The Power of Light: Improving Synthetic-to-Real Domain Adaptation through Physically-Based Indirect Illumination
Pith reviewed 2026-06-26 11:08 UTC · model grok-4.3
The pith
Indirect lighting and relevant backgrounds in synthetic data narrow the gap to real images for object detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that complex, indirect lighting configurations paired with domain-relevant background variability significantly increase visual cue richness, mitigate the domain gap, reduce false positives, and accelerate model convergence compared to using conventional direct-light synthetic data.
What carries the argument
Physically-based shading applied to controlled variations in lighting and background within an automated synthetic data generation pipeline.
If this is right
- Avoiding direct specular peaks preserves surface textures needed for recognition.
- Indirect lighting increases the number of usable visual cues in each training image.
- The combination of lighting and background reduces the mismatch between synthetic and real images.
- Fewer false positives appear when models are tested on real scenes.
- Training reaches good performance in fewer steps than with direct-light data.
Where Pith is reading between the lines
- The same lighting principles could apply to synthetic data for segmentation or pose estimation tasks.
- Simulation software might benefit from defaulting to physically accurate indirect light rather than simple direct sources.
- The results suggest testing whether these gains hold when dataset size or object variety changes independently.
Load-bearing premise
The experiments isolate lighting and background effects from other variables such as model settings or exact scene composition.
What would settle it
Retraining the detector on indirect-light synthetic data but with mismatched backgrounds and seeing no gain over direct-light data would challenge the claim that the two factors must be paired.
Figures

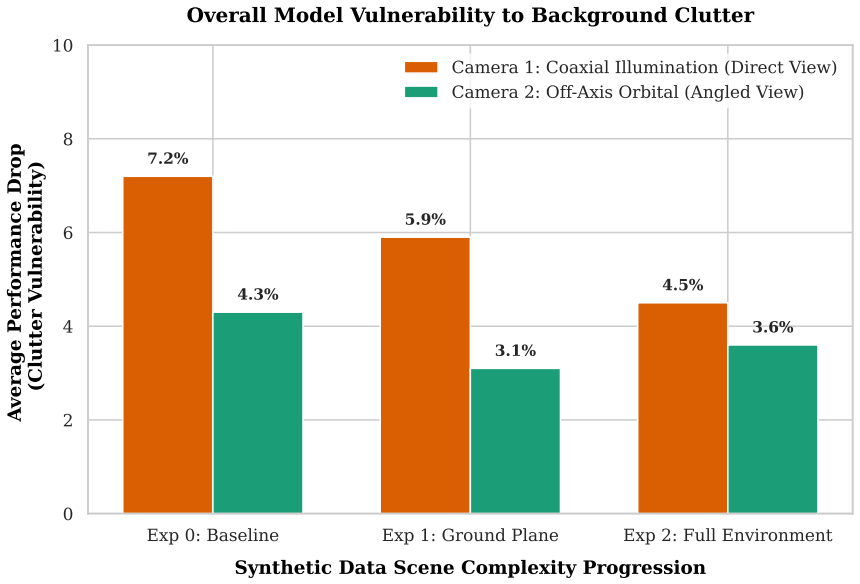
