FOAM: Frequency and Operator Error-Based Adaptive Damping Method for Reducing Staleness-Oriented Error for Shampoo
Pith reviewed 2026-06-28 15:47 UTC · model grok-4.3
The pith
FOAM reduces wall-clock time for Shampoo by adaptively controlling damping and eigendecomposition frequency based on staleness error approximation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling staleness effects on convergence and stability, the work establishes that an approximation of the staleness-oriented error can be used to dynamically set both the damping factor and the eigendecomposition frequency, thereby allowing Shampoo to operate with stale preconditioners while reducing wall-clock time and preserving robust convergence.
What carries the argument
FOAM, the adaptive algorithm that approximates the staleness-oriented error to guide changes in the damping factor and eigendecomposition frequency.
Load-bearing premise
An approximation of the staleness-oriented error can reliably guide dynamic control of the damping factor and eigendecomposition frequency without introducing new instabilities or degrading optimization performance.
What would settle it
Running the reported large-scale benchmarks and observing that FOAM either increases wall-clock time or produces unstable training or worse final performance than standard Shampoo.
Figures
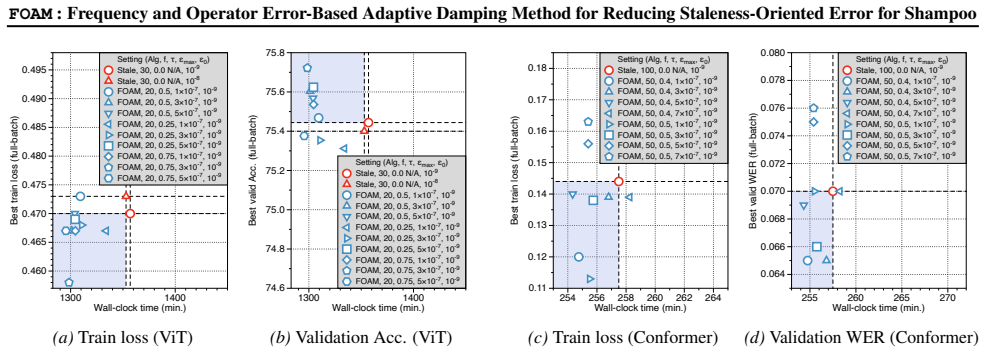

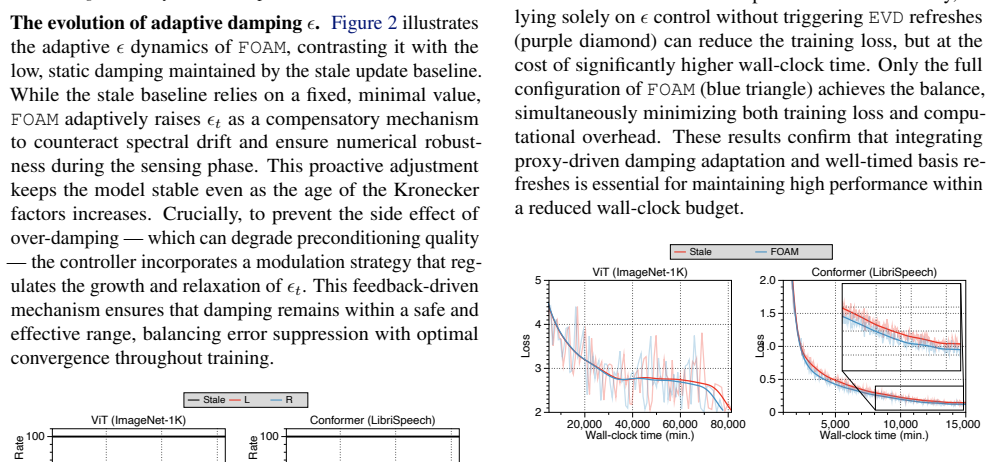

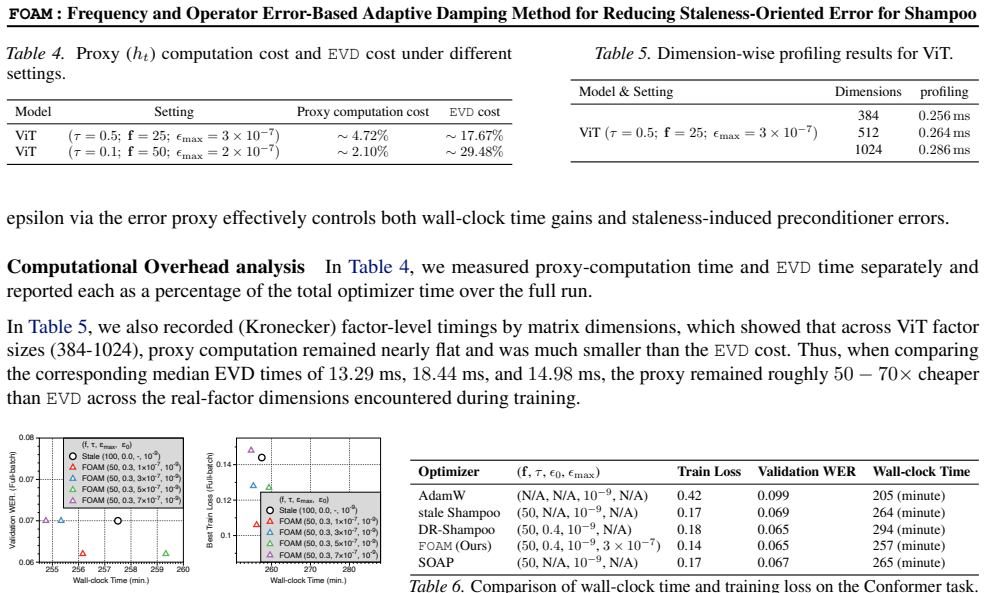
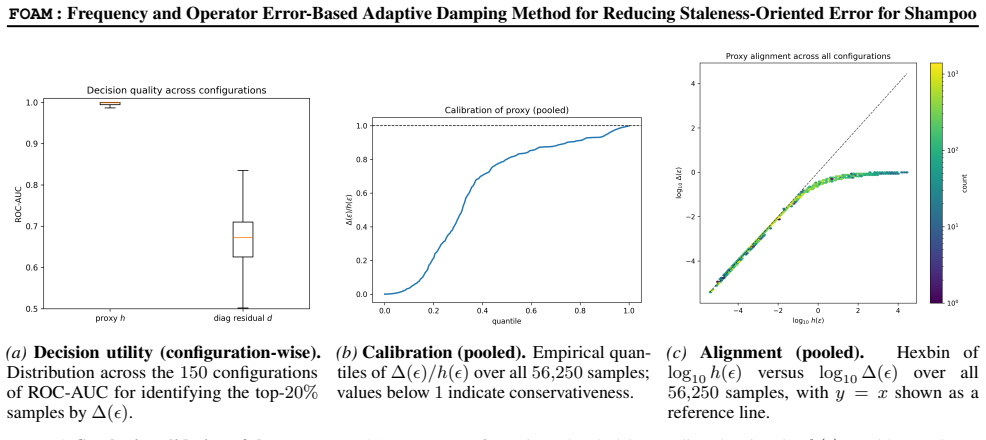
read the original abstract
Shampoo is attracting considerable attention for its superior performance on large-scale optimization benchmarks; yet it faces a significant practical bottleneck: the prohibitive computational overhead of matrix inversion. To mitigate this, practitioners typically rely on stale preconditioner updates, creating a fundamental trade-off between computational efficiency and optimization fidelity. In this work, we provide a theoretical study of staleness through the complementary