BrainJanus: A Unified Model for Understanding and Generation across Brain, Vision, and Language
Pith reviewed 2026-06-30 06:42 UTC · model grok-4.3
The pith
BrainJanus turns brain signals into tokens shared with images and text for any-direction translation in one model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
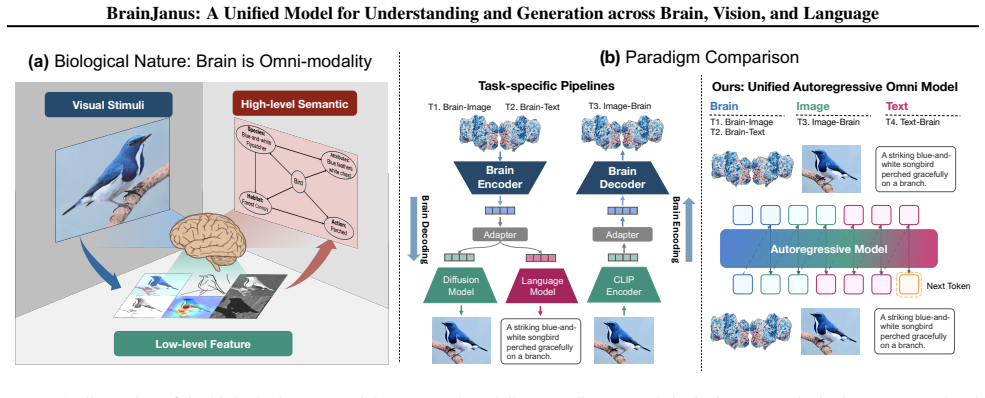
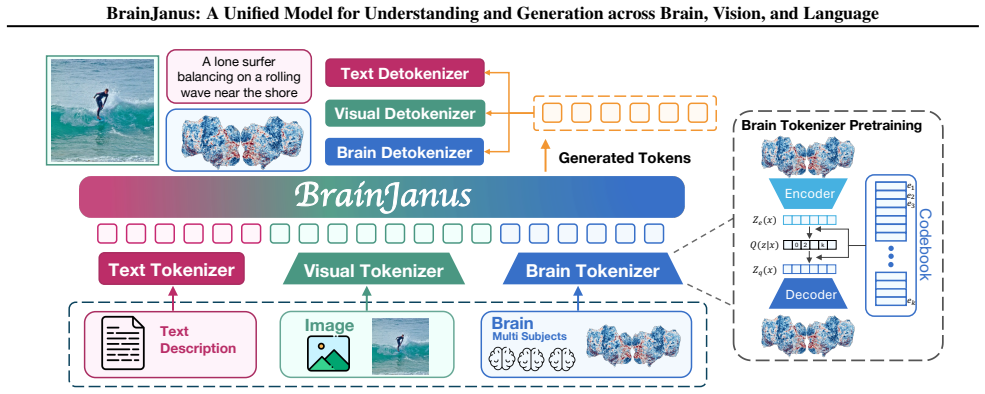
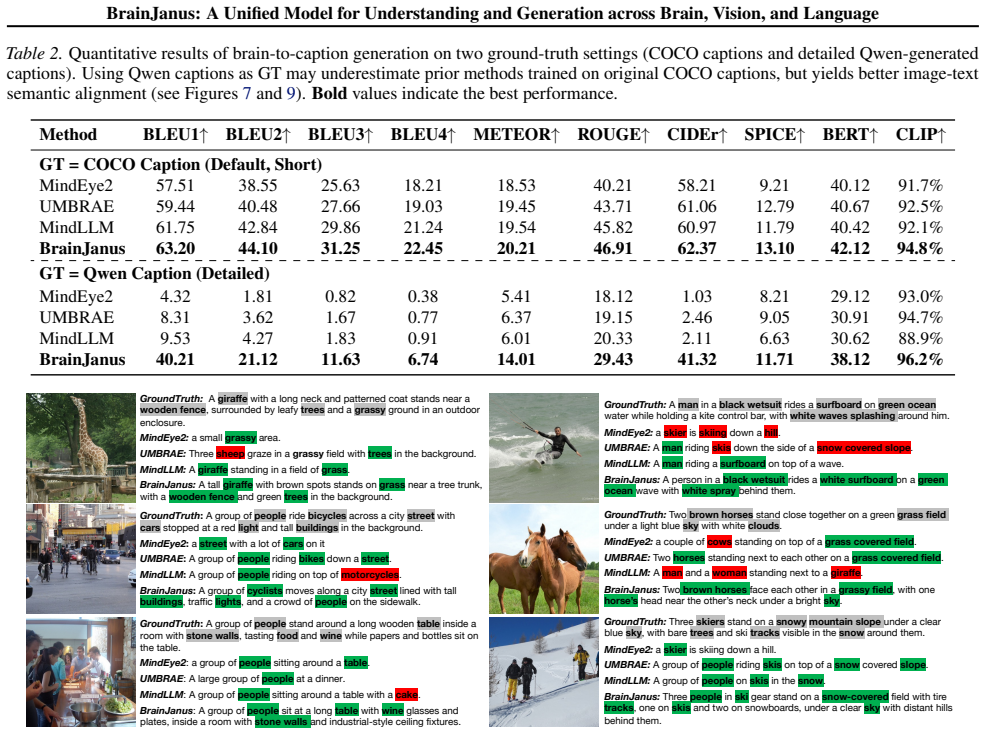
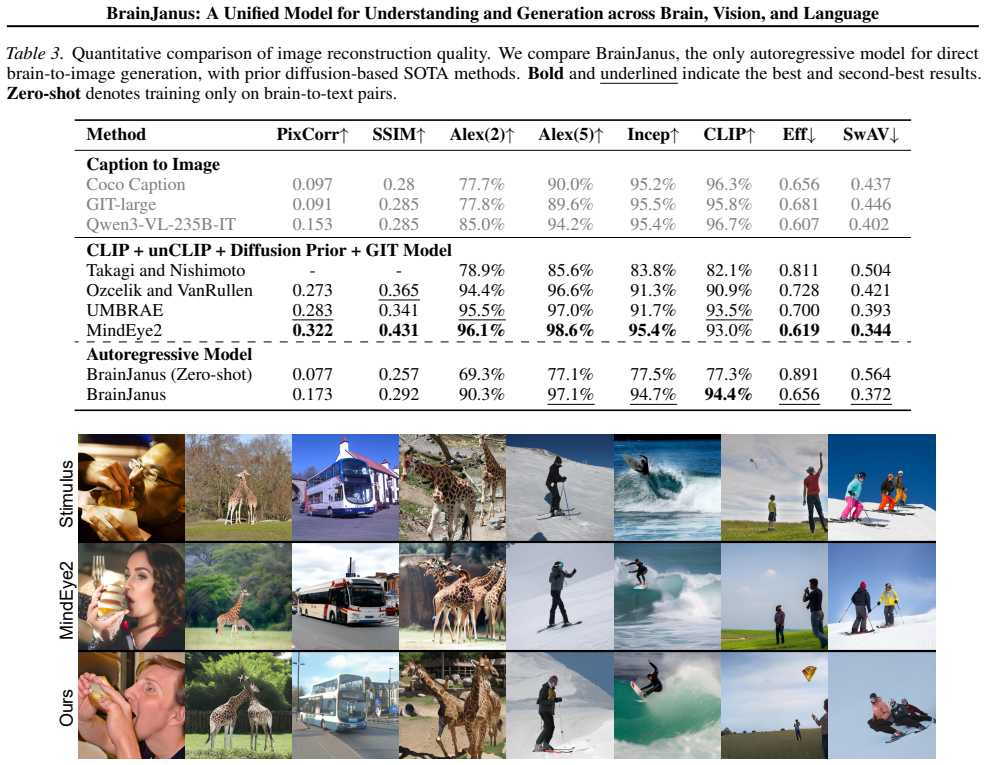
BrainJanus is the first unified brain model that integrates brain, vision, and language within a single framework. It introduces a Unified Brain Tokenizer to quantize continuous neural dynamics into discrete tokens aligned with visual and linguistic representations in a shared Omni space. Building on this, an All-in-One autoregressive architecture uses next-token prediction to enable seamless any-to-any generation, which encompasses image-to-brain and text-to-brain encoding, and brain-to-image and brain-to-text decoding. The framework achieves superior performance across diverse benchmarks, exhibits zero-shot generalization, and preserves interpretable biological topography.
What carries the argument
The Unified Brain Tokenizer, which quantizes continuous neural dynamics into discrete tokens aligned with visual and linguistic representations in a shared Omni space, allowing the All-in-One autoregressive next-token model to treat brain, vision, and language uniformly for any-to-any generation.
