A Study of Temporal Fusion Strategies for Named Entity Recognition in Historical Texts
Pith reviewed 2026-06-29 04:49 UTC · model grok-4.3
The pith
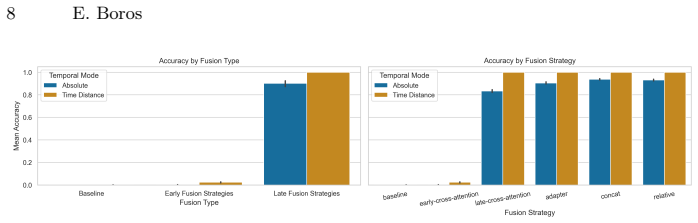
Late fusion of temporal metadata yields more robust NER performance on historical texts than early fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
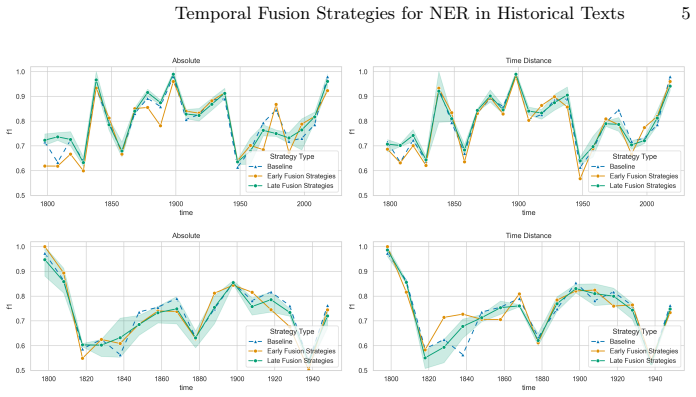
Late fusion strategies for injecting absolute or relative temporal representations into Transformer-based NER architectures produce more robust and temporally generalisable performance than early fusion, with the advantage most visible on early and noisy portions of French and German historical datasets.
What carries the argument
Late fusion mechanisms (cross-attention, adapters, concatenation) that add temporal metadata after the main Transformer layers rather than at the input.
If this is right
- Late fusion improves robustness on diachronic NER tasks.
- Gains concentrate in the earliest and noisiest time periods.
- Both absolute and relative temporal encodings work with late fusion.
- The benefit appears across both French and German historical collections.
- Lightweight adapters and cross-attention suffice; no full retraining of the base model is required.
Where Pith is reading between the lines
- The same late-fusion pattern could be tested on other sequence labelling tasks that cross time periods, such as event detection.
- If temporal labels are only partially available, late fusion may still allow the model to fall back to the text-only path more gracefully than early fusion.
- Extending the approach to decade-level or event-linked time representations might further reduce reliance on coarse period labels.
Load-bearing premise
The supplied temporal metadata for the historical datasets is accurate enough that fusion lets the model reason about time instead of simply memorising dataset patterns.
What would settle it
Run the same models after randomly shuffling or deleting the temporal metadata labels and measure whether late fusion still outperforms early fusion and the no-metadata baseline.
Figures
read the original abstract
Temporal variation poses a unique challenge for named entity recognition (NER) in historical texts, where entities drift in surface form and salience across time. While language models (LMs) have made progress in various NLP tasks, their ability to reason about temporality, especially in diachronic contexts, remains limited or at least, questionable. In this paper, we systematically study how temporal metadata can be structurally embedded into NER models using a range of lightweight fusion strategies. We experiment with both absolute and relative temporal representations, injected into Transformer-based architectures via early or late fusion mechanisms such as cross-attention, adapters, and concatenation. Our evaluations on French and German historical datasets reveal that late fusion strategies yield more robust and temporally generalisable performance, particularly in early and noisy periods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that temporal metadata can be effectively embedded into Transformer-based NER models for historical texts via lightweight fusion strategies (early/late fusion using cross-attention, adapters, and concatenation, with both absolute and relative temporal representations). Systematic experiments on French and German historical datasets show that late fusion strategies produce more robust and temporally generalisable NER performance, especially in early and noisy time periods.
Significance. If the central empirical claim holds after addressing controls, the work provides a useful comparative study of fusion mechanisms for incorporating temporal signals in diachronic NER. It offers concrete guidance on preferring late fusion for better generalization across time in historical corpora, which addresses a practical challenge in applying LMs to texts with entity drift. The systematic comparison of multiple strategies is a positive aspect of the experimental design.
major comments (1)
- [Experimental Design / Results] Experimental section: the design does not include a negative control (e.g., shuffling or ablating temporal metadata while preserving all other inputs, architecture, and splits) to test whether observed gains in early/noisy periods reflect genuine exploitation of temporality or merely fitting to dataset-specific artifacts correlated with the splits. This directly undermines the claim that late fusion enables 'temporally generalisable performance' and matches the weakest assumption in the evaluation.
minor comments (1)
- [Abstract / Results] Abstract and results tables should report dataset sizes, number of periods, baseline comparisons, and statistical significance tests to allow readers to assess the magnitude and reliability of the late-fusion advantage.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below and will revise the manuscript accordingly to strengthen the experimental controls.
read point-by-point responses
-
Referee: [Experimental Design / Results] Experimental section: the design does not include a negative control (e.g., shuffling or ablating temporal metadata while preserving all other inputs, architecture, and splits) to test whether observed gains in early/noisy periods reflect genuine exploitation of temporality or merely fitting to dataset-specific artifacts correlated with the splits. This directly undermines the claim that late fusion enables 'temporally generalisable performance' and matches the weakest assumption in the evaluation.
