SAMA: Semantic Anchor-aligned Augmentation for Unified Low-Resource Multimodal Information Extraction
Pith reviewed 2026-06-26 21:13 UTC · model grok-4.3
The pith
SAMA generates synthetic multimodal data aligned to semantic anchors from ground-truth labels, enabling unified augmentation for low-resource MNER, MRE, and MEE.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
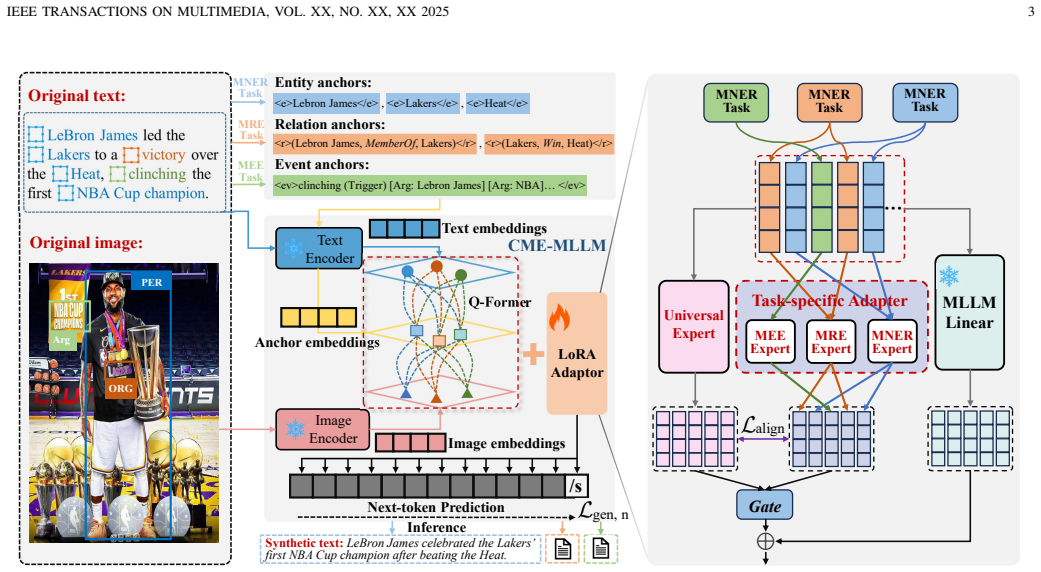
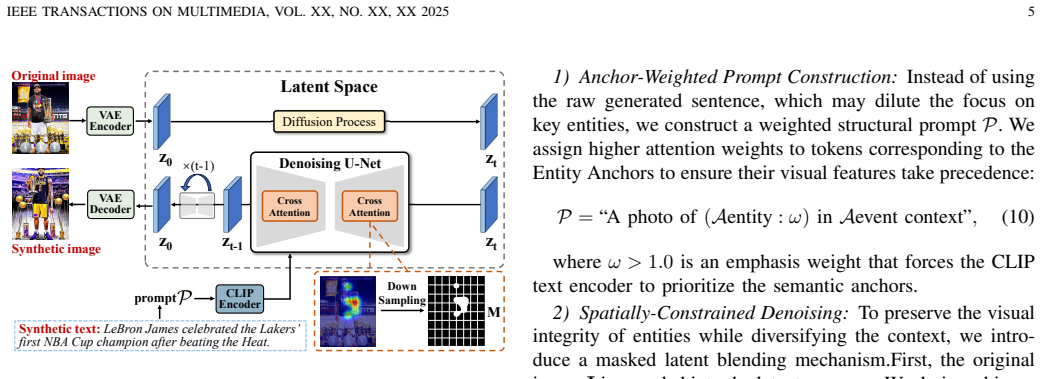
SAMA is a unified augmentation framework that constructs semantic anchors from ground-truth labels to direct a Collaborative Multi-Experts Multimodal Large Language Model (with universal and task-specific adapters) in producing textual samples, applies Anchor-Preserving Diffusion with anchor-weighted prompts and latent conditioning for image synthesis, and uses Dual-Constraint Filtering based on cross-modal consistency and anchor fidelity to select high-quality outputs without manual verification. This produces task-aware synthetic data that yields consistent gains on MNER, MRE, and MEE benchmarks under both supervised and low-resource conditions.
