Pruning via Causal Attribution Preserves Reasoning Performance in Large Language Models
Pith reviewed 2026-07-01 09:27 UTC · model grok-4.3
The pith
Measuring the causal impact of each attention head on reasoning tasks lets pruning remove weights while keeping more of the model's original performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By estimating the expected performance degradation when each attention head is masked on a calibration set of reasoning problems and converting those scores into weight-level importance values, CAP produces higher downstream accuracy than magnitude-only or activation-based pruning at equivalent sparsity, with relative gains up to 61 percent over Wanda on ARC-Challenge at 20 percent sparsity for the tested models.
What carries the argument
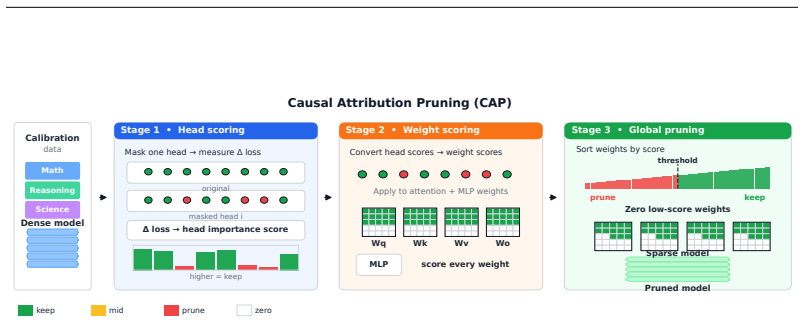
Causal Attribution Pruning, which converts interventional head-masking performance drops on a reasoning calibration set into importance scores for the corresponding projection matrices.
If this is right
- At 10-20 percent sparsity CAP improves accuracy over Wanda in most model-benchmark pairs, with especially large gains on ARC-Challenge for Llama-3-8B-Instruct.
- The method yields relative accuracy gains of up to 61 percent over Wanda on ARC-Challenge at 20 percent sparsity.
- At 50 percent sparsity the advantage shrinks because MLP attribution remains coarse.
- Attention-head-level interventional scores preserve reasoning performance better than correlational criteria at moderate sparsity.
Where Pith is reading between the lines
- Extending the same interventional measurement to MLP layers could remove the current limit at higher sparsity levels.
- The success of the method appears to depend on matching the calibration examples closely to the target reasoning domain.
- Hybrid pruning that first uses causal head scores and then refines within layers might reach higher sparsity while retaining accuracy.
Load-bearing premise
The performance drop observed when a single head is masked on a small calibration set of reasoning problems gives a stable, accurate estimate of that head's true causal contribution to the full task, even when other heads remain active.
What would settle it
Running the same pruning procedure on a calibration set drawn from non-reasoning tasks and finding that the accuracy advantage over Wanda disappears would show the estimates are not capturing general causal contributions.