lenses of convergence and stability. While staleness improves computational efficiency, it inherently degrades performance and introduces numerical instability. Crucially, we identify that damping, acting as a numerical stabilizer, can effectively suppress these negative effects. Guided by this analysis, we propose FOAM, an adaptive algorithm that stabilizes training by dynamically controlling both the damping factor and the eigendecomposition frequency based on an approximation of the staleness-oriented error. Experimental results demonstrate that FOAM reduces wall-clock time compared to standard Shampoo while maintaining robust convergence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper provides a theoretical analysis of staleness effects on convergence and stability in the Shampoo optimizer, noting that stale preconditioner updates improve efficiency but degrade performance and introduce instability, with damping acting as a stabilizer. It proposes FOAM, an adaptive method that dynamically modulates the damping factor and eigendecomposition frequency using an approximation of the staleness-oriented error. Experiments claim that FOAM reduces wall-clock time relative to standard Shampoo while preserving robust convergence.
Significance. If the approximation of staleness-oriented error is independently derived and the adaptive controls prove stable, the work could meaningfully improve the practicality of second-order methods like Shampoo on large-scale problems by addressing a key computational bottleneck. The dual theoretical and experimental framing is a positive feature, though the absence of explicit derivations or controls in the provided text limits evaluation of its broader impact.
major comments (2)
- [Abstract] Abstract: The abstract asserts a theoretical study of staleness plus supporting experiments, yet supplies no equations, proof sketches, dataset details, or error-bar information, so it is not possible to verify whether the data or derivations support the stated claim.
