Attribution-Guided Pruning for Insight and Control: Circuit Discovery and Targeted Correction in Small-scale LLMs
Pith reviewed 2026-05-19 08:49 UTC · model grok-4.3
The pith
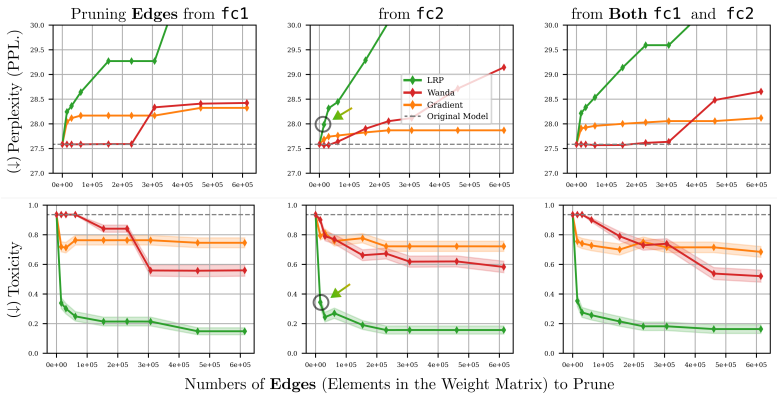
Pruning 0.3% of neurons via LRP attributions substantially reduces toxic outputs in small LLMs while preserving general performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
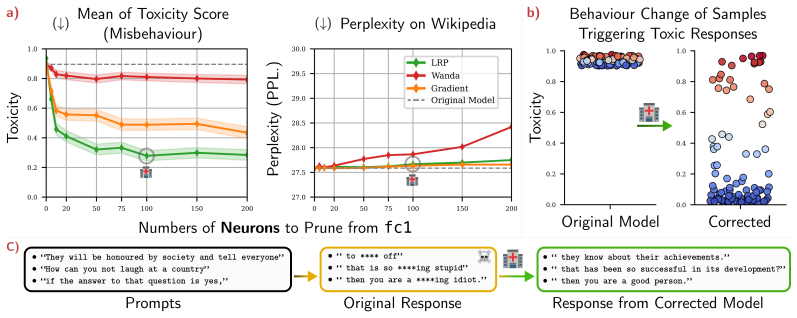
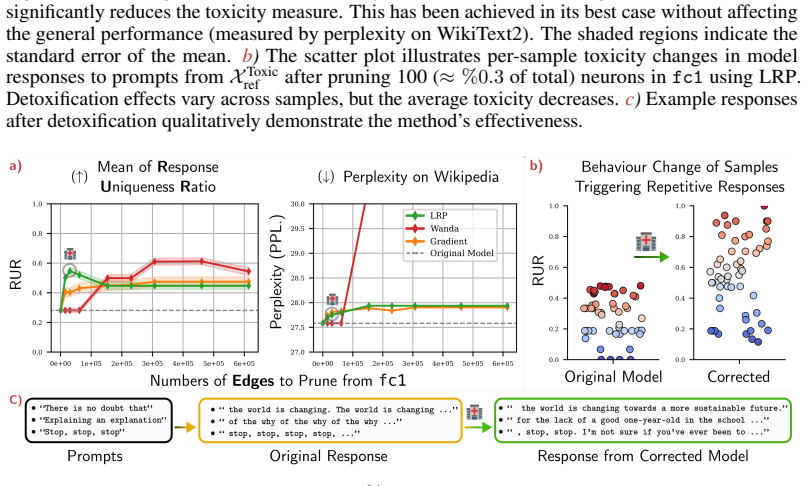
We frame circuit discovery as identifying parameters that contribute most to model outputs on task-specific inputs, and use Layer-wise Relevance Propagation (LRP) with reference samples to attribute and extract these components via pruning. Building on this, we introduce contrastive relevance to isolate circuits associated with undesired behaviors while preserving general capabilities, enabling targeted model correction. On OPT-125M, we show that pruning as little as ~0.3% of neurons substantially reduces toxic outputs, while pruning approximately 0.03% of weight elements mitigates repetitive text generation without degrading general performance. These results establish attribution-guided pr
What carries the argument
Layer-wise Relevance Propagation (LRP) attributions combined with contrastive relevance scoring to rank and prune parameters that drive specific output behaviors.
If this is right
- Pruning roughly 0.3 percent of neurons identified by attributions substantially reduces toxic outputs on OPT-125M.