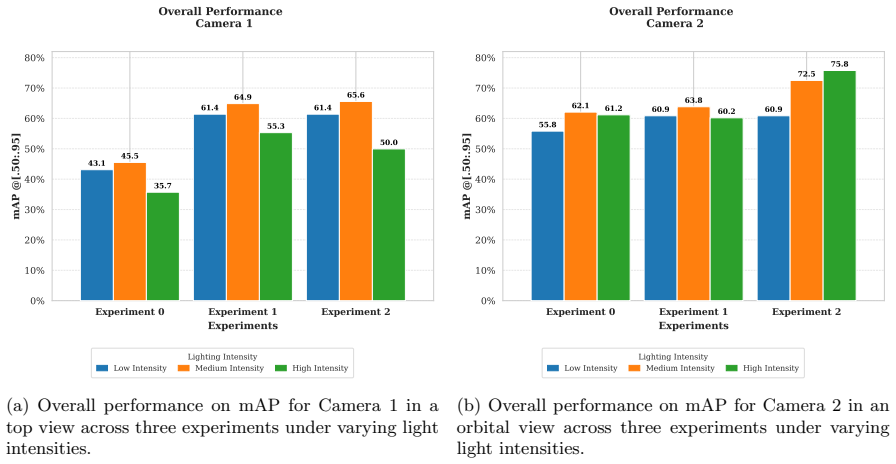
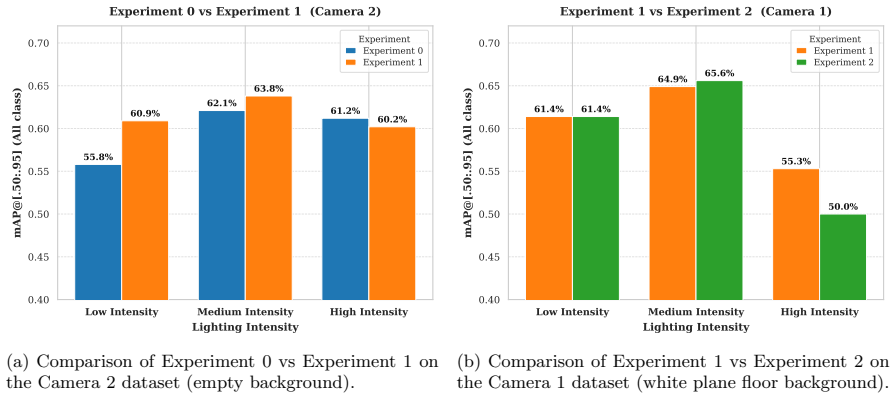
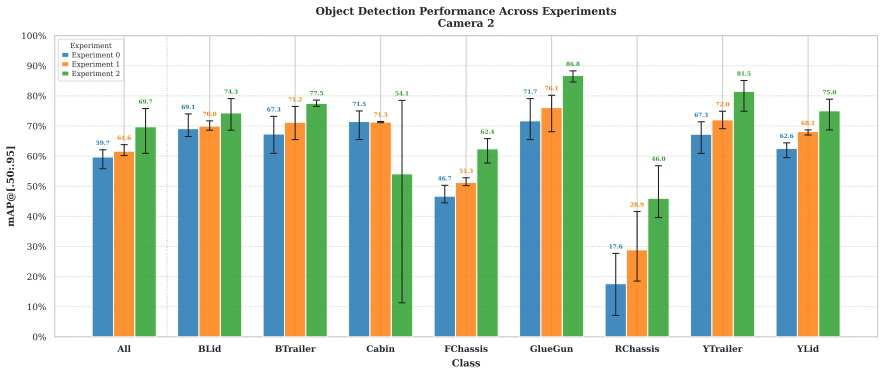


read the original abstract
While synthetic data generation resolves the manual labeling bottleneck in computer vision, minimizing the syn-to-real domain gap requires optimizing rendering variables. This paper presents a systematic study analyzing the impact of lighting configurations and background complexity on object detection performance. We introduce SmartSDG, an automated, reproducible pipeline built on NVIDIA Isaac Sim using Physically-Based Shading (PBS), alongside ILLUM\_INTRUCK, a new multi-object industrial benchmark dataset. Through 18 controlled experiments utilizing a state-of-the-art YOLOv12 framework, we demonstrate that complex, indirect lighting configurations paired with domain-relevant background variability significantly increase visual cue richness. Our quantitative findings show that avoiding direct specular peaks preserves crucial surface textures, mitigates the domain gap, reduces false positives, and accelerates model convergence compared to using conventional direct-light synthetic data. Ultimately, we provide actionable virtual scene design guidelines to maximize object detection robustness in industrial automation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that complex indirect lighting configurations combined with domain-relevant background variability in physically-based synthetic data generation (via the SmartSDG pipeline on NVIDIA Isaac Sim) significantly improve object detection performance on real data compared to conventional direct-light synthetic data. This is demonstrated through 18 controlled experiments using YOLOv12 on the new ILLUM_INTRUCK industrial benchmark dataset, with reported benefits including increased visual cue richness, reduced false positives, faster model convergence, and mitigation of the synthetic-to-real domain gap; the work concludes with actionable virtual scene design guidelines.