Authors: We agree that a negative control (e.g., shuffling temporal metadata while keeping all other inputs and splits fixed) is necessary to isolate whether gains stem from genuine temporal signal exploitation rather than split-correlated artifacts. We will add these ablation experiments to the revised experimental section and update the claims about temporal generalisability to reflect the new results. revision: yes
Circularity Check
No circularity: purely empirical comparison of fusion strategies
full rationale
The paper presents an empirical study comparing early/late fusion mechanisms (cross-attention, adapters, concatenation) on French/German historical NER datasets using temporal metadata. No equations, derivations, or parameter-fitting steps are described that could reduce a claimed result to its own inputs by construction. The central claim (late fusion yields better temporal generalization) rests on reported performance metrics rather than any self-definitional, fitted-prediction, or self-citation load-bearing structure. External benchmarks (dataset splits, fusion variants) remain independent of the reported outcomes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Transformer architectures can incorporate metadata via cross-attention, adapters, or concatenation without breaking core functionality.
- domain assumption Temporal metadata for the historical texts is reliable and correctly aligned with the documents.
Reference graph
Works this paper leans on
-
[1]
Agarwal, P., Strötgen, J., del Corro, L., Hoffart, J., Weikum, G.: di- aned: Time-aware named entity disambiguation for diachronic corpora (2018), https://www.aclweb.org/anthology/P18-2109/
2018
- [2]
-
[3]
In: Proceedings of the 24th conference on computational natural language learning
Boros, E., Hamdi, A., Pontes, E.L., Cabrera-Diego, L.A., Moreno, J.G., Sidere, N., Doucet, A.: Alleviating digitization errors in named entity recognition for histor- ical documents. In: Proceedings of the 24th conference on computational natural language learning. pp. 431–441 (2020)
2020
- [4]
-
[5]
In: Proceedings of the Ninth International Workshop on Natural Language Processing for Social Media
Chen, S., Neves, L., Solorio, T.: Mitigating temporal-drift: A sim- ple approach to keep NER models crisp. In: Proceedings of the Ninth International Workshop on Natural Language Processing for Social Media. pp. 163–169. Association for Computational Linguis- tics, Online (Jun 2021). https://doi.org/10.18653/v1/2021.socialnlp-1.14, https://www.aclweb.org/...
-
[6]
https://doi.org/10.1162/tacl_a_00459, https://aclanthology.org/2022.tacl-1.15/
Cole, J.R.: Time-aware language models as temporal knowledge bases (2022). https://doi.org/10.1162/tacl_a_00459, https://aclanthology.org/2022.tacl-1.15/
- [7]
-
[8]
Ehrmann, M., Romanello, M., Bircher, S., Clematide, S.: Introducing the clef 2020 hipe shared task: Named entity recognition and linking on historical newspapers. (2020). https://doi.org/10.1007/978-3-030-45442-5_68, https://doi.org/10.1007/978-3-030-45442-5_68
-
[9]
Ehrmann, M., Romanello, M., Doucet, A., Clematide, S.: Introducing the hipe 2022 shared task: Named entity recognition and linking in multilin- gual historical documents. (2022). https://doi.org/10.1007/978-3-030-99739-7_44, https://doi.org/10.1007/978-3-030-99739-7_44 10 E. Boros
-
[10]
In: Faggioli, G., Ferro, N., Han- bury, A., Potthast, M
Ehrmann, M., Romanello, M., Najem-Meyer, S., Doucet, A., Clematide, S.: Extended overview of HIPE-2022: Named Entity Recognition and Link- ing in Multilingual Historical Documents. In: Faggioli, G., Ferro, N., Han- bury, A., Potthast, M. (eds.) Proceedings of the Working Notes of CLEF 2022 - Conference and Labs of the Evaluation Forum. vol. 3180. CEUR- WS...
