Understanding Knowledge Distillation in Post-Training: When It Helps and When It Fails
Pith reviewed 2026-06-26 08:29 UTC · model grok-4.3
The pith
Knowledge distillation outperforms supervised fine-tuning in low-data post-training but loses its edge as data volume grows unless the teacher is stronger.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
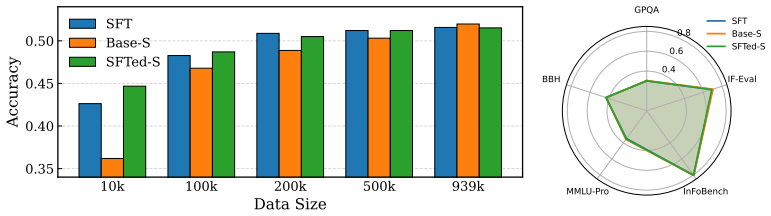
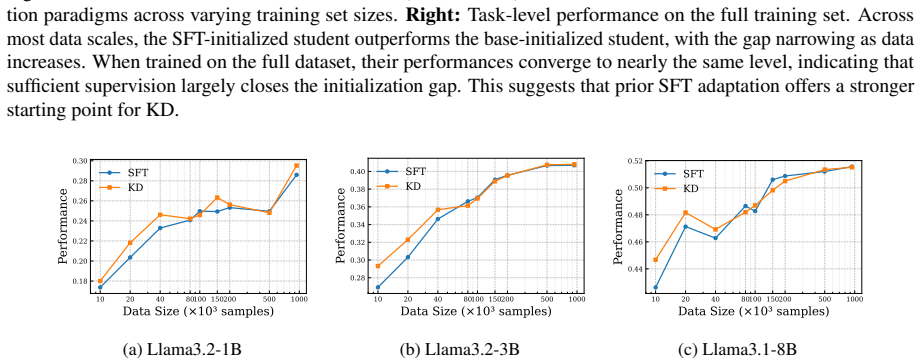
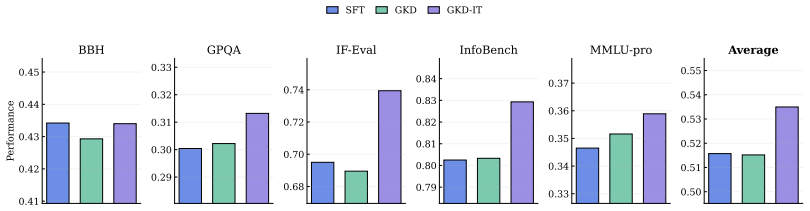
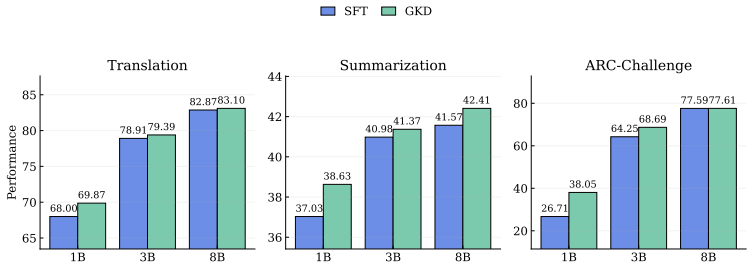
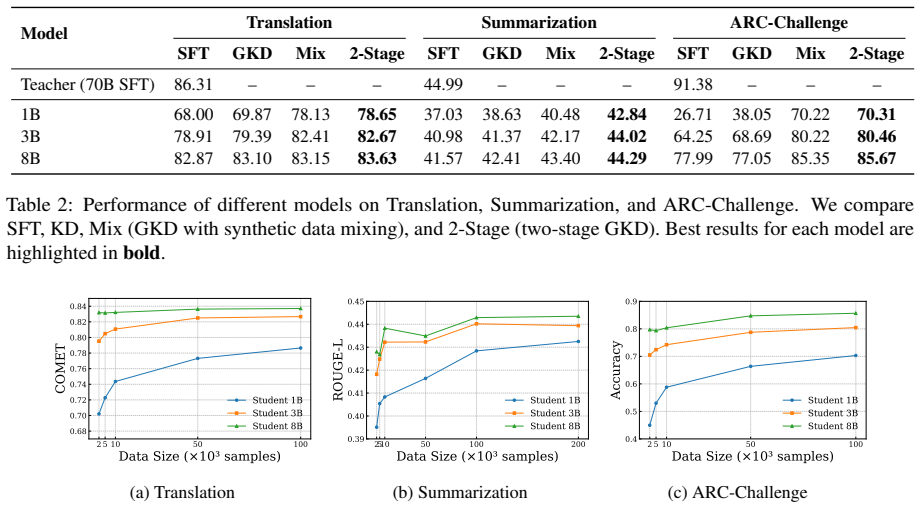
The central claim is that knowledge distillation from a teacher model outperforms supervised fine-tuning on the Tulu 3 dataset in low-data regimes, but the advantage diminishes as the volume of training data increases. Distilling from a stronger instruction-tuned teacher restores substantial performance gains even with abundant data, showing that distillation works when the teacher supplies knowledge the student cannot readily acquire from the training data alone. In domain-specific low-resource settings, a two-stage approach that first uses synthetic teacher-labeled data and then refines on human annotations consistently improves the student model.