Figures
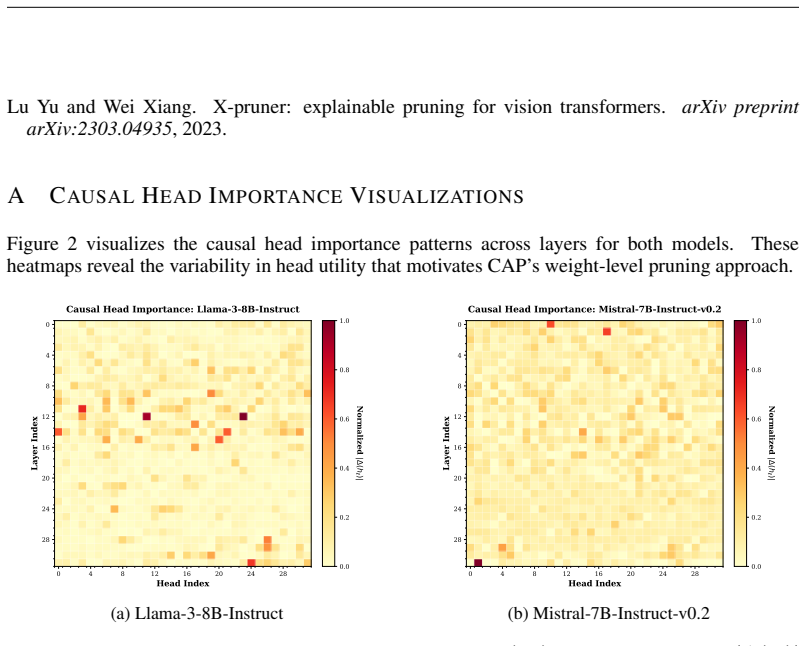
read the original abstract
Large language models (LLMs) excel at multi-step reasoning but incur substantial inference cost. We introduce Causal Attribution Pruning (CAP), a training-free method that identifies critical attention heads by measuring their causal impact on reasoning tasks and uses these head-level scores to guide fine-grained weight pruning. For each attention head, CAP estimates the expected performance degradation when the head is masked during forward passes on a small calibration set of reasoning problems. These causal scores are then converted into weight-level importance values for the corresponding projection matrices. Unlike magnitude-only or activation-based criteria, CAP's interventional measurement directly captures each head's functional contribution, yielding relative accuracy gains of up to 61% over Wanda on ARC-Challenge at 20% sparsity. We evaluate CAP on GSM8K, StrategyQA, and ARC-Challenge using Llama-3-8B-Instruct and Mistral-7B-Instruct at 10%, 20%, and 50% sparsity. At moderate sparsity (10-20%), CAP improves over Wanda in most model-benchmark configurations. with especially large gains on ARC-Challenge for Llama-3. Our results suggest that attention-head-level causal attribution can better preserve reasoning performance on downstream benchmarks than correlational pruning criteria at equivalent sparsity, while remaining limited by coarse MLP attribution at 50% sparsity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Causal Attribution Pruning (CAP), a training-free method that estimates each attention head's causal contribution to reasoning performance via expected accuracy drop under single-head masking on a small calibration set of reasoning problems, converts these head-level scores to weight-level importance for the corresponding projection matrices, and prunes accordingly. It evaluates the approach on Llama-3-8B-Instruct and Mistral-7B-Instruct at 10-50% sparsity on GSM8K, StrategyQA, and ARC-Challenge, claiming relative accuracy gains of up to 61% over Wanda at 20% sparsity on ARC-Challenge and improvements in most model-benchmark pairs at moderate sparsity.
Significance. If the empirical superiority holds after addressing calibration sensitivity and interaction assumptions, the result would indicate that interventional head-level causal attribution can outperform magnitude- and activation-based pruning criteria for preserving multi-step reasoning, which is relevant for efficient deployment of LLMs on reasoning benchmarks.
major comments (1)
- [Abstract and §3 (CAP estimation procedure)] Abstract and method description of CAP estimation procedure: the central claim that CAP's interventional scores yield superior reasoning preservation (e.g., 61% relative gain over Wanda on ARC-Challenge at 20% sparsity) rests on single-head masking on a small calibration set producing stable, additive estimates of functional contribution. No analysis of head-interaction effects, variance across calibration sets, or sensitivity to calibration composition is provided, which directly undermines verification of the reported gains.
minor comments (2)
- [Abstract] The abstract states numerical gains but supplies no information on calibration-set size/composition, statistical significance, or error bars, limiting assessment of the empirical claims.
- [Method] Clarify the exact conversion from head-level causal scores to per-weight importance values in the projection matrices, including any scaling or aggregation steps.
Simulated Author's Rebuttal
We thank the referee for highlighting this important aspect of our method. We address the concern point-by-point below and commit to revisions that directly strengthen the empirical grounding of CAP.
read point-by-point responses
-
Referee: [Abstract and §3 (CAP estimation procedure)] Abstract and method description of CAP estimation procedure: the central claim that CAP's interventional scores yield superior reasoning preservation (e.g., 61% relative gain over Wanda on ARC-Challenge at 20% sparsity) rests on single-head masking on a small calibration set producing stable, additive estimates of functional contribution. No analysis of head-interaction effects, variance across calibration sets, or sensitivity to calibration composition is provided, which directly undermines verification of the reported gains.
