CaC: Advancing Video Reward Models via Hierarchical Spatiotemporal Concentrating
Pith reviewed 2026-05-13 05:56 UTC · model grok-4.3
The pith
CaC shows that a hierarchical temporal-then-spatial scan lets vision-language models detect subtle video anomalies more reliably for use as rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
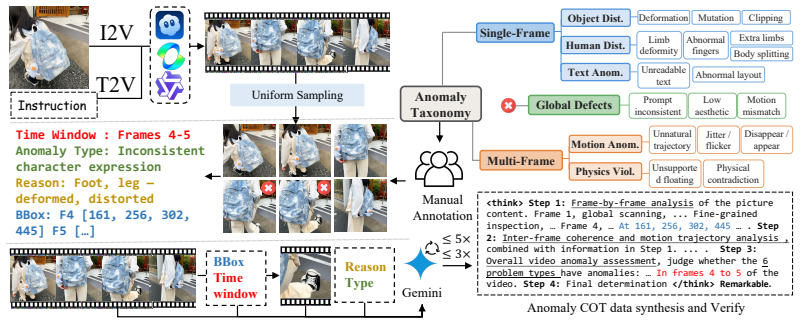
CaC is a coarse-to-fine anomaly reward model based on vision-language models. During inference it first runs a global temporal scan to anchor anomalous time windows, then performs fine-grained spatial grounding inside the selected interval, and finally reaches judgments through structured spatiotemporal chain-of-thought reasoning. The model is trained on a newly built large-scale generated-video anomaly dataset using a three-stage pipeline: single- and multi-frame supervised fine-tuning for anchoring, followed by group relative policy optimization that adds temporal and spatial IoU rewards to supervise the intermediate localization steps.
What carries the argument
Hierarchical spatiotemporal concentrating: the three-step inference process of global temporal anchoring, localized spatial grounding, and chain-of-thought reasoning, trained with added IoU rewards in reinforcement learning.
If this is right
- Accuracy on fine-grained anomaly benchmarks rises when the model concentrates hierarchically rather than scoring globally.
- Using CaC as a reward signal during generation reduces the rate of anomalies in the resulting videos.
- Overall visual quality of generated videos improves when the reward model supplies more localized feedback.
- The added temporal and spatial IoU rewards in training produce more grounded intermediate localization outputs.
- The progressive three-stage training allows the model to acquire both basic anchoring and advanced reasoning capabilities.
Where Pith is reading between the lines
- The same staged temporal-then-spatial pattern could be tested on other sequential media such as audio tracks or multi-view 3D sequences.
- If the localization rewards generalize, they might serve as a template for training interpretable reasoning in other vision-language tasks beyond anomaly detection.
- Extending the dataset construction pipeline to include longer videos or real captured footage would test whether the gains remain when the domain shifts.
- The approach opens a route to reward models that output not only a score but also explicit time and space attributions that human reviewers can inspect.
Load-bearing premise
The newly constructed generated-video anomaly dataset is representative of the distributions that appear in real deployment of video generation systems.
What would settle it
Apply the trained CaC model to videos produced by a different generator or containing anomaly types absent from the training set, then measure whether the reported accuracy gains and anomaly reduction still appear.
Figures



read the original abstract
In this paper, we propose Concentrate and Concentrate (CaC), a coarse-to-fine anomaly reward model based on Vision-Language Models. During inference, it first conducts a global temporal scan to anchor anomalous time windows, then performs fine-grained spatial grounding within the localized interval, and finally derives robust judgments via structured spatiotemporal Chain-of-Thought reasoning. To equip the model with these capabilities, we construct the first large-scale generated video anomaly dataset with per-frame bounding-box annotations, temporal anomaly windows, and fine-grained attribution labels. Building on this dataset, we design a three-stage progressive training paradigm. The model initially learns spatial and temporal anchoring through single- and multi-frame supervised fine-tuning, and then is optimized by a reinforcement learning strategy based on two-turn Group Relative Policy Optimization (GRPO). Beyond conventional accuracy rewards, we introduce Temporal and Spatial IoU rewards to supervise the intermediate localization process, effectively guiding the model toward more grounded and interpretable spatiotemporal reasoning. Extensive experiments demonstrate that CaC can stably concentrate on subtle anomalies, achieving a 25.7% accuracy improvement on fine-grained anomaly benchmarks and, when used as a reward signal, CaC reduces generated-video anomalies by 11.7% while improving overall video quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CaC, a coarse-to-fine anomaly reward model for videos based on vision-language models. It first performs global temporal scanning to identify anomalous windows, then fine-grained spatial grounding, followed by structured spatiotemporal Chain-of-Thought reasoning. To support this, the authors construct a large-scale generated-video anomaly dataset with per-frame bounding-box annotations, temporal windows, and attribution labels. Training proceeds in three stages: single- and multi-frame supervised fine-tuning for anchoring, followed by two-turn Group Relative Policy Optimization (GRPO) augmented with Temporal and Spatial IoU rewards. The central claims are a 25.7% accuracy improvement on fine-grained anomaly benchmarks and an 11.7% reduction in generated-video anomalies (with improved overall quality) when CaC is used as a reward signal.
Significance. If the performance claims are substantiated with rigorous controls, the work would advance video reward modeling by introducing interpretable hierarchical spatiotemporal reasoning and IoU-supervised localization. The construction of the annotated dataset and the GRPO augmentation with localization rewards constitute concrete contributions that could be adopted in video generation alignment pipelines. The approach is technically coherent and addresses a genuine gap in fine-grained anomaly handling, though its broader impact hinges on demonstrated generalizability beyond the custom dataset.
major comments (3)
- [§5] §5 (Experiments): The headline claims of 25.7% accuracy improvement and 11.7% anomaly reduction are stated without reported baselines, statistical significance tests, ablation studies isolating the IoU rewards or the hierarchical stages, or explicit data splits. This absence prevents verification that the gains arise from the proposed concentrating mechanism rather than dataset-specific fitting.