- [Abstract] Abstract: Without details on the derivation, it is unclear whether the 'approximation of the staleness-oriented error' is derived independently or reduces to a quantity defined in terms of parameters fitted to the same training runs, which is load-bearing for the central adaptive-control claim.
Simulated Author's Rebuttal
We thank the referee for their comments. We address the two major comments on the abstract point by point below. The full manuscript contains the requested theoretical and experimental details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts a theoretical study of staleness plus supporting experiments, yet supplies no equations, proof sketches, dataset details, or error-bar information, so it is not possible to verify whether the data or derivations support the stated claim.
Authors: Abstracts are concise summaries and standardly omit detailed equations, proofs, or experimental specifics to meet length limits. The full manuscript provides the theoretical analysis of staleness effects on convergence and stability (including equations and proof sketches) in the dedicated theory sections, along with dataset details and error bars in the experiments section. Readers can verify the claims from the main text. revision: no
-
Referee: [Abstract] Abstract: Without details on the derivation, it is unclear whether the 'approximation of the staleness-oriented error' is derived independently or reduces to a quantity defined in terms of parameters fitted to the same training runs, which is load-bearing for the central adaptive-control claim.
Authors: The approximation of the staleness-oriented error is independently derived from the theoretical analysis of how staleness degrades preconditioner quality and introduces instability. It follows directly from the mathematical modeling of staleness effects rather than from parameters fitted to training runs. The explicit derivation appears in the theoretical section of the manuscript. revision: no
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The abstract presents a theoretical analysis of staleness effects on convergence and stability, followed by an adaptive method (FOAM) that uses an approximation of staleness-oriented error to control damping and eigendecomposition frequency. No equations, self-citations, or fitted parameters are quoted that reduce the central claim (reduced wall-clock time with maintained convergence) to a definition or input by construction. The approximation is described as guided by analysis rather than fitted to the target metric. This matches the default expectation of no circularity when the derivation chain does not exhibit the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2512.05620 , year=
Hyperparameter Transfer Enables Consistent Gains of Matrix-Preconditioned Optimizers Across Scales , author=. arXiv preprint arXiv:2512.05620 , year=
-
[3]
Journal of Computer and System Sciences , volume=
Efficient algorithms for online decision problems , author=. Journal of Computer and System Sciences , volume=. 2005 , publisher=
2005
-
[4]
Disentangling adaptive gradient methods from learning rates.arXiv preprint arXiv:2002.11803,
Disentangling adaptive gradient methods from learning rates , author=. arXiv preprint arXiv:2002.11803 , year=
-
[5]
The Thirteenth International Conference on Learning Representations , year=
Adam-mini: Use Fewer Learning Rates To Gain More , author=. The Thirteenth International Conference on Learning Representations , year=
-
[6]
A Daleckiˇi-Kreˇin formula for the Fr
Noferini, Vanni , year=. A Daleckiˇi-Kreˇin formula for the Fr
-
[7]
2025 , url=
Gyu Yeol Kim and Min-hwan Oh , booktitle=. 2025 , url=
2025
-
[8]
Small Batch Size Training for Language Models: When Vanilla
Martin Marek and Sanae Lotfi and Aditya Somasundaram and Andrew Gordon Wilson and Micah Goldblum , booktitle=. Small Batch Size Training for Language Models: When Vanilla. 2026 , url=
2026
-
[9]
2022 , url =
Roger Grosse , title =. 2022 , url =
2022
-
[10]
arXiv preprint arXiv:2301.11235 , year=
Handbook of convergence theorems for (stochastic) gradient methods , author=. arXiv preprint arXiv:2301.11235 , year=
-
[11]
Mathematical Programming , volume=
Nonsmooth optimization via quasi-Newton methods , author=. Mathematical Programming , volume=. 2013 , publisher=
2013
-
[12]
Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond
Eigenvalues of the hessian in deep learning: Singularity and beyond , author=. arXiv preprint arXiv:1611.07476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
2020 IEEE international conference on big data (Big data) , pages=
Pyhessian: Neural networks through the lens of the hessian , author=. 2020 IEEE international conference on big data (Big data) , pages=. 2020 , organization=
2020
-
[14]
2013 , publisher=
Matrix analysis , author=. 2013 , publisher=
2013
-
[15]
International Conference on Machine Learning , pages=
Shampoo: Preconditioned stochastic tensor optimization , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[16]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[17]
Journal of Machine Learning Research , volume=
New insights and perspectives on the natural gradient method , author=. Journal of Machine Learning Research , volume=