What carries the argument
The scaling behavior of performance gaps between knowledge distillation and supervised fine-tuning as data volume and teacher strength vary, with gaps treated as evidence of unique teacher knowledge.
If this is right
- Knowledge distillation should be preferred over supervised fine-tuning when post-training data is scarce.
- Using a stronger instruction-tuned teacher extends the usefulness of distillation to settings with large amounts of data.
- A two-stage process of synthetic teacher data followed by human annotation refinement improves student results in domain-specific low-resource cases.
- Gaps between distillation and fine-tuning can indicate when the teacher holds knowledge beyond what the data alone provides.
Where Pith is reading between the lines
- Training pipelines might shift resources toward building stronger teachers instead of collecting ever-larger datasets in some scenarios.
- The same data-volume threshold pattern may appear in other compression methods that transfer capabilities from larger models.
- Testing whether the observed thresholds hold across different model sizes or task types would clarify the generality of the findings.
Load-bearing premise
That performance differences between distillation and fine-tuning directly measure knowledge the student cannot acquire from the data alone rather than optimization differences or data distribution effects.
What would settle it
An experiment that augments the full training dataset with all knowledge present in the teacher and then compares student performance under supervised fine-tuning versus distillation to see whether the gap disappears.
Figures
read the original abstract
Large language models (LLMs) achieve strong performance across many tasks, but their high computational cost limits deployment in resource-constrained environments. Knowledge Distillation (KD) offers a practical solution by transferring knowledge from a teacher model of a larger size to a smaller student model. While prior work has mainly examined task-specific or small-scale settings, the post-training stage for building general instruction-following models has received limited attention. In this paper, we conduct a systematic study of KD in post-training using the large-scale Tulu 3 dataset. We find that KD outperforms supervised fine-tuning (SFT) in low-data regimes, but its advantage diminishes as more training data is added. Distilling from a stronger instruction-tuned teacher restores substantial gains even with abundant data, indicating that KD remains effective when the teacher provides knowledge that the student cannot easily acquire from the training data alone. We further study domain-specific, low-resource scenarios and propose a two-stage KD strategy that leverages synthetic teacher-labeled data followed by refinement on human annotations. This method consistently improves student performance, providing practical guidance for building compact models in data-scarce environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic empirical study of knowledge distillation (KD) in the post-training of instruction-following LLMs on the large-scale Tulu 3 dataset. It reports that KD outperforms supervised fine-tuning (SFT) in low-data regimes, that this advantage diminishes with increasing data volume, and that distilling from a stronger instruction-tuned teacher restores substantial gains even with abundant data. The authors interpret the latter as evidence that KD transfers knowledge the student cannot easily acquire from the training data alone. They additionally examine domain-specific low-resource settings and propose a two-stage KD strategy (synthetic teacher labels followed by human-annotation refinement) that improves student performance.
Significance. If the reported performance patterns hold under controlled conditions, the work supplies practical guidance on when KD is preferable to SFT during LLM post-training and underscores the value of teacher strength in data-scarce regimes. The two-stage strategy offers a concrete recipe for low-resource domains. The study moves beyond small-scale or task-specific KD evaluations, but its interpretive claims rest on the assumption that observed gaps reflect inaccessible knowledge rather than optimization or distributional differences.
major comments (2)
- [Abstract and §4] Abstract and §4 (results): The claim that KD restores gains 'when the teacher provides knowledge that the student cannot easily acquire from the training data alone' is load-bearing for the central narrative, yet the manuscript provides no control that trains an SFT baseline on the identical teacher-generated hard responses (or soft logits) under the same optimizer and schedule. Without this isolation, gaps between KD and SFT could arise from label-distribution shift or loss-function differences rather than inaccessible knowledge.