If this is right
- Any-to-any generation becomes possible without separate models for each direction.
- Performance exceeds prior unimodal or separate-task approaches on encoding and decoding benchmarks.
- Zero-shot application to new tasks or datasets without retraining.
- Biological topography of brain activity remains interpretable after training.
Where Pith is reading between the lines
- The shared token space could let researchers compare how different senses represent the same concept by inspecting token neighborhoods.
- If the quantization step succeeds, similar tokenizers might be tested on other continuous signals such as muscle activity or eye tracking.
- A practical next step would be to measure whether the model supports real-time closed-loop tasks where brain output directly drives image or text generation.
Load-bearing premise
Continuous neural dynamics can be quantized into discrete tokens that align with visual and linguistic representations in a shared space while preserving interpretable biological topography.
What would settle it
Demonstration that the brain-derived tokens fail to align with vision or language tokens in the shared space, or that the resulting model erases measurable biological topography of brain activity on standard mapping tasks.
Figures

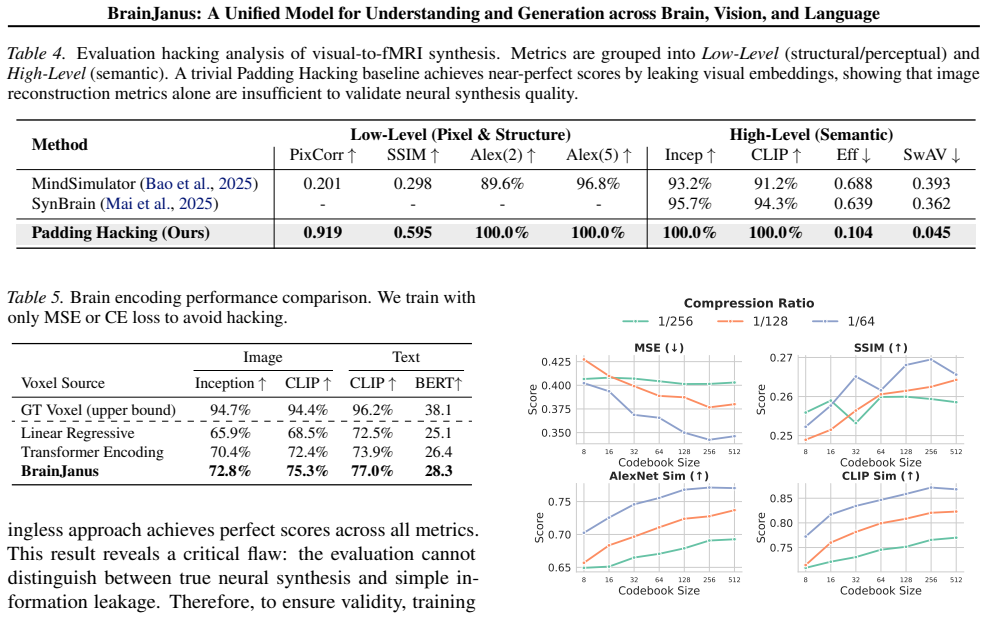




read the original abstract
Modeling the bidirectional correspondence between external sensory stimuli and internal neural activity has emerged as a critical frontier in neuroscience. However, existing approaches predominantly treat brain encoding and decoding as isolated tasks, relying heavily on unimodal alignment and external priors while overlooking the brain's intrinsic nature as a multimodal integration system. To address these limitations, we propose BrainJanus, the first unified brain model that integrates brain, vision, and language within a single framework. Specifically, we introduce a Unified Brain Tokenizer to quantize continuous neural dynamics into discrete tokens aligned with visual and linguistic representations in a shared Omni space. Building on this, we utilize an All-in-One autoregressive architecture that leverages next-token prediction to enable seamless any-to-any generation, which encompasses image-to-brain and text-to-brain encoding, and brain-to-image and brain-to-text decoding. Extensive experiments demonstrate that BrainJanus achieves superior performance across diverse benchmarks. Furthermore, our framework exhibits zero-shot generalization and preserves interpretable biological topography, highlighting its potential as a general-purpose brain modeling paradigm. The code is available at \href{https://github.com/HaitaoWuTJU/BrainJanus}{GitHub}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BrainJanus as the first unified model integrating brain, vision, and language. It introduces a Unified Brain Tokenizer that quantizes continuous neural dynamics into discrete tokens aligned with visual and linguistic representations in a shared Omni space, and an All-in-One autoregressive architecture using next-token prediction for any-to-any generation (image-to-brain, text-to-brain, brain-to-image, brain-to-text). The manuscript claims superior performance across diverse benchmarks, zero-shot generalization, and preservation of interpretable biological topography, with code released on GitHub.