Significance. If the experimental isolation of lighting and background effects holds, the result would provide concrete, reproducible guidance for synthetic data pipelines in industrial computer vision, emphasizing physically accurate indirect illumination over simpler direct-light setups. The introduction of an automated pipeline and a new multi-object benchmark dataset adds practical value for the community.
major comments (2)
- [Abstract and Experiments section] The description of the 18 experiments (referenced in the abstract and methods) does not explicitly confirm that training-set cardinality, object density/placement statistics, and camera/viewpoint sampling distributions are held fixed across the direct-light versus indirect-light conditions. Without this verification, performance differences cannot be unambiguously attributed to PBS indirect illumination rather than incidental variations in data volume or diversity, which is load-bearing for the central causal claim.
- [Abstract and Results] Quantitative results from the 18 experiments are presented without reported statistical significance tests, error bars, exact hyperparameter controls for YOLOv12, or per-condition image counts. This absence prevents assessment of whether observed reductions in false positives and faster convergence are robust or could arise from uncontrolled factors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental controls and statistical reporting. These comments help strengthen the clarity of our causal claims. We address each point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract and Experiments section] The description of the 18 experiments (referenced in the abstract and methods) does not explicitly confirm that training-set cardinality, object density/placement statistics, and camera/viewpoint sampling distributions are held fixed across the direct-light versus indirect-light conditions. Without this verification, performance differences cannot be unambiguously attributed to PBS indirect illumination rather than incidental variations in data volume or diversity, which is load-bearing for the central causal claim.
Authors: We agree that explicit verification is essential to support the central claim. The 18 experiments were conducted with fixed training-set cardinality, identical object density/placement statistics (via the same procedural generation rules in SmartSDG), and matched camera/viewpoint sampling distributions across all direct-light and indirect-light conditions; only the illumination model and background variability were varied. These controls are inherent to the pipeline described in the Methods but were not stated with sufficient explicitness. We will revise the Experiments section to include a dedicated paragraph and summary table confirming the fixed parameters. revision: yes
-
Referee: [Abstract and Results] Quantitative results from the 18 experiments are presented without reported statistical significance tests, error bars, exact hyperparameter controls for YOLOv12, or per-condition image counts. This absence prevents assessment of whether observed reductions in false positives and faster convergence are robust or could arise from uncontrolled factors.
Authors: We acknowledge that the current presentation lacks the requested statistical and control details. In the revised manuscript we will add error bars from multiple independent runs, report results of statistical significance tests (e.g., paired t-tests or Wilcoxon tests) comparing conditions, list the exact YOLOv12 hyperparameters (learning rate, batch size, epochs, etc.), and provide a table of per-condition image counts. These additions will allow readers to evaluate the robustness of the reported improvements in false-positive reduction and convergence speed. revision: yes
Circularity Check
No derivation chain present; purely empirical comparison
full rationale
The manuscript describes an empirical study consisting of 18 controlled experiments that compare object detection performance across different synthetic rendering configurations (direct vs. indirect lighting, background variability) using YOLOv12 on held-out real data. No equations, fitted parameters, predictions derived from models, uniqueness theorems, or ansatzes are presented. The central claims rest on direct measurement of metrics such as false positives and convergence speed rather than any reduction of outputs to inputs by construction. Self-citations, if present, are not load-bearing for any derivation. This is a standard empirical ablation study with no circularity risk.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Pick and place robotic arm: a review paper.Int
