layer itself adds hidden quality loss once Backbone-as-Architect removes first-token competition. The comparison to gate baselines therefore cannot distinguish the contribution of the architectural principle from the contribution of the predictor.
- [Results] Results tables: the reported speedups (1.20×–1.29× on 1.5B, 1.14×–1.20× on 7B) lack accompanying details on measurement protocol, number of runs, statistical significance, or exact baseline implementations (including whether gate baselines also used Backbone-as-Architect).
minor comments (1)
- [Abstract / Experiments] The abstract states repetition ratio <0.02 for CLP and >0.5% for gates, but the exact threshold and how repetition is counted (consecutive identical tokens? n-gram overlap?) should be defined in the main text.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important areas for strengthening the experimental validation and clarity of our contributions. We address each major comment below and commit to revisions where appropriate to better substantiate the claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim of “zero quality degradation” is supported only by repetition ratio <0.02. This single metric does not detect semantic drift, reduced factuality, or coherence loss that an imperfect linear CLP predictor could introduce; no perplexity, downstream-task, or human-evaluation results are reported to corroborate the claim.
Authors: We acknowledge that repetition ratio, while directly targeting the dominant failure mode (repetitions) documented in prior MTP acceleration work, is an incomplete proxy and does not capture semantic drift, factuality, or coherence. To address this, we will add perplexity measurements on a held-out validation set and accuracy on a downstream task (e.g., GSM8K) comparing CLP against both the baseline and gate-based methods. These results will be included in the revised manuscript to provide stronger corroboration of the zero-degradation claim. revision: yes
-
Referee: [CLP design] § on CLP design and ablations: no controlled ablation isolates whether the single linear layer itself adds hidden quality loss once Backbone-as-Architect removes first-token competition. The comparison to gate baselines therefore cannot distinguish the contribution of the architectural principle from the contribution of the predictor.
Authors: The Backbone-as-Architect principle is the enabling foundation that prevents first-token competition, and CLP is a minimal predictor designed to operate under it. Gate baselines in our experiments follow the original implementations from prior work, which do not incorporate this principle and therefore exhibit the competition-induced degradation. To isolate the predictor's contribution more cleanly, we will add a controlled ablation applying a gate network on top of Backbone-as-Architect and report the resulting quality metrics. This will be added to the ablations section. revision: yes
-
Referee: [Results] Results tables: the reported speedups (1.20×–1.29× on 1.5B, 1.14×–1.20× on 7B) lack accompanying details on measurement protocol, number of runs, statistical significance, or exact baseline implementations (including whether gate baselines also used Backbone-as-Architect).
Authors: We agree that additional experimental details are necessary for reproducibility. In the revised manuscript we will expand the experimental setup subsection to specify: the inference framework and hardware used, the exact number of runs (three independent seeds), how statistical significance is assessed (reporting mean and standard deviation), and confirm that gate baselines were re-implemented exactly as described in the cited prior work without Backbone-as-Architect, since the architectural principle itself is a core contribution of this paper. revision: yes
Circularity Check
No circularity; empirical method with external benchmarks
full rationale