- [§3] §3 (Dataset Construction): The newly constructed generated-video anomaly dataset with per-frame boxes, temporal windows, and attribution labels is load-bearing for all training and evaluation. No cross-distribution hold-out, external benchmark comparison, or analysis of distributional shift (e.g., artifact patterns, motion profiles) is described, leaving the representativeness assumption untested.
- [§4.2] §4.2 (GRPO Training): The Temporal and Spatial IoU rewards are introduced to supervise intermediate localization, yet no sensitivity analysis on their coefficients, comparison to standard accuracy-only GRPO, or quantitative ablation of the two-turn structure is provided. These omissions directly affect the claim that the rewards produce more grounded reasoning.
minor comments (2)
- The abstract and method description refer to 'structured spatiotemporal Chain-of-Thought reasoning' without an explicit example or template of the reasoning format in the main text or supplementary material.
- Figure captions and axis labels in the experimental results would benefit from explicit indication of which curves correspond to the full CaC model versus ablated variants.
Simulated Author's Rebuttal
We thank the referee for the detailed and insightful review of our manuscript. We are pleased that the referee recognizes the potential of our hierarchical spatiotemporal concentrating approach and the contributions of the new dataset and GRPO training strategy. We address each of the major comments below and commit to substantial revisions to address the concerns raised.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): The headline claims of 25.7% accuracy improvement and 11.7% anomaly reduction are stated without reported baselines, statistical significance tests, ablation studies isolating the IoU rewards or the hierarchical stages, or explicit data splits. This absence prevents verification that the gains arise from the proposed concentrating mechanism rather than dataset-specific fitting.
Authors: We fully agree that the experimental section requires more rigorous validation to support the headline claims. In the revised manuscript, we will expand §5 to include a comprehensive set of baselines from prior video anomaly detection methods and reward models. Statistical significance will be assessed using appropriate tests such as Student's t-test or Wilcoxon signed-rank test over multiple random seeds. We will add ablation studies that systematically isolate the impact of the Temporal and Spatial IoU rewards as well as each component of the hierarchical pipeline (global temporal scanning, fine-grained spatial grounding, and structured CoT). Explicit details on data splits, including the proportions for training, validation, and testing, along with any stratification by anomaly type, will be provided. These changes will allow readers to verify that the reported improvements are due to the proposed CaC mechanism. revision: yes
-
Referee: [§3] §3 (Dataset Construction): The newly constructed generated-video anomaly dataset with per-frame boxes, temporal windows, and attribution labels is load-bearing for all training and evaluation. No cross-distribution hold-out, external benchmark comparison, or analysis of distributional shift (e.g., artifact patterns, motion profiles) is described, leaving the representativeness assumption untested.
Authors: We recognize that demonstrating the dataset's robustness is essential. In the revision, we will introduce a cross-distribution hold-out evaluation by reserving subsets generated from unseen video generation models or with distinct anomaly characteristics. Where feasible, we will perform comparisons on adapted external benchmarks to assess transferability. Furthermore, we will add a dedicated analysis subsection quantifying distributional shifts, including metrics on artifact patterns (e.g., frequency of specific visual artifacts) and motion profiles (e.g., optical flow statistics). This will provide evidence supporting the dataset's representativeness for generated video anomalies. revision: yes
-
Referee: [§4.2] §4.2 (GRPO Training): The Temporal and Spatial IoU rewards are introduced to supervise intermediate localization, yet no sensitivity analysis on their coefficients, comparison to standard accuracy-only GRPO, or quantitative ablation of the two-turn structure is provided. These omissions directly affect the claim that the rewards produce more grounded reasoning.
Authors: We agree that these analyses are necessary to substantiate the effectiveness of our reward design. The revised paper will include a sensitivity study on the weighting coefficients for the Temporal IoU and Spatial IoU rewards, reporting performance across a range of values. We will also present direct comparisons between our IoU-augmented GRPO and a baseline using only accuracy rewards. Additionally, we will quantify the benefit of the two-turn structure through an ablation study comparing one-turn and two-turn variants. These results will be incorporated into §4.2 to more convincingly demonstrate that the IoU rewards lead to improved localization and grounded reasoning. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs a new dataset with per-frame annotations and attribution labels, then applies a three-stage training process (SFT followed by GRPO augmented with explicitly defined Temporal and Spatial IoU rewards). The reported 25.7% accuracy gain and 11.7% anomaly reduction are measured outcomes on fine-grained benchmarks and generated videos, not quantities that reduce by the paper's own equations to parameters fitted on the target test distribution. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation; the spatiotemporal concentrating mechanism and reward design remain independent of the final evaluation metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- Temporal and Spatial IoU reward coefficients
axioms (1)
- domain assumption Vision-language models possess sufficient spatiotemporal grounding capacity that can be elicited via progressive fine-tuning and RL
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce Temporal and Spatial IoU rewards to supervise the intermediate localization process... Rtemp(yi) = |Fpred ∩ Fgt| / |Fpred ∪ Fgt| ... Rspa(yi) = mean IoU(bpred_m, bgt_m)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-turn GRPO... first conducts a global temporal scan to anchor anomalous time windows, then performs fine-grained spatial grounding
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
IndusAgent: Reinforcing Open-Vocabulary Industrial Anomaly Detection with Agentic Tools
IndusAgent achieves state-of-the-art zero-shot performance on industrial anomaly benchmarks by using a custom Indus-CoT dataset, dynamic tool orchestration, and gated RL to optimize anomaly classification, localizatio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.