Significance. If the tokenizer and autoregressive claims hold with supporting evidence, the work could provide a general-purpose paradigm for multimodal brain modeling that unifies encoding and decoding tasks.
major comments (2)
- [Abstract] Abstract: The central claims of superior performance across benchmarks and zero-shot generalization are asserted without any methods description, datasets, quantitative results, error bars, or ablation studies, preventing evaluation of whether the Unified Brain Tokenizer or All-in-One architecture actually delivers these outcomes.
- [Abstract] Abstract: The Unified Brain Tokenizer is described as quantizing continuous neural dynamics into discrete tokens that align in Omni space while preserving biological topography, but no equations, loss terms, architecture details, or validation experiments for topography preservation or alignment fidelity are supplied; this is load-bearing for the any-to-any generation claims.
Simulated Author's Rebuttal
We thank the referee for the comments. We address each major point below, noting that the abstract is a concise summary per standard academic conventions, with full technical details in the manuscript body.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of superior performance across benchmarks and zero-shot generalization are asserted without any methods description, datasets, quantitative results, error bars, or ablation studies, preventing evaluation of whether the Unified Brain Tokenizer or All-in-One architecture actually delivers these outcomes.
Authors: The abstract is designed as a high-level overview of contributions and results, as is conventional for papers in this field due to length constraints. The methods, datasets, quantitative results with error bars, ablation studies, and evaluation of the tokenizer and architecture are fully detailed in Sections 3 (Methodology), 4 (Experiments), and the supplementary material, enabling complete assessment of the claims. revision: no
-
Referee: [Abstract] Abstract: The Unified Brain Tokenizer is described as quantizing continuous neural dynamics into discrete tokens that align in Omni space while preserving biological topography, but no equations, loss terms, architecture details, or validation experiments for topography preservation or alignment fidelity are supplied; this is load-bearing for the any-to-any generation claims.
Authors: The abstract summarizes the tokenizer at a high level. The equations, loss terms, architecture details, and validation experiments for topography preservation and alignment fidelity are provided in Section 3.1 (Unified Brain Tokenizer) and Section 4.2 (Interpretability Analysis), directly supporting the any-to-any generation results reported in the experiments. revision: no
Circularity Check
No derivation chain or equations presented; no circularity detectable
full rationale
The abstract and available text introduce the Unified Brain Tokenizer and All-in-One autoregressive architecture as components but supply no equations, loss functions, parameter-fitting procedures, or self-citations that could reduce any claimed result to its inputs by construction. No predictions are framed as first-principles derivations, and no load-bearing steps match the enumerated circularity patterns. The work is therefore self-contained as an empirical modeling proposal without detectable circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Spice: Semantic propositional image caption evaluation
Anderson, P., Fernando, B., Johnson, M., and Gould, S. Spice: Semantic propositional image caption evaluation. InComputer Vision–ECCV 2016: 14th European Confer- ence, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part V 14, pp. 382–398. Springer,
2016
-
[2]
Bao, G., Zhang, Q., Gong, Z., Wu, Z., and Miao, D. Mind- simulator: Exploring brain concept localization via syn- thetic fmri.arXiv preprint arXiv:2503.02351,
-
[3]
O., Fonseca, A
Caro, J. O., Fonseca, A. H. d. O., Averill, C., Rizvi, S. A., Rosati, M., Cross, J. L., Mittal, P., Zappala, E., Levine, D., Dhodapkar, R. M., et al. Brainlm: A foundation model for brain activity recordings.bioRxiv, pp. 2023–09,
2023
-
[4]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., and Ruan, C. Janus-pro: Unified multimodal understand- ing and generation with data and model scaling.arXiv preprint arXiv:2501.17811,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Chen, Y ., Ren, K., Song, K., Wang, Y ., Wang, Y ., Li, D., and Qiu, L. Eegformer: Towards transferable and inter- pretable large-scale eeg foundation model.arXiv preprint arXiv:2401.10278,