-
[18]
International Conference on Machine Learning , pages=
Second-order optimization with lazy Hessians , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[19]
Advances in neural information processing systems , volume=
Visualizing the loss landscape of neural nets , author=. Advances in neural information processing systems , volume=
-
[20]
The American Mathematical Monthly , volume=
A modification of Newton's method , author=. The American Mathematical Monthly , volume=. 1948 , publisher=
1948
-
[21]
Uspekhi Matematicheskikh Nauk , volume=
Functional analysis and applied mathematics , author=. Uspekhi Matematicheskikh Nauk , volume=. 1948 , publisher=
1948
-
[22]
The annals of mathematical statistics , pages=
A stochastic approximation method , author=. The annals of mathematical statistics , pages=. 1951 , publisher=
1951
-
[23]
Lowe and Felix Dangel and Runa Eschenhagen and Zikun Xu and Roger Baker Grosse , booktitle=
Wu Lin and Scott C. Lowe and Felix Dangel and Runa Eschenhagen and Zikun Xu and Roger Baker Grosse , booktitle=. Understanding and improving Shampoo and. 2026 , url=
2026
-
[24]
A Unified Approach to Adaptive Regularization in Online and Stochastic Optimization
A unified approach to adaptive regularization in online and stochastic optimization , author=. arXiv preprint arXiv:1706.06569 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Purifying Shampoo: Investigating Shampoo's Heuristics by Decomposing its Preconditioner , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[26]
International Conference on Machine Learning , pages=
Asynchronous Byzantine machine learning (the case of SGD) , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[27]
International Conference on Learning Representations , volume=
SOAP: Improving and stabilizing shampoo using adam for language modeling , author=. International Conference on Learning Representations , volume=
-
[28]
International Conference on Machine Learning , year=
Understanding Adam Optimizer via Online Learning of Updates: Adam is FTRL in Disguise , author=. International Conference on Machine Learning , year=
-
[29]
2012 , publisher=
Matrix analysis , author=. 2012 , publisher=
2012
-
[30]
arXiv preprint arXiv:2306.07179 , year=
Benchmarking neural network training algorithms , author=. arXiv preprint arXiv:2306.07179 , year=
-
[31]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[32]
Advances in Neural Information Processing Systems , volume=
Second-order forward-mode optimization of recurrent neural networks for neuroscience , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
The Eleventh International Conference on Learning Representations , year=
Fisher-Legendre (FishLeg) optimization of deep neural networks , author=. The Eleventh International Conference on Learning Representations , year=
-
[34]
Advances in Neural Information Processing Systems , volume=
Exact natural gradient in deep linear networks and its application to the nonlinear case , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Advances in Neural Information Processing Systems , volume=
Practical quasi-newton methods for training deep neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Advances in Neural Information Processing Systems , volume=
Exact, tractable gauss-newton optimization in deep reversible architectures reveal poor generalization , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[38]
SIAM review , volume=
Optimization methods for large-scale machine learning , author=. SIAM review , volume=. 2018 , publisher=
2018
-
[39]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author =. arXiv preprint arXiv:2001.08361 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[40]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Training Compute-Optimal Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[41]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Limitations of the Empirical Fisher Approximation for Natural Gradient Descent , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[42]
The Twelfth International Conference on Learning Representations , year=
On the Parameterization of Second-Order Optimization Effective towards the Infinite Width , author=. The Twelfth International Conference on Learning Representations , year=
-
[43]
The Thirteenth International Conference on Learning Representations , year=
Accelerating neural network training: An analysis of the AlgoPerf competition , author=. The Thirteenth International Conference on Learning Representations , year=
-
[44]
Numerical analysis: proceedings of the biennial Conference held at Dundee, June 28--July 1, 1977 , pages=
The Levenberg-Marquardt algorithm: implementation and theory , author=. Numerical analysis: proceedings of the biennial Conference held at Dundee, June 28--July 1, 1977 , pages=. 2006 , organization=
1977
-
[45]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
2018 , publisher=
Lectures on convex optimization , author=. 2018 , publisher=
2018
-
[47]
A distributed data-parallel pytorch implementation of the distributed shampoo optimizer for training neural networks at-scale , author=. arXiv preprint arXiv:2309.06497 , year=
-
[48]