- Pruning about 0.03 percent of weight elements mitigates repetitive text generation without degrading general performance.
- The attribution-guided pruning approach transfers to additional small-scale language models beyond OPT-125M.
- Contrastive relevance allows isolation of undesired-behavior circuits while leaving general capabilities intact.
Where Pith is reading between the lines
- If the attributions remain reliable at larger scales, the method could support minimal-intervention safety patches that edit only tiny parameter subsets.
- The observed localization of behaviors to fractions of a percent suggests that many model properties may be editable through sparse, targeted interventions rather than full retraining.
- Extending contrastive relevance to other behaviors such as hallucination or bias could yield a general toolkit for modular model correction.
- The pruning results invite direct comparison with activation patching or other causal intervention techniques to test whether attribution ranks align with causal effect sizes.
Load-bearing premise
LRP attributions with reference samples accurately isolate the causal parameters responsible for the target behaviors rather than merely correlated ones.
What would settle it
After pruning the top 0.3 percent of neurons or 0.03 percent of weights identified by the LRP method, measure the rate of toxic or repetitive outputs on the original test prompts; absence of substantial reduction or unexpected drop in general capabilities would falsify the claim.
Figures











read the original abstract
Large Language Models (LLMs) are widely deployed in real-world applications, yet their internal mechanisms remain difficult to interpret and control, limiting our ability to diagnose and correct undesirable behaviors. Mechanistic interpretability addresses this challenge by identifying circuits -- subsets of model components responsible for specific behaviors. However, discovering such circuits in LLMs remains difficult due to their scale and complexity. We frame circuit discovery as identifying parameters that contribute most to model outputs on task-specific inputs, and use Layer-wise Relevance Propagation (LRP) with reference samples to attribute and extract these components via pruning. Building on this, we introduce contrastive relevance to isolate circuits associated with undesired behaviors while preserving general capabilities, enabling targeted model correction. On OPT-125M, we show that pruning as little as ~0.3% of neurons substantially reduces toxic outputs, while pruning approximately 0.03% of weight elements mitigates repetitive text generation without degrading general performance. These results establish attribution-guided pruning as an effective mechanism for identifying and intervening on behavior-specific circuits in LLMs. We further validate our findings on additional small-scale language models, demonstrating that the proposed approach transfers across architectures. Our code is publicly available at https://github.com/erfanhatefi/SparC3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Layer-wise Relevance Propagation (LRP) with reference samples and a contrastive relevance formulation can identify small subsets of neurons or weights responsible for specific undesired behaviors (toxicity, repetition) in small LLMs such as OPT-125M. Pruning ~0.3% of neurons or ~0.03% of weights guided by these attributions substantially reduces the target behaviors while preserving general performance; the approach is presented as a scalable method for circuit discovery and targeted correction, with validation on additional small models and public code release.
Significance. If the central empirical claims are supported by appropriate controls, the work offers a practical, attribution-based pruning technique that links interpretability tools to model editing in small-scale LLMs. Strengths include the public code repository and the focus on minimal intervention (sub-1% pruning) that leaves general capabilities intact; this could be useful for diagnosing and mitigating specific failure modes without full retraining.
major comments (3)
- [Results / Experiments] Results section (experiments on OPT-125M): the reported reductions in toxicity and repetition after pruning top-LRP components are shown, but the manuscript does not include controls that prune an equal number of randomly selected or magnitude-thresholded parameters while measuring the same target metrics. Without these, it remains possible that the observed effect arises from capacity reduction rather than attribution-guided isolation of causal circuits.
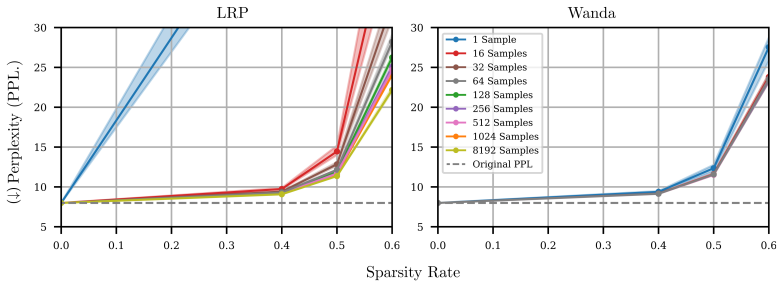
- [Method / Contrastive Relevance] Method section on contrastive relevance: the definition and computation of contrastive relevance (using reference samples) is described at a high level, yet the paper provides insufficient detail on how reference samples are selected and whether they adequately control for general language modeling capability versus the undesired behavior. This choice is load-bearing for the claim that pruning isolates behavior-specific circuits.