-
[7]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al. Emerging proper- ties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Ferrante, M., Ozcelik, F., Boccato, T., VanRullen, R., and Toschi, N. Brain captioning: Decoding human brain activ- ity into images and text.arXiv preprint arXiv:2305.11560,
-
[9]
Huang, R., Cho, S., Gohil, C., Jones, O. P., and Wool- rich, M. Meg-gpt: A transformer-based foundation model for magnetoencephalography data.arXiv preprint arXiv:2510.18080,
-
[10]
Jiang, W.-B., Zhao, L.-M., and Lu, B.-L. Large brain model for learning generic representations with tremendous eeg data in bci.arXiv preprint arXiv:2405.18765,
-
[11]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Mai, W. and Zhang, Z. Unibrain: Unify image reconstruc- tion and captioning all in one diffusion model from human brain activity.arXiv preprint arXiv:2308.07428,
-
[13]
Scotti, P. S., Tripathy, M., Villanueva, C. K. T., Kneeland, R., Chen, T., Narang, A., Santhirasegaran, C., Xu, J., Naselaris, T., Norman, K. A., et al. Mindeye2: Shared- subject models enable fmri-to-image with 1 hour of data. arXiv preprint arXiv:2403.11207,
-
[14]
Decoding natural images from eeg for object recognition.arXiv preprint arXiv:2308.13234, 2023
10 BrainJanus: A Unified Model for Understanding and Generation across Brain, Vision, and Language Song, Y ., Liu, B., Li, X., Shi, N., Wang, Y ., and Gao, X. Decoding natural images from eeg for object recognition. arXiv preprint arXiv:2308.13234,
-
[15]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y ., Chen, S., Zhang, S., Peng, B., Luo, P., and Yuan, Z. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
GIT: A Generative Image-to-text Transformer for Vision and Language
Wang, G., Liu, W., He, Y ., Xu, C., Ma, L., and Li, H. Eegpt: Pretrained transformer for universal and reliable repre- sentation of eeg signals.Advances in Neural Information Processing Systems, 37:39249–39280, 2024a. Wang, J., Yang, Z., Hu, X., Li, L., Lin, K., Gan, Z., Liu, Z., Liu, C., and Wang, L. Git: A generative image-to- text transformer for visio...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Emu3: Next-Token Prediction is All You Need
Wang, S., Liu, S., Tan, Z., and Wang, X. Mindbridge: A cross-subject brain decoding framework. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11333–11342, 2024b. Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y ., Wang, J., Zhang, F., Wang, Y ., Li, Z., Yu, Q., et al. Emu3: Next-token prediction is all you need.arXiv...
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Brainomni: A brain foundation model for unified eeg and meg signals
Xiao, Q., Cui, Z., Zhang, C., Chen, S., Wu, W., Thwaites, A., Woolgar, A., Zhou, B., and Zhang, C. Brainomni: A brain foundation model for unified eeg and meg signals. arXiv preprint arXiv:2505.18185,
-
[20]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Xie, J., Mao, W., Bai, Z., Zhang, D. J., Wang, W., Lin, K. Q., Gu, Y ., Chen, Z., Yang, Z., and Shou, M. Z. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
BERTScore: Evaluating Text Generation with BERT
Zhang, T., Kishore, V ., Wu, F., Weinberger, K. Q., and Artzi, Y . Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[23]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Zhou, C., Yu, L., Babu, A., Tirumala, K., Yasunaga, M., Shamis, L., Kahn, J., Ma, X., Zettlemoyer, L., and Levy, O. Transfusion: Predict the next token and dif- fuse images with one multi-modal model.arXiv preprint arXiv:2408.11039, 2024a. Zhou, Q., Du, C., Wang, S., and He, H. Clip-mused: Clip- guided multi-subject visual neural information semantic deco...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Detailed Results B.1
Table 6.Hyperparameters of BrainTokenizer Hyperparameter Value Base channel size 64 Encoder channel multipliers [1, 2, 2, 2, 4, 4, 4] Decoder channel multipliers [1, 2, 2, 2, 4, 4, 4] Residual blocks per level 2 Downsampling factor per level 2 Latent channel dimension 512 Codebook size 128 Codebook embedding dimension 32 Commitment loss weight 0.25 Entrop...
2022
-
[25]
However, these local measures suffer from two fundamental limitations
predominantly rely on voxel-wise metrics, such as Pearson correlation and MSE. However, these local measures suffer from two fundamental limitations. First, they neglect global cortical topography, failing to penalize structurally incoherent predictions. Second, they are overly sensitive to the intrinsic stochasticity of neural responses (i.e., trial-to-t...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.