What carries the argument
Semantic anchors built from ground-truth labels, which steer both the CME-MLLM text generator and the Anchor-Preserving Diffusion image generator while Dual-Constraint Filtering enforces quality via consistency and fidelity checks.
If this is right
- A single framework can supply augmentation for multiple multimodal extraction tasks instead of requiring separate pipelines.
- Performance improvements appear in both fully supervised and low-resource training regimes.
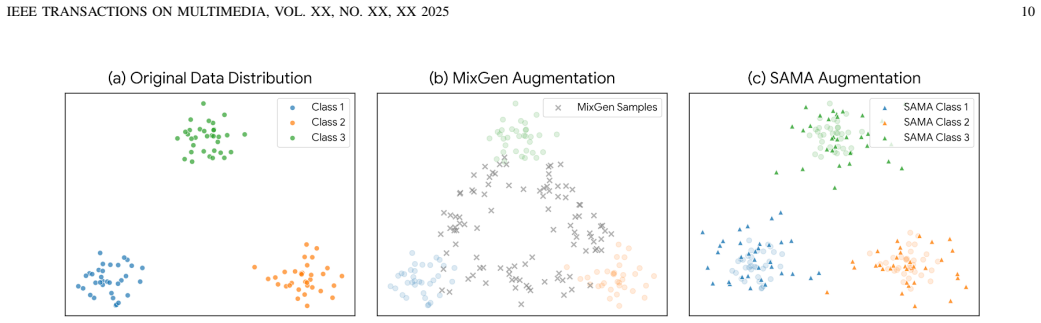
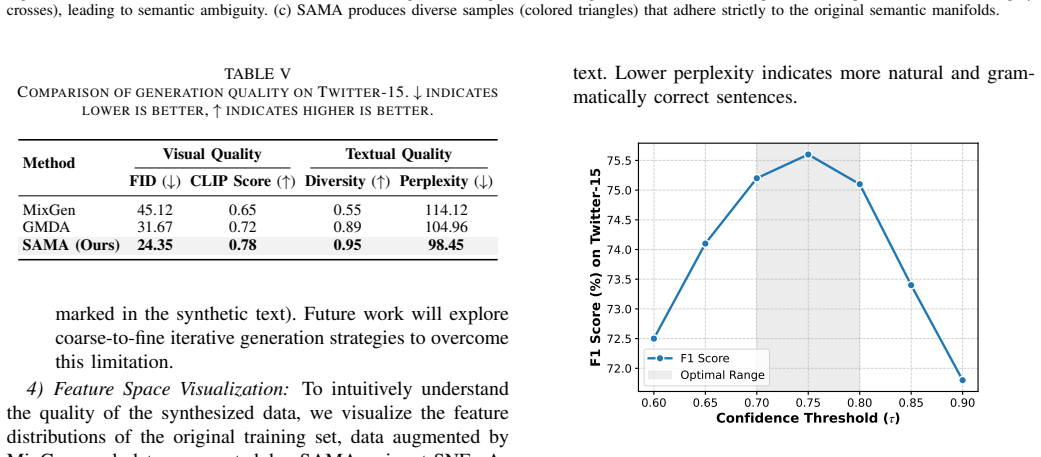
- Generated samples preserve critical semantic content from the original labels while adding diversity.
- The pipeline removes the manual verification step that previously limited scalable augmentation.
Where Pith is reading between the lines
- The anchor mechanism could transfer to other multimodal tasks such as visual question answering by reusing label-derived structures for generation guidance.
- Wider adoption might lower the amount of human-labeled multimodal data needed to reach target accuracy levels across multimedia understanding problems.
- Anchor alignment during synthesis may improve robustness when models encounter domain shifts not seen in the original training distribution.
