Capability and Robustness Cannot Both Be Free: An Information-Theoretic Bound for Vision-Language-Action Models
Pith reviewed 2026-06-29 21:27 UTC · model grok-4.3
The pith
For any vision-language-action policy, capability and robustness sum to at most task entropy plus adversarial channel capacity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
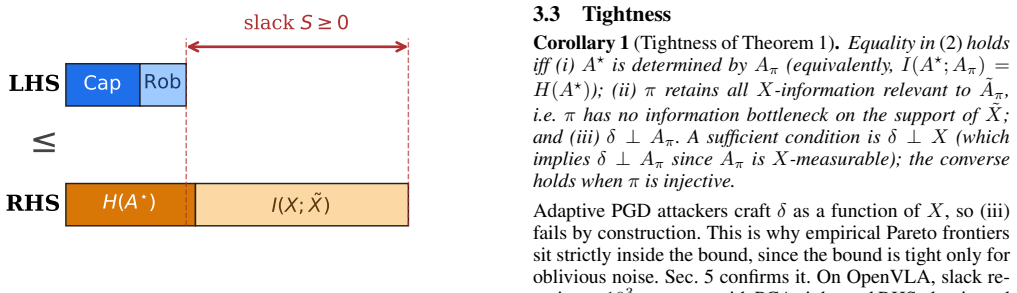
For any VLA policy, capability I(A*;Aπ) and robustness I(Aπ;Ãπ)−I(Aπ;δ) sum to at most H(A*)+I(X;X̃). The proof reduces to two applications of the Data Processing Inequality.
What carries the argument
Two successive applications of the data processing inequality to the Markov chains linking optimal actions to policy actions and policy actions to perturbed actions under input perturbation.
Load-bearing premise
The information flow inside the VLA policy obeys the Markov chain conditions required for the data processing inequality to apply to the pairs of actions and perturbations.
What would settle it
A single VLA policy in which the measured sum of capability and robustness exceeds H(A*) + I(X; X̃) while the Markov conditions hold would falsify the bound.
Figures
read the original abstract
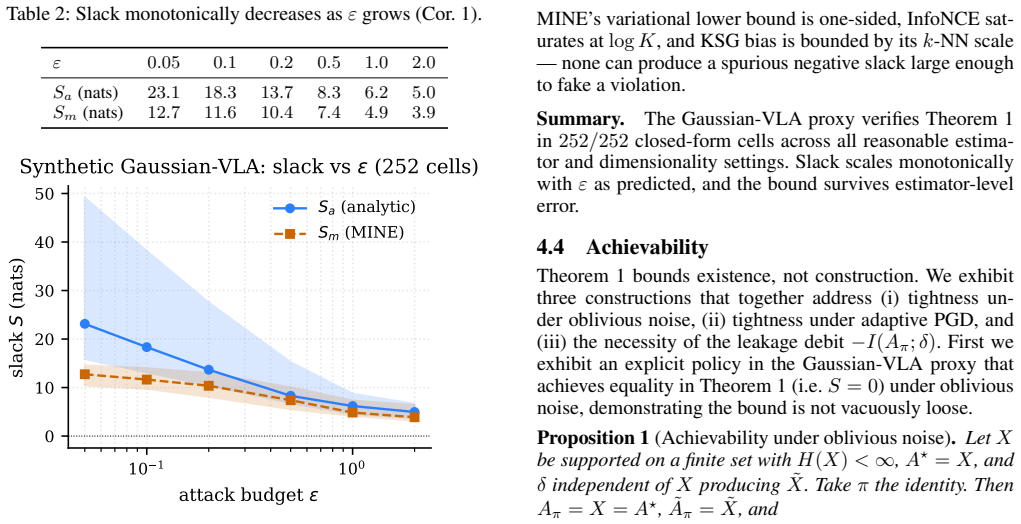
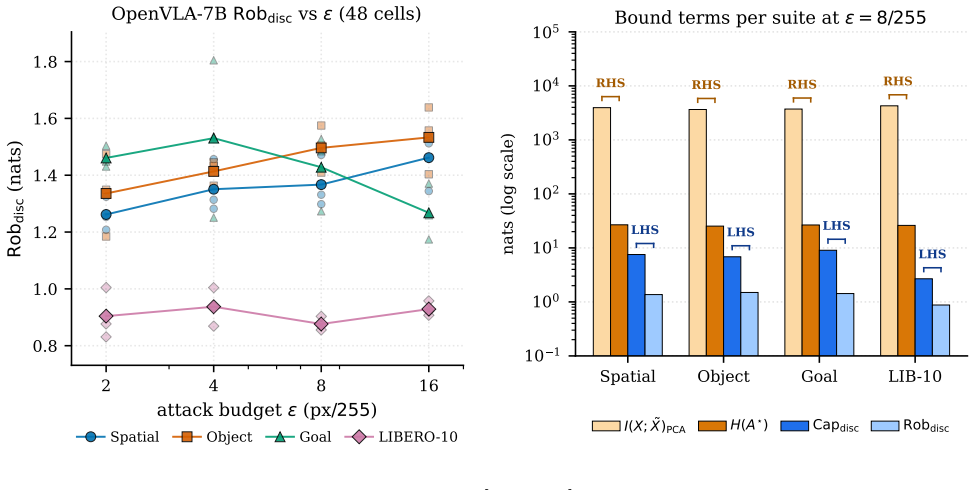
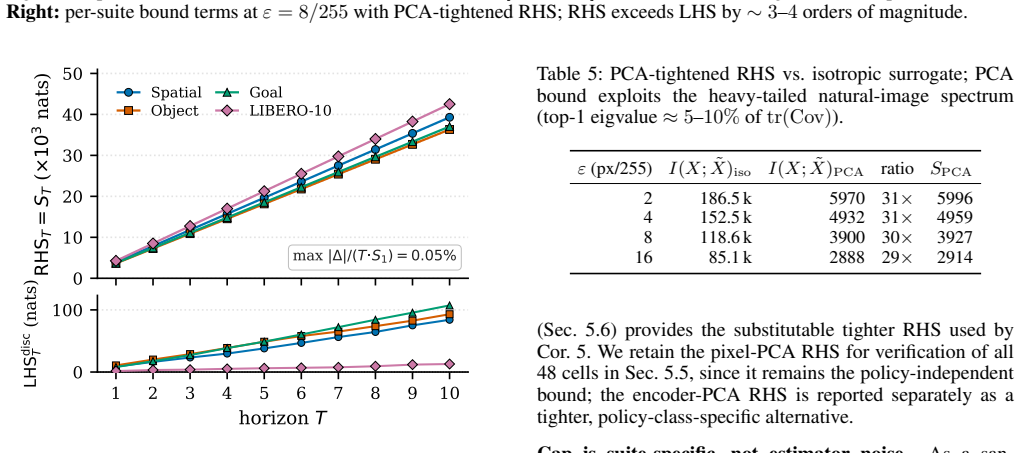
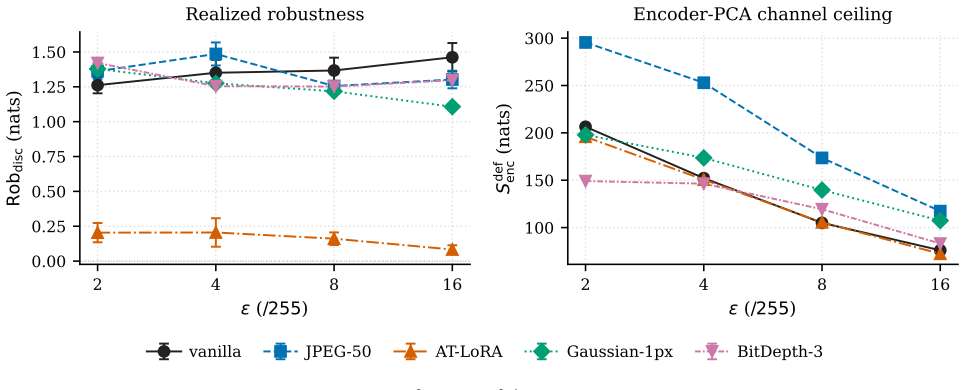
Vision-Language-Action (VLA) models reach high success rates on clean inputs but collapse under small adversarial perturbations: a $16/255$ PGD attack drops OpenVLA-7B's LIBERO success from $95\%$ to under $5\%$. Whether this trade-off has a theoretical floor was open. We prove that it does. For any VLA policy, capability $I(\Astar;\Api)$ and robustness $I(\Api;\Atildepi)-I(\Api;\delta)$ sum to at most $H(\Astar)+I(X;\Xtilde)$, the task entropy plus adversarial