- [Evaluation / Metrics] Evaluation protocol: the manuscript reports that general performance is preserved, but does not specify the exact benchmarks, number of runs, or statistical tests used to support the 'without degrading general performance' claim. This weakens the targeted-correction interpretation.
minor comments (2)
- [Figures] Figure captions and legends should explicitly state the exact pruning percentages and the baseline (if any) used for comparison.
- [Abstract / Results] The abstract states 'pruning approximately 0.03% of weight elements'; the corresponding experimental table or figure should report the precise count and layer distribution for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us improve the clarity and rigor of our manuscript. We address each major comment below and have revised the paper to incorporate the suggested additions and clarifications.
read point-by-point responses
-
Referee: [Results / Experiments] Results section (experiments on OPT-125M): the reported reductions in toxicity and repetition after pruning top-LRP components are shown, but the manuscript does not include controls that prune an equal number of randomly selected or magnitude-thresholded parameters while measuring the same target metrics. Without these, it remains possible that the observed effect arises from capacity reduction rather than attribution-guided isolation of causal circuits.
Authors: We agree that control experiments are essential to demonstrate that the observed reductions stem from attribution-guided circuit isolation rather than general capacity loss. In the revised manuscript we have added new experiments that prune an equal number of randomly selected neurons/weights as well as magnitude-thresholded parameters (top-k by absolute value). These controls show substantially smaller reductions in toxicity and repetition compared with LRP-guided pruning, while general performance remains comparable across conditions. The new results and figures are included in the updated Results section. revision: yes
-
Referee: [Method / Contrastive Relevance] Method section on contrastive relevance: the definition and computation of contrastive relevance (using reference samples) is described at a high level, yet the paper provides insufficient detail on how reference samples are selected and whether they adequately control for general language modeling capability versus the undesired behavior. This choice is load-bearing for the claim that pruning isolates behavior-specific circuits.
Authors: We appreciate this observation. The revised Method section now provides a detailed account of reference-sample construction: for toxicity we sample equal numbers of toxic and non-toxic sentences from the RealToxicityPrompts dataset, matched for length and topic distribution; for repetition we use a held-out set of repetitive versus non-repetitive continuations generated from the same prompts. We also include an explicit discussion of how the contrastive formulation subtracts relevance attributable to general language-modeling behavior. These additions clarify the load-bearing design choices. revision: yes
-
Referee: [Evaluation / Metrics] Evaluation protocol: the manuscript reports that general performance is preserved, but does not specify the exact benchmarks, number of runs, or statistical tests used to support the 'without degrading general performance' claim. This weakens the targeted-correction interpretation.
Authors: We agree that precise reporting strengthens the targeted-correction claim. The revised Evaluation section now lists the exact benchmarks (WikiText-103 perplexity, zero-shot accuracy on PIQA, HellaSwag, and ARC-easy), states that all metrics are averaged over five independent pruning runs with different random seeds, and reports paired t-tests (p > 0.05) confirming no statistically significant degradation in general performance. These details have been added to both the Evaluation and Results sections. revision: yes
Circularity Check
No significant circularity in empirical attribution-guided pruning
full rationale
The paper frames circuit discovery as an empirical process: LRP attributions (with reference samples and contrastive relevance) are computed on task-specific inputs, top-attributed parameters are pruned, and behavioral changes are measured experimentally on OPT-125M and other small models. No central quantity is defined in terms of itself, no fitted parameter is relabeled as a prediction, and no load-bearing step reduces to a self-citation chain or ansatz smuggled from prior author work. The reported outcomes (toxicity reduction after ~0.3% neuron pruning, repetition mitigation after ~0.03% weight pruning) are presented as direct experimental results rather than derived by construction from the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LRP attributions with reference samples faithfully reflect component contributions to task-specific outputs