Load-bearing premise
The Dual-Constraint Filtering module can reliably select high-quality synthetic samples based solely on cross-modal consistency and anchor fidelity without requiring manual verification.
What would settle it
Reproducing the benchmark experiments and observing that models trained with SAMA-augmented data fail to exceed the accuracy of state-of-the-art augmentation baselines on MNER, MRE, or MEE test sets.
Figures




read the original abstract
Multimodal Information Extraction (MIE)-covering tasks such as Multimodal Named Entity Recognition (MNER), Relation Extraction (MRE), and Event Extraction (MEE)-is essential for understanding multimedia content but remains constrained by severe data scarcity. Although data augmentation is a promising remedy, existing approaches are impeded by coarse cross-modal alignment and fragmented, task-specific designs that fail to exploit shared semantic knowledge. To overcome these limitations, we introduce Semantic Anchor-aligned Multimodal Augmentation (SAMA), a unified framework for generating high-fidelity, task-aware synthetic data. SAMA constructs structured semantic anchors from ground-truth labels to guide a Collaborative Multi-Experts Multimodal Large Language Model (CME-MLLM), which integrates a Universal Adapter for shared semantics with Task-Specific Adapters to produce diverse yet constraint-compliant textual samples. For image synthesis, SAMA employs an Anchor-Preserving Diffusion mechanism that uses anchor-weighted prompts and latent conditioning to maintain critical semantic anchors while diversifying visual contexts. To eliminate the need for manual verification, SAMA further introduces a Dual-Constraint Filtering module that selects synthetic samples based on both cross-modal consistency and anchor fidelity. Extensive experiments across benchmark datasets for MNER, MRE, and MEE demonstrate that SAMA consistently outperforms state-of-the-art augmentation baselines under both fully supervised and low-resource settings, underscoring its versatility, robustness, and effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Semantic Anchor-aligned Multimodal Augmentation (SAMA) as a unified framework for low-resource Multimodal Information Extraction (MNER, MRE, MEE). It builds semantic anchors from ground-truth labels to steer a Collaborative Multi-Experts Multimodal Large Language Model (CME-MLLM) equipped with a Universal Adapter and Task-Specific Adapters for text synthesis, applies Anchor-Preserving Diffusion with anchor-weighted prompts and latent conditioning for image generation, and uses a Dual-Constraint Filtering module (cross-modal consistency plus anchor fidelity) to select samples and remove the need for manual verification. Extensive experiments on benchmark datasets are reported to show consistent outperformance versus state-of-the-art augmentation baselines in both fully supervised and low-resource regimes.
Significance. If the empirical results hold after addressing validation gaps, the work supplies a task-aware, anchor-guided augmentation pipeline that integrates recent MLLM and diffusion techniques into multimodal IE. This could reduce data-scarcity barriers while preserving semantic fidelity across modalities, offering a more unified alternative to fragmented, task-specific augmentation methods.
major comments (1)
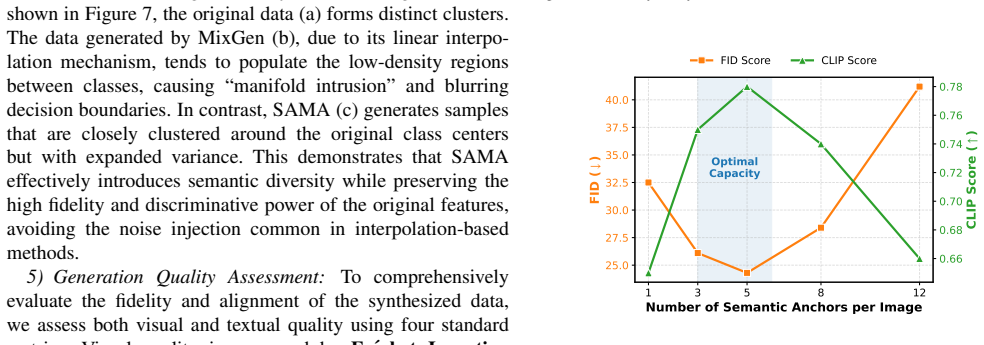
- [Abstract / §3.4] Abstract (and §3.4 on Dual-Constraint Filtering): The central claim that SAMA eliminates manual verification rests on the Dual-Constraint Filtering module reliably discarding low-quality samples via cross-modal consistency and anchor fidelity scores. No correlation study, ablation on filtering thresholds, or human validation linking these automated metrics to downstream IE performance (e.g., F1 on MNER/MRE/MEE) is described; without such evidence the reported gains could be driven by the underlying CME-MLLM rather than the SAMA pipeline, making this assumption load-bearing for the outperformance conclusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the concern about validation of the Dual-Constraint Filtering module below.