channel capacity. The proof reduces to two applications of the Data Processing Inequality. The pixel-level bound is loose by $\sim 10^3$ nats and serves as a ceiling guarantee; an encoder-specific corollary tightens it by over an order of magnitude, into a regime where realized capability already consumes $5$--$9\%$ of the budget. We validate Theorem~\ref{thm:main} with zero violations across $308$ cells: $252$ closed-form Gaussian-VLA, $48$ OpenVLA-7B$+$LIBERO$+$PGD ($4$ suites $\times$ $4$ $\eps$ $\times$ $3$ seeds), $4$ Square-Attack, and $4$ multi-step ($T{=}10$). A complementary measurability inequality $\Rob_{\text{disc}} \le \Cap_{\text{disc}}$ further holds across $144$ cross-architecture cells spanning OpenVLA, OpenVLA-OFT (continuous-$L_1$), and SmolVLA (flow-matching). The same construction yields three label-free diagnostics: a pre-flight encoder ceiling, a defense-forensics probe that localizes input-side vs.\ language-model intervention, and a head-agnostic robustness ratio comparable across discrete-token, $L_1$-regression, and flow-matching policies. Together these provide the cross-setting axis defense and architecture comparisons currently lack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to derive an information-theoretic upper bound on the sum of capability I(A*;Aπ) and robustness I(Aπ;Ãπ)−I(Aπ;δ) for any VLA policy, showing it is at most H(A*)+I(X;X̃). The derivation is stated to reduce to two applications of the Data Processing Inequality. The bound is presented as a loose pixel-level ceiling guarantee, with a tighter encoder-specific corollary, and is supported by zero violations across 308 empirical cells (Gaussian simulations, OpenVLA-7B on LIBERO with PGD, Square-Attack, multi-step, and cross-architecture checks) plus a measurability inequality Rob_disc ≤ Cap_disc.