Sharath Surati, Shaunak Hedaoo, Tushar Rotti, Vaibhav Ahuja, and Nishigandha Patel. Pick and place robotic arm: a review paper.Int. Res. J. Eng. Technol, 8(2):2121–2129, 2021
2021
-
[3]
Autonomous object detection and grasping using deep learning for design of an intelligent assistive robot manipulation system
Sanzhar Rakhimkul, Anton Kim, Askarbek Pazylbekov, and Almas Shintemirov. Autonomous object detection and grasping using deep learning for design of an intelligent assistive robot manipulation system. In2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), pages 3962–3968. IEEE, 2019
2019
-
[4]
Vision-based robotic arm control algorithm using deep reinforcement learning for autonomous objects grasping.Applied Sciences, 11(17):7917, 2021
Hiba Sekkat, Smail Tigani, Rachid Saadane, and Abdellah Chehri. Vision-based robotic arm control algorithm using deep reinforcement learning for autonomous objects grasping.Applied Sciences, 11(17):7917, 2021
2021
-
[5]
You only look once: Unified, real-time object detection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016
2016
-
[6]
Yolov12: Attention-centric real-time object detectors.arXiv preprint arXiv:2502.12524, 2025
Yunjie Tian, Qixiang Ye, and David Doermann. Yolov12: Attention-centric real-time object detectors.arXiv preprint arXiv:2502.12524, 2025
Pith/arXiv arXiv 2025
-
[7]
A short survey on modern virtual environments that utilize ai and synthetic data
Michalis Korakakis, Phivos Mylonas, and Evaggelos Spyrou. A short survey on modern virtual environments that utilize ai and synthetic data. 2018
2018
-
[8]
Hooman Tavakoli, Snehal Walunj, Parsha Pahlevannejad, Christiane Plociennik, and Martin Ruskowski. Small object detection for near real-time egocentric perception in a manual assembly scenario.arXiv preprint arXiv:2106.06403, 2021
arXiv 2021
-
[9]
The eurocity persons dataset: A novel benchmark for object detection
M Braun, S Krebs, F Flohr, and DM Gavrila. The eurocity persons dataset: A novel benchmark for object detection. arxiv 2018.arXiv preprint arXiv:1805.07193
Pith/arXiv arXiv 2018
-
[10]
Deflating dataset bias using synthetic data augmentation
Nikita Jaipuria, Xianling Zhang, Rohan Bhasin, Mayar Arafa, Punarjay Chakravarty, Shubham Shrivastava, Sagar Manglani, and Vidya N Murali. Deflating dataset bias using synthetic data augmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition workshops, pages 772–773, 2020
2020
-
[11]
Synthetic data and active learning for efficient object detection
Hooman Tavakoli Ghinani, Nimesh Singh, Tatjana Legler, Achim Wagner, and Martin Ruskowski. Synthetic data and active learning for efficient object detection. InInternational Conference on Advanced Information Systems Engineering, pages 338–350. Springer, 2025
2025
-
[12]
A survey of image synthesis methods for visual machine learning
Apostolia Tsirikoglou, Gabriel Eilertsen, and Jonas Unger. A survey of image synthesis methods for visual machine learning. InComputer graphics forum, volume 39, pages 426–451. Wiley Online Library, 2020
2020
-
[13]
Xiaomeng Zhu, Jacob Henningsson, Duruo Li, P¨ ar M˚ artensson, Lars Hanson, M˚ arten Bj¨ orkman, and Atsuto Maki. Domain randomization for object detection in manufacturing applications using synthetic data: A comprehensive study.arXiv preprint arXiv:2506.07539, 2025
arXiv 2025
-
[14]
Db-gan: Boosting object recognition under strong lighting conditions
Luca Minciullo, Fabian Manhardt, Kei Yoshikawa, Sven Meier, Federico Tombari, and Norimasa Kobori. Db-gan: Boosting object recognition under strong lighting conditions. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2939–2949, 2021
2021
-
[15]
Isaac Sim
NVIDIA. Isaac Sim. URLhttps://github.com/isaac-sim/IsaacSim
-
[16]
Smartfactory-kl introduces the future of production: Production Level 4.https://www.dfki.de/en/web/news/smartfactory-kl-production-level-4-en, Jun 2024
SmartFactory-KL. Smartfactory-kl introduces the future of production: Production Level 4.https://www.dfki.de/en/web/news/smartfactory-kl-production-level-4-en, Jun 2024. Accessed: 2025-10-07. 17
2024
-
[17]