read point-by-point responses
-
Referee: [Abstract / §3.4] Abstract (and §3.4 on Dual-Constraint Filtering): The central claim that SAMA eliminates manual verification rests on the Dual-Constraint Filtering module reliably discarding low-quality samples via cross-modal consistency and anchor fidelity scores. No correlation study, ablation on filtering thresholds, or human validation linking these automated metrics to downstream IE performance (e.g., F1 on MNER/MRE/MEE) is described; without such evidence the reported gains could be driven by the underlying CME-MLLM rather than the SAMA pipeline, making this assumption load-bearing for the outperformance conclusion.
Authors: We agree that additional empirical validation would strengthen the claim that the filtering module contributes to the observed gains beyond the base CME-MLLM. The current experiments demonstrate that SAMA (including filtering) outperforms baselines, but we did not include a dedicated correlation analysis or threshold ablation. In the revised manuscript we will add: (1) an ablation varying the consistency and fidelity thresholds and reporting resulting F1 scores on MNER/MRE/MEE, and (2) a human evaluation on a random subset of accepted/rejected samples to correlate the automated scores with perceived quality and downstream utility. These additions will clarify the module's contribution. revision: yes
Circularity Check
No circularity; empirical augmentation method validated on external benchmarks
full rationale
The paper introduces an engineering pipeline (semantic anchors, CME-MLLM adapters, Anchor-Preserving Diffusion, Dual-Constraint Filtering) and supports its claims solely through performance comparisons on standard MNER/MRE/MEE benchmark datasets under supervised and low-resource regimes. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The filtering module is presented as a practical component whose efficacy is assessed via downstream task results rather than by construction or internal self-reference. This is a self-contained empirical contribution with no load-bearing steps that reduce to the inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ground-truth labels contain sufficient structured semantic information to serve as anchors that guide both text and image generation while preserving task constraints.
invented entities (2)
-
Semantic Anchor-aligned Multimodal Augmentation (SAMA)
no independent evidence
-
Collaborative Multi-Experts Multimodal Large Language Model (CME-MLLM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Visual attention model for name tagging in multimodal social media,
D. Lu, L. Neves, V . Carvalho, N. Zhang, and H. Ji, “Visual attention model for name tagging in multimodal social media,” inProceedings of the 56th Annual Meeting of the Association for Computational Linguistics, 2018, pp. 1990–1999
2018
-
[2]
Multimodal named entity recogni- tion for short social media posts,
S. Moon, L. Neves, and V . Carvalho, “Multimodal named entity recogni- tion for short social media posts,” inProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics, 2018, pp. 852–860
2018
-
[3]
Multimodal relation extraction with efficient graph alignment,
C. Zheng, J. Feng, Z. Fu, Y . Cai, Q. Li, and T. Wang, “Multimodal relation extraction with efficient graph alignment,” inProceedings of the 29th ACM international conference on multimedia, 2021, pp. 5298– 5306
2021
-
[4]
Mujo-sf: Multimodal joint slot filling for attribute value prediction of e-commerce commodities,
M. Jia, L. Shen, L. A. Tuan, M. Chen, J. Xu, L. Liao, S. Yuan, and X. He, “Mujo-sf: Multimodal joint slot filling for attribute value prediction of e-commerce commodities,”IEEE Transactions on Multimedia, vol. 26, pp. 10 354–10 366, 2024. IEEE TRANSACTIONS ON MULTIMEDIA, VOL. XX, NO. XX, XX 2025 12
2024
-
[5]
Fcds: Fusing constituency and depen- dency syntax into document-level relation extraction,