Authors: We agree that the absence of explicit stability and interaction analyses limits the strength of the claims. The current manuscript reports results from a single fixed calibration set without quantifying variance or head interactions. In revision we will add: (1) variance of head scores across 5 independent calibration draws of equal size, (2) sensitivity experiments swapping in/out subsets of GSM8K/ARC problems, and (3) a brief discussion of the single-head masking approximation together with a small-scale pairwise masking study on the top-20 heads. These additions will be placed in §3 and a new appendix. We believe the core interventional approach remains valid, but the referee is correct that the reported gains require this supporting evidence. revision: yes
Circularity Check
No significant circularity; method defined by explicit interventional procedure on separate calibration data
full rationale
The paper defines CAP via an explicit procedure: mask each head individually on a small calibration set of reasoning problems, compute expected accuracy drop, convert to weight-level scores, then prune. This is applied to held-out benchmarks (GSM8K, StrategyQA, ARC-Challenge) without any reduction of the importance scores to the final evaluation numbers by construction. No self-citations, fitted-input predictions, or ansatzes are described that would make the central claim equivalent to its inputs. The derivation chain remains independent of the reported accuracy gains.
Axiom & Free-Parameter Ledger
free parameters (1)
- calibration set size and composition
axioms (1)
- domain assumption Masking an individual attention head during forward passes on the calibration set produces a valid estimate of its causal contribution to reasoning performance.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Jacob Hilton, and et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2301.00774 , year=
URLhttps://arxiv.org/abs/2301.00774. Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? A question answering benchmark with implicit reasoning strategies.Transactions of the Association for Computational Linguistics, 9:346–361,
-
[3]
Learning both Weights and Connections for Efficient Neural Networks
URLhttps://arxiv.org/abs/1506.02626. Song Han, Huizi Mao, and William J. Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URLhttps://arxiv.org/ abs/1510.00149. Sayed Mohammad Vakilzadeh Hatefi, Maximilian Dreyer, Reduan Achtibat, Thomas Wiegand, Wo- jciech Samek, and Sebastian Lapuschkin. Pruning by explaining revisited: Optimizing attribution methods to prune cnns and transformers.arXiv preprint arXiv:2408.12568,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Sayed Mohammad Vakilzadeh Hatefi, Maximilian Dreyer, Reduan Achtibat, Patrick Kahardipraja, Thomas Wiegand, Wojciech Samek, and Sebastian Lapuschkin. Attribution-guided pruning for compression, circuit discovery, and targeted correction in llms.arXiv preprint arXiv:2506.13727,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, et al. Mistral 7b.arXiv preprint arXiv:2310.06825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Andrew Nam, Henry Conklin, Yukang Yang, Thomas Griffiths, Jonathan Cohen, and Sarah-Jane Leslie
Introduces the WikiText language modeling dataset. Andrew Nam, Henry Conklin, Yukang Yang, Thomas Griffiths, Jonathan Cohen, and Sarah-Jane Leslie. Causal head gating: A framework for interpreting roles of attention heads in transformers. arXiv preprint arXiv:2505.13737,
-
[9]
A Simple and Effective Pruning Approach for Large Language Models
URLhttps://arxiv.org/abs/2306.11695. Hugo Touvron et al. The Llama 3 herd of models. Meta AI Technical Report,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
URLhttps: //ai.meta.com/research/publications/the-llama-3-herd-of-models/. Open-weight language models. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.arXiv preprint arXiv:2201.11903,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Transformers: State- of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, R´emi Louf, Morgan Funtowicz, and Jamie Brew. Transformers: State- of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 38–45,
2020
-
[12]
X-pruner: explainable pruning for vision transformers.arXiv preprint arXiv:2303.04935,
11 Lu Yu and Wei Xiang. X-pruner: explainable pruning for vision transformers.arXiv preprint arXiv:2303.04935,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.