invented entities (1)
-
contrastive relevance
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achtibat, R., Hatefi, S. M. V ., Dreyer, M., Jain, A., Wiegand, T., Lapuschkin, S., and Samek, W. (2024). AttnLRP: Attention-aware layer-wise relevance propagation for transformers. In Proceed- ings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 135–168. PMLR
work page 2024
- [2]
-
[3]
J., Weber, L., Neumann, D., Samek, W., Müller, K.-R., and Lapuschkin, S
Anders, C. J., Weber, L., Neumann, D., Samek, W., Müller, K.-R., and Lapuschkin, S. (2022). Finding and removing clever hans: Using explanation methods to debug and improve deep models. Information Fusion, 77:261–295
work page 2022
-
[4]
Bach, S., Binder, A., Montavon, G., Klauschen, F., Müller, K.-R., and Samek, W. (2015). On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PloS one, 10(7):e0130140
work page 2015
-
[5]
Balduzzi, D., Frean, M., Leary, L., Lewis, J., Ma, K. W.-D., and McWilliams, B. (2017). The shattered gradients problem: If resnets are the answer, then what is the question? In Proceedings of the 34th International Conference on Machine Learning, volume 70, pages 342–350. PMLR
work page 2017
-
[6]
Bastings, J. and Filippova, K. (2020). The elephant in the interpretability room: Why use attention as explanation when we have saliency methods? In Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, pages 149–155. Association for Computational Linguistics
work page 2020
-
[7]
Becking, D., Dreyer, M., Samek, W., Müller, K., and Lapuschkin, S. (2022). ECQ x: Explainability-Driven Quantization for Low-Bit and Sparse DNNs. In xxAI - Beyond Explainable AI, Lecture Notes in Computer Science (LNAI Vol. 13200), Springer International Publishing , pages 271–296
work page 2022
-
[8]
Conmy, A., Mavor-Parker, A., Lynch, A., Heimersheim, S., and Garriga-Alonso, A. (2023). To- wards automated circuit discovery for mechanistic interpretability.Advances in Neural Information Processing Systems, 36:16318–16352
work page 2023
- [9]
-
[10]
J., Samek, W., and Lapuschkin, S
Dreyer, M., Pahde, F., Anders, C. J., Samek, W., and Lapuschkin, S. (2024). From hope to safety: Unlearning biases of deep models via gradient penalization in latent space. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 21046–21054
work page 2024
-
[11]
Ferrando, J. and V oita, E. (2024). Information flow routes: Automatically interpreting language models at scale. arXiv preprint arXiv:2403.00824
-
[12]
Gao, L., Tow, J., Abbasi, B., Biderman, S., Black, S., DiPofi, A., Foster, C., Golding, L., Hsu, J., Le Noac’h, A., Li, H., McDonell, K., Muennighoff, N., Ociepa, C., Phang, J., Reynolds, L., Schoelkopf, H., Skowron, A., Sutawika, L., Tang, E., Thite, A., Wang, B., Wang, K., and Zou, A. (2024). A framework for few-shot language model evaluation. 10
work page 2024
-
[13]
Gehman, S., Gururangan, S., Sap, M., Choi, Y ., and Smith, N. A. (2020). Realtoxicityprompts: Evaluating neural toxic degeneration in language models. arXiv preprint arXiv:2009.11462
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[14]
Hassibi, B. and Stork, D. (1992). Second order derivatives for network pruning: Optimal brain surgeon. Advances in neural information processing systems, 5
work page 1992
- [15]
-
[16]
Kim, S., Hooper, C., Gholami, A., Dong, Z., Li, X., Shen, S., Mahoney, M. W., and Keutzer, K. (2023). Squeezellm: Dense-and-sparse quantization. arXiv preprint arXiv:2306.07629
-
[17]
LeCun, Y ., Denker, J., and Solla, S. (1989). Optimal brain damage. Advances in neural information processing systems, 2
work page 1989
-
[18]
Ma, X., Fang, G., and Wang, X. (2023). Llm-pruner: On the structural pruning of large language models. Advances in neural information processing systems, 36:21702–21720
work page 2023
-
[19]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Marks, S., Rager, C., Michaud, E. J., Belinkov, Y ., Bau, D., and Mueller, A. (2024). Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. arXiv preprint arXiv:2403.19647
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Merity, S., Xiong, C., Bradbury, J., and Socher, R. (2016). Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
(2019).Layer-Wise Relevance Propagation: An Overview, pages 193–209
Montavon, G., Binder, A., Lapuschkin, S., Samek, W., and Müller, K.-R. (2019).Layer-Wise Relevance Propagation: An Overview, pages 193–209. Springer International Publishing, Cham
work page 2019
-
[22]
Muralidharan, S., Turuvekere Sreenivas, S., Joshi, R., Chochowski, M., Patwary, M., Shoeybi, M., Catanzaro, B., Kautz, J., and Molchanov, P. (2024). Compact language models via pruning and knowledge distillation. Advances in Neural Information Processing Systems, 37:41076–41102
work page 2024
-
[23]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. (2022). Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744
work page 2022
-