X. Zhu, Z. Kang, and B. Hui, “Fcds: Fusing constituency and depen- dency syntax into document-level relation extraction,” inProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024, pp. 7141–7152
2024
-
[6]
Bridging generative and discriminative learning: few-shot relation ex- traction via two-stage knowledge-guided pre-training,
Q. Guo, J. Zhang, S. Wang, L. Tian, Z. Kang, B. Yan, and W. Xiao, “Bridging generative and discriminative learning: few-shot relation ex- traction via two-stage knowledge-guided pre-training,” inProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelli- gence, 2025, pp. 8068–8076
2025
-
[7]
Prompt- ing chatgpt in mner: Enhanced multimodal named entity recognition with auxiliary refined knowledge,
J. Li, H. Li, Z. Pan, D. Sun, J. Wang, W. Zhang, and G. Pan, “Prompt- ing chatgpt in mner: Enhanced multimodal named entity recognition with auxiliary refined knowledge,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 2787–2802
2023
-
[8]
Named entity and relation extraction with multi-modal retrieval,
X. Wang, J. Cai, Y . Jiang, P. Xie, K. Tu, and W. Lu, “Named entity and relation extraction with multi-modal retrieval,” inFindings of the Association for Computational Linguistics: EMNLP 2022, 2022, pp. 5925–5936
2022
-
[9]
Cross-media structured common space for multimedia event extraction,
M. Li, A. Zareian, Q. Zeng, S. Whitehead, D. Lu, H. Ji, and S.-F. Chang, “Cross-media structured common space for multimedia event extraction,” inProceedings of the 58th Annual Meeting of the Associa- tion for Computational Linguistics, 2020, pp. 2557–2568
2020
-
[10]
Clip-event: Connecting text and images with event structures,
M. Li, R. Xu, S. Wang, L. Zhou, X. Lin, C. Zhu, M. Zeng, H. Ji, and S.-F. Chang, “Clip-event: Connecting text and images with event structures,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 420–16 429
2022
-
[11]
Adaptive co-attention network for named entity recognition in tweets,
Q. Zhang, J. Fu, X. Liu, and X. Huang, “Adaptive co-attention network for named entity recognition in tweets,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018
2018
-
[12]
Generative mul- timodal data augmentation for low-resource multimodal named entity recognition,
Z. Li, J. Yu, J. Yang, W. Wang, L. Yang, and R. Xia, “Generative mul- timodal data augmentation for low-resource multimodal named entity recognition,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 7336–7345
2024
-
[13]
Data augmentation via dependency tree morphing for low-resource languages,
G. G. S ¸ahin and M. Steedman, “Data augmentation via dependency tree morphing for low-resource languages,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 5004–5009
2018
-
[14]
An analysis of simple data augmentation for named entity recognition,
X. Dai and H. Adel, “An analysis of simple data augmentation for named entity recognition,” inProceedings of the 28th International Conference on Computational Linguistics, 2020, pp. 3861–3867
2020
-
[15]
Object-aware multi- modal named entity recognition in social media posts with adversarial learning,
C. Zheng, Z. Wu, T. Wang, Y . Cai, and Q. Li, “Object-aware multi- modal named entity recognition in social media posts with adversarial learning,”IEEE Transactions on Multimedia, vol. 23, pp. 2520–2532, 2020
2020
-
[16]
Learning from different text-image pairs: A relation-enhanced graph convolutional network for multimodal ner,
F. Zhao, C. Li, Z. Wu, S. Xing, and X. Dai, “Learning from different text-image pairs: A relation-enhanced graph convolutional network for multimodal ner,” inProceedings of the 30th ACM international confer- ence on multimedia, 2022, pp. 3983–3992
2022
-
[17]
Document-level relation extraction with cross-sentence reasoning graph,
H. Liu, Z. Kang, L. Zhang, L. Tian, and F. Hua, “Document-level relation extraction with cross-sentence reasoning graph,” inPacific-Asia conference on knowledge discovery and data mining. Springer, 2023, pp. 316–328
2023
-
[18]