Significance. If the bound and its DPI derivation hold, the result supplies a theoretical floor to the observed capability-robustness trade-off in VLAs, together with three label-free diagnostics (encoder ceiling, input-vs-LM forensics probe, head-agnostic robustness ratio) that apply across discrete, L1-regression, and flow-matching policies. The empirical coverage across real models and attack types strengthens the practical utility of the ceiling guarantee.
major comments (1)
- [Theorem 1 (thm:main)] Theorem 1 (thm:main): the two DPI steps require explicit Markov chains (e.g., A*—X—Aπ for the capability term and Aπ—X—X̃—Ãπ or Aπ—(X,δ)—Ãπ for the subtracted robustness term). The manuscript does not define or verify these chains; in a VLA, A* is the expert action while X is the observed image, so no automatic conditional independence places A* upstream of Aπ given X. The same gap appears once δ perturbs X to X̃. Without these chains the DPI applications are not justified and the stated bound does not follow.
minor comments (1)
- The abstract states the pixel-level bound is loose by ~10^3 nats; a short quantitative comparison of the encoder-specific corollary versus the pixel bound would help readers assess tightness.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need to make the Markov chain assumptions explicit in the proof of Theorem 1. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Theorem 1 (thm:main): the two DPI steps require explicit Markov chains (e.g., A*—X—Aπ for the capability term and Aπ—X—X̃—Ãπ or Aπ—(X,δ)—Ãπ for the subtracted robustness term). The manuscript does not define or verify these chains; in a VLA, A* is the expert action while X is the observed image, so no automatic conditional independence places A* upstream of Aπ given X. The same gap appears once δ perturbs X to X̃. Without these chains the DPI applications are not justified and the stated bound does not follow.
Authors: We agree that the Markov chains should be stated explicitly for clarity. In the VLA setting the policy π is a (possibly stochastic) mapping from the observation X (and language instruction) to the action Aπ only. Consequently Aπ is conditionally independent of A* given X, establishing the Markov chain A* — X — Aπ. The DPI then directly yields I(A*; Aπ) ≤ I(A*; X) ≤ H(A*). For the robustness term, X̃ is obtained from X via the perturbation δ and Ãπ = π(X̃). The resulting chain Aπ — X — X̃ — Ãπ holds because both actions are generated solely from their respective inputs, so I(Aπ; Ãπ) ≤ I(X; X̃). The subtracted term I(Aπ; δ) accounts for any direct dependence on the perturbation; combining the two DPI applications produces the claimed bound. We will add a dedicated paragraph (and optional diagram) in the proof of Theorem 1 that defines these chains and verifies the conditional independences from the policy definition. revision: yes
Circularity Check
Standard DPI application with no self-referential reduction
full rationale
The central claim is obtained by applying the Data Processing Inequality (a standard external theorem) twice under explicitly stated Markov chain assumptions on the VLA information flow. No parameters are fitted to data and renamed as predictions, no self-citation chain supports the bound, and the result is not equivalent to its inputs by definition or renaming. The derivation remains independent of the paper's own experimental validations or prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Data Processing Inequality applies to the relevant Markov chains in any VLA policy
Reference graph
Works this paper leans on
-
[1]
InAdvances in Neural Infor- mation Processing Systems (NeurIPS), Datasets and Bench- marks Track
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), Datasets and Bench- marks Track. Liu, H.; Ruan, S.; Long, J.; Wu, J.; Hou, J.; Tang, H.; Jiang, T.; Zhou, W.; and Yao, W. 2025. Eva-VLA: Evaluating Vision-Language-Action Models’ Robustness Under Real-World Physical Variati...
-
[2]
Zhai, X.; Mustafa, B.; Kolesnikov, A.; and Beyer, L
Multimodal Adversarial Attacks on Vision-Language- Action Models.arXiv preprint arXiv:2511.16203. Zhai, X.; Mustafa, B.; Kolesnikov, A.; and Beyer, L. 2023. Sigmoid Loss for Language Image Pre-Training. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Zhang, H.; Yu, Y .; Jiao, J.; Xing, E. P.; El Ghaoui, L.; and Jordan, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.