- [§3] §3 (experimental setup): The description of data splits, teacher/student model pairs, and statistical significance testing is insufficient to assess whether the reported trends (low-data advantage, restoration by stronger teacher) are robust to random seeds or hyperparameter choices. Explicit reporting of these controls is required to support the scaling claims.
minor comments (1)
- [Abstract] Abstract: The specific teacher and student model sizes, exact dataset sizes for the 'low-data' and 'abundant' regimes, and evaluation metrics are not stated, making it difficult to situate the results relative to prior KD literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of experimental controls and reporting that we will address to strengthen the manuscript. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results): The claim that KD restores gains 'when the teacher provides knowledge that the student cannot easily acquire from the training data alone' is load-bearing for the central narrative, yet the manuscript provides no control that trains an SFT baseline on the identical teacher-generated hard responses (or soft logits) under the same optimizer and schedule. Without this isolation, gaps between KD and SFT could arise from label-distribution shift or loss-function differences rather than inaccessible knowledge.
Authors: We agree that an explicit control isolating the effect of the distillation objective from the source of the labels would strengthen the interpretation. In the revised manuscript we will add an SFT baseline trained on the identical teacher-generated hard responses (and, where relevant, soft logits) using the same optimizer, schedule, and data volume as the corresponding KD runs. This addition will allow readers to distinguish label-distribution effects from the benefits of the KD loss and will directly support the claim regarding inaccessible knowledge. revision: yes
-
Referee: [§3] §3 (experimental setup): The description of data splits, teacher/student model pairs, and statistical significance testing is insufficient to assess whether the reported trends (low-data advantage, restoration by stronger teacher) are robust to random seeds or hyperparameter choices. Explicit reporting of these controls is required to support the scaling claims.
Authors: We acknowledge that Section 3 requires additional detail to demonstrate robustness. In the revision we will expand the experimental setup to specify: (i) exact data-split proportions and sampling procedure for each low-data regime, (ii) the complete list of teacher and student model pairs with sizes and instruction-tuning status, and (iii) the statistical testing protocol, including the number of random seeds, variance reporting, and hyperparameter sensitivity checks. These additions will make the scaling trends reproducible and will address concerns about seed or hyperparameter dependence. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential reductions
full rationale
The paper conducts a systematic empirical study comparing KD and SFT on the Tulu 3 dataset across data regimes, reporting observed performance differences without any equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce claims to inputs by construction. All central claims rest on direct experimental outcomes (e.g., KD advantage in low-data settings diminishing with more data, restored by stronger teachers), which are externally falsifiable via replication on the stated dataset and models. No self-definitional loops, ansatz smuggling, or uniqueness theorems appear in the provided abstract or described methodology.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard i.i.d. sampling and optimization assumptions in supervised fine-tuning and distillation experiments
Reference graph
Works this paper leans on
-
[1]
Winning Big with Small Models: Knowledge Distillation vs
Ashley Lewis and Michael White and Jing Liu and Toshiaki Koike. Winning Big with Small Models: Knowledge Distillation vs. Self-Training for Reducing Hallucination in. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.19545 , eprinttype =. 2502.19545 , timestamp =
-
[2]
Anup Shirgaonkar and Nikhil Pandey and Nazmiye Ceren Abay and Tolga Aktas and Vijay Aski , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.18588 , eprinttype =. 2410.18588 , timestamp =
-
[3]
OpenAssistant Conversations - Democratizing Large Language Model Alignment , booktitle =
Andreas K. OpenAssistant Conversations - Democratizing Large Language Model Alignment , booktitle =. 2023 , url =
2023
-
[4]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[5]
Long Ouyang and Jeffrey Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul F. Christiano and Jan Leike and Ryan Lowe , editor =...
2022
-
[6]
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. CoRR , volume =. 2018 , url =. 1803.05457 , timestamp =
Pith/arXiv arXiv 2018
-
[7]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[8]
D ialog S um: A real-life scenario dialogue summarization dataset
Yulong Chen and Yang Liu and Liang Chen and Yue Zhang , editor =. DialogSum:. Findings of the Association for Computational Linguistics:. 2021 , url =. doi:10.18653/V1/2021.FINDINGS-ACL.449 , timestamp =
-
[9]
Proceedings of the Seventh Conference on Machine Translation,
Ricardo Rei and Jos. Proceedings of the Seventh Conference on Machine Translation,. 2022 , url =
2022
-
[10]
Le and Dhruv Madeka and Lei Li and William Yang Wang and Rishabh Agarwal and Chen
Wenda Xu and Rujun Han and Zifeng Wang and Long T. Le and Dhruv Madeka and Lei Li and William Yang Wang and Rishabh Agarwal and Chen. Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved Sampling , booktitle =. 2025 , url =
2025
-
[11]
Marta R. Costa. No Language Left Behind: Scaling Human-Centered Machine Translation , journal =. 2022 , url =. doi:10.48550/ARXIV.2207.04672 , eprinttype =. 2207.04672 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.04672 2022
-
[12]
MMLU-Pro:
Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shiguang Guo and Weiming Ren and Aaran Arulraj and Xuan He and Ziyan Jiang and Tianle Li and Max Ku and Kai Wang and Alex Zhuang and Rongqi Fan and Xiang Yue and Wenhu Chen , editor =. MMLU-Pro:. Advances in Neural Information Processing Systems 38: Annual Conference on Neura...