BANER: Boundary-aware LLMs for few-shot named entity recognition,
Q. Guo, Y . Dong, L. Tian, Z. Kang, Y . Zhang, and S. Wang, “BANER: Boundary-aware LLMs for few-shot named entity recognition,” in Proceedings of the 31st International Conference on Computational Linguistics. Association for Computational Linguistics, 2025, pp. 10 375–10 389
2025
-
[19]
Extracting events like code: A multi-agent programming framework for zero-shot event extraction,
Q. Guo, S. Wang, J. Zhang, B. Zhang, Z. Kang, L. Tian, and K. Yan, “Extracting events like code: A multi-agent programming framework for zero-shot event extraction,” inProceedings of the 40th Annual AAAI Conference on Artificial Intelligence, 2026
2026
-
[20]
Umie: Unified multimodal information extraction with instruction tuning,
L. Sun, K. Zhang, Q. Li, and R. Lou, “Umie: Unified multimodal information extraction with instruction tuning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, 2024, pp. 19 062–19 070
2024
-
[21]
Instructblip: Towards general-purpose vision-language models with instruction tuning,
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P. N. Fung, and S. Hoi, “Instructblip: Towards general-purpose vision-language models with instruction tuning,”Advances in neural information processing systems, vol. 36, pp. 49 250–49 267, 2023
2023
-
[22]
Learning implicit entity-object relations by bidirectional generative alignment for multimodal ner,
F. Chen, J. Liu, K. Ji, W. Ren, J. Wang, and J. Chen, “Learning implicit entity-object relations by bidirectional generative alignment for multimodal ner,” inProceedings of the 31st ACM international conference on multimedia, 2023, pp. 4555–4563
2023
-
[23]
Hybrid transformer with multi-level fusion for multimodal knowledge graph completion,
X. Chen, N. Zhang, L. Li, S. Deng, C. Tan, C. Xu, F. Huang, L. Si, and H. Chen, “Hybrid transformer with multi-level fusion for multimodal knowledge graph completion,” inProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval, 2022, pp. 904–915
2022
-
[24]
Mcg-mner: A multi-granularity cross-modality generative framework for multimodal ner with instruc- tion,
J. Wu, C. Gong, Z. Cao, and G. Fu, “Mcg-mner: A multi-granularity cross-modality generative framework for multimodal ner with instruc- tion,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 3209–3218
2023
-
[25]
Multimodal representation with embedded visual guiding objects for named entity recognition in social media posts,
Z. Wu, C. Zheng, Y . Cai, J. Chen, H.-f. Leung, and Q. Li, “Multimodal representation with embedded visual guiding objects for named entity recognition in social media posts,” inProceedings of the 28th ACM International conference on multimedia, 2020, pp. 1038–1046
2020
-
[26]
Maf: a general matching and alignment framework for multimodal named entity recognition,
B. Xu, S. Huang, C. Sha, and H. Wang, “Maf: a general matching and alignment framework for multimodal named entity recognition,” in Proceedings of the fifteenth ACM international conference on web search and data mining, 2022, pp. 1215–1223
2022
-
[27]
Improving multimodal named entity recognition via entity span detection with unified multimodal transformer,
J. Yu, J. Jiang, L. Yang, and R. Xia, “Improving multimodal named entity recognition via entity span detection with unified multimodal transformer,” inProceedings of the 58th Annual Meeting of the As- sociation for Computational Linguistics, 2020, pp. 3342–3352
2020
-
[28]
Adaptive multi-scale language reinforcement for multimodal named entity recognition,
E. Li, T. Li, H. Luo, J. Chu, L. Duan, and F. Lv, “Adaptive multi-scale language reinforcement for multimodal named entity recognition,”IEEE Transactions on Multimedia, 2025
2025
-
[29]
Ita: Image-text alignments for multi-modal named entity recognition,
X. Wang, M. Gui, Y . Jiang, Z. Jia, N. Bach, T. Wang, Z. Huang, and K. Tu, “Ita: Image-text alignments for multi-modal named entity recognition,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics, 2022, pp. 3176–3189