Ussr computational mathematics and mathematical physics , volume=
Some methods of speeding up the convergence of iteration methods , author=. Ussr computational mathematics and mathematical physics , volume=. 1964 , publisher=
1964
-
[49]
The Thirteenth International Conference on Learning Representations , year=
A New Perspective on Shampoo's Preconditioner , author=. The Thirteenth International Conference on Learning Representations , year=
-
[50]
Online Learning: A Modern Introduction Using Convex Optimization
A modern introduction to online learning , author=. arXiv preprint arXiv:1912.13213 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[51]
, author=
Adaptive subgradient methods for online learning and stochastic optimization. , author=. Journal of machine learning research , volume=
-
[52]
Biometrika , volume=
A useful variant of the Davis--Kahan theorem for statisticians , author=. Biometrika , volume=. 2015 , publisher=
2015
-
[53]
arXiv preprint arXiv:2211.15596 , year=
A survey of deep learning optimizers--first and second order methods , author=. arXiv preprint arXiv:2211.15596 , year=
-
[54]
2016 , publisher=
Information geometry and its applications , author=. 2016 , publisher=
2016
-
[55]
CoRR , year=
Discounted adaptive online prediction , author=. CoRR , year=
-
[56]
1998 , publisher=
The symmetric eigenvalue problem , author=. 1998 , publisher=
1998
-
[57]
Forty-first International Conference on Machine Learning , year=
Online Linear Regression in Dynamic Environments via Discounting , author=. Forty-first International Conference on Machine Learning , year=
-
[58]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[59]
Pointer Sentinel Mixture Models
Pointer sentinel mixture models , author=. arXiv preprint arXiv:1609.07843 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
SmolLM2: When Smol Goes Big--Data-Centric Training of a Small Language Model , author=. arXiv preprint arXiv:2502.02737 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
arXiv preprint arXiv:2405.09742 , year=
Random scaling and momentum for non-smooth non-convex optimization , author=. arXiv preprint arXiv:2405.09742 , year=
-
[62]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
A Stable Whitening Optimizer for Efficient Neural Network Training , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[63]
The Twelfth International Conference on Learning Representations , year=
Combining axes preconditioners through kronecker approximation for deep learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[64]
2024 , url =
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
2024
-
[65]
International conference on machine learning , pages=
Optimizing neural networks with kronecker-factored approximate curvature , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[66]
SIAM Journal on Matrix Analysis and Applications , volume=
Backward stability of iterations for computing the polar decomposition , author=. SIAM Journal on Matrix Analysis and Applications , volume=. 2012 , publisher=
2012
-
[67]
OPT 2024: Optimization for Machine Learning , year=
Old Optimizer, New Norm: An Anthology , author=. OPT 2024: Optimization for Machine Learning , year=
2024
-
[68]
arXiv preprint arXiv:2405.16002 , year=
Does SGD really happen in tiny subspaces? , author=. arXiv preprint arXiv:2405.16002 , year=
-
[69]
Springer Science , volume=
Numerical optimization , author=. Springer Science , volume=
-
[70]
SIAM review , volume=
Quasi-Newton methods, motivation and theory , author=. SIAM review , volume=. 1977 , publisher=
1977
-
[71]
Mathematical programming , volume=
Cubic regularization of Newton method and its global performance , author=. Mathematical programming , volume=. 2006 , publisher=
2006
-
[72]
International Conference on Learning Representations , year=
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes , author=. International Conference on Learning Representations , year=
-
[73]
Forty-second International Conference on Machine Learning , year=
Structured Preconditioners in Adaptive Optimization: A Unified Analysis , author=. Forty-second International Conference on Machine Learning , year=
-
[74]
, author=
Deep learning via hessian-free optimization. , author=. Icml , volume=
-
[75]
General framework for online-to-nonconvex conversion: Schedule-free
Kwangjun Ahn and Gagik Magakyan and Ashok Cutkosky , booktitle=. General framework for online-to-nonconvex conversion: Schedule-free. 2025 , url=
2025
-
[76]
International Conference on Machine Learning , pages=
Optimal stochastic non-smooth non-convex optimization through online-to-non-convex conversion , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[77]
Scalable second order optimization for deep learning , author=. arXiv preprint arXiv:2002.09018 , year=
-
[78]
Advances in neural information processing systems , volume=
Why transformers need adam: A hessian perspective , author=. Advances in neural information processing systems , volume=
-
[79]
The Potential of Second-Order Optimization for LLMs: A Study with Full Gauss-Newton
The Potential of Second-Order Optimization for LLMs: A Study with Full Gauss-Newton , author=. arXiv preprint arXiv:2510.09378 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.