2024
-
[13]
I n F o B ench: Evaluating Instruction Following Ability in Large Language Models
Yiwei Qin and Kaiqiang Song and Yebowen Hu and Wenlin Yao and Sangwoo Cho and Xiaoyang Wang and Xuansheng Wu and Fei Liu and Pengfei Liu and Dong Yu , editor =. InFoBench: Evaluating Instruction Following Ability in Large Language Models , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-ACL.772 , timestamp =
-
[14]
2023 , eprint=
Instruction-Following Evaluation for Large Language Models , author=. 2023 , eprint=
2023
-
[15]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2311.12022 , eprinttype =. 2311.12022 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.12022 2023
-
[16]
Brown and Adam Santoro and Aditya Gupta and Adri
Aarohi Srivastava and Abhinav Rastogi and Abhishek Rao and Abu Awal Md Shoeb and Abubakar Abid and Adam Fisch and Adam R. Brown and Adam Santoro and Aditya Gupta and Adri. Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models , journal =. 2023 , url =
2023
-
[17]
On the Generalization vs Fidelity Paradox in Knowledge Distillation , booktitle =
Suhas Kamasetty Ramesh and Ayan Sengupta and Tanmoy Chakraborty , editor =. On the Generalization vs Fidelity Paradox in Knowledge Distillation , booktitle =. 2025 , url =
2025
-
[18]
Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al. The Llama 3 Herd of Models , journal =. 2024 , url =. doi:10.48550/ARXIV.2407.21783 , eprinttype =. 2407.21783 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[19]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert and Jacob Morrison and Valentina Pyatkin and Shengyi Huang and Hamish Ivison and Faeze Brahman and Lester James V. Miranda and Alisa Liu and Nouha Dziri and Shane Lyu and Yuling Gu and Saumya Malik and Victoria Graf and Jena D. Hwang and Jiangjiang Yang and Ronan Le Bras and Oyvind Tafjord and Chris Wilhelm and Luca Soldaini and Noah A. Smi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.15124 2024
-
[20]
Direct Preference Knowledge Distillation for Large Language Models , url =
Yixing Li and Yuxian Gu and Li Dong and Dequan Wang and Yu Cheng and Furu Wei , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2406.19774 , eprinttype =. 2406.19774 , timestamp =
-
[21]
The Twelfth International Conference on Learning Representations,
Rishabh Agarwal and Nino Vieillard and Yongchao Zhou and Piotr Stanczyk and Sabela Ramos Garea and Matthieu Geist and Olivier Bachem , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[22]
The Twelfth International Conference on Learning Representations,
Yuxian Gu and Li Dong and Furu Wei and Minlie Huang , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[23]
Sequence-Level Knowledge Distillation
Yoon Kim and Alexander M. Rush , editor =. Sequence-Level Knowledge Distillation , booktitle =. 2016 , url =. doi:10.18653/V1/D16-1139 , timestamp =
-
[24]
Hinton and Oriol Vinyals and Jeffrey Dean , title =
Geoffrey E. Hinton and Oriol Vinyals and Jeffrey Dean , title =. CoRR , volume =. 2015 , url =. 1503.02531 , timestamp =
Pith/arXiv arXiv 2015
-
[25]
OpenAI , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2303.08774 , eprinttype =. 2303.08774 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[26]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jian Yang and Jiaxi Yang and Ji...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[27]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , journal =. 2025 , url =. doi:10.48550/ARXIV.2501.12948 , eprinttype =. 2501.12948 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[28]
arXiv preprint arXiv:1511.05101 , year =
How (not) to Train your Generative Model: Scheduled Sampling, Likelihood, Adversary? , author =. arXiv preprint arXiv:1511.05101 , year =. 1511.05101 , archiveprefix =
-
[29]
arXiv preprint arXiv:2412.15115 , year =
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =. 2412.15115 , archiveprefix =
-
[30]
Data-Efficient Knowledge Distillation for Supervised Fine-Tuning with
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.