2022
-
[30]
Mpmrc-mner: A unified mrc framework for multimodal named entity recognition based multimodal prompt,
X. Bao, M. Tian, Z. Zha, and B. Qin, “Mpmrc-mner: A unified mrc framework for multimodal named entity recognition based multimodal prompt,” inProceedings of the 32nd ACM International Conference on Information and Knowledge Management, 2023, pp. 47–56
2023
-
[31]
Query prior matters: A mrc framework for multimodal named entity recognition,
M. Jia, X. Shen, L. Shen, J. Pang, L. Liao, Y . Song, M. Chen, and X. He, “Query prior matters: A mrc framework for multimodal named entity recognition,” inProceedings of the 30th ACM international conference on multimedia, 2022, pp. 3549–3558
2022
-
[32]
In-context learning for few-shot multimodal named entity recognition,
C. Cai, Q. Wang, B. Liang, B. Qin, M. Yang, K.-F. Wong, and R. Xu, “In-context learning for few-shot multimodal named entity recognition,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 2969–2979
2023
-
[33]
F. Chen and Y . Feng, “Chain-of-thought prompt distillation for mul- timodal named entity recognition and multimodal relation extraction,” arXiv preprint arXiv:2306.14122, 2023
arXiv 2023
-
[34]
Grounded multimodal named entity recognition on social media,
J. Yu, Z. Li, J. Wang, and R. Xia, “Grounded multimodal named entity recognition on social media,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 9141–9154
2023
-
[35]
Fine-grained multimodal named entity recognition and grounding with a generative framework,
J. Wang, Z. Li, J. Yu, L. Yang, and R. Xia, “Fine-grained multimodal named entity recognition and grounding with a generative framework,” inProceedings of the 31st ACM International Conference on Multime- dia, 2023, pp. 3934–3943
2023
-
[36]
Mnre: A challenge multimodal dataset for neural relation extraction with visual evidence in social media posts,
C. Zheng, Z. Wu, J. Feng, Z. Fu, and Y . Cai, “Mnre: A challenge multimodal dataset for neural relation extraction with visual evidence in social media posts,” in2021 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2021, pp. 1–6
2021
-
[37]
Good visual guidance make a better extractor: Hierarchical visual prefix for multimodal entity and relation extraction,
X. Chen, N. Zhang, L. Li, Y . Yao, S. Deng, C. Tan, F. Huang, L. Si, and H. Chen, “Good visual guidance make a better extractor: Hierarchical visual prefix for multimodal entity and relation extraction,” inFindings of the Association for Computational Linguistics: NAACL 2022, 2022, pp. 1607–1618
2022
-
[38]
Multimodal relation extraction with cross-modal retrieval and synthesis,
X. Hu, Z. Guo, Z. Teng, I. King, and S. Y . Philip, “Multimodal relation extraction with cross-modal retrieval and synthesis,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023, pp. 303–311
2023
-
[39]
Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts,
J. Xie, K. Zhang, J. Chen, R. Lou, and Y . Su, “Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[40]
Automatic evaluation of attribution by large language models,
X. Yue, B. Wang, Z. Chen, K. Zhang, Y . Su, and H. Sun, “Automatic evaluation of attribution by large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 4615–4635
2023
-
[41]
Multimedia event extraction from news with a unified contrastive learning framework,
J. Liu, Y . Chen, and J. Xu, “Multimedia event extraction from news with a unified contrastive learning framework,” inProceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 1945– 1953
2022
-
[42]
Multi- grained gradual inference model for multimedia event extraction,
Y . Liu, F. Liu, L. Jiao, Q. Bao, L. Sun, S. Li, L. Li, and X. Liu, “Multi- grained gradual inference model for multimedia event extraction,”IEEE IEEE TRANSACTIONS ON MULTIMEDIA, VOL. XX, NO. XX, XX 2025 13 Transactions on Circuits and Systems for Video Technology, vol. 34, no. 10, pp. 10 507–10 520, 2024