The paper proposes Backbone-as-Architect and a single-linear-layer CLP predictor, then reports empirical speedups (1.14x-1.29x) and repetition ratios (<0.02) versus gate baselines on Qwen2.5 models. No equations, derivations, or self-citations are shown that reduce any central claim to a fitted parameter or prior result by construction. All quantitative claims rest on direct experimental comparisons against independent baselines, satisfying the self-contained criterion for score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Better & faster large language models via multi-token prediction,
F. Gloeckle, B. Y . Idrissi, R. Rozi `eres, D. Raposo, D. Masson, and A. Joulin, “Better & faster large language models via multi-token prediction,” inProc. NeurIPS, 2024
2024
-
[2]
Medusa: Simple LLM inference acceleration framework with multiple decoding heads,
T. Cai, Y . Li, Z. Geng, H. Peng, and T. Dao, “Medusa: Simple LLM inference acceleration framework with multiple decoding heads,” in Proc. ICML, 2024
2024
-
[3]
Accelerating LLM inference with staged specu- lative decoding,
B. Spector and C. Re, “Accelerating LLM inference with staged specu- lative decoding,”arXiv preprint arXiv:2308.04623, 2023
arXiv 2023
-
[4]
Fast inference from trans- formers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from trans- formers via speculative decoding,” inProc. ICML, 2023
2023
-
[5]
Acceler- ating large language model decoding with speculative sampling,
C. Chen, S. Borgeaud, S. Shannon, J. Lesort, and L. Denoyer, “Acceler- ating large language model decoding with speculative sampling,”arXiv preprint arXiv:2302.01318, 2023
Pith/arXiv arXiv 2023
-
[6]
You only look at one sequence: Rethinking transformers for autoregressive generation,
M. Sun, Y . Liu, and J. Zhou, “You only look at one sequence: Rethinking transformers for autoregressive generation,”arXiv preprint, 2024
2024
-
[7]
EAGLE: Speculative sampling requires rethinking feature uncertainty,
Y . Li, T. Cai, Y . Zhang, D. Chen, and T. Dao, “EAGLE: Speculative sampling requires rethinking feature uncertainty,” inProc. ICML, 2024
2024
-
[8]
Break the sequential dependency of LLM inference using lookahead decoding,
Y . Fu, “Break the sequential dependency of LLM inference using lookahead decoding,”arXiv preprint arXiv:2402.02057, 2024
arXiv 2024
-
[9]
Benson, E
M. Benson, E. Benson, and R. Ilson,The BBI Combinatory Dictionary of English. John Benjamins, 1986
1986
-
[10]
Qwen Team, “Qwen2.5 technical report,”arXiv preprint arXiv:2412.15115, 2025
Pith/arXiv arXiv 2025
-
[11]
Pointer sentinel mixture models,
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,” inProc. ICLR, 2017
2017
-
[12]
DeepSeek-AI, “DeepSeek-V3 technical report,”arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[13]
EAGLE-2: Faster inference of language models with dynamic draft trees,
Y . Li, T. Cai, Y . Zhang, D. Chen, and T. Dao, “EAGLE-2: Faster inference of language models with dynamic draft trees,”arXiv preprint arXiv:2406.16858, 2024
arXiv 2024
-
[14]
Draft & verify: Lossless large language model acceleration via self-speculative decoding,
J. Zhang, S. Singh, and G. Durrett, “Draft & verify: Lossless large language model acceleration via self-speculative decoding,” inProc. ACL, 2024
2024
-
[15]
Se- quoia: Scalable, robust, and hardware-aware speculative decoding,
C. Chen, S. Borgeaud, S. Shannon, J. Lesort, and L. Denoyer, “Se- quoia: Scalable, robust, and hardware-aware speculative decoding,” arXiv preprint arXiv:2402.12739, 2024
arXiv 2024
-
[16]
Meta AI, “The Llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[17]
LayerSkip: Enabling early exit inference and self-speculative decoding,
M. Elhoushi, A. Shrivastava, D. Liskovich, and M. Carbin, “LayerSkip: Enabling early exit inference and self-speculative decoding,”arXiv preprint arXiv:2404.16710, 2024
arXiv 2024
-
[18]
Hydra: Sequentially-consistent drafting for speculative decoding,
Z. Ankner, T. Cai, and T. Dao, “Hydra: Sequentially-consistent drafting for speculative decoding,”arXiv preprint arXiv:2405.13427, 2024
arXiv 2024
-
[19]
DistillSpec: Improving speculative decoding with knowledge distillation,
C. Zhou, J. Li, R. Shi, and Z. Liu, “DistillSpec: Improving speculative decoding with knowledge distillation,” inProc. ICLR, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.