- [11]
-
[12]
González-Gallardo, C.E., Boros, E., Giamphy, E., Hamdi, A., Moreno, J.G., Doucet, A.: Injecting temporal-aware knowledge in historical named entity recognition. (2023). https://doi.org/10.1007/978-3-031-28244-7_24, https://doi.org/10.1007/978-3-031-28244-7_24
- [13]
-
[14]
Gurnee, W., Tegmark, M.: Language models represent space and time (2024), https://openreview.net/forum?id=jE8xbmvFin
2024
-
[15]
a humanities informed approach (2025), https://arxiv.org/abs/2502.04351
Hiltmann, T., Dröge, M., Dresselhaus, N., Grallert, T., Althage, M., Bayer, P., Eckenstaler, S., Mendi, K., Schmitz, J.M., Schneider, P., Sczeponik, W., Skibba, A.: Ner4all or context is all you need: Using llms for low-effort, high- performance ner on historical texts. a humanities informed approach (2025), https://arxiv.org/abs/2502.04351
-
[16]
Jain, R., Sojitra, D., Acharya, A., Saha, S., Jatowt, A., Dandapat, S.: Do language models have a common sense regarding time? revisiting tem- poral commonsense reasoning in the era of large language models (2023), https://aclanthology.org/2023.emnlp-main.418/
2023
-
[17]
Jia, Z., Abujabal, A., Roy, R.S., Strötgen, J., Weikum, G.: Tempquestions: A benchmark for temporal question answering. (2018). https://doi.org/10.1145/3184558.3191536, https://doi.org/10.1145/3184558.3191536
-
[18]
Ko, D., Lee, J.S., Kang, W., Roh, B., Kim, H.J.: Large language mod- els are temporal and causal reasoners for video question answering (2023), https://aclanthology.org/2023.emnlp-main.261/
2023
-
[19]
Dynamic, and Multimodal (2022)
Liang, K., Meng, L., Liu, M., Liu, Y., Tu, W., Wang, S., Zhou, S., Liu, X., Sun, F.: A survey of knowledge graph reasoning on graph types: Static. Dynamic, and Multimodal (2022)
2022
- [20]
-
[21]
Liu, R., Li, C., Tang, H., Ge, Y., Shan, Y., Li, G.: St-llm: Large language models are effective temporal learners (2024)
2024
-
[22]
In: Pro- ceedings of the AAAIConference on Artificial Intelligence.vol
Lu, Y., Zhou, Y., Li, J., Wang, Y., Liu, X., He, D., Liu, F., Zhang, M.: Knowledge editing with dynamic knowledge graphs for multi-hop question answering. In: Pro- ceedings of the AAAIConference on Artificial Intelligence.vol. 39, pp. 24741–24749 (2025)
2025
- [23]
- [24]
-
[25]
Papadopoulos, V., Wenger, J., Hongler, C.: Arrows of time for large language models (2024), https://openreview.net/forum?id=UpSe7ag34v
2024
-
[26]
Pawłowski, A., Walkowiak, T.: Nlp for digital humanities: Processing chronological text corpora (2024), https://aclanthology.org/2024.nlp4dh-1.10/
2024
-
[27]
In: Proceedings of the AAAI conference on artificial intelligence
Perez, E., Strub, F., De Vries, H., Dumoulin, V., Courville, A.: Film: Visual rea- soning with a general conditioning layer. In: Proceedings of the AAAI conference on artificial intelligence. vol. 32 (2018)
2018
- [28]
-
[29]
Rijhwani, S., Preotiuc-Pietro, D.: Temporally-informed analysis of named entity recognition (2020), https://www.aclweb.org/anthology/2020.acl-main.680/
2020
-
[30]
In: Proceedings of the fifteenth ACM international conference on Web search and data mining
Rosin, G.D., Guy, I., Radinsky, K.: Time masking for temporal language models. In: Proceedings of the fifteenth ACM international conference on Web search and data mining. pp. 833–841 (2022)
2022
- [31]
- [32]
-
[33]
In: Rogers, A., Boyd-Graber, J., Okazaki, N
Song, R., He, S., Gao, S., Cai, L., Liu, K., Yu, Z., Zhao, J.: Multi- lingual knowledge graph completion from pretrained language models with knowledge constraints. In: Rogers, A., Boyd-Graber, J., Okazaki, N. (eds.) Findings of the Association for Computational Linguistics: ACL
-
[34]
pp. 7709–7721. Association for Computational Linguistics, Toronto, Canada (Jul 2023). https://doi.org/10.18653/v1/2023.findings-acl.488, https://aclanthology.org/2023.findings-acl.488/
- [35]
-
[36]
In: Bastings, J., Belinkov, Y., Dupoux, E., Giulianelli, M., Hupkes, D., Pinter, Y., Sajjad, H
Thukral, S., Kukreja, K., Kavouras, C.: Probing language models for under- standing of temporal expressions. In: Bastings, J., Belinkov, Y., Dupoux, E., Giulianelli, M., Hupkes, D., Pinter, Y., Sajjad, H. (eds.) Proceedings of the Fourth BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP. pp. 396–406. Association for Computational ...
-
[37]
Ushio, A., Barbieri, F., Sousa, V., Neves, L., Camacho-Collados, J.: Named entity recognition in twitter: A dataset and analysis on short-term temporal shifts (2022), https://aclanthology.org/2022.aacl-main.25/
2022
- [38]
-
[39]
Xiong, S., Payani, A., Kompella, R., Fekri, F.: Large language models can learn temporal reasoning (2024), https://aclanthology.org/2024.acl-long.563/
2024
- [40]
- [41]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.