Detlef Zuehlke. Smartfactory – from vision to reality in factory technologies.IFAC Pro- ceedings Volumes, 41(2):14101–14108, 2008. ISSN 1474-6670. doi: https://doi.org/10.3182/ 20080706-5-KR-1001.02391. URLhttps://www.sciencedirect.com/science/article/pii/ S1474667016412565. 17th IFAC World Congress
arXiv 2008
-
[18]
Adam Westerski and Wee Teck Fong. Synthetic data for object detection with neural networks: state-of-the-art survey of domain randomisation techniques.ACM Transactions on Multimedia Computing, Communications and Applications, 21(1):1–20, 2024
2024
-
[19]
Matthew Johnson-Roberson, Charles Barto, Rounak Mehta, Sharath Nittur Sridhar, Karl Rosaen, and Ram Vasudevan. Driving in the matrix: Can virtual worlds replace human-generated anno- tations for real world tasks?arXiv preprint arXiv:1610.01983, 2016
Pith/arXiv arXiv 2016
-
[20]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. InConference on Computer Vision and Pattern Recognition (CVPR), 2012
2012
-
[21]
Training deep networks with synthetic data: Bridging the reality gap by domain randomization
Jonathan Tremblay, Aayush Prakash, David Acuna, Mark Brophy, Varun Jampani, Cem Anil, Thang To, Eric Cameracci, Shaad Boochoon, and Stan Birchfield. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2018
2018
-
[22]
Cut, paste and learn: Surprisingly easy synthesis for instance detection
Debidatta Dwibedi, Ishan Misra, and Martial Hebert. Cut, paste and learn: Surprisingly easy synthesis for instance detection. InProceedings of the IEEE international conference on computer vision, pages 1301–1310, 2017
2017
-
[23]
On pre-trained image features and synthetic images for deep learning
Stefan Hinterstoisser, Vincent Lepetit, Paul Wohlhart, and Kurt Konolige. On pre-trained image features and synthetic images for deep learning. InProceedings of the European Conference on Computer Vision (ECCV) Workshops, pages 0–0, 2018
2018
-
[24]
Fernando Camaro Nogues, Andrew Huie, and Sakyasingha Dasgupta. Object detection using domain randomization and generative adversarial refinement of synthetic images.arXiv preprint arXiv:1805.11778, 2018
Pith/arXiv arXiv 2018
-
[25]
An annotation saved is an annotation earned: Using fully synthetic training for object detection
Stefan Hinterstoisser, Olivier Pauly, Hauke Heibel, Marek Martina, and Martin Bokeloh. An annotation saved is an annotation earned: Using fully synthetic training for object detection. In Proceedings of the IEEE/CVF international conference on computer vision workshops, pages 0–0, 2019
2019
-
[26]
Synscapes: A photorealistic synthetic dataset for street scene parsing
Magnus Wrenninge and Jonas Unger. Synscapes: A photorealistic synthetic dataset for street scene parsing. arxiv 2018.arXiv preprint arXiv:1810.08705, 1810
Pith/arXiv arXiv 2018
-
[27]
The rendering equation
James T Kajiya. The rendering equation. InProceedings of the 13th annual conference on Computer graphics and interactive techniques, pages 143–150, 1986
1986
-
[28]
Dominik Schraml and Gunther Notni. Synthetic training data in ai-driven quality inspection: The significance of camera, lighting, and noise parameters.Sensors, 24(2), 2024. ISSN 1424-8220. doi: 10.3390/s24020649. URLhttps://www.mdpi.com/1424-8220/24/2/649
-
[29]
Generating images with physics-based rendering for an industrial object detection task: Realism versus domain randomization.Sensors, 21(23):7901, 2021
Leon Eversberg and Jens Lambrecht. Generating images with physics-based rendering for an industrial object detection task: Realism versus domain randomization.Sensors, 21(23):7901, 2021
2021
-
[30]
Unity perception: generate synthetic data for computer vision.arXiv preprint arXiv:2107.04259, 2021
Steve Borkman, Adam Crespi, Saurav Dhakad, Sujoy Ganguly, Jonathan Hogins, You-Cyuan Jhang, Mohsen Kamalzadeh, Bowen Li, Steven Leal, Pete Parisi, et al. Unity perception: generate synthetic data for computer vision.arXiv preprint arXiv:2107.04259, 2021
arXiv 2021
-
[31]
Domain randomization-enhanced deep learning models for bird detection.Scientific reports, 11(1):639, 2021
Xin Mao, Jun Kang Chow, Pin Siang Tan, Kuan-fu Liu, Jimmy Wu, Zhaoyu Su, Ye Hur Cheong, Ghee Leng Ooi, Chun Chiu Pang, and Yu-Hsing Wang. Domain randomization-enhanced deep learning models for bird detection.Scientific reports, 11(1):639, 2021
2021
-
[32]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014. 18
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.