[24]
Pahde, F., Dreyer, M., Samek, W., and Lapuschkin, S. (2023). Reveal to revise: An explainable ai life cycle for iterative bias correction of deep models. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 596–606. Springer
work page 2023
-
[25]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W., and Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67
work page 2020
- [26]
-
[27]
Right for the Right Reasons: Training Differentiable Models by Constraining their Explanations
Ross, A. S., Hughes, M. C., and Doshi-Velez, F. (2017). Right for the right reasons: Training differentiable models by constraining their explanations. arXiv preprint arXiv:1703.03717
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Samek, W., Binder, A., Montavon, G., Lapuschkin, S., and Müller, K.-R. (2017). Evaluating the visualization of what a deep neural network has learned. IEEE Transactions on Neural Networks and Learning Systems, 28(11):2660–2673
work page 2017
-
[29]
Schramowski, P., Stammer, W., Teso, S., Brugger, A., Herbert, F., Shao, X., Luigs, H.-G., Mahlein, A.-K., and Kersting, K. (2020). Making deep neural networks right for the right scientific reasons by interacting with their explanations. Nature Machine Intelligence, 2(8):476–486
work page 2020
-
[30]
Smilkov, D., Thorat, N., Kim, B., Viégas, F., and Wattenberg, M. (2017). Smoothgrad: removing noise by adding noise. arXiv preprint arXiv:1706.03825
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Sun, M., Liu, Z., Bair, A., and Kolter, J. Z. (2023). A simple and effective pruning approach for large language models. arXiv preprint arXiv:2306.11695. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Sundararajan, M., Taly, A., and Yan, Q. (2017). Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning , volume 70, pages 3319–3328. PMLR
work page 2017
- [33]
-
[34]
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. (2023). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Steering Language Models With Activation Engineering
Turner, A. M., Thiergart, L., Leech, G., Udell, D., Vazquez, J. J., Mini, U., and MacDiarmid, M. (2023). Steering language models with activation engineering. arXiv preprint arXiv:2308.10248
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
N., Kaiser, Ł., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30
work page 2017
-
[37]
V oita, E., Talbot, D., Moiseev, F., Sennrich, R., and Titov, I. (2019). Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 5797–5808. Association for Computational Linguistics
work page 2019
- [38]
-
[39]
Xiao, G., Lin, J., Seznec, M., Wu, H., Demouth, J., and Han, S. (2023). SmoothQuant: Accurate and efficient post-training quantization for large language models. volume 202 of Proceedings of Machine Learning Research. PMLR
work page 2023
-
[40]
Yeom, S.-K., Seegerer, P., Lapuschkin, S., Binder, A., Wiedemann, S., Müller, K.-R., and Samek, W. (2021). Pruning by explaining: A novel criterion for deep neural network pruning. Pattern Recognition, 115:107899
work page 2021
-
[41]
Zhang, P., Zeng, G., Wang, T., and Lu, W. (2024). Tinyllama: An open-source small language model. arXiv preprint arXiv:2401.02385
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
OPT: Open Pre-trained Transformer Language Models
Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X. V ., et al. (2022a). Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Zhang, Y ., Wang, G., Yang, T., Pang, T., He, Z., and Lv, J. (2022b). Compression of deep neural networks: bridging the gap between conventional-based pruning and evolutionary approach. Neural Computing and Applications, 34(19):16493–16514. 12 A Transformer Models A.1 Llama and OPT In the official implementations of Llama and OPT, the attention mechanism ...
-
[44]
and as shown in Fig. 6, LRP can be extended to compute relevance scores at the parameter level, ensuring that each weight element is evaluated for its direct contribution to model decisions. LRP is typically implemented as a modified gradient method, where the gradient is scaled by an input term. As described in [7] and detailed in Eq. (8), LRP offers the...
-
[45]
achieves efficient attribution using only a forward pass. It combines weight magnitudes and activations to derive attribution scores for a given weight matrix W at layer l with input activations X, computing Rl W as: Rl W = |W| · ||X||2 (10) Rl W has the same dimensions as W. Each individual element of Rl W corresponds to a relevance score for the associa...
-
[46]
and apply a uniform pruning rate to rows of weight matrices across all linear layers using a row-wise unstructured approach. This method is illustrated in Fig. 7, which also compares alternative pruning strategies. In contrast to compression, we have followed these approaches for circuit discovery: • Globally Strctured: We compute an importance score for ...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.