2025
-
[43]
EDA: Easy data augmentation techniques for boost- ing performance on text classification tasks,
J. Wei and K. Zou, “EDA: Easy data augmentation techniques for boost- ing performance on text classification tasks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Nov. 2019, pp. 6382–6388
2019
-
[44]
Daga: Data augmentation with a generation approach for low-resource tagging tasks,
B. Ding, L. Liu, L. Bing, C. Kruengkrai, T. H. Nguyen, S. Joty, L. Si, and C. Miao, “Daga: Data augmentation with a generation approach for low-resource tagging tasks,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 6045–6057
2020
-
[45]
Mixgen: A new multi-modal data augmentation,
X. Hao, Y . Zhu, S. Appalaraju, A. Zhang, W. Zhang, B. Li, and M. Li, “Mixgen: A new multi-modal data augmentation,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2023, pp. 379–389
2023
-
[46]
Caption-aware multimodal rela- tion extraction with mutual information maximization,
Z. Zhang, W. Zhang, Y . Li, and T. Bai, “Caption-aware multimodal rela- tion extraction with mutual information maximization,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 1148–1157
2024
-
[47]
Training multimedia event extraction with generated images and captions,
Z. Du, Y . Li, X. Guo, Y . Sun, and B. Li, “Training multimedia event extraction with generated images and captions,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 5504– 5513
2023
-
[48]
Lora: Low-rank adaptation of large language models,
E. J. Hu, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen et al., “Lora: Low-rank adaptation of large language models,” inInter- national Conference on Learning Representations, 2022
2022
-
[49]
Col- laborative multi-lora experts with achievement-based multi-tasks loss for unified multimodal information extraction,
L. Yuan, Y . Cai, X. Shen, Q. Li, Q. Huang, Z. Deng, and T. Wang, “Col- laborative multi-lora experts with achievement-based multi-tasks loss for unified multimodal information extraction,” inProceedings of the Thirty- Fourth International Joint Conference on Artificial Intelligence, 2025, pp. 6940–6948
2025
-
[50]
Ace 2005 multilingual training corpus,
C. Walker, S. Strassel, J. Medero, and K. Maeda, “Ace 2005 multilingual training corpus,”(No Title), 2006
2005
-
[51]
Situation recognition: Visual semantic role labeling for image understanding,
M. Yatskar, L. Zettlemoyer, and A. Farhadi, “Situation recognition: Visual semantic role labeling for image understanding,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5534–5542
2016
-
[52]
Scaling instruction-finetuned language models,
H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y . Tay, W. Fedus, Y . Li, X. Wang, M. Dehghani, S. Brahmaet al., “Scaling instruction-finetuned language models,”Journal of Machine Learning Research, vol. 25, no. 70, pp. 1–53, 2024
2024
-
[53]
Eva: Exploring the limits of masked visual representation learning at scale,
Y . Fang, W. Wang, B. Xie, Q. Sun, L. Wu, X. Wang, T. Huang, X. Wang, and Y . Cao, “Eva: Exploring the limits of masked visual representation learning at scale,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 19 358–19 369
2023
-
[54]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[55]
Rethinking multimodal entity and relation extraction from a translation point of view,
C. Zheng, J. Feng, Y . Cai, X. Wei, and Q. Li, “Rethinking multimodal entity and relation extraction from a translation point of view,” in Proceedings of the 61st Annual Meeting of the Association for Com- putational Linguistics, 2023, pp. 6810–6824
2023
-
[56]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,”Advances in neural information processing systems, 2017
2017
-
[57]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning, 2021, pp. 8748–8763. Quanjiang Guoreceived the BEng degree from Beijing University of Technology in 